미분
-
변수의 움직임에 따른 함수의 변화를 측정하기 위한 도구로써, 최적화에서 제일 많이 사용하는 기법
-
미분은 함수 f의 주어진점 (x,f(x)) 에서의 접선의 기울기를 구한다.
-
한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가/감소 하는지 알 수 있다.
- 함수 값을 증가시키고 싶을 때 미분값을 더하는 것을 경사상승법이라 하며, 함수의 극대값의 위치를 구할 때 사용
- 함수 값을 감소시키고 싶을 때 미분값을 빼는 것을 경사하강법이라 하며, 함수의 극소값의 위치를 구할 때 사용
-
경사상승/경사하강 방법은 극값에 도달하면 미분값이 0이 되므로 움직임이 멈춘다.
-
컴퓨터로 미분 계산
import sympy as sym
from sympy.abc import x
sym.diff(sym.poly(x**2 + 2*x +3),x)
>>> Poly(2*x + 2, x, domain='ZZ')-
미분값이 양수
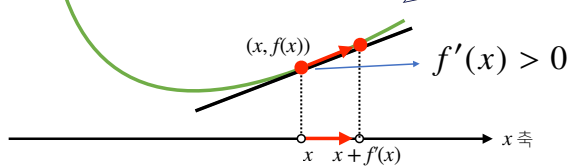
- 함수를 증가시키고 싶다 → 더한다 →오른쪽으로 이동
- 함수를 감소시키고 싶다 → 뺀다 → 왼쪽으로 이동
-
미분값이 음수
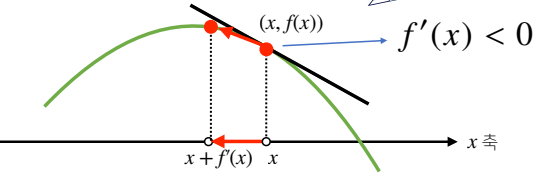
- 함수를 증가시키고 싶다 → 더한다 →왼쪽으로 이동
- 함수를 감소시키고 싶다 → 뺀다 → 오른쪽으로 이동
경사하강법
-
input으로 gradient함수, 초기점, 학습률, epsilon을 설정한다.
-
컴퓨터로 계산할 때 미분이 정확히 0이 되는 것은 불가능하므로, 미분의 절대값이 epsilon보다 작아지면 종료되게 하는 설정이 필요하다.
-
경사하강법 구현
def func(val):
fun = sym.poly(x**2 + 2*x + 3)
return fun.subs(x,val),fun
def func_gradient(fun, val):
_, function = fun(val)
diff = sym.diff(function, x)
return diff.subs(x,val), diff
def gradient_descent(fun, init_point, lr_rate=1e-2, epsilon=1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, init_point)
while np.abs(diff) > epsilon:
val = val - lr_rate*diff
diff, _ = func_gradient(fun,val)
cnt+=1
print("함수 : {}, 연산횟수 : {}, 최소점: ({}, {})".format(fun(val)[1],cnt,val,fun(val)[0]))
gradient_descent(fun=func, init_point=np.random.uniform(-2,2)편미분
- 변수가 벡터인 경우 이동할 때 많은 방향으로 이동할 수 있기 때문에, 앞서 배웠던 미분을 사용할 수는 없고, 특정 좌표축으로 이동하는 편미분을 사용한다.
- 각 변수 별로 편미분을 계산한 그레디언트 벡터(gradient vetor)를 이용하여 경사하강/경사상승법에 사용할 수 있다.
- 차원의 수와 상관없이 gradient vector를 활용하여 최소, 최대값을 구하는데 이용할 수 있다.
- 위의 공식에서 ei는 i번째 벡터값만 1이고 나머지는 0인 단위벡터로 이를 이용해 i번째 변수에서만의 변화를 계산할 수 있다.
- 목적함수(objective function ) : 최소화 혹은 최대화할 함수
- 최적화(optimization) : 목적함수를 최대화 혹은 최소화하는 것
- 그레디언트 벡터(gradient vector) : 다변수 함수의 일차 편미분값으로 이루어진 벡터
- 경사하강법(gradient descent) : 가장 가파른 방향으로 이동하면서 함수의 최소지점을 찾는 기법
- 학습률(learning rate) : 경사하강법에서 gradient에 곱해지는 계수로, 업데이트하는 속도를 조절한다.
- 최적화를 위해 지역 최소점(local minimum)이 아닌 전역 최소점(grobal minimum)에 수렴할 수 있도록 학습률을 잘 조정해야 한다.
- 학습률이 작으면 최소값으로 수렴하는데 시간이 오래 걸리는 단점이 있다.
- 학습률이 높으면 최소값으로 빠르게 수렴할 수 있지만, 오히려 업데이트마다 함수값이 증가하는 방향으로 최적화가 진행될 수 있으므로, 학습률은 조심히 다뤄줄 필요가 있다.
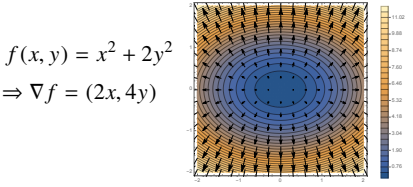
gradient vector
- x,y,z 3차원 공간 상에서 f(x,y)의 표면을 따라 gradient vector를 더하거나 빼면 어떤 점에서 시작을 하든 f(x,y)의 최소,최대점으로 흐르게 된다.

경사하강법 알고리즘 구현
- 앞에서는 gradient의 절대값을 계산했지만, gradient 가 vector이기 때문에 norm을 이용해 종료 조건을 설정한다.
