MLflow가 없던 시절
-
사람들이 각자 자신의 코드를 Jupyter Notebook에서 작성
-
머신러닝 모델 학습시 사용한 Parameter, Metric을 따로 기록
-
개인 컴퓨터, 연구실 서버를 사용하다가 메모리 초과로 Memory Exceed 오류가 발생할 수 있다.
-
학습하며 생긴 Weight File을 지정해 다른 동료들에게 공유
-
Weight File 이름으로 Model Versioning을 하거나 아예 Versioning을 하지 않음
MLflow가 해결하려고 했던 Pain Point
1) 실험을 추적하기 어렵다
2) 코드를 재현하기 어렵다
3) 모델을 패키징하고 배포하는 방법이 어렵다
4) 모델을 관리하기 위한 중앙 저장소가 없다
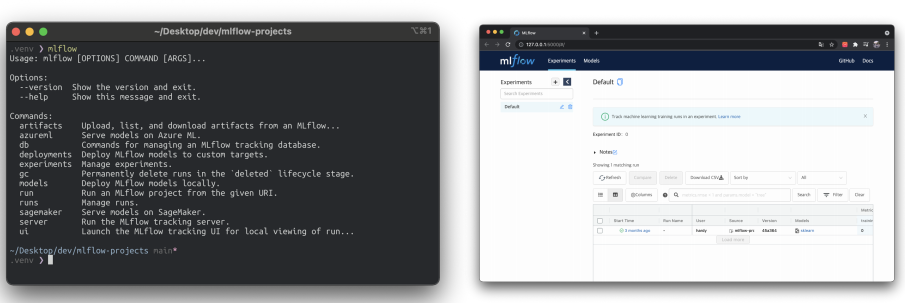
CLI, GUI 지원
- CLI : 터미널에서 사용하는 어떤 명령어를 쓸지 보이는 것
- GUI : 웹 인터페이스가 지원됨
MLflow의 핵심 기능
- 집에서 요리를 만들 때, 레시피를 기록해야 어떤 조합이 좋은지 알 수 있는 것처럼 파라미터, 모델 구조 등을 기록하는데 MLflow를 사용한다.
- MLflow에서는 레시피들을 정렬할 수 있고, 제일 맛있었던(성능이 좋았던) 레시피를 찾아 볼 수 있다.
- 또한, 요리를 만드는 과정에서 생기는 부산물을 저장할 수 있다.(=모델 Artifact, 이미지 등)
- 모델은 다양한 종류가 있으므로 언제 만든 모델인지, 성능이 얼마나 나왔는지, 모델에 대한 메타 정보 등을 기록할 수 있다.
- 여러 모델을 운영하면서도 기록할 수 있다.
1) Experiment Management & Tracking
- 머신러닝 관련 “실험”들을 관리하고, 각 실험의 내용들을 기록할 수 있음.
-
여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유할 수 있다.
ex) jupyter notebook 파일을 드려서 피드백을 받는 것이 아닌 MLflow서버에서 제 파일 여기에 있는데 피드백좀 부탁드립니다. 처럼 할 수 있다.
-
2) Model Registry
- MLflow로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록할 수 있다.
- 모델 저장소에 모델이 저장될 때마다 해당 모델에 버전이 자동으로 올라간다. (v1, v2, v3...)
- Model Registry에 등록된 모델은 다른 사람들에게 쉽게 공유 가능하고, 쉽게 활용할 수 있다.
3) Model Serving
- Model Registry에 등록된 모델을 REST API 형태의 서버로 Serving 할 수 있다.
- Input = Model의 Input
- Output = Model의 Output
- 직접 Docker Image 만들지 않아도 생성할 수 있다
MLflow Component
1) MLflow Tracking
- 머신러닝 코드 실행, 로깅을 위한 API, UI
- MLflow Tracking을 이용해 결과를 Local, Server에 기록해서 여러 실행과 비교할 수 있다(기록하는 Tracking하는 핵심 역할 수행)
2) MLflow Project
- 머신러닝 프로젝트 코드를 패키징하기 위한 표준
- Project에는 소스 코드, requirement, model 등을 프로젝트화 하여 템플릿으로 만들어 두었는데, 의존성과 어떻게 실행해야 하는지 저장되어 있다.
- MLflow Tracking API를 사용하면 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅
3) MLflow Model
- 모델은 모델 파일과 코드로 저장
- 제언이 가능할 수 있도록 만듦과 동시에 pickle파일과 같이 저장
- 다양한 플랫폼에에 배포할 수 있는 여러 도구 제공
- MLflow Tracking API를 사용하면 MLflow는 자동으로 해당 프로젝트에 대한 내용을 사용함
4) MLflow Registry
- MLflow Model의 전체 Lifecycle에서 사용할 수 있는 중앙 모델 저장소
MLflow 설치
- Experiment
-
맨 처음 MLflow에서Experiment(실험)을 생성
-
하나의 Experiment는 진행하고 있는 머신러닝 프로젝트 단위로 구성
ex) 개/고양이 이미지 분류 실험, 택시 수요량 예측 분류 실험
-
정해진 Metric으로 모델을 평가 (RMSE, MSE, MAE, Accuracy)
-
하나의 Experiment는 여러 Run을 가짐
-
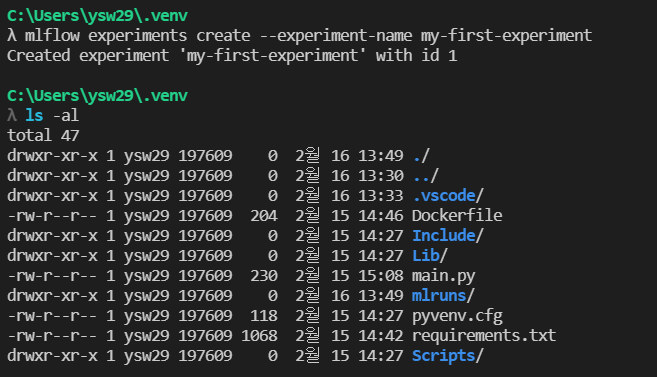
- Experiment 생성
- mlflow experiments create --experiment-name my-first-experiment
- 이후 ls -al을 하게 되면 실행 기록을 담는 mlruns 라는 새로운 폴더가 생성
- Experiment 리스트 확인
- mlflow experiments list

-
모델에 필요한 라이브러리 설치
- pip install numpy sklearn
-
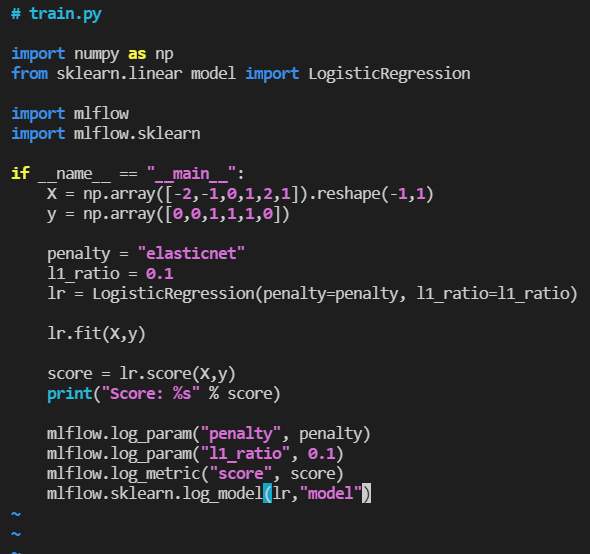
폴더 생성 후 , 머신러닝 코드 생성
- mkdir logistic_regression
- vi logistic_regression/train.py
- vi를 통해 train.py 생성
- 기존의 logisticregression 코드에서 하단에 mlflow logging param 부분만 추가 됨
- 추가로 LogisticRegression의 solver인자에 “saga”를 넣어줘야 돌아간다
- 프로젝트(MLProject) 생성
-
MLflow는 사용한 코드의 프로젝트 메타 정보 저장하고, 프로젝트를 어떤 환경에서 어떻게 실행시킬지 정의하고 requirement들을 기록.
-
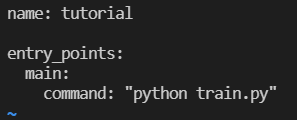
패키지 모듈의 상단에 위치하고, 파일이름을 MLProject로 해야 한다
- Dockerfile을 사용하는 것처럼 고정된 파일 이름을 사용해야 함
-
vi logistic_regression/MLProjcet
-
- Run(실행)
-
하나의 Run은 코드를 1번 실행한 것을 의미
-
즉, 한번의 코드 실행 = 하나의 Run 생성
-
Run을 하면 여러가지 내용이 기록된다
-
Run에서 로깅하는 것들
- Source : 실행한 Project의 이름
- Version : 실행 Hash
- Start & end time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, Metric을 시각화 할 수 있다.
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)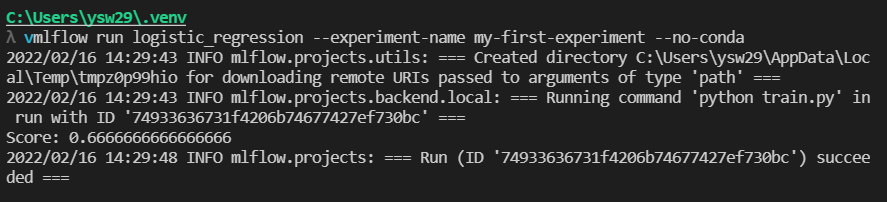
-
-
기록 확인
- mlflow ui를 통해 기록을 확인
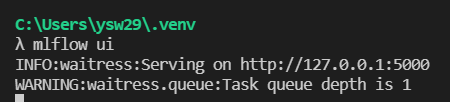
- 해당 포트로 접속하면 mlflow ui가 나타나는데, Experiments와 Experiments ID, RUN 정보 등이 나타난다.
- RUN 정보를 누르면 실행한 RUN 기록이 나타나는데, RUN command, parameter, metrics, tag, artifacts 등을 확인할 수 있다.
- mlflow ui를 통해 기록을 확인
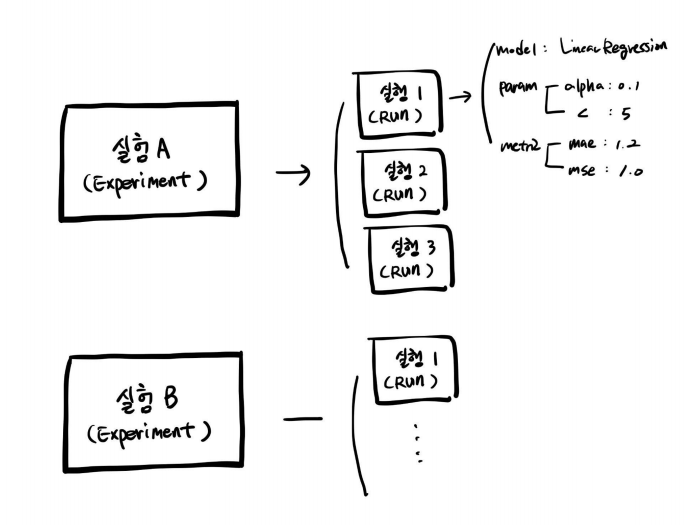
- Experiments와 RUN의 관계
- Experiments는 여러 개를 가질 수 있고, 여러 개의 RUN이 있을 수 있다.
- RUN안에서는 parameter와 metric이 다를 수 있다.
-
Autolog
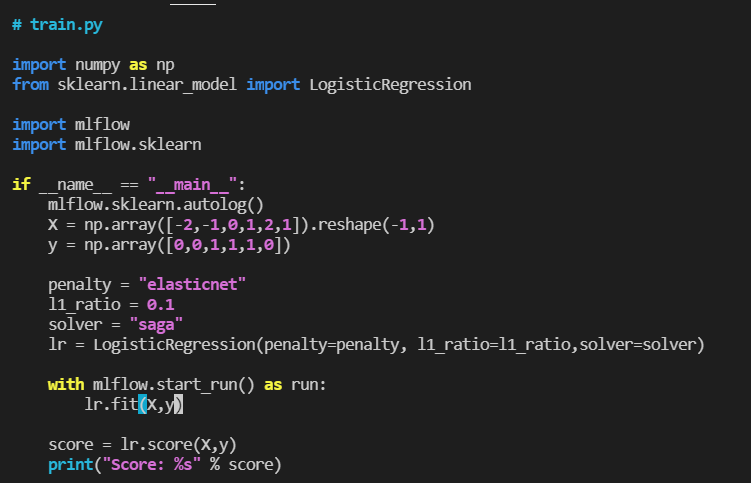
- 파라미터를 매번 명시하다 보면 귀찮을 수 있다.
- 따라서, autolog를 활용해 자동으로 파라미터를 저장
-
Autolog 기록 확인
- 이전 방법과 똑같이 RUN을 하고 ui에서 확인
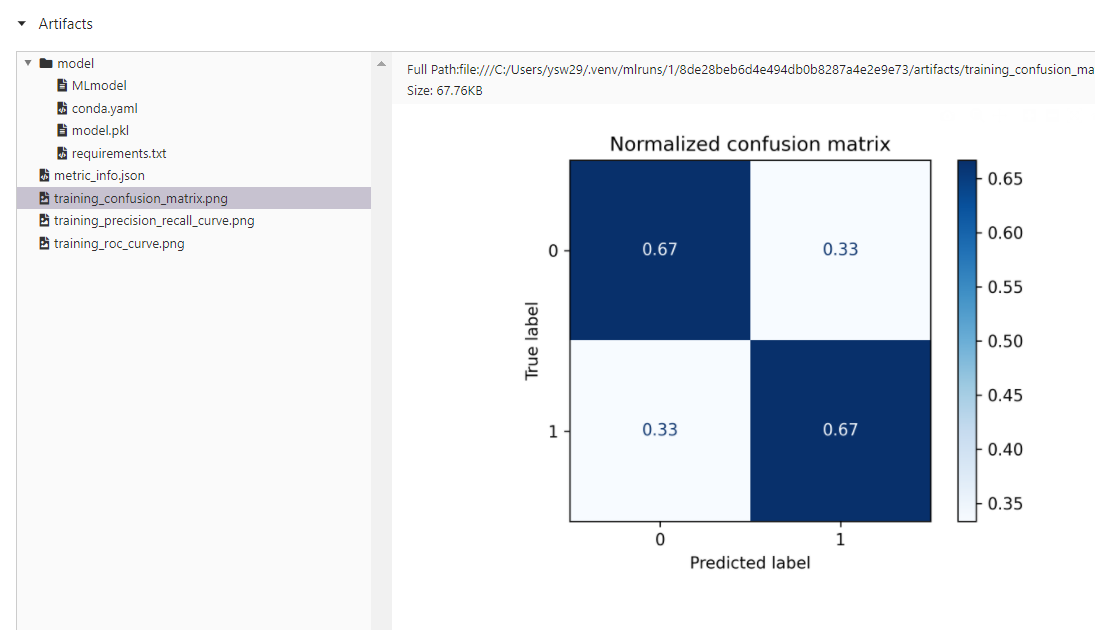
- 기본적인 정보들은 물론 confusion matrix와 precision&recall curve도 자동으로 나타내 주는 것을 볼 수 있다.
- Autolog 주의 사항
- Autolog를 모든 프레임워크에서 사용 가능한 것은 아님
- pytorch.nn.Module은 지원하지 않음.(pytorch Lighting은 지원)
- MLflow에서 지원해주는 프레임워크들
- Scikit-learn
- TensorFlow and Keras
- Gluon
- XGBoost
- LightGBM
- Statsmodels
- Spark
- Fastai
- Pytorch (nn.module은 지원하지 않음)
- MLflow Parameter
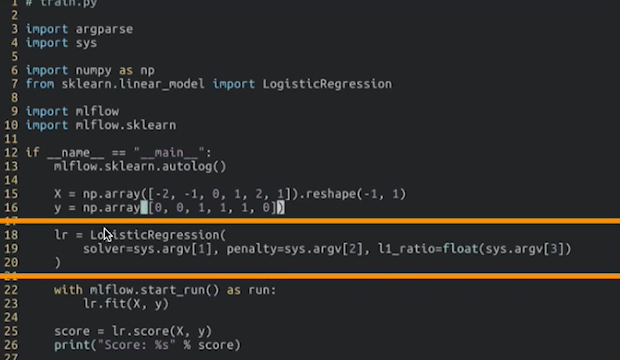
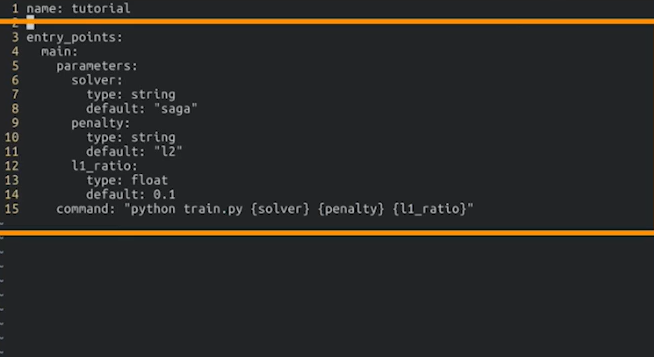
- 매번 파라미터를 저장하고 실행하는 것도 번거롭다고 생각될 경우 sys.argv를 통해 미리 파라미터를 저장해놓고 실행할 수 있다.
-
이후 mlflow run logistic_regression_with_autolog_and_params -P solver=”saga” -P penalty=”elasticnet” -P l1_rate=0.1 —experiment-name my-first-experiment —no-conda 를 통해 실행
-
또한, autolog와 hyper parameter tuning도 같이 할 수 있다.
MLflow 서버로 배포하기
-
파이썬 코드(with MLflow package)
- 모델을 만들고 학습하는 코드
- mlflow run으로 실행
-
Tracking Server
- 파이썬 코드가 실행되는 동안 Parameter, Metric 등 메타 정보 저장
- 파일 혹은 DB에 저장
- 결국엔 데이터를 어디에 저장할 것인가?
- mlflow architecture 들이 지금은 우리의 local에 저장되어 있지만 서버나 DB에 저장하면 공용으로 사용할 수 있다.
-
Artifact Store
- 파이썬 코드가 실행되는 동안 생기는 Model File, Image 등의 아티팩트를 저장
- 파일 혹은 스토리지에 저장
-
MLflow Tracking Server와 외부 Storage 사용하기
- mlflow server 명령어로 Backend Store URI를 지정할 수 있다.
- mlflow server —backend-store-uri sqlite:///mlflow.db —default-artifact-root $(pwd)/artifacts 를 실행하면 mlflow server가 띄워진다.
- MLFLOW_TRACKING_URI를 통해 환경변수를 지정하고, Experiments를 생성 후 RUN을 하면 ui에서 데이터를 확인할 수 있다.
정리
- mlflow run으로 파이썬 코드를 실행
- Tracking Server에 실행 기록을 요청
- Tracking Server가 local이 아닌 DB에 기록이 진행됨
- Artifact Store에 아티팩트가 저장
MLflow 실제 활용 사례
- 보통 회사에서는 Tracking Server를 하나만 운영하기 때문에 하나만 배포하고, 팀 내 모든 Researcher가 이 Tracking Server에 실험을 기록하는데, 작성하는 사람 이름만 다르게 설정하고 나머지 환경변수들은 똑같이 설정한다.
- 배포할 떄는 Docker Image, Kubernetes 등을 통해 진행한다.
- 이렇게 공용 MLflow Tracking Server를 띄움으로써 실험도 많이할 수 있고, 공유도 할 수 있으며, 다운도 쉽게 받을 수 있는 환경을 만들 수 있다.
