선형회귀분석 복습
-
무어 팬로즈 역행렬을 이용해 주어져 있는 데이터와 가장 가까운 선형 모델을 찾을 수가 있다.
-
경사하강법으로 선형회귀 계수 구하기
- 주어진 선형회귀의 목적식을 이해를 하고, 그 목적식을 최소화하기 위해서 미분을 계산할 수 있어야 한다.
- 선형회귀의 목적식은 실제 데이터 y값과 의 차이의 L2-norm의 B를 찾는 것이 목적
-
L2 노름 gradient 계산하기
- 주어진 B 벡터 내에서 k번째 계수에 해당하는 B(k)를 가지고 목적식을 편미분 하는 식
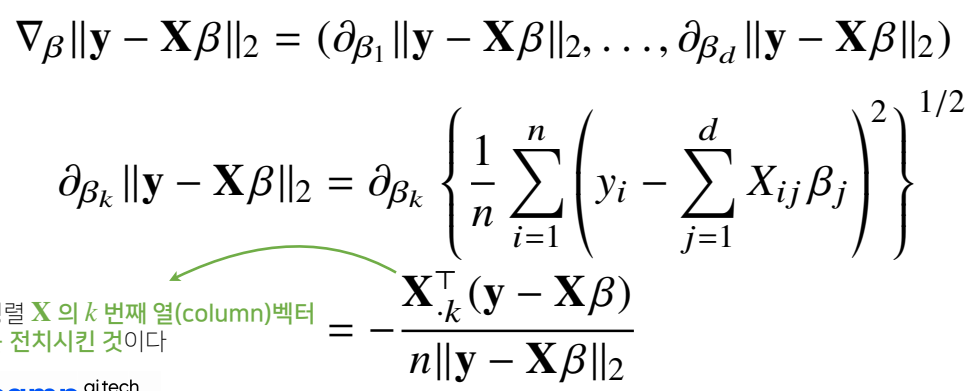
-
여기서 사용되는 L2 노름은 n개의 데이터를 가지고 계산되기 때문에 i = 1 부터 n 까지의 더해준 다음 제곱하는 것이 아닌 평균값을 취해준다음 제곱근을 취해준다.
-
위의 미분결과의 Transpose(X)가 바로 gradient vector
-
손 풀이
-
경사하강법 알고리즘
- 해당 시점의 B에서 gradient vector를 빼면서 업데이트 해나가면 목적식을 최소화할 수 있다. 또한, 학습률인 람다를 통해 수렴 속도를 조절할 수 있다.
- 또한, 선형회귀의 목적식은 L2-norm을 사용하지만, gradient vector를 더 쉽게 계산하기 위해 L2-norm의 제곱을 이용하고, 이를 최소화 하는 B를 구하는 것이 더 편리하다.
- 알고리즘 코드
X = np.array([1,1],[1,2],[2,2],[2,3])
y = np.dot(X, np.array([1,2])) + 3
beta_gd = [10.1, 15.1, -6.5] # [1,2,3] 이 정답
X_ = np.array([np.append(x,[1]) for x in X]) # 절편 추가
for t in range(5000): # 학습횟수
error = y - X @ beta_gd
grad = -np.transpose(X_) @ error
beta_gd = beta_gd - 0.01 * grad # learning rate = 0.01- 알고리즘 학습 방법 중 gradient vector가 일정 값보다 떨어질 때까지 계속 학습하는 알고리즘을 써도 되고, 위의 코드와 같이 일정 시간이나 학습 횟수로 통제해도 괜찮지만, 기준을 적절히 정해야 한다.
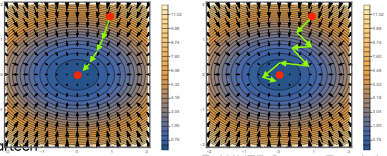
경사하강법은 만능일까?
- 경사하강법은 적절한 학습률과 학습횟수를 선택했을 때 수렴이 보장된다. 또한, 볼록한 함수의 경우에는 gradient vector 가 항상 최소점을 향한다.
- 하지만, 딥러닝에서 사용하는 대부분의 모델과 목적식은 볼록성을 보장하지 못하기 때문에 항상 수렴하지는 않는다.
확률적 경사하강법
-
기존의 경사하강법과 달리 모든 데이터를 사용하여 업데이트하는 것이 아닌 데이터를 한 개 또는 일부분만 사용하여 업데이트 하는 것을 확률적 경사하강법(Stochastic gradient descent)라 한다.
-
SGD는 데이터의 일부(미니 배치)를 가지고 파라미터를 업데이트 하기 때문에 연산 지원을 좀 더 효율적으로 활용할 수 있으면서 기대값인 gradient와 유사한 결과를 뽑아낼 수 있다.
-
또한, 미니 배치 연산을 통해 확률적으로 목적식 모양이 바뀜으로써 지역 최소점이 아닌 전역 최소점에 수렴이 가능해지고, 이를 통해 볼록이 아닌 목적식들을 최적화 할 수 있다.
-
따라서, SGD에서는 학습률, 학습 횟수 외에 미니 배치까지 고려해야 할 필요가 있다.
-
오늘날 딥러닝에서 사용되는 데이터는 사이즈도 크고 양도 많기 때문에, 메모리 과부하가 올 수 있으므로, 미니배치를 통해 효율적인 연산 지원을 하는 SGD가 많이 사용된다.