모델에 데이터를 먹이는 방법
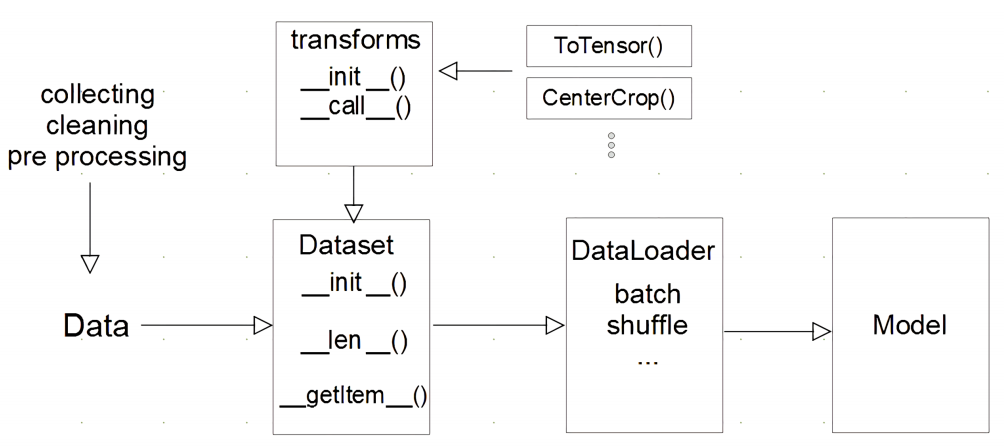
Dataset
- 데이터 입력 형태를 정의하며, 데이터를 입력하는 방식을 표준화한다
- Class를 생성하여 그 데이터 셋을 어떻게 불러올것인지(init) 길이는 얼마인지(len), 하나의 데이터를 불러올때 어떻게 반환을 하는지(getitem)와 같은 입력 형태 정의
- 유의점!
- 데이터 형태와 특징에 따라 각 함수를 다르게 정의
- 모든 것을 데이터 생성 시점에 처리할 필요는 없음
- cpu에서 tensor를 변환하고 gpu에서 학습을 시키기 때문에 컴퓨터는 충분히 시간이 있다. 따라서, image의 Tensor는 학습을 하는 시점에 transfroms을 통해 변환한다.
- transforms : 이미지 같은 데이터를 전처리하거나, data augmentation 할 때 데이터를 변형시킬때 transforms을 처리, 주로 ToTensor()를 통해 Tensor로 변환하는 작업을
- cpu에서 tensor를 변환하고 gpu에서 학습을 시키기 때문에 컴퓨터는 충분히 시간이 있다. 따라서, image의 Tensor는 학습을 하는 시점에 transfroms을 통해 변환한다.
- 데이터 셋에 대한 표준화된 처리방법 제공 필요
- 후속 연구자 또는 동료가 편하게 내 데이터 셋을 처리할 수 있게끔한다.
- 최근에는 HuggingFace 등 표준화된 라이브러리 사용
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels)
def __getitem__(self,idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text" : text, "Class":label}
return sampleDataLoader
-
Data의 Batch를 생성해주는 클래스
- Dataset은 하나의 데이터를 어떻게 가져올지에 대한 것이라면, DataLoader는 인덱스를 가지고 데이터를 묶어서 모델에 던져주는 역할을 한다.
-
학습직전 데이터의 변환을 책임지며, 대부분 이 부분에서 Tensor를 변환한다.
-
Tensor 변환과 Batch처리가 메인 업무
-
parameter
-
sampler / batch_sampler: 데이터를 어떻게 뽑을지 인덱스를 정해주는 기법
-
collate_fn : zero-padding이나 Variable 데이터 등 데이터 사이즈를 맞추기 위해 사용
-
# 글자가 긍정인지 부정인지에 대한 dataset
text = ["Happy","Amazing","Sad","Unhappy","Glum"]
labels = ["Positive","Positive","Negative","Negative","Negative"]
MyDataset = CustomDataset(text,labels)
# iterable한 객체이기 때문에 iter와 next 사용
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
MyDataLoader = DataLoader(MyDataset, batch_size=3, shuffle=True)
for dataset in MyDataLoader:
print(dataset)