조건부확률
- 베이즈 통계학을 이해하기 위해서는 조건부확률의 개념을 이해해야 한다.
- 특정 사건 B가 일어난 상황을 분모로 두고, B가 일어난 사건에서 A가 발생할 상황을 분자로 놓았을 때 B일때 A의 확률을 계산할 수 있다.
P(A∩B)=P(B)P(A∣B)
베이즈 정리
- 베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려준다.
- A라는 정보가 주어졌을 때 P(B)로부터 P(B|A)를 계산하는 방법은 다음과 같다.
P(B∣A)=P(A)P(A∩B)=P(A)P(B)P(A∣B)
베이즈 정리 : 예제
P(θ∣D)=P(θ)P(D)P(D∣θ)
- D : 새로 관찰하는 데이터
- θ : 모델에서 계산하고 싶은 파라미터, 모수
- 사후확률 : P(θ∣D) , 데이터를 관찰한 이후의 측정한 확률
- 사전확률 : P(θ), 데이터가 주어지지 않은 상황에서 θ에 대해 사전에 미리 주어진 가정, 확률
- 가능도(likelihood) : P(D∣θ), 현재 주어진 파라미터(모수 또는 가정)에서 이 데이터가 관찰될 확률
- Evidence : P(D), 데이터 자체의 분포
문제.
COVID-99의 발병률이 10%로 알려져 있다. COVID-99에 실제로 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진될 확률이 1%라고 할 때, 어떤 사람이 질병에 걸렸다고 검진결과가 나왔을 때 정말로 COVID-99에 감염되었을 확률은?
P(θ) = 0.1 (사전확률)
P(D∣θ) = 0.99 (가능도)
P(D∣θ′) = 0.01 (가능도)
P(D)=∑θP(D∣θ)P(θ) = 0.99×0.1+0.01×0.9=0.108 (evidence)
따라서, P(θ∣D) =0.1×0.1080.99≈0.916
Evidence = P(D)=∑θP(D∣θ)P(θ) =0.99×0.1+0.1×0.9=0.189
P(θ∣D) =0.1×0.1890.99≈0.524
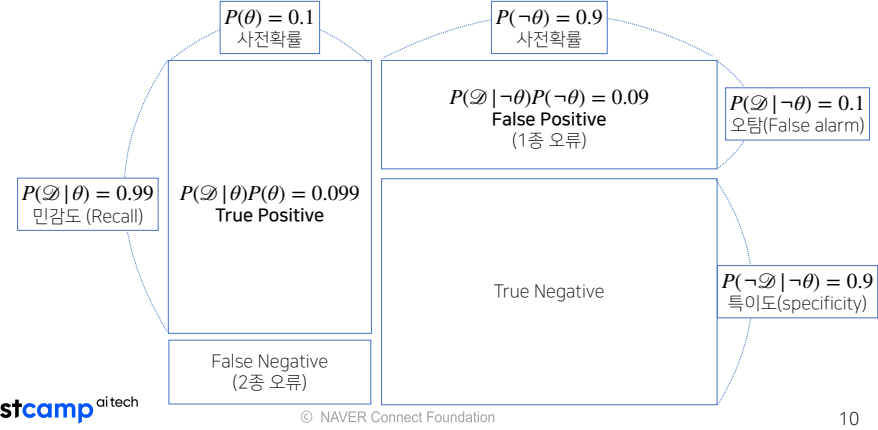
- 민감도(Recall) : 양성으로 진단되었을때, 실제로 양성인 경우(TP)
- 특이도 : 음성으로 진단되었을때, 실제로 음성인 경우(TN)
- 1종 오류 : 양성으로 진단되었을때, 실제로 음성인 경우(FP)
- 2조 오류 : 음성으로 진단되었을때, 실제로 양성인 경우(FN)
베이즈 정리를 통한 정보 갱신
- 베이즈 정리를 통해 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산할 수 있다.

- 앞서 COVID-99판정을 받은 사람이 두 번째 검진을 받았을 때도 양성이 나왔을 때 진짜 COVID-99에 걸렸을 확률은?
P(θ∣D) =0.1×0.1890.99≈0.524 = P(θ) (사전확률)
P(D∗)=∑θP(D∣θ)P(θ) = 0.99×0.524+0.01×0.476=0.566 (evidence)
P(θ∣D) =0.524×0.5660.99≈0.917
조건부확률 → 인과관계
- 조건부 확률은 유용한 통계적 해석을 제공하지만 인과관계를 추론할 때는 함부로 사용해서는 안된다.
- 데이터가 아무리 많아져도 조건부 확률만으로 인과관계를 추론하는 것은 불가능하다.
- 인과관계는 데이터 분포의 변화에 강건한(robust한) 예측모형을 만들 떄 필요하다

-
인과관계만으로는 높은 예측 정확도를 얻는 것은 어렵지만, 로버스트한 모형을 만들 수 있다.
-
인과관계를 알아내기 위해서는 중첩요인의 효과를 제거하고 오로지 원인에 해당하는 변수만의 인과관계를 계산해야 한다.
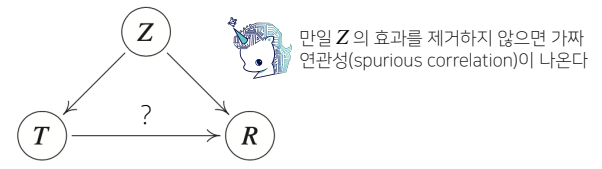
ex ) T를 ‘키’라고 하고 R을 ‘지능 지수’라 할 때, 키가 클 수록 지능이 높아진다는 효과가 나올 수 있는데, 이 효과는 열량과 나이와 같은 Z의 효과를 제거하지 않았기에 나타난 것이다.
인과관계 추론 : 예제
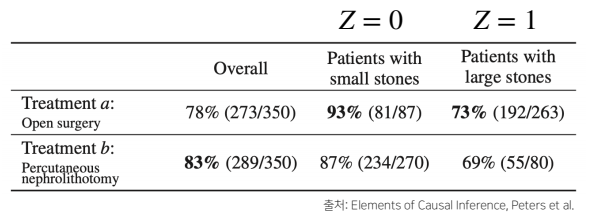
문제. 치료법 a와 b 중 어떤 것이 더 나은가?
- 조정 효과를 통해 Z의 개입을 제거하여 완치율을 계산한 결과는 다음과 같다.
Pa(R)=8781×700(87+270)+263192×700(263+80)≈0.8325
Pb(R)=270234×700(87+270)+8055×700(263+80)≈0.7789
- 베이즈 정리로 계산한 결과는 a가 78%, b가 83%로 나타났는데, 신장 결석의 효과를 제거한 인과관계로 추론한 결과는 a가 83%, b가 77%로 나타났다.
- 인과관계를 고려해서 중첩효과를 제거해 데이터 분석을 할 경우 조금 더 신뢰도가 높고, 안정적인 결과를 얻을 수 있다.
