끊임없이 실험들을 정리를 하고 그것을 바탕으로 좋은 모델을 찾아내는 것을 Hyperparameter tuning이라 한다.
좋은 모델을 찾아내는 방법
- 모델을 바꾼다
- 데이터를 추가하거나 오류가 있나 확인하고 바꾼다
- Hyperparameter tuning
- 일반적으로 가장 좋은 성능을 내는 것은 2번으로 데이터가 가장 중요하다.
- 1번의 경우 요즘에는 이미 대부분의 좋은 모델을 알기 때문에, 그렇게 중요하지 않다.
Hyperparameter Tuning
-
모델 스스로 학습하지 않는 값은 사람이 지정(learning rate, model(batch) size, optimizer 등)
-
한 때는 hyperparameter에 의해 값이 크게 좌우 될 때도 있었지만, 요즘에는 그렇지 않다.
-
최근에는 베이지안 기반 기법들이 주도하고있으며, 가장 기본적인 방법으로는 grid 와 random이 있다.
-
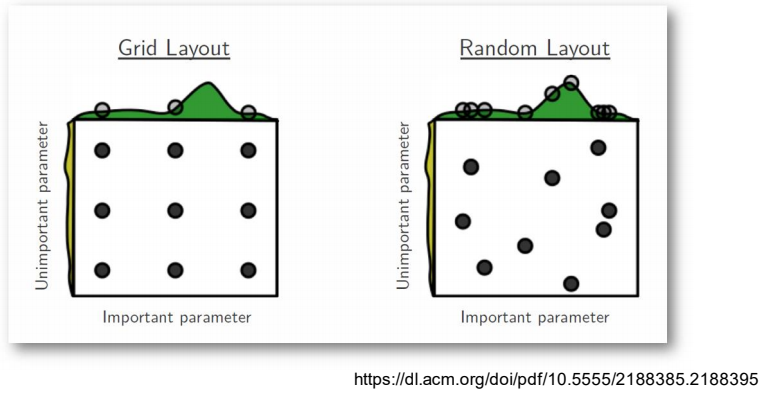
grid
- grid search는 어떠한 값들을 hyperparameter tuning으로 찾을 때 그 값들을 일정한 범위를 정해서 값을 자르는 것
-
random
- 값 들을 랜덤으로 아무거나 찾아보고, 그 중에서 가장 잘 나온 것을 찾는 것
Ray
- 하이퍼 파라미터 튜닝을 위한 여러 가지 도구 중 가장 대표적인 도구
- multi_node multi processing 지원하며 ML/DL의 병렬 처리를 위해 개발된 모듈으로 현재의 분산병렬 ML/DL 모듈의 표준이다
data_dir = os.path.abspath("./data")
load_data(data_dir)
# config에 하이퍼 파라미터 search space 지정
config = {"l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])}
# 학습 스케줄링 알고리즘 지정
scheduler = ASHAScheduler(metric="loss", mode="min", max_t=max_num_epochs,
grace_period=1,reduction_factor=2)
# 결과 출력 양식 지정
reporter = CLIReporter(metric_columns=["loss", "accuracy", "training_iteration"])
# 병렬 처리 양식으로 학습 시행
result = tune.run(partial(train_cifar, data_dir=data_dir),resources_per_trial={"cpu": 2, "gpu": gpus_per_trial},
config=config, num_samples=num_samples,scheduler=scheduler,progress_reporter=reporter)- tune.run() : 병렬 처리 양식으로 학습 시행
- partial(train_cifar) : 데이터를 쪼개서 train_cifar이라는 함수를 학습할 때 실행
- resources_per_trial : 한번 trial 할 때 쓸 수 있는 cpu와 gpu에 사용할 수 있는 개수
