Abstract
논문은 큰 이미지 인식 설정 시 Convolution 네트워크의 깊이가 정확도에 미치는 영향을 조사한다. Vggnet은 3x3의 작은 filter들을 이용하여 네트워크를 점점 깊게 쌓으며 검증하였고, 그 결과 상당한 개선이 이루어졌다. 또한, vggnet을 이용해 ImageNet Challenge 2014에서 classification 2위를 차지했다고 한다.
Introduction
Convolutional networks는 ImageNet과 같은 큰 공공의 이미지 저장소와 GPU와 같은 고성능 컴퓨팅 시스템 덕분에 큰 이미지와 비디오 인식 분야에서 큰 성공을 거두었다. 특히, 심층적인 시각적 인식 아키텍처의 발전에는 ILSVRC와 같은 대규모 시각적 인식 대회가 큰 역할을 하였다.
ConvNets가 컴퓨터 비전 분야에서 더욱 상용화됨에 따라, 더 나은 정확도를 얻기 위해 Krizhevsky 등(2012)의 원래 convnet구조를 개선하려는 여러 시도가 있었다. 이 논문에서는 ConvNet 구조의 깊이에 집중하며, parameter를 수정하고, conv layer를 더 추가하여 네트워크의 깊이를 꾸준히 높인다. 모든 layer에서 매우 작은(3×3) 컨볼루션 필터를 사용하는 것으로 이를 실현 가능케 하였다.
결과적으로, image classification 및 loclalisation task에 대한 sota 정확도를 달성했을 뿐만 아니라 다른 이미지 인식 데이터 세트에 적용할 수 있는 훨씬 더 정확한 ConvNet 구조를 만들었다고 한다.
ConvNet Configurations
Conv layer의 깊이에 따른 효과를 검증하기 위해 모든 conv layer는 똑같은 방법으로 설계되었다.
Architecture
훈련 시 입력 데이터는 convnet은 224 x 224 고정된 RGB 이미지를 사용하였으며, 전처리 시에는 각 픽셀에 고정된 RGB 평균 값을 빼서 사용하였다.
일부 배열은 1 x 1 conv filter를 사용하여 비선형성을 띄게 하였고, padding을 이용해 크기를 동일하게 유지하였다.
conv layer층 다음에는 3개의 fc layer를 배치하였고, 4096 채널을 갖는 첫 번째와 두 번째 fc layer와 마지막 1000개의 채널과 softmax를 적용하는 layer로 이루어져 있다. 모든 hidden layer는 ReLU activation function을 사용하였으며, AlexNet의 LRN은 모델에 영향을 주지 않기 때문에 사용하지 않았다.
Discussion
VGG 연구팀은 깊이에 따른 성능을 비교하기 위해 서로 다른 깊이의 모델을 만들어 성능을 비교하였다.
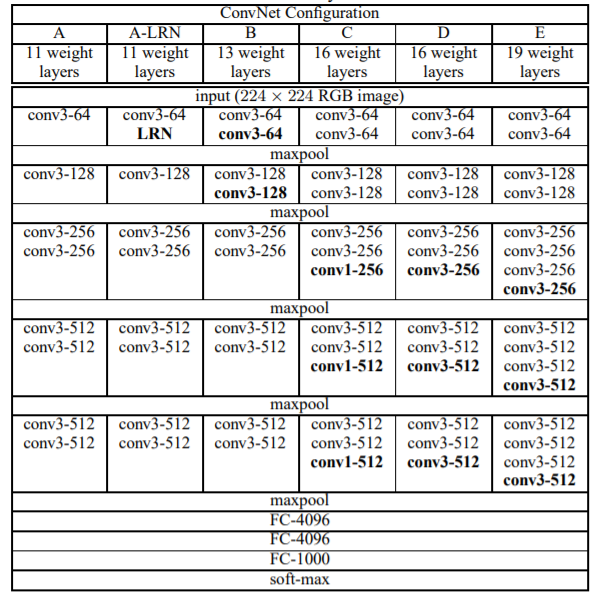
Vggnet은 오직 stride = 1, 3 x 3 filter만 사용하며, 이를 통해 모델을 깊게 쌓을 수 있었으며,아래와 같이 파라미터를 줄이는 효과를 이루었다.
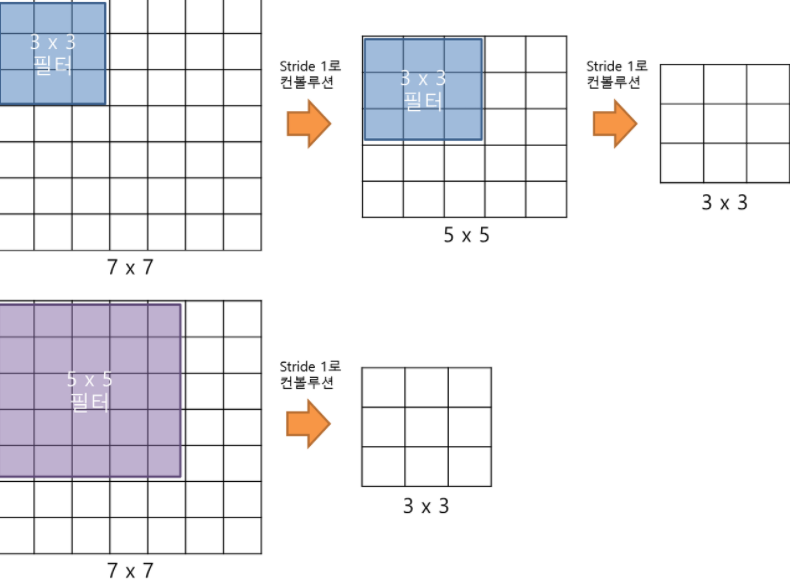
위의 사진과 같이 3 x 3 filter를 두 번 적용한 뒤의 하나의 사각형에는 원래 이미지의 5 x 5 만큼의 정보량이 담겨있는 것과 같다. 세 번을 적용한다면 한 사각형 당 7 x 7 만큼의 정보량이 포함된 것과 같다.
따라서, 7 x 7 filter를 쓰는 것보다는 3 x 3 filter를 세 층을 쌓는 것이 더 효율적이며 각 층마다 ReLU함수를 사용하기 때문에 레이어가 증가할수록 비선형성이 증가하여 더 다양한 특징을 추출할 수 있는 효과가 있다.
<
Train
훈련은 미니 배치 경사하강법을 사용하여 multinomial logistic regression objective를 최적화하는 것으로 진행하였다. 각 배치는 256 크기를 가지며, momentum 0.9와 weight_decay = 0.0005를 사용하였고, dropout은 0.5로 설정하였으며 첫 번째와 두 번째 fc layer에서 사용하였다. learning_rate는 초기에 0.01로 설정하였으며, 검증 정확도가 더 이상 향상되지 않으면. 10배만큼 감소 시켰다. 종합적으로, 학습은 총 3번의 lr 감소가 있었으며 74 epoch만큼을 실시하고 멈추었다.
또한, 잘못된 초기값 설정은 학습을 지연시키기 때문에, 평균이 0 분산이 0.01인 정규분포에서 추출하여 초기화를 하였다고 한다.
batch_size = 256
momentum = 0.9
weight_decay = 0.0005
learning_rate = 0.01
dropout = 0.5
Augmentation
- training image size
- 입력 size를 [256,512] 사이의 크기로 랜덤 resize를 통해 다양한 크기의 image를 학습
- 논문에서는 빠른 학습을 위해 384 크기를 갖는 이미지로 pretrained된 모델을 fine-tuning함으로서 학습시켰다.
- 224 x 224 크기로 random crop하고, horizontalflip을 사용
- 무작위 RGB 색 변경
Vgg-16
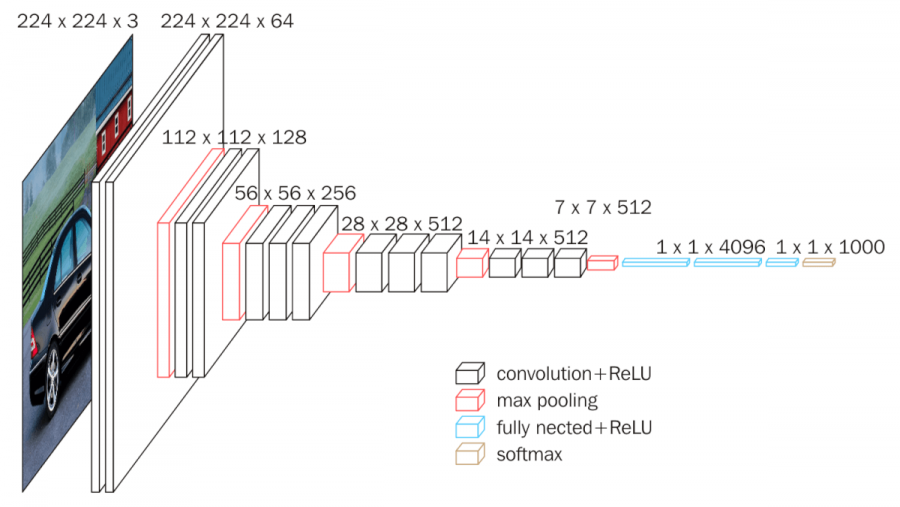
검은색 사각형은 conv layer를 의미하며 빨간색 사각형은 maxpooling을 의미한다.
각 layer는 padding = 1 , stride = 1을 적용했으며 3 x 3 filter와 ReLU함수를 사용하였다. 또한, 2 x 2 max pool에 stride 2를 적용하였다.
첫 번째와, 두 번째 layer에는 conv layer가 2개씩 쌓여져 있으며, 이후에는 3개씩 쌓여져 있다.
첫 층에는 3 x 3 filter 64개를 이용해 224 x 224 x 64의 feature map 생성
이후는 다음과 같다.
| layer | input | filter | stride | padding | activation | output | dropout |
|---|---|---|---|---|---|---|---|
| 1 conv, maxpool | 224 x 224 x 64 | 3 x 3 x 128 | 1 | 1 | ReLU | 112 x 112 x 128 | |
| 2 conv, maxpool | 112 x 112 x 128 | 3 x 3 x 256 | 1 | 1 | ReLU | 56 x 56 x 256 | |
| 3 conv, maxpool | 56 x 56 x 256 | 3 x 3 x 512 | 1 | 1 | ReLU | 28 x 28 x 512 | |
| 4 conv, maxpool | 28 x 28 x 512 | 3 x 3 x 512 | 1 | 1 | ReLU | 14 x 14 x 512 | |
| 5 conv, maxpool | 14 x 14 x 512 | 3 x 3 x 512 | 1 | 1 | ReLU | 7 x 7 x 512 | |
| 6 fc | 7 x 7 x 512 | ReLU | 25088 → 4096 | 0.5 | |||
| 7 fc | 4096 | ReLU | 4096 → 4096 | 0.5 | |||
| 8 fc | 4096 | softmax | 1000 |
