YOLO
- Region proposal 단계가 없고, 전체 이미지에서 bounding box 예측과 classification을 동시에 예측한다.
- 따라서, 이미지 또는 물체를 전체적으로 관찰하여 추론하는 것으로 맥락적 이해가 높은 모델이다.
| version | 특징 |
|---|---|
| Yolo v1 | 하나의 이미지의 Bbox와 classification 동시에 예측하는 1 stage detector |
| Yolo v2 | 빠르고 강력하고 더 좋게 3가지 측면에서 model 향상 |
| Yolo v3 | multi-scale feature maps 사용 |
| Yolo v4 | 최신 딥러닝 기술 사용(BOF : Bag of Freebies , BOS: Bag of Specials) |
| Yolo v5 | 크기별로 모델 구성(Small, Medium, Large , XLarge) |
Abstract
CNN의 정확도를 향상시키는 feature들은 많이 있지만 특정 모델과 문제 그리고 작은 데이터셋에서만 작동하였다.
이를 대규모 데이터 셋에서 사용하기 위해서는 다양한 feature 조합에 대한 결과와 실제 테스트의 정당성이 필요하다
논문에서는 다양한 feature들 중에 대부분의 모델과 데이터에 적용할 수 있는 기능들은 대표적으로 BN, residual connectivity 와 같은 기능들이 있으며, 추가적으로 아래 기능들이 범용성을 가질 수 있는 feature들 이라고 가정한다.
-
weighted residual connection(WRC)
-
cross-stage partial connection(CSP)
-
cross mini-batch normalization(CmBN)
-
self adversarial training(SAT)
-
mish activation
-
결과적으로 이러한 기능들을 결합하여 MS coco dataset에서 43.5% AP (AP_50 : 65.7%)와 실시간에 가까운 65 FPS를 달성했다고 한다.
Introduction
대부분의 CNN 기반 object detector 들은 recommendation system에서만 사용할 수 있습니다.
예를 들어, 빈 주차 공간을 찾는 모델은 느리고 정확도가 높은 반면 자동차 충돌 경고를 나타내는 모델은 빠르고 부정확하다 것
real-time object detector의 정확도를 향상시키면 recommendation system 뿐만 아니라 자립적인 프로세스 관리와 인력 투입을 감소시킬 수 있다.
최신 Neural Networks 들은 높은 정확도를 가지지만, 실시간으로 작동하지 못하며 큰 mini-batch를 학습하기 위해 많은 수의 GPU가 필요하다는 단점이 존재한다.
이러한 문제를 해결하기 위해 기존의 GPU에서 실시간으로 동작하며, 하나의 GPU만으로 학습할 수 있는 object detector를 만들었다.
따라서, 논문의 주요 목적은 생산 시스템에서 빠른 속도로 동작하는 object detector 를 고안하고 BFLOP를 줄인다기 보다는 병렬 계산을 최적화 하는 것이다.
Yolo v4의 기여
-
효율적이고 강력한 object detection model을 개발하였다.
- 1080 Ti 또는 2080 Ti GPU를 사용하는 모든 사람들은 매우 빠른 속도로 훈련할 수 있으며, 정확한 object detector를 사용할 수 있다.
-
detector를 훈련시키는 동안 최신의 BOF , BOS 기법들이 주는 영향을 검증하였다.
-
single GPU training에 효과적이고 적합하도록 CBN,PAN,SAM 등을 포함한 기법을 수정하였다.
Related work
Object detection models
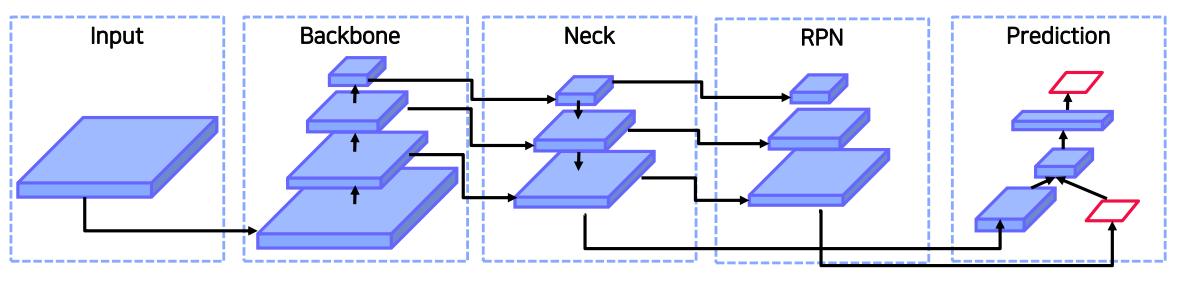
-
Input
- Image, Patches, Image Pyramid
-
Backbone
- Input이 backbone 네트워크를 거치게 되면 semantic을 가지는 feature map으로 변형되어진다.
- GPU platform : VGG-16, ResNet-50, SpineNet, EfficientNet-B0/B7, CSPResNext50, CSPDarkNet53
- CPU platform : SqueezeNet, MobileNet, ShuffleNet
-
Pooling & Neck
-
Backbone과 Head를 연결하는 부분으로, feature map을 재구성하는 단계
-
Additional blocks : SPP, ASPP, RFB, SAM
- spp : neck 정보에서 ROI를 뽑기 위해 고정된 feature size를 얻기 위해 사용
- aspp : neck 정보를 다시 backbone에 넘겨줄 때 사용
-
Path-aggregation blocks : FPN, PAN, NAS-FPN, BiFPN, ASFF, SFAM
- high level feature map과 low level feature map을 섞어주기 위해 사용
-
-
Head
-
Dense Prediction : RPN, YOLO, SSD, RetinaNet, CornerNet, CenterNet, MatrixNet, FCOS
- 1 stage detector 의 경우 RPN이 따로 존재하지 않았기에, feature map의 각 픽셀에 anchor box를 할당해주고 바로 객체의 클래스와 위치에 대해 예측을 진행하였다.
-
Sparse Prediction : Faster-RCNN, R-FCN, Mask R-CNN, RepPoints
- 2 stage detector의 경우 모든 픽셀에서 예측하는 것이 아니라 feature map에서 객체가 있을법한 위치를 추천받는 RPN을 활용했다.
- RPN에서 proposal이 나오게 되면, 이를 feature map에 projection한 뒤 ROI pooling을 통해 각 class, box head에 넘겨주었다.
-
BOF & BOS
- 모델에 적용 가능한 다양한 방법들을 크게 두 가지로 구분하였다.
- BOF(Bag of Freebies) : inference 비용을 늘리지 않고 정확도를 향상시키는 방법
- 하지만 training 단계에서 학습 코스트는 증가할 수 있다.
- BOS(Bag of Specials) : inference 비용을 조금 높이지만 정확도가 크게 향상하는 방법
- e.g.) cascade, deformable rcnn
BOF(Bag of Freebies)
보통 object detector는 offline으로 traning되므로, 연구자들은 이러한 이점을 활용하여 inference 비용을 늘리지 않고도 정확도를 높일 수 있는 더 나은 학습 방법들을 개발하는 것을 선호한다. 이 방법을 BOF라 한다.
BOF는 다음과 같이 3가지 카테고리로 분류된다.

-
Data Augmentation
-
입력 이미지의 variability을 증가시켜 overfitting을 막고, 다른 환경의 이미지에 대해서도 높은 robust를 유지하는 것이 목적
-
Photometric Distortions(color transform)
- brightness, contrast, hue, saturation, noise
-
Geometric Distortions
- random scaling, cropping, flipping, rotating
-
위의 augmentation은 pixel-wise 하게 조정되어, 원래 영역의 픽셀 정보는 유지된다.

-
이외에도 연구자들은 object occlusion 문제를 시뮬레이션 하는데 중점을 두었는데, 이는 classification과 object detection에서 좋은 성과를 보였다
-
object occlusion
- random erase, cutout
- 이미지 내 사각형 영역을 random하게 선택하여 0 또는 random한 값으로 채워 넣는 방법
- hide and seek, grid mask
- 이미지 내 여러 개의 사각형 영역을 random하게 또는 균등하게 선택해 모두 0으로 변경
- random erase, cutout
-
feature map에 object occlusion을 적용한 방법들
- DropOut, DropConnect , DropBlock
-
여러 이미지를 함께 사용하여 데이터를 증가시키는 연구
- CutMix
- 한 이미지의 patch를 다른 이미지에 섞는 방법
- Mixup
- 두 이미지를 아예 섞어버리는 방법
- CutMix
-
위의 연구들 외에도 style transfer GAN을 활용하여 CNN이 학습한 texture bias를 효과적으로 줄였다고 한다.
-
-
Semantic Distribution Bias
-
위에서 제안된 다양한 접근법과 달리, 일부 BOF는 semantic distribution의 bias 문제를 해결하기 위해 사용된다.
-
semantic distribution bias를 다룰 때 매우 중요한 문제는 서로 다른 등급 사이에 데이터 불균형이 있다는 것이다.
- 특히 detection task의 경우 객체보다 배경이 압도적으로 많기 때문에, 이러한 방법들을 이용하면 큰 성능 향상을 가져올 수 있다.
-
hard negative mining
- Negative 를 Positive라고 잘못 예측하기 쉬운 데이터들을 다음 학습에 추가하여 학습하는 방법
-
Focal Loss
- 다양한 범주 간 존재하는 imbalance를 해결하기 위해 제안되었다.
- 어려운 예제로부터는 gradient를 크게 하고, 쉬운 예제는 gradient를 작게 주는 Loss
-
Label smoothing
- 서로 다른 범주 간의 연관 관계를 one-hot 방식으로 표현하기 어렵기에 이를 soft하게 변환하여 model을 robust하게 만드는 label smoothing을 제안
- 잘못된 라벨링이 존재하는 가능성을 고려하는 방법
- 라벨에 0 또는 1로 설정하는 것이 아니라 smooth하게 부여
- 이는 모델의 overfitting을 막아주고 regularization의 효과가 있다.
- 서로 다른 범주 간의 연관 관계를 one-hot 방식으로 표현하기 어렵기에 이를 soft하게 변환하여 model을 robust하게 만드는 label smoothing을 제안
-
-
Bounding box regression
- 기존에는 MSE를 사용하여 bbox의 중심 좌표 또는 각 꼭짓점의 좌표에 대한 회귀를 수행하였다.
- anchor - based 방법에서는 각 중심과 꼭짓점의 offset을 추정하였다.
- 하지만, 이렇게 bbox의 각 point에 대한 좌표값을 직접적으로 조정하려면 각 point들은 independent point여야 하지만, 실제로는 object 무결성이 고려되지 않는다.
-
따라서, 이러한 문제를 개선하기 위해 IOU 기반의 loss를 사용하자고 제안되었다 (GIOU, DIOU, CIOU)
-
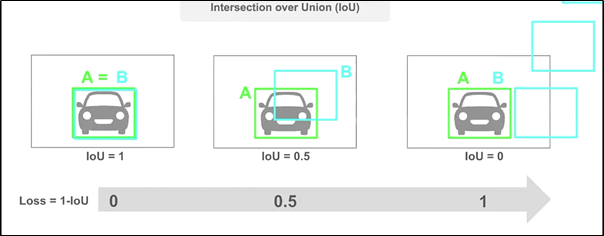
IOU Loss
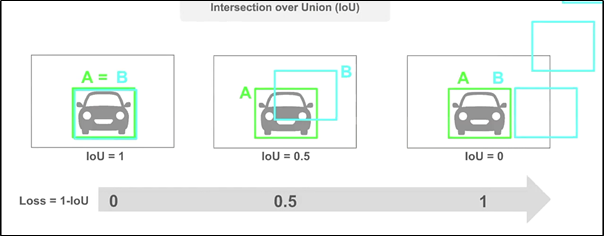
- GT와의 IOU를 높이는 방법으로 학습
- IOU가 0인 경우에 한해서 box가 얼마나 떨어져 있던 간에 모두 IOU가 0으로 나오는 경우가 있다. → box간의 거리가 고려되지 않는다.
-
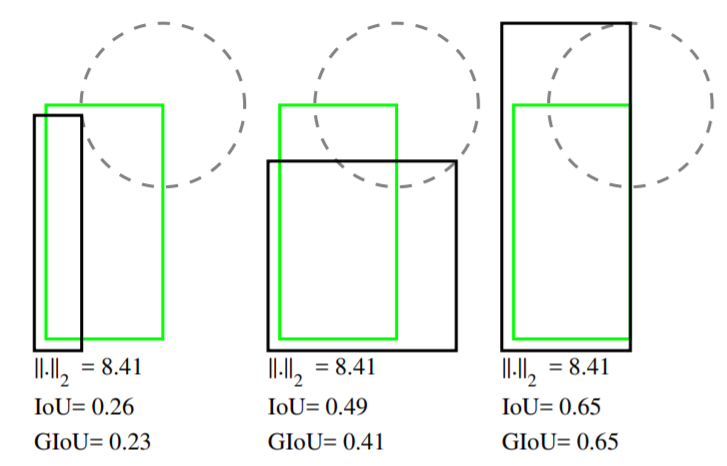
GIOU Loss
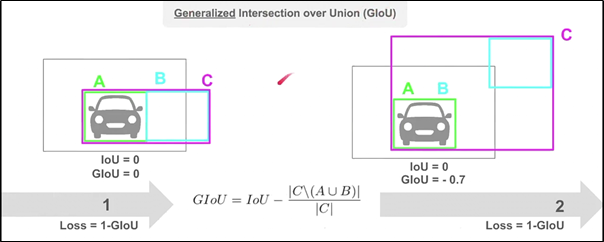
- Bbox 와 GT를 모두 포함하는 최소 크기의 C라는 박스를 활용한다
- 따라서, GIOU loss는 box의 방향을 고려함으로써 gradient vanishing 문제를 개선하였다고 한다.
- 하지만, 여전히 수렴 속도가 느리고 부정확하게 박스를 예측한다는 문제점이 존재한다.
-
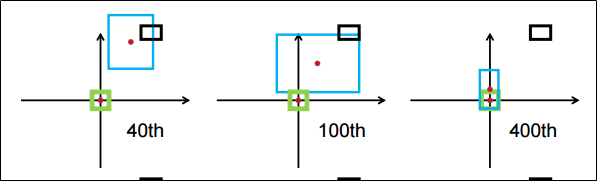
DIOU Loss
-
IOU와 함께 중심점의 좌표를 활용하는 방법
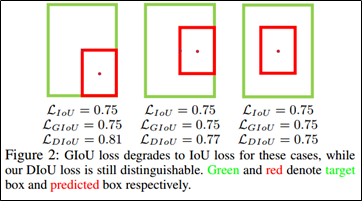
-
GT와 bbox가 겹쳐진 영역이 동일하고, bbox의 위치만 달라졌을 때 IOU,GIOU는 위치정보를 포함하지 않기 때문에 동일하게 나타지만, DIOU는 중심점의 좌표를 고려하기에 값이 달라지는 것을 볼 수 있다.
-
-
CIOU Loss
- overlap area, central point distance, aspect ratio 3가지 요소를 모두 고려하는 것
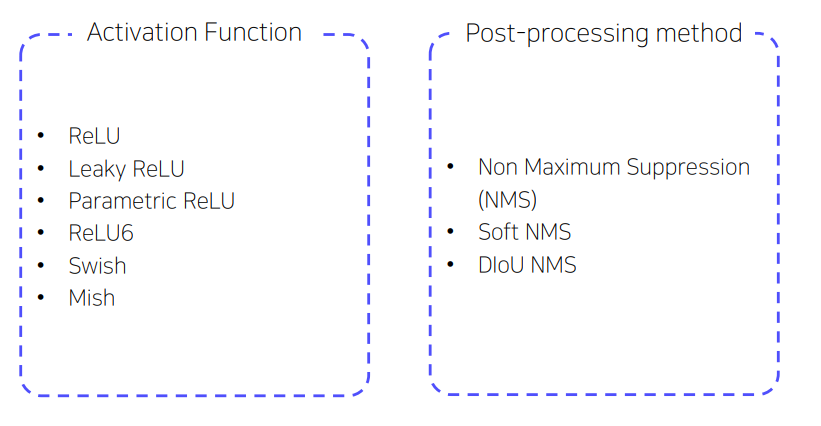
BOS (Bag of Specials)
- BOS는 inference 비용을 조금 높이지만 정확도를 크게 향상시키는 방법으로 다음과 같이 5가지 카테고리로 나눌 수 있다.

-
Enhancement of receptive filed
-
SPP(Spatial Pyramid Pooling)
- Spatial Pyramid Matching에서 유래되었으며, 원래 방법은 feature map을 여러개의 고정된 grid로 분할하여 spatial pyramid를 형성하여 back-of-word연산을 하여 feature들을 추출하였다.
- SPP는 SPM을 CNN에 통합하고 back-of-word 연산 대신 max-pooling 연산을 이용
- 이는 1차원의 feature vector를 출력하므로 Fully convolutional network에 적용할 수 없기 때문에, YOLO V3에서 설계된 k x k kernel size와 stride=1인 max pooling을 concat하는 것으로 SPP module을 개선하였다.
- 비교적 큰 k x k maxpooling이 backbone feature map의 receptive field를 효과적으로 증가시킬 수 있었다고 한다.
- 개선된 SPP 모듈을 추가한 후 YOLOv3-608은 0.5%의 추가 계산 비용으로 MS coco dataset에 대한 AP50을 2.7% 향상시켰다고 한다.
-
ASPP
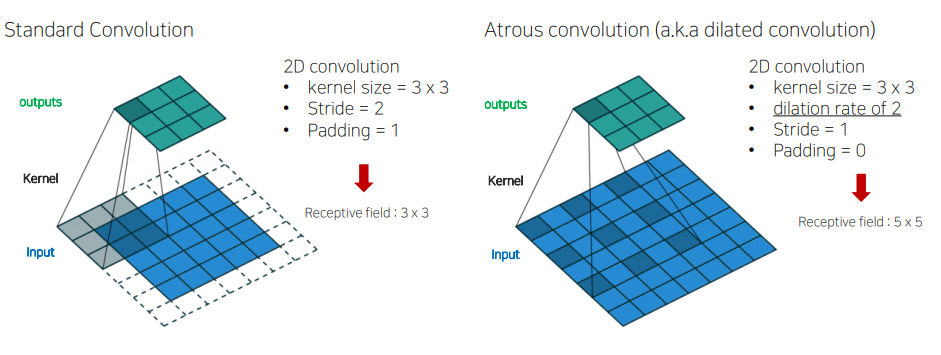
- filter의 각 픽셀 사이의 간격을 두어서 넓은 영역의 특징을 추출하는 것
- SPP와의 작동 차이는 k x k kernel size에서 비롯되며, 3 x 3 kernel size에 대한 max-pooling의 stride는 1이고, dilated rate는 k, dilated convolution 연산 시 stride는 1이다.
-
RBF(Receptive Field Block)
- ASPP보다 더 포괄적인 공간 정보를 얻기 위해 여러 개의 k x k kernel의 dilated convolutions 사용하였다.
- 경량화된 CNN 모델에서 학습된 feature를 강조하여, 빠른 추론 속도와 더불어 향상된 정확도에 기여한 구조
- MS coco dataset에 대해 7%의 추가 inference 시간으로 AP50을 5.7% 향상시켰다고 한다.
-
-
Attention Module
-
Squeeze-and-Excitation(SE)
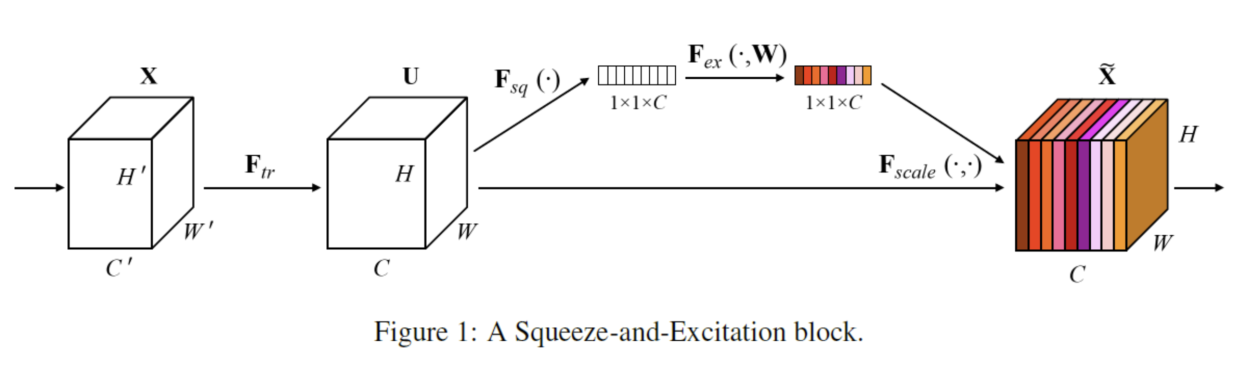
- feature map을 그대로 이용하는 것이 아니라 feature map을 channel 별로 global average 연산을 하여 1 x 1 x C로 만들어주고, 이에 activation 함수를 적용하여 channel별 가중치를 계산한다.
- 이후 이 가중치들을 원래의 feature map과 channel wise하게 곱해주게 되면 각 채널의 중요도가 반영된 feature map이 생성된다.
- 이렇게 함으로써 모델이 중요한 정보를 담고 있는 feature map에 집중할 수 있게 한다.
- 계산 작업을 2%늘리는 대신 ResNet 50의 top-1 성능을 1% 향상시켰지만, inference time을 약 10% 증가시키므로 모바일에서 사용하는 것이 더 적합하다고 한다.
-
SAM(Spatial Attention Module)
- 대표적인 point-wise attention model
- 0.1%의 추가 계산의 수행으로 ImageNet 이미지 분류 task에서 ResNet50-SE의 정확도를 0.5% 향상시킬 수 있었으며, GPU의 inference 속도에 전혀 영향을 주지 않았다.
-
-
Feature Integration
-
low level의 물리적인 feature를 high level의 semantic feature로 통합하기 위해 skip connection 구조 또는 hyper-columne을 사용하였다.
-
FPN과 같은 multi-scale 방법이 인기를 끌면서, FPN 기반의 다양한 경량 모듈이 제안되었다.
-
FPN
-
scale - wise feature aggregation module(SFAM)
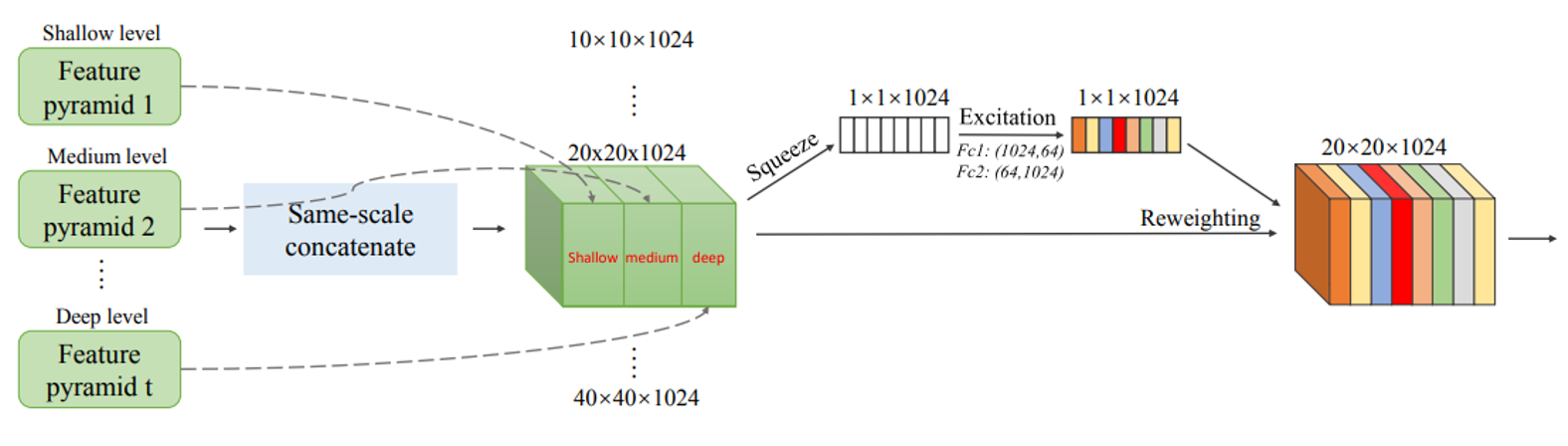
- SE 모듈을 사용하여 multi-scale의 concatenated feature map 상에서 channel-wise level의 re-weighting을 수행
-
adaptive spatial feature fusion(ASFF)
- soft max함수를 사용하여 point-wise level의 re-weighting을 수행하고, 서로 다른 scale들의 feature map들을 추가하였다.
-
BiFPN
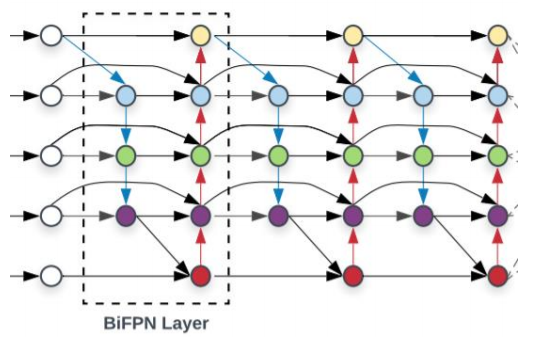
- scale-wise level의 re-weighting을 수행한 후 서로 다른 scale의 feature map들을 추가하기 위해 multi-input의 weighted residual connections가 제안되었다.
-
-
-
Activation function
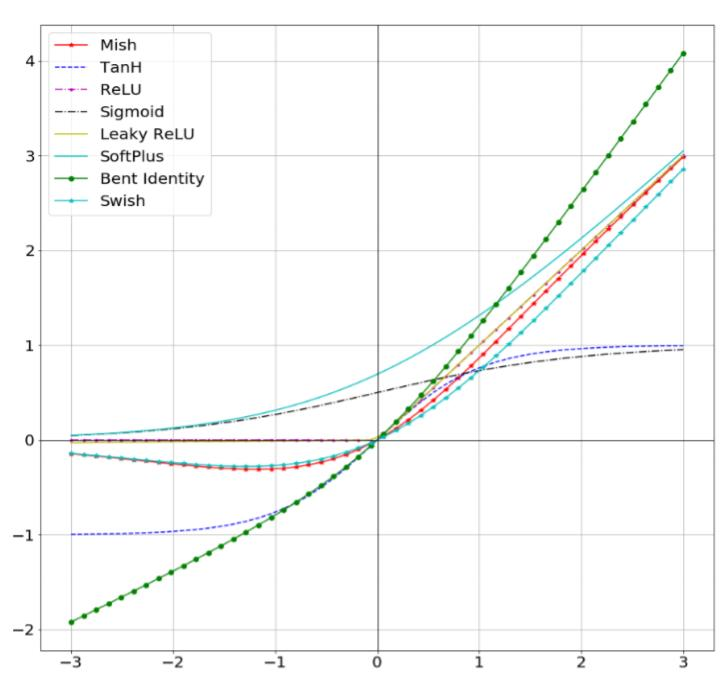
- 좋은 activation 함수는 gradient를 더 효율적으로 전파하는 동시에 너무 많은 계산 비용이 들지 않아야 한다.
- ReLU
- 일반적으로 사용되는 ReLU함수는 sigmoid의 gradient vanishing 문제를 해결하기 위해 등장하였는데, 이는 음수는 전혀 학습하지 못한다.
- Swish / mish
- 약간의 음수를 허용하여 학습하는 방법으로 ReLU의 zero bound보다 gradient 흐름에 좋은 영향을 준다고 한다.
-
Post processing method
-
object detection에서 일반적으로 사용되는 후처리 방법은 NMS이다. 이 방법은 잘못 예측한 bbox를 필터링하고 response가 높은 box만을 유지할 수 있다.
-
NMS가 개선하려는 방법은 목적 함수를 최적화하는 방법과 같다.
-
NMS

- 가장 높은 confidence score를 찾고, 같은 class인 bbox들 중 겹치는 영역이 threshold 이상인 bbox를 제거해서 중복된 detection 결과를 없애는 것
-
soft-nms

- greedy NMS에서 object occlusion으로 인해 confidence score와 IOU score가 저하될 수 있다는 문제를 고려하였다.
-
Methodology
YOLO V4는 연산량(BFLOP)보다는 생산 시스템에서 빠른 속도와 병렬 계산을 최적화 하는 것 목표이기에 real-time 네트워크를 위한 두 가지 옵션을 제시한다.
-
GPU
- convolution layers의 group의 수(1-8)가 작은 모델들을 이용
- CSPResNeXt50, CSPDarknet53
-
VPU
- grouped-convolution은 사용하지만, Squeeze-and-excitement blocks은 되도록 사용하지 않는다.
- EfficientNet-lit, MixNet, GhostNet, MobileNetV3
Selection of architecture
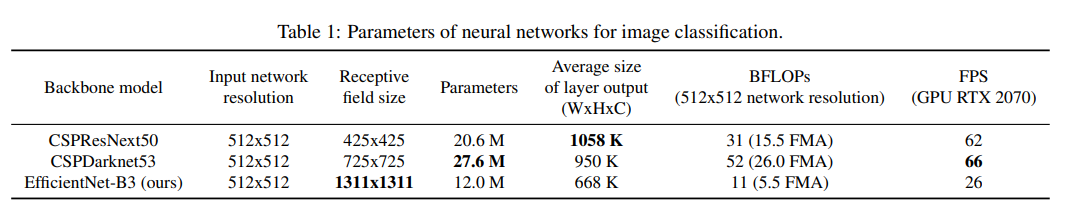
이 실험의 첫 번째 목적은 network의 입력 해상도와, convolution layer의 개수, parameter 개수, layer output의 개수 가운데서 최적의 균형을 찾는 것이다.
- 연구에 따르면 ILSVRC2012(ImageNet) 데이터 세트의 object detection 측면에서 CSPResNext50이 CSPDarknet53에 비해 성능이 뛰어나다.
- 하지만, MS coco 데이터 셋에서는 CSPDarknet53이 CSPResNext50보다 더 우수한 성능을 보였다.
두 번째 목적은 receptive field를 늘릴 수 있는 additional blocks와 다양한 level의 detector와 backbone에서 parameter 집합을 선택하는 최적의 방법을 찾는 것
e.g. ) FPN, PAN, ASFF, BiFPN
classification을 위한 reference model이 detector에도 항상 최적은 아니며, classification과 달리 detector에는 아래와 같은 내용들이 필요하다.
- 작은 물체를 검출하기 위해 resolution이 큰 이미지를 사용
- 네트워크 입력 사이즈가 증가함으로써 큰 receptive field를 필요하게 되었기에 layer의 개수를 늘렸다.
- 하나의 이미지로 다양한 사이즈의 물체를 검출하기 위해 모델 파라미터를 키웠다.
-
receptive filed의 크기가 더 크고, 더 많은 수의 parameter를 가진 모델을 bakcbone으로 선택해야 한다고 가정할 수 있다.
-
크기가 다른 receptive field의 영향
- object 크기를 키우면 더 쉽게 전체적인 object를 볼 수 있다.
- 네트워크 크기가 커지면 object 주변의 context를 많이 볼 수 있다.
- network 크기가 초과되면 image point와 최종 activation 사이의 연결 개수가 증가된다
-
논문에서는 수많은 실험과 함께 CSPDarknet53 이 backbone으로서 최적의 모델임을 보여주었다.
-
Yolo v4는 SPP block을 CSPDarknet53에 추가하여 receptive filed를 대폭 키웠으며, 가장 중요한 context features를 분리하여 네트워크 동작 속도가 거의 저하되지 않았다고 한다.
-
결과적으로 YOLO v4는 CSPdarknet53을 backbone으로 SPP block을 추가했으며, neck으로는 PANet을 사용하고, detection head는 YOLO v3를 따른다
-
연구자들은 Cross-GPU Batch Normalization 또는 고가의 전용 장비를 사용하지 않았으며, 1080ti 또는 2080ti 등의 기존의 GPU를 통해 최신의 결과를 재현할 수 있었습니다.
-
CSPDarknet 53
-
backbone model을 개선하면서 모델의 크기가 커지게 되었고, 성능 향상을 위해서는 어느정도 경량화가 필요하다.
-
따라서, yolo v4 부터는 yolo v2부터 사용하던 darknet의 Cross stage partial이라는 새로운 알고리즘을 변형해서 사용하였다.
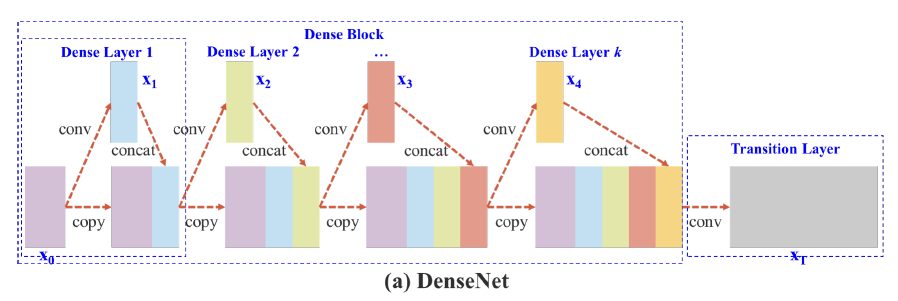
-
기존의 Cross Stage Partial DenseNet은 구조는 다음과 같다.
- input feature map인 X0가 존재하고 X0를 convolution 연산을 통해 X1을 생성한다
- X0과 X1을 channel dimension으로 concat한다.
- 이렇게 concat 된 feature map을 다시 input으로 하여 1번과 2번을 반복한다.
- 최종적으로, Feature map X_T를 만들어 낸다.
-
이러한 구조는 하나의 feature map을 여러 번 사용하기 때문에, 가중치를 업데이트할 때 gradient 정보가 재사용되어 계산량이 많아지는 단점이 존재한다.
-
forward
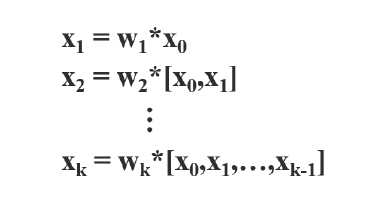
- *는 convolution 연산을 의미하며 는 과 을 결합했다는 의미이다.
-
backward
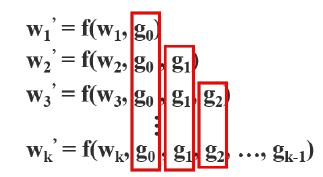
- g0, g1, g2 와 같이 gradient가 재사용된다.
-
-
따라서, Yolo v4에서는 계산량을 줄이기 위해서 이렇게 반복되는 gradient를 줄이는데 집중하였다.
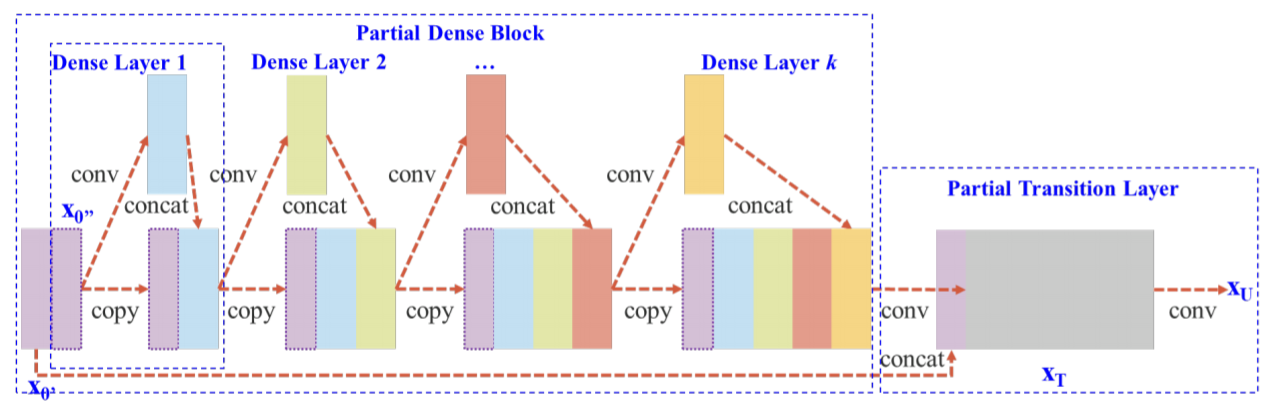
-
yolo v4에서는 X0를 channel기준으로 두 부분으로 나누어서 일반적인 CSPNet과 같이 진행한다.
-
forward
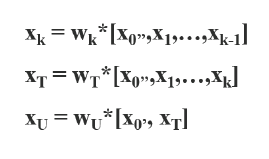
- X_0가 X0’ , X0’’ 두 부분으로 나뉘고, X0’’ 만 conv layer를 통과하여 Densnet의 구조대로 진행된다.
- 이후 생성된 X_T 에 X0’을 concat하여 X_U라는 최종 feature map을 생성한다.
-
backward
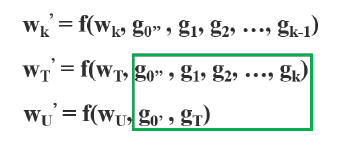
- X_0를 두 개로 분할하여 진행하였기에 gradient도 두 개로 나뉘어 g0’, g0’’각 W_T , W_U에 포함된 것을 볼 수 있다.
- 이를 통해 feature map에 대한 cost를 줄일 수 있고, gradient flow를 나눠주어서 학습에 좋은 영향을 끼친다고 한다.
- CSPNet의 장점은 backbone을 크게 바꾸지 않고, 모든 backbone에 적용할 수 있으며 유명한 모델들의 성능을 향상시켰다.
-
yolo v4에서 사용된 BOF, BOS
- Activations : ReLU, leaky-ReLU,
parametric-ReLU, ReLU6, SELU,Swish, or Mish - Bounding box regression loss : MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation : CutOut, MixUp, CutMix
- Regularization method :
DropOut, DropPath, Spatial DropOut,DropBlock - Normalization : Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter
- Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN)
- Skip-connections : Residual connections, Weighted residual connections, Multi-input weighted
residual connections, Cross stage partial connections (CSP) - Others : label smoothing
Additional Imporvements
설계된 detector를 단일 GPU 훈련에 적합하도록 하기 위해 다음과 같은 추가 설계 및 개선을 수행하였다.
- Mosaic 와 Self-Adversarial Training(SAT) 등의 새로운 augmentation 기법 도입
- genetic algorithms 을 적용하여 최적의 hyper-parameters 선택
- 효율적인 training과 detection을 위해 기존의 기법들을 제안한 detector에 적합하도록 수정
-
Augmentation
-
Mosaic

- Cutmix는 2개의 이미지를 혼합하는 반면 mosaic은 이미지 4장을 하나의 이미지로 혼합
- 하나의 input으로 4개의 이미지를 학습시킬 수 있기 때문에 batch size가 커지는 효과가 있으며, 작은 batch size를 사용하여도 학습이 잘된다
- Cutmix는 2개의 이미지를 혼합하는 반면 mosaic은 이미지 4장을 하나의 이미지로 혼합
-
Self-Adversarial Training(SAT)
- adversarial perturbation이라는 눈에 보이지 않는 오작동을 유도하는 sample들을 활용해 좀 더 robust한 모델을 만들 수 있다.
- 1 stage : 원본 이미지를 변형시켜 이미지 안에 객체가 없어보이게 하는 adversarial perturbation을 추가한다.
- 2 stage : 변형된 이미지를 사용해서 학습한다.
-
-
기존의 기법들을 수정
-
modified SAM
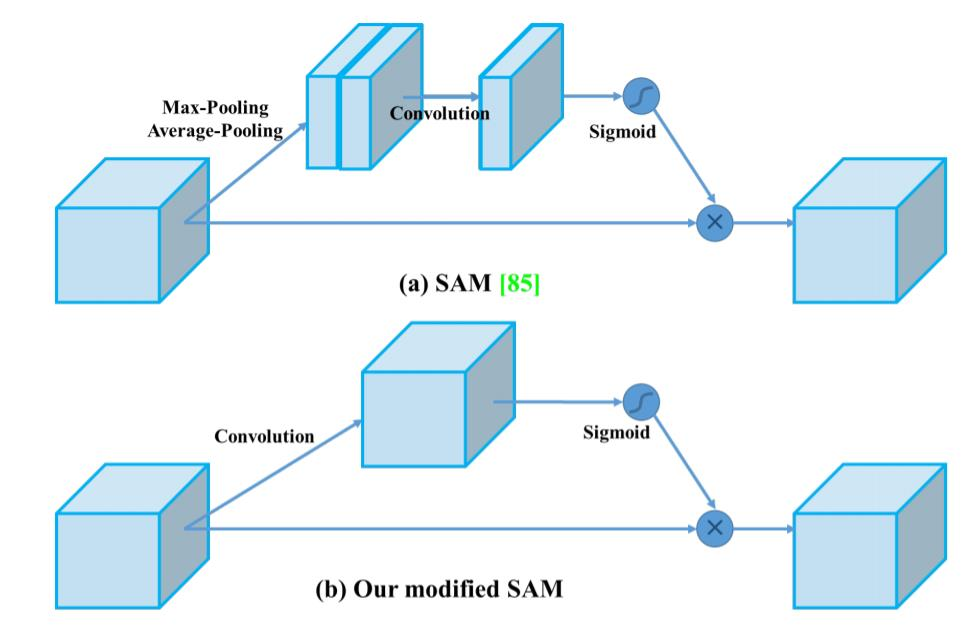
- spatial wise attention을 point wise attention으로 변환하여 사용하였다.
-
modified PAN
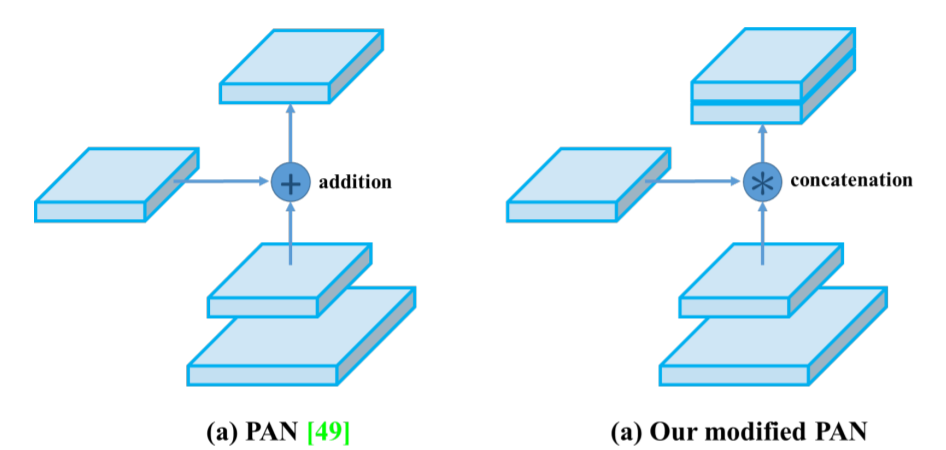
- Add 연산을 concat연산으로 대체하여 사용하였다.
-
Cross Mini-Batch Normalization(CmBN)
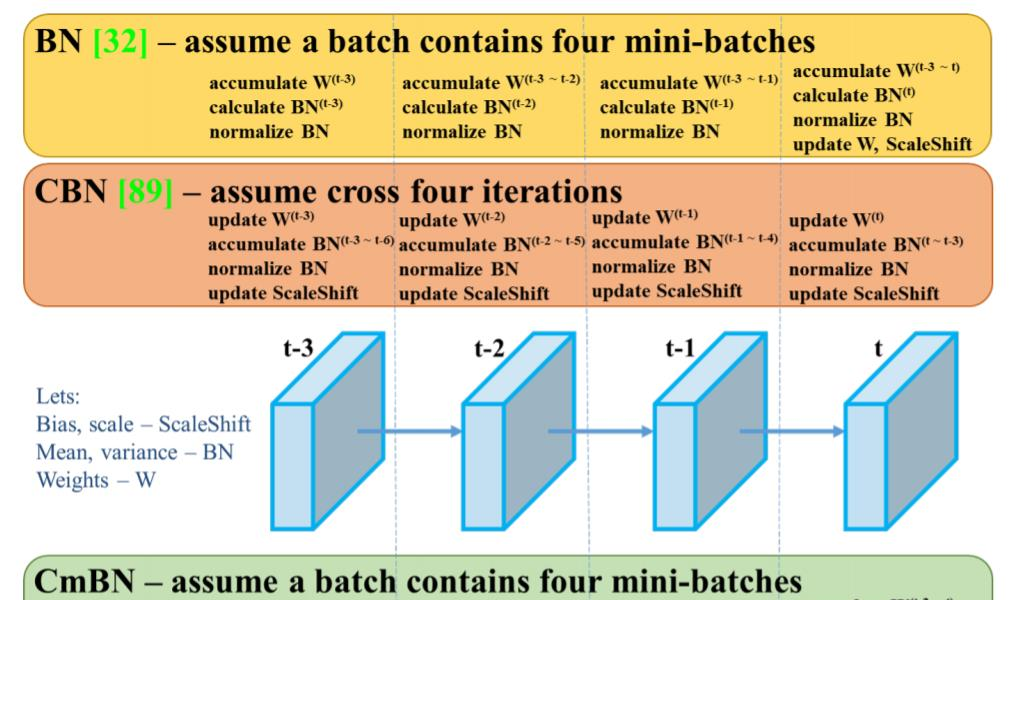
- 일반적인 BN인 경우 각 mini-batch 마다 batch-norm을 계산하였고, 만약 mini-batch size가 적은 경우 적은 sample로 평균과 분산을 추정해야 했다.
- 이에 CmBN은 각 mini-batch에서 batch-norm을 계산하는 것이 아니라 accumulate해서 마치 batch-size가 큰 것 과 같은 효과를 부여했다.
-
최종적으로 사용된 기법들
-
Bag of Freebies (BoF) for backbone
- CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
-
Bag of Specials (BoS) for backbone
- Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
-
Bag of Freebies (BoF) for detector
- CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler [52], Optimal hyperparameters, Random training shape
-
Bag of Specials (BoS) for detector
- Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
Expreriment
- ImageNet 데이터셋을 이용하여 다양한 training 기법들이 classfier의 정확도에 미치는 영향 테스트
- MS coco 데이터셋을 이용하여 다양한 training 기법들이 detector의 정확도에 미치는 영향 테스트
ImageNet을 이용한 Classification 실험
모든 실험은 1080 ti 또는 2080 ti를 이용하여 훈련하였으며 하이퍼 파라미터는 다음과 같다.
- training steps : 8,000,000
- batch size: 128
- mini-batch size: 32
- initial learning rate: 0.1 / polynomial decay learning rate scheduling 전략 적용
- warm-up steps: 1000
- momentum: 0.9
- weight decay: 0.005
BOS : 기본 설정과 동일하며, LReLU, Swish, Mish 등 activation function의 효과를 비교하였다.
BOF : 50%의 training step을 추가하였으며, MixUp, CutMix, Mosaic, Bluring 등 data augmentation과 label smoothing regularization 기법들을 검증하였다.
MS COCO를 이용한 object detection 실험
genetic algorithm을 이용하여 하이퍼 파라미터를 탐색하는 것 외에는 기본 설정과 동일하다.
또한, 하나의 GPU에서만 train하기 때문에, 여러개의 GPU를 이용하여 최적화하는 syncBN등의 기법은 사용하지 않았다.
- default hyper parameter
- training steps: 500,500
- initial learning rate: 0.01 / step decay learning rate scheduling 전략 적용 / 400,000 steps과 450,000 steps에서 각각 0.1을 곱함
- momentum: 0.9
- weight decay: 0.0005
- batch size: 64 / 하나의 GPU로 multi-scale training을 고려
- mini-batch size: 8 또는 4 / 아키텍처 및 GPU 메모리 제한에 따라 결정
- genetic algorithm parameter
- learning rate: 0.00261
- momentum: 0.949
- IoU threshold: 0.213
- loss normalizer: 0.07
BOF : IoU threshold, genetic algorithm, class label smoothing, cross mini batch normalization, self- adversarial training, cosine annealing scheduler, dynamic mini batch size, DropBlock, Optimized Anchors, different kind of IoU losses
BOS : Mish, SPP, SAM, RFB, BiFPN, Gausian YOLO
Influence of different features on Classifier training
먼저, classifier 훈련 시 서로 다른 feature 들이 주는 영향에 대해서 실험하였다.

- Influence of BoF and Mish on the CSPResNeXt-50 classifier accuracy
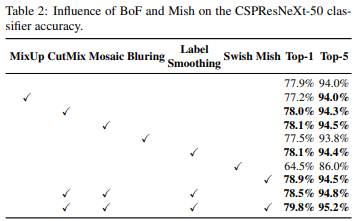
- Influence of BoF and Mish on the CSPDarknet-53 classifier accuracy

Cutmix, mosaic, label smoothing, mish와 같은 feature들을 사용하였을 때 성능이 향상됨
Influence of Different features on Detector training
다양한 BOF가 detector의 정확도에 대한 영향을 실험
FPS에 영향을 주지 않으면서 정확도를 높이는 다양한 기능들을 연구하여 BOF 목록을 크게 확장하였다.
- Ablation Studies of Bag-of-Freebies
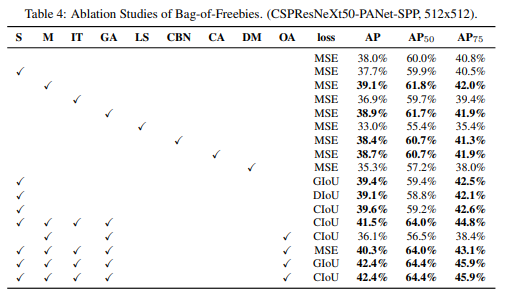
- S : Eliminate grid sensitivity the equation
- sigmoid 에 1.0을 초과하는 계수를 곱해 object가 검출되지 않는 grid의 영향을 제거한다.
- M : Mosaic data augmentation
- IT : IoU threshold
- GA : Genetic algorithms
- 전체 시간 중 처음 10% 기간 동안 network를 학습하여 최적의 hyperparameter 선택을 위해 genetic algorithm 사용
- LS : Class label smoothing
- CBN : CmBN
- CA : Cosine annealing scheduler
- DM : Dynamic mini-batch size
- OA : Optimized Anchors
-
loss를 MSE로 고정시킨 후 다양한 BOF의 실험 결과
- M, GA, CBN, CA 등을 포함하는 것이 성능 향상에 도움이 되었다.
-
GIOU, DIOU, CIOU 에 따른 실험
- CIOU를 사용하는 것이 성능 향상에 도움이 된다.
-
OA 적용유무에 따른 실험
- OA적용하는 것이 성능 향상에 도움이 된다.
-
S, M ,IT, GA, OA를 적용하고 다양한 loss를 비교
- IOU기반의 loss를 적용하는 것이 성능이 좋게 나타났다.
- Ablation Studies of Bag-of-Specials
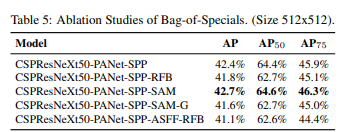
- BOS가 detector 훈련 정확도에 주는 영향을 보기 위해 추가적인 연구를 수행
- SAM을 사용하였을 때 성능이 가장 좋았다.
Influence of different backbones and pre-trained weightings on Detector training
- Using different classifier pre-trained weightings for detector training (all other training parameters are similar in all models)
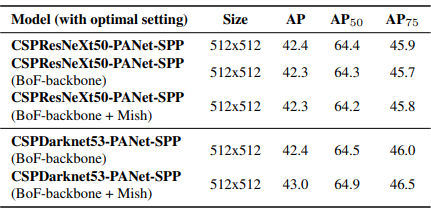
다양한 backbone model들이 detector의 정확도에 주는 영향을 보기 위해 연구를 수행
-
가장 우수한 classification 정확도를 보이는 backbone model이 detector의 정확도에서 가장 우수한 것은 아님을 알 수 있다.
- CSPResNeXt50 모델은 CSPDarknet53 모델에 비해 다양한 기능으로 훈련되어 정확도가 높지만 detector에서 성능이 높은 것은 CSPDarknet53이다.
-
위에서 CSPResNeXt50 classifier train을 위해 BOF와 Mish를 사용하면 classifier 정확도가 높아지는 것을 알 수 있었는데, 이렇게 pre-trained된 weight를 detector에 적용하면 정확도가 떨어진다.
- 그러나 CSPDarknet53에 BOF와 Mish를 사용한 경우는 classfication과 detector의 정확도가 모두 향상되므로, CSPDarknet53이 detector에 더 적합한 모델이다.
따라서, CSPDarknet53은 다양한 개선을 통해 정확도를 향상시킬 수 있는 더 큰 능력을 가지고 있다.
Influence of dfferent mini-batch size on Detector training
- Using different mini-batch size for detector training
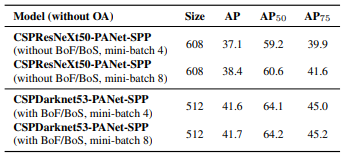
마지막으로, 다양한 mini-batch size로 train시킨 모델을 사용하여 얻은 결과를 비교한다.
두 모델 모두 mini-batch size에 따른 성능 차이가 미미하다.
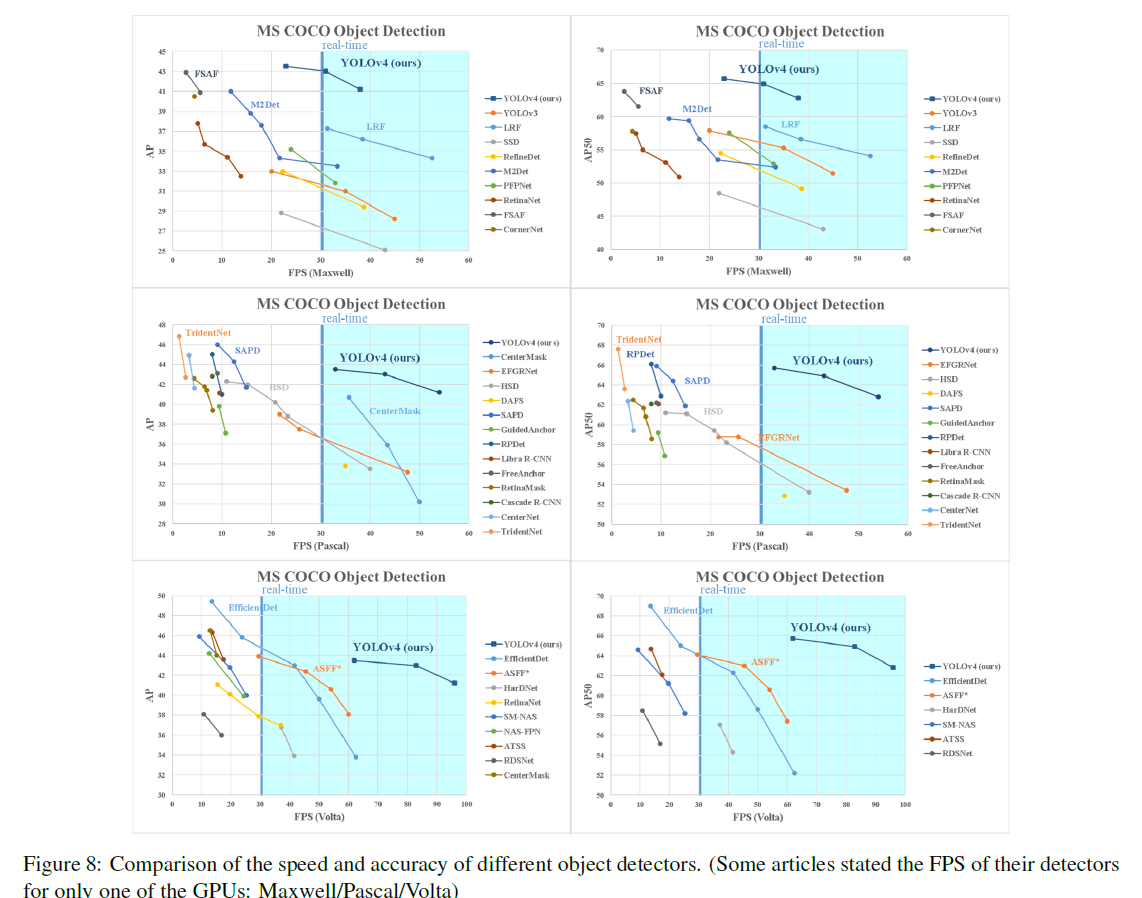
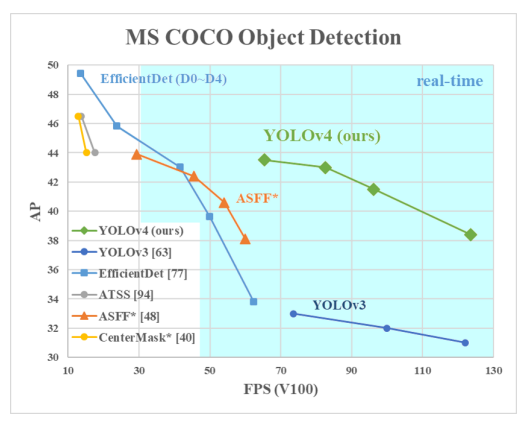
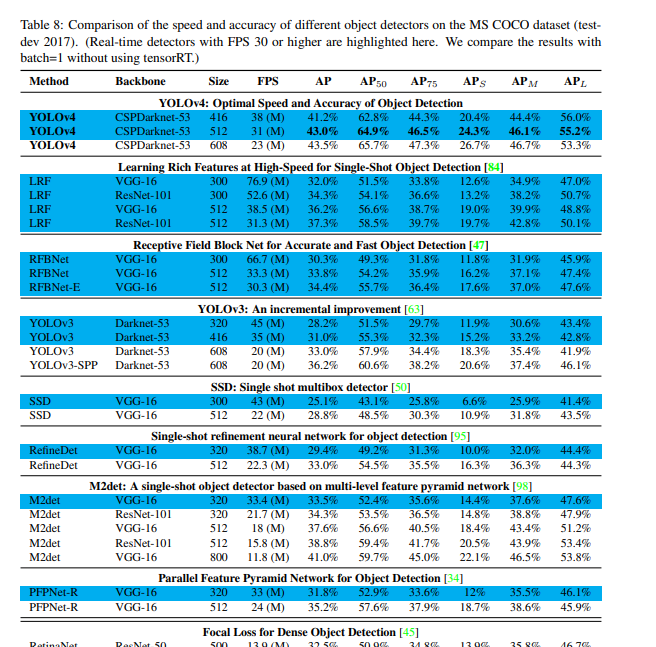
다른 object detector와의 속도와 정확도 비교 결과 속도와 정확도 측면에서 가장 빠르고 정확한 detector임을 볼 수 있다.
- GPU에 따른 다른 object detectors와의 결과 비교
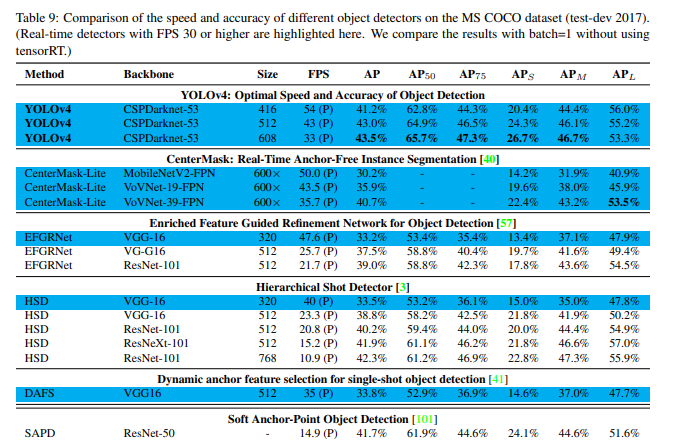
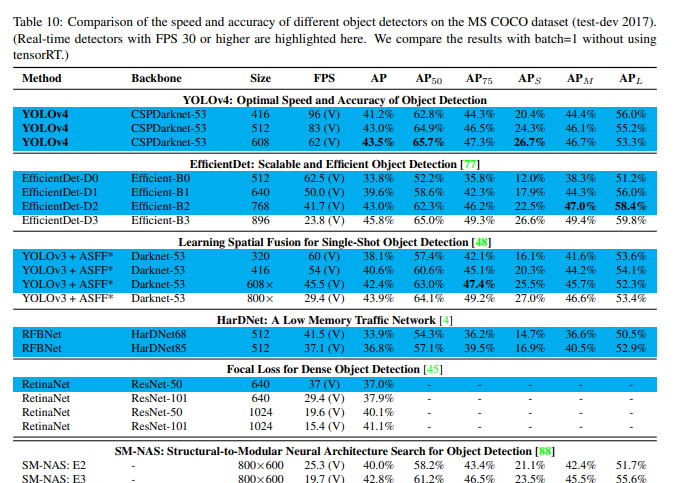
Conclusions
- 사용 가능한 다른 object detector보다 빠르고 정확한 최첨단 object detector를 제공한다.
- 제안된 detector는 8~16 GB의 VRAM으로 기존의 GPU에서 학습 및 사용이 가능하므로 광범위하게 적용이 가능하다.
- one-stage anchor-based detectors의 실행 가능성을 입증하였다.
- classifier와 detector 모두의 정확도 개선을 위해 많은 features들을 검증하여 선택하였다.
- 이러한 실험들은 향후 연구 및 개발을 위한 best-practice 로 사용할 수 있다.
