📌 들어가며
웹 크롤링을 할 때 단순히 URL만 분석해서 데이터를 긁어오면 끝일 줄 알았지만… 막상 해보면 그렇지 않다.
그 이유 중 하나가 바로 웹 페이지의 구조 때문이다.
이번 글에서는 크롤링을 하면서 꼭 알아야 했던 DOM, SPA, 그리고 CSR vs SSR 개념을 나의 쿠팡 리뷰 크롤링 프로젝트 맥락에서 정리해본다.
🔍 DOM이란?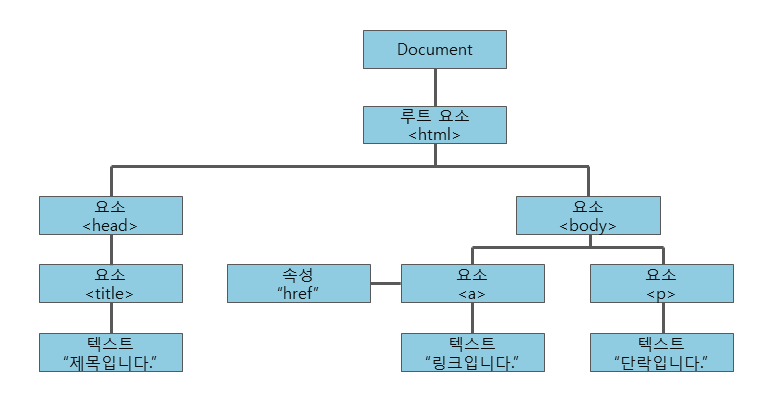
DOM (Document Object Model) 은 브라우저가 HTML 문서를 해석해서 만들어낸 트리 구조다.
- HTML 태그 → JavaScript로 조작 가능한 객체 구조로 바뀜
- 크롤러가 데이터를 추출하는 대상 = 이 DOM 구조
- 예시:
<div class="review">
<span class="user-name">김*민</span>
<p class="content">배송 빠르고 좋아요!</p>
</div>// Puppeteer에서 이걸 긁어오려면
await page.$eval('.user-name', el => el.innerText); // → "김*민"✅ 중요: 우리가 보고 있는 "리뷰"는 단순 텍스트가 아니라 DOM 위에 그려진 동적 객체들이다.
🧠 SPA (Single Page Application)
SPA는 페이지 전체를 새로 불러오지 않고, JavaScript로 필요한 부분만 바꾸는 구조다.
-
쿠팡 리뷰 탭도 SPA 구조를 사용해서, URL은 그대로인데 내부 DOM만 바뀐다.
-
이 말은 즉,
requests.get()으로는 아무것도 안 보임- 실제 데이터를 보려면 JS 실행 → DOM 완성 → 그걸 크롤링해야 함
✅ 결론: SPA는 JS 렌더링 이후의 DOM을 크롤링해야 하므로, Puppeteer나 Playwright 같은 Headless 브라우저가 필수다.
⚔️ CSR vs SSR
| 구분 | 설명 | 크롤링 관점 |
|---|---|---|
| CSR (Client Side Rendering) | JS가 클라이언트에서 DOM 구성 | 렌더링까지 기다려야 함 |
| SSR (Server Side Rendering) | HTML이 서버에서 완성되어 전달됨 | requests로도 가능함 |
- 쿠팡의 리뷰 영역은 CSR 기반 SPA
→HTML엔 데이터 없음
→page.goto()이후waitForSelector()로 DOM이 뜰 때까지 기다려야 함
💡 실전 적용
쿠팡 리뷰 크롤링할 때 DOM 구조를 이해하지 못했다면
- 아무것도 추출되지 않음
- HTML 안에 데이터가 없어서 당황
- 결국 Puppeteer 쓰게 됨 (CSR 대응 + 무한스크롤 처리)
✍️ 마무리
웹 크롤링을 하려면 먼저 웹 구조를 읽는 눈이 필요하다.
그 핵심은 바로 DOM, SPA, CSR vs SSR.
다음 글에서는 이걸 바탕으로 Puppeteer를 활용한 실제 쿠팡 리뷰 크롤러 구현 과정을 정리해보겠다.

일단 하고 보자 (펠리컨적 마인드 ㅠㅠ)