이전에 숫자 Oracle 함수 포스팅에서 중복제거를 하는 DISTINCT 함수에 대해 배웠었죠. 하지만 이처럼 중복 제거를 하는 데에 있어서는 더한 함수들이 있습니다.
중복제거
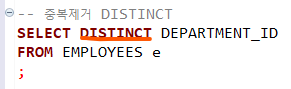
이전에 배웠던 DISTINCT 함수 문제를 응용하여 부서 이름을 중복 없이 불러온 예시입니다. 그렇다면 이보다 더한 함수들은 어떻게 있을까요?
우선, DISTINCT 함수는 데이터를 하나씩만 뽑아와 중복을 제거해준다는 특징이 있습니다. 데이터를 하나하나 검토함으로서 중복을 검사하는 것이죠.
그럼 다른 것들은 어떨까요?
1. Group by
그 다른 것들 중, group by 함수라는 것이 있습니다. 이는 데이터를 말 그대로 그룹핑하여서 받아오는데요. 이를 통해 그룹으로 된 결과를 가져오게 됩니다.
또한, DISTINCT는 집계 함수를 사용할 수 없지만 이 함수는 그와 짝을 이루어 사용할 수 있습니다.

예시로 부서별로 부서 정보를 가져온다고 해봅시다. 이는 부서별 그룹핑을 통해 다음과 같은 결과를 가져옵니다.
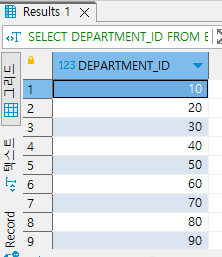
사실 그룹으로 되어있는 것이 없어서 DISTINCT로 보는 것과 크게 다를 바가 없죠.
하지만 이를 계산식으로 작용할 경우는 다릅니다. 한번, 부서별로 합계를 불러오도록 하겠습니다.
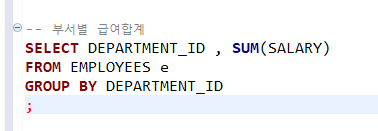
SUM() 에 대한 건 저번에 배웠었죠? 이를 응용해봅시다.
SELECT DEPARTMENT ID, SUM(SALARY)
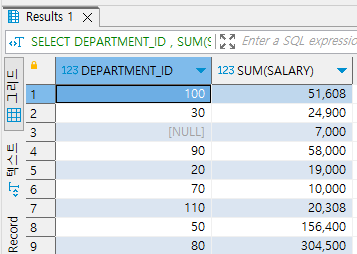
그럼 다음과 같이 부서별로 하나로 그룹핑되어 사원 수까지 다 조회가 됩니다.
2. Having
이와 다른 것으로 HAVING이라는 함수가 있는데요. 이는 자바로 치면 ELSE IF에 해당합니다.
(feat. 습관적으로 대문자로 치게 되는데.. 이게 DB의 힘인가 봅니다.)
이 having 함수는 WHERE 문과 달리 집계 함수를 사용할 수 있는데요. 그를 통해 조건 비교를 하게 되는데요. 이는 GROUP BY 함수와 함께 사용됩니다.
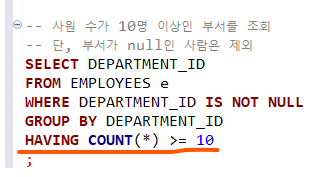
예시로 사원이 10명 이상인 부서를 조회한다고 해봅시다.
필요한 데이터는 부서, 더 정리한 것으로 보기 위해서 부서별로 정리해주었습니다. (GROUP BY()) 그리고 조건에 또 NULL이 아닌 값을 불러와야 한다고 되어있죠?
이 NULL이 아닌 값을 처음의 WHERE문으로 작성해줍니다.
그리고 조건 비교를 하기 위해, HAVING 함수를 이용해 전체 부서별 사원 수를 조회하고 그가 10 이상일 때, 조회하도록 해줍시다.
HAVING COUNT(*) >= 10
그럼 아래와 같은 값이 나타납니다.
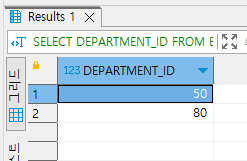
50과 80의 아이디를 갖고있는 부서들이 나타나네요. 성공했나 봅니다.
끝!
이로서 3번째 DBMS 교육날의 중복제거 설명을 마칩니다. 다음 포스팅에서 뵙겠습니다.
