저번에 기본 키(Primary Key)에 대해서 배울 때 인덱스에 대해서 언급되었었죠. 이번에 한번 알아보겠습니다.
Index(인덱스)
(출처: Data Schoolhttps://bit.ly/40VdgK0)
이전 포스팅에서 기본 키는 Not Null + Unique + index의 형태라고 했습니다.
그럼 이 index란 무엇일까요?
이는 데이터를 조회하는 속도를 향상시키기 위한 데이터베이스 검색 기술입니다. 색인이라는 뜻을 가지고 있어 해당 테이블의 조회 속도를 더 빠르게 하기 위해서 있는 것인데요.
1. 원리
그럼 이 index는 어떻게 작동할까?
이는 단순하다면 단순하고, 복잡하다면 복잡하다고 할 수 있겠습니다. 정말 쉽게 간추려서 말하자면..
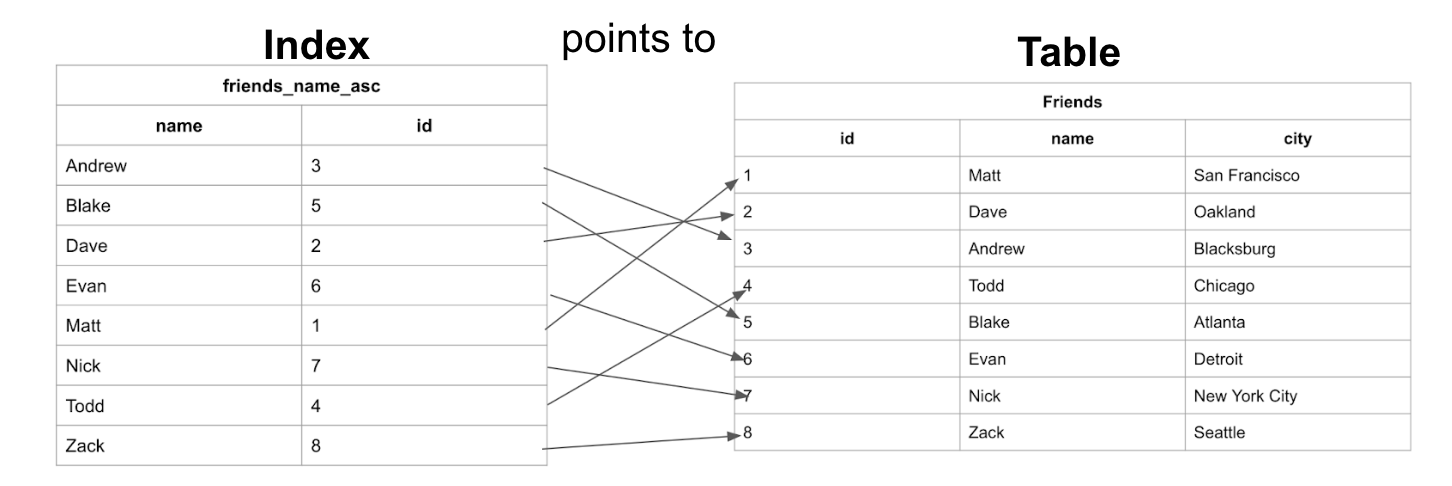
필요한 데이터를 따로 빼 새로 테이블을 만들어 조회하는 것입니다.
이렇게 만들어진 테이블을 index table(인덱스 테이블)이라고 하는데요. 어느 테이블에 index를 특정 컬럼에 주게 되면 이 테이블이 만들어지면서, 컬럼의 row값과 rowid값 (열 값, 열 ID값)이 저장되어 더 빠르게 해당 데이터를 찾아줍니다.
이리 편리한 기능을 하는 인덱스는 다만 단점이 있습니다.
DML에서 조회(Select)문이 아닌 다른 명령어에는 속도 느림!
이는 원본 데이터를 바꾸면 index 테이블의 값도 같이 갱신해줘야 하기 때문입니다. 따라서, insert, delete 같은 다른 명령어들에게는 속도가 느릴 수밖에 없습니다.
2. 불필요한 경우
하지만, 이가 불필요한 경우도 존재합니다.
index는 수많은 데이터에서 해당 데이터를 더 빨리 찾기 위해 존재합니다. 따라서, 데이터가 적을 때에는 설정해주지 않는 것이 오히려 성능에 좋죠.
또한, 조회가 많은 테이블이면 유용합니다. 그렇기에 더욱, 생성 또는 삭제, 수정 같은 명령어를 많이 실행하는 테이블에는 쓰는 걸 추천하지 않습니다.
3. DML, Select 이외의 취약점
방금 전에도 말했듯이, 조회 빼고는 index는 다른 DML 명령어에 성능이 낮습니다.
그럼 어떻게 약해지는지 볼까요?
- Insert : 두 개의 테이블에 동시 생성 필요
- Delete : index에서는 데이터를 사용하지 않음으로 표시, 지우지 않음
- Update : index에서는 delete 후, 새로운 데이터를 insert해서 작업
이리하여 select보다 더해지는 과정들이 있기 때문에, 아무래도 더 느릴 수밖에 없습니다.
4. index 생성
index를 생성하는 데에는 2가지 방법이 있습니다.
1. unique index
중복 X
우선 unique index라는 것이 있습니다. 이는 인덱스를 사용한 컬럼의 중복값들을 포함하지 않고 사용할 수 있는 장점이 있습니다.
쿼리 작성 방법은 아래와 같습니다.


2. non-unique index
중복 O
이에 반대로 non-unique index 라는 것이 있는데요. 이는 인덱스를 사용한 컬럼에 중복 데이터 값을 가질 수 있습니다.
쿼리 작성 방법은 아래와 같습니다. 아무것도 붙지 않은, 그저 인덱스 생성으로 표시됩니다.

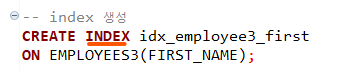
끝!
이로서 index(인덱스)에 대한 설명을 마칩니다. 더불어서, DBMS에 대한 포스팅도 오늘로 끝이 납니다. 내일부터는 html로 넘어가겠습니다.
