네트워크
✏️ OSI 7 layers
프로토콜이란?
프로토콜(Protocol)은 컴퓨터나 네트워크 장비가 서로 통신하기 위해 미리 정해 놓은 약속, 규약입니다.
컴퓨터와 컴퓨터도 서로 일해할 수 있는 언어, 공용된 언어를 사용해야 하는데 이것이 바로 프로토콜입니다.
프로토콜의 기능으로써 1.세분화와 재합성 2.캡슐화 3.연결제어 4.오류제어 5.흐름제어 6.동기화 7.순서결정 8.주소 설정 9.다중화 10.전송서비스의 다양한 기능을 포함하고 있습니다.
네트워크 용어에서 나오는 P는 Protocol의 약자가 대부분이며 대표적으로 인터넷을 할 때 사용되는 프로토콜은 TCP/IP가 있습니다.
그 외 HTTP, ARP, ICMP, SMTP, DHCP 등이 프로토콜의 종류입니다.
패킷이란?
컴퓨터 네트워크에서 데이터를 주고받을 때 정해 놓은 규칙입니다.
패킷은 pack과 bucket의 합친 말로, 정보를 보낼 때 특정 형태를 맞추어 보낸다는 것입니다. 컴퓨터 간에 데이터를 주고받을 때 네트워크를 통해서 전송되는 데이터 조각이라고 생각할 수 있습니다.
OSI 7 계층이란?
OSI(Open System Interconnection) 7계층은 ISO에서 개발한 모델로서, 네트워크 프로토콜 디자인과 통신을 계층으로 나눠 설명한 것입니다. 즉 네트워크 통신의 7단계 과정을 말하는 것입니다.
OSI 계층을 단계별로 알아보겠습니다
작동 원리
1. OSI 7계층은 응용, 표현, 세션, 전송, 네트워크, 데이터링크, 물리계층으로 나뉩니다.
2. 전송 시 7계층에서 1계층으로 각각의 층마다 인식할 수 있어야 하는 헤더를 붙입니다(캡슐화)
3. 수신 시 1계층에서 7게층으로 헤더를 떼어냅니다(디캡슐화)
4. 출발지에서 데이터가 전송될 때 헤더가 추가되는데 2계층에서만 오류제어를 위해 꼬리부분에 추가됩니다.
5. 물리계층에서 1, 0의 신호가 되어 전송매체(동축케이블, 광섬유 등)을 통해 전송합니다.
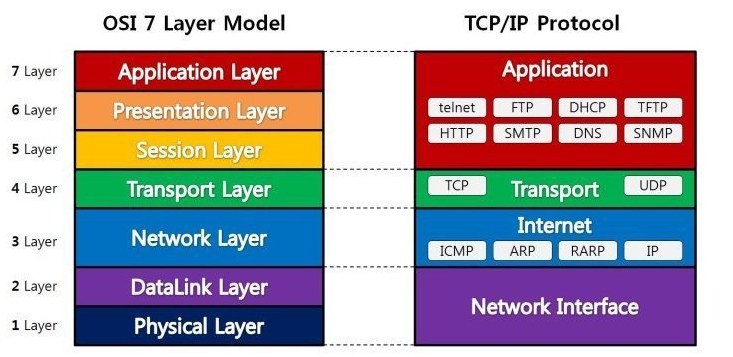
물리 계층(Physical Layer)
- 7계층 중 최하위 계층
- 주로 전기적, 기계적, 기능적인 특성을 이용해 데이터를 전송
- 데이터는 0과 1의 비트열, 즉 On,Off의 전기적 신호 상태로 이루어져 해당 계층은 단지 데이터를 전달
- 단지 데이터 전달의 역할을 할 뿐이라 알고리즘, 오류제어 기능이 없음
- 장비로는 케이블, 허브가 있음
데이터링크 계층(Data-Link Layer)
- 물리적인 연결을 통하여 인접한 두 장치 간의 신뢰성 있는 정보 전송을 담당(Point-To-Point 전송)
- 안전한 정보의 전달이라는 것은 오류나 재전송하는 기능이 존재
- MAC 주소를 통해서 통신
- 데이터 링크 계층에서 데이터 단위는 프레임(Frame)
- 장비로는 브리지, 스위치가 있음
네트워크 계층(Network Layer)
- 이 계층은 경로를 선택하고, 주소를 정하고 경로에 따라 패킷을 전달해주는 것이 이 계층의 역할(여기서 IP 주소를 사용한다)
- 라우팅 기능을 맡고 있는 계층으로 목적지까지 가장 안전하고 빠르게 데이터를 보내는 기능을 가지고 있음(최적의 경로를 설정가능)
- 데이터 단위는 패킷
- 장비로는 라우터, L3 스위치
전송 계층(Transport Layer)
- 종단 간 신뢰성 있고 정확한 데이터 전송을 담당
- 송신자와 수신자 간의 신뢰성있고 효율적인 데이터를 전송하기 위해 오류검출 및 복구, 흐름제어와 중복검사 등을 수행
- 데이터 전송을 위해서 Port 번호를 사용함(대표적인 프로토콜로 TCP와 UDP가 있음)
- 전송 계층에서 데이터 단위는 세그먼트(Segment)
세션 계층(Session Layer)
- 통신 장치 간 상호작용 및 동기화를 제공
- 연결 세션에서 데이터 교환과 에러 발생 시의 복구를 관리
표현 계층(Presentation Layer)
- 데이터를 어떻게 표현할지 정하는 역할을 하는 계층
- 표현 계층의 세가지 기능
- 송신자에서 온 데이터를 해석하기 위한 응용 계층 데이터 부호화, 변화
- 수신자에서 데이터의 압축을 풀 수 있는 방식으로 된 데이터 압축
- 데이터 암호화, 복호화
응용 계층(Application Layer)
- 사용자와 가장 밀접한 계층으로 인터페이스 역할
- 응용 프로세스 간의 정보 교환을 담당
- ex) 전자메일, 인터넷, 동영상 플레이어
✏️ TCP/IP Layer
TCP/IP Layer와 각 계층에 대한 설명을 해주세요.
OSI7은 시스템에 상관없이 서로의 시스템이 연결될 수 있도록 만들어주는 모델이고, 이 이론을 실제 사용하는 인터넷 표준이 TCP/IP 4계층입니다.
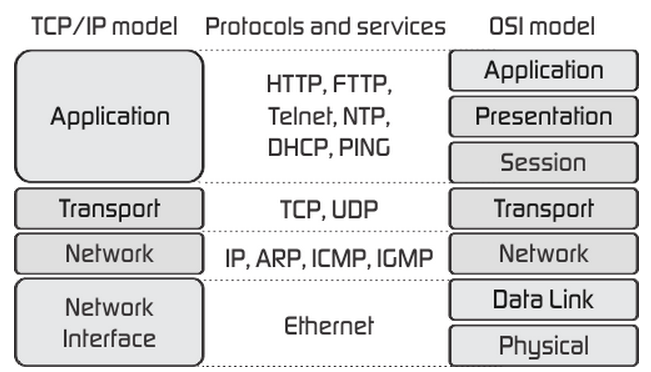
TCP/IP 4 layer는
1계층: 네트워크 액세스 계층
2계층: 인터넷 계층
3계층: 전송 계층
4계층: 응용 계층 으로 구성되어있습니다.
네트워크 인터페이스 계층(Network Access Layer or Network Interface Layer)
- OSI계층의 물리 계층과 데이터 링크 계층에 해당합니다(1,2계층에 해당)
- Node-To-Node간의 신뢰성 있는 데이터 전송을 담당합니다
- 물리적인 주소로 MAC을 사용합니다
- LAN, 패킷망 등에 사용됩니다
- 에러검출 기능(Detecting errors), 패킷의 프레임화(Framing packets)
- 주요 프로토콜: Ethernet, Token Ring, Frame Relay, ATM 등
인터넷 계층(Internet Layer)
- OSI 계층의 네트워크 계층에 해당합니다(3계층에 해당)
- 호스트 간의 라우팅 담당
- 상위 트랜스포트 계층으로부터 받은 데이터에 IP패킷 헤더를 붙여 IP패킷을 만들고 이를 전송합니다
- addressing, packaging, routing 기능을 제공합니다
- 통신 노드 간의 IP패킷을 전송하는 기능과 라우팅 기능을 담당합니다
- 주요 프로토콜:
- IP(Internet Protocol): 비신뢰성, 비연결지향 데이터그램 프로토콜
- ARP(Address Resolution Protocol): 주소변환 프로토콜(ip주소를 MAC주소로 변환하는 프로토콜)
- RARP, ICMP 등
전송 계층(Transport Layer)
- OSI계층의 전송 계층에 해당(4계층)
- 프로세스간의 신뢰성있는 데이터 전송을 담당
- 통신 노드 간의 연결을 제어합니다
- 네트워크 양단의 송수신 호스트 사이에서 신뢰성 있는 데이터 전송을 담당합니다
- 주요 프로토콜: TCP, UDP
응용 계층(Application Layer)
- OSI계층의 세션 계층, 표현 계층, 응용계층에 해당합니다
- 사용자와 가장 가까운 계층이며
- 서버나 클라이언트 응용 프로그램이 이 계층에서 동작합니다
- 동작하기 위해서는 전송계층의 주소, 즉 포트번호를 사용합니다.
- TCP/UDP 기반의 응용 프로그램을 구현할 때 사용합니다
- 응용 계층 프로토콜의 종류:
- 파일 전송: FTP(포트번호:23), TFTP
- 원격 로그인: Telnet(포트번호:23)
- 전자메일: SMTP(TCP 포트번호:25), POP3(TCP 포트번호:110)
- 지원 서비스 범주: DNS, SNMP
- 기타 프로토콜: HTTP(TCP 기반의 프로토콜, 포트번호:80), SSH(포트번호: 22)
✏️ 계층화의 이유
OSI 7 Layer 또는 TCP/IP Layer에서 계층화하는 이유가 무엇인가요?
계층을 나눈 이유는 통신이 일어나는 과정을 단계별로 파악할 수 있기 때문입니다.
흐름을 한눈에 알아보기 쉽고, 사람들이 이해하기 쉽게 7단계 중 특정한 곳에 이상이 생기면 다른 단계의 장비 및 소프트웨어를 건들이지 않고도 이상이 생긴 단뎨만 고칠 수 있기 때문입니다.
✏️ 캡슐화와 역캡슐화
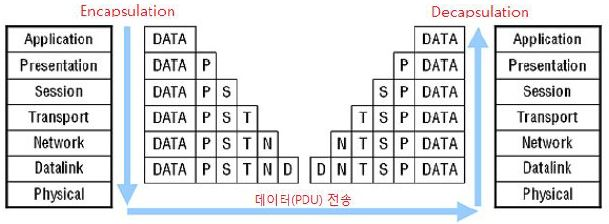
Encapsulation과 Decapsulation을 서로 비교하며 설명해주세요
네트워크를 통해 데이터를 보낼 때는 캡슐화와 역캡슐화의 과정이 이루어집니다.
데이터를 보내기 위해선 데이터 앞부분에 전송하는데 필요한 정보를 붙여서 다음 계층으로 보내기 때문입니다.
이처럼 헤더를 붙여나가는 것을 캡슐화라고 합니다.
데이터 송신 측에서 캡슐화를 통해 데이터를 전송한다면 수신측에서는 역캡슐화를 통해 최초로 보낸 데이터 형태로 받을 수 있는 것입니다.
- 캡슐화: 페이로드에 헤더를 추가하여 전송 꾸러미를 만드는 과정
- 역캡슐화: 전송 꾸러미를 받아 헤더를 제거하며 원래의 페이로드를 복원하는 과정
✏️ IP와 IP주소
IP란?
IP는 Internet Protocol의 약자로 기기간 네트워크 통신을 할 때 쓰는 프로토콜입니다.즉, 예를들어 인터넷 검색 등을 할 때 컴퓨터 기기 간에 통신하는 방식입니다.
IP 주소란?
IP 프로토콜에서 IP 기기의 주소를 나타내는 것이 바로 IP주소입니다.
✏️ IPv4 vs IPv6
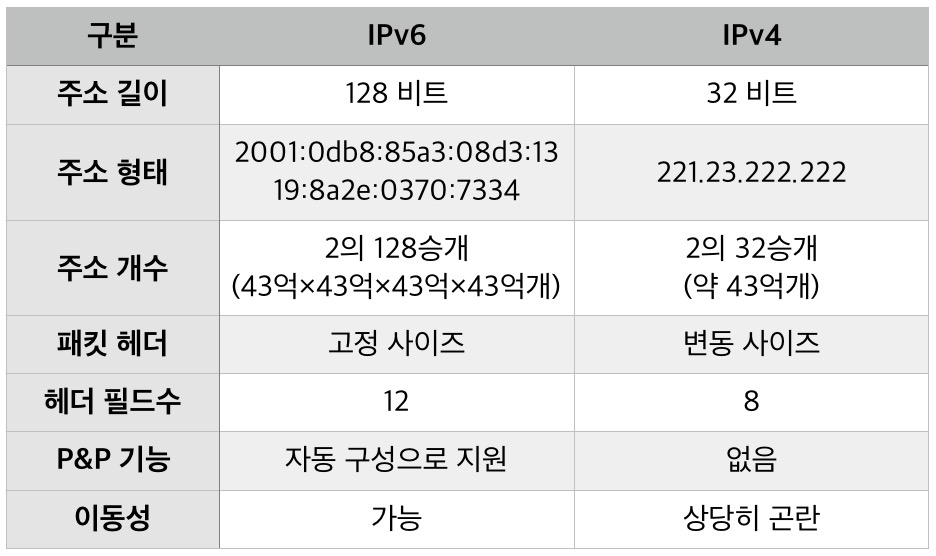
IP 주소는 IPv4, IPv6 2가지 종류가 있으며 일반적으로 IP 주소라 하면 IPv4 주소를 말합니다.
IPv4는 IPversion4의 약자로 전 세계적으로 사용된 첫 번째 인터넷 프로토콜입니다.
주소는 32 비트 방식으로, 8비트씩 4자리로 되어 있으며 각 자리는 온점으로 구분합니다
ex) 115.68.24.88
IPv4는 0 ~ 2^32 (약 42억 9천)개의 주소를 가질 수 있는데,
전 세계적으로 인터넷 사용자 수가 급증하면서 IPv4 주소가 고갈될 위기에 처해있습니다.
이러한 고갈 문제를 해결하기 위해 등장한 주소가 바로 IPv6입니다.
IPv6는 IPversion6의 약자로,
IPv4의 주소체계를 128비트 크기로 확장한 차세대 인터넷 프로토콜 주소입니다.
16비트씩 8자리로 각 자리는 콜론으로 구분합니다
ex) 2001:0DB8:1000:0000:0000:0000:1111:2222
네트워크 속도, 보안적인 부분뿐만 아니라 여러 면에서 뛰어나지만
기존의 주소체계를 변경하는데 비용이 많이 들어서 아직 완전히 상용화가 되지 않았습니다.
[참고 링크1]
[참고 링크2]
[참고 링크3]
[참고 링크4]
[참고 링크5]
✏️ TCP와 UDP
💡 TCP와 UDP의 특징과 차이점을 설명해주세요.
TCP/UDP란 전송 계층에서 사용하는 프로토콜로써, 목적지 장비까지 전송한 패킷을 상위의 특정 응용 프로토콜에게 전달하는 것에 목적이 있습니다. 전송 방식으로는 TCP와 UDP가 있습니다.
TCP란?
: 연결형 서비스를 지원하는 전송 계층 프로토콜로써, 인터넷 환경에서 기본으로 사용합니다.
호스트간 신뢰성 있는 데이터 전달과 흐름제어를 합니다. 일반적으로 TCP와 IP를 함께 사용하는데, IP가 데이터의 배달을 처리한다면 TCP는 패킷을 추적 및 관리하게 됩니다.
UDP란?
: 비연결형 서비스를 지원하는 전송 계층 프로토콜로써, 인터넷상에서 서로 정보를 주고받을 때 정보를 보낸다는 신호나 받는다는 신호 절차를 거치지 않고, 보내는 쪽에서 일방적으로 데이터를 전달하는 통신 프로토콜입니다. 데이터를 데이터그램 단위로 처리하는 프로토콜입니다.
TCP 특징
- 연결형 서비스
- 데이터의 경계를 구분하지 않는다
- 데이터의 전송 순서를 보장한다
- UDP보다 전송속도가 느리다
- 신뢰성 있는 데이터를 전송한다
- 일대일 통신
UDP 특징
- 비연결형 서비스로 데이터그램 방식을 제공
- 정보를 주고 받을 때 정보를 보내거나 받는다는 신호절차를 거치지 않는다
- 신뢰성 없는 데이터를 전송한다
- 데이터의 경계를 구분한다
- TCP보다 전송속도가 빠르다
- 일대일, 일대다, 다대다 통신
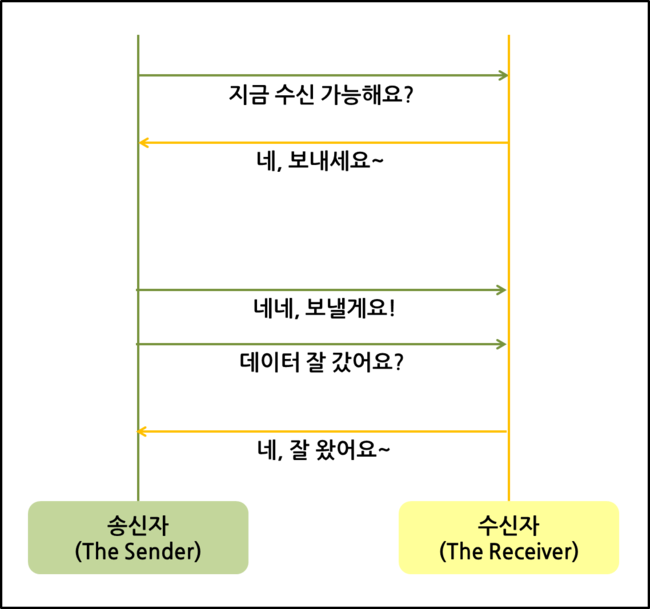
차이점
: TCP는 연속성보다 신뢰성 있는 전송이 중요할 때에 사용하는 프로토콜이며,
UDP는 TCP보다 속도가 빠르며 네트워크 부하가 적다는 장점이 있지만, 신뢰성 있는 데이터 전송을 보장하지 않습니다. 그렇기 때문에 신뢰성보다 연속성이 중요한 실시간 서비스(streaming)에 자주 사용됩니다.
💡 TCP를 사용하는 대표적인 프로토콜은 무엇인가요?
- HTTP: TCP 기반의 프로토콜로 포트번호 80번을 사용합니다
- Telnet: TCP 포트번호 23번을 사용합니다.
- FTP: TCP 포트 20번은 데이터 전송을 위한 용도, TCP포트 21번은 제어용으로 사용합니다
- SMTP: TCP 상에서 동작하며 포트는 25번을 사용합니다.
- DNS: 기본적으로 UDP상에서 동작하지만 신뢰성을 요할 경우 TCP상에서도 동작합니다. UDP, TCP포트는 53번을 사용합니다.
✏️ 3-Handshaking vs 4-Handshaking
💡 3-Handshaking과 4-Handshaking의 과정을 설명해주세요.
- TCP 3-way Handshake란?
TCP/IP 프로토콜을 이용해서 통신하는 응용프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해서 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미합니다.
(SYN - synchronize sequence numbers , ACK - acknowledgement) - TCP 4-way Handshake란?
3-way handshake는 TCP 연결을 초기화 할 때 사용한다면, 4-way handshake는 세션을 종료하기 위해 수행되는 절차입니다.
TCP의 3-way Handshaking 역할과 과정
- 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장하고, 실제로 데이터 전달이 시작하기 전에 한쪽이 다른 쪽이 준비되었다는 것을 알 수 있도록 합니다
- 양쪽 모두 상대편에 대한 초기 순차일련번호를 얻을 수 있도록 합니다.
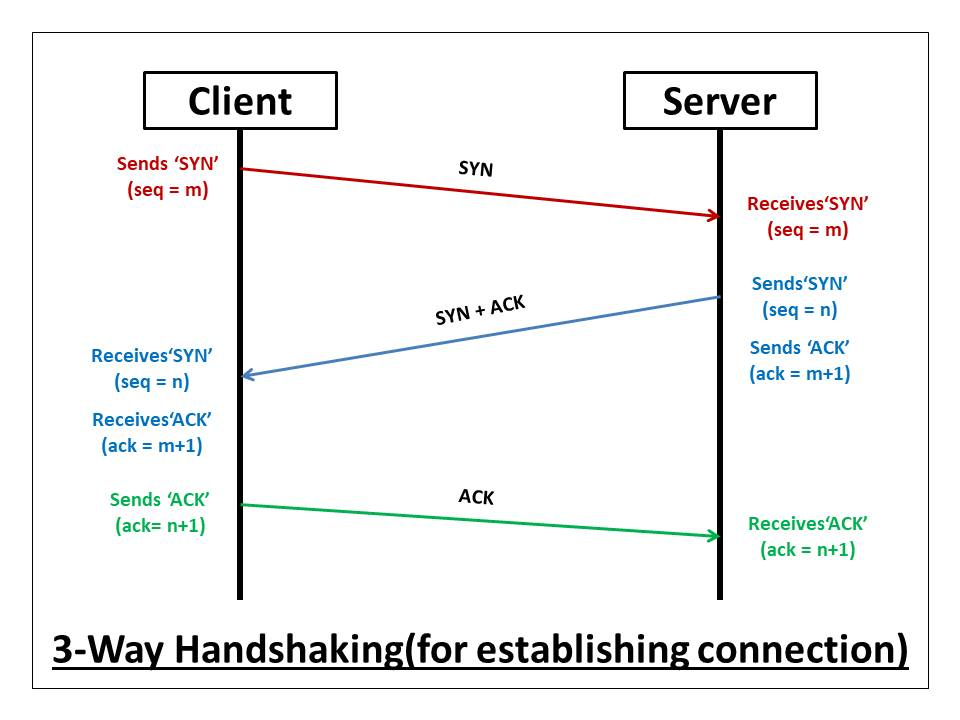
-
step 1
: A클라이언트는 B서버에 접속을 요청하는 SYN 패킷을 보냅니다. 이때 A클라이언트는 SYN을 보내고 SYN/ACK 응답을 기다리는 SYN_SENT 상태가 됩니다 -
step 2
: B서버는 SYN 요청을 받고 A클라이언트에게 요청을 수락한다는 ACK과 SYN flag가 설정된 패킷을 발송하고 A가 다시 ACK으로 응답하기를 기다립니다. 이때 B서버는 SYN_RECEIVED 상태가 됩니다. -
step 3
: A클라이언트는 B서버에게 ACK을 보내고 이후로부터는 연결이 이루어지고 데이터가 오갑니다. 이때 B서버 상태는 ESTABLISHED입니다.
TCP의 4-way Handshaking 역할과 과정
- 세션을 종료하기 위해 수행되는 절차입니다
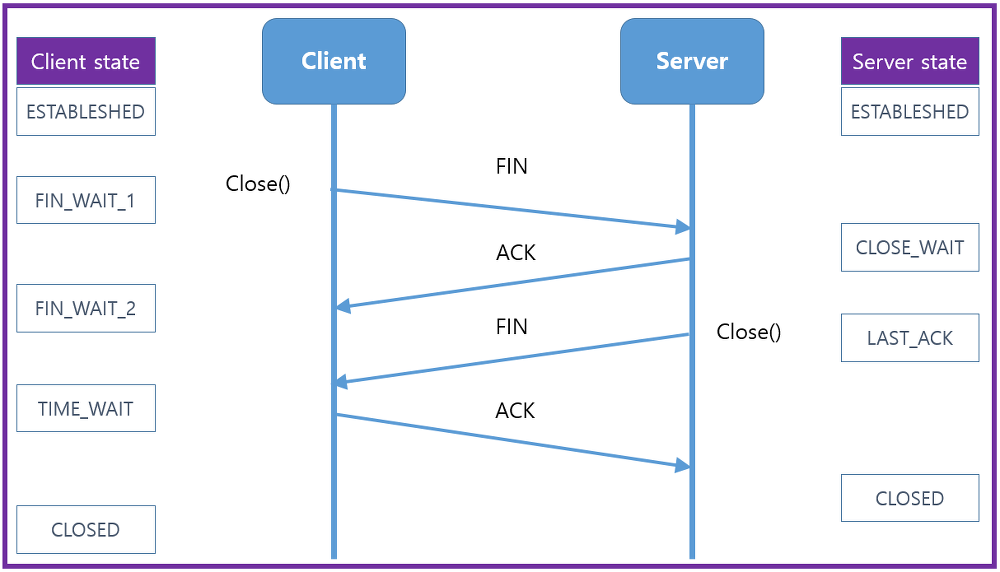
-
step 1
: 클라이언트가 연결을 종료하겠다는 FIN 플래그를 전송합니다 -
step 2
: 서버는 일단 확인메시지를 보내고 자신의 통신이 끝날때까지 기다리는데 이 상태가 TIME_WAIT 상태입니다 -
step 3
: 서버가 통신이 끝났으면 연결이 종료되었다고 클라이언트에게 FIN플래그를 전송합니다 -
step 4
: 클라이언트는 확인했다는 메시지를 보냅니다
✏️ 클라이언트와 서버
💡 클라이언트와 서버는 무엇인가요?
서버는 제공자이며 클라이언트는 사용자라고 할 수 있습니다.
클라이언트는 서버와 서로 대응되는 개념이며 서비스를 사용하는 사용자를 의미하며 서버는 일반적으로 클라이언트에게 네트워크를 통해 서비스를 제공하는 시스템을 말합니다.
[참고 링크1]
[참고 링크2]
[참고 링크3]
[참고 링크4]
✏️ TCP 관련 질문
💡 4-way handshaking 과정에서 클라이언트가 마지막에 ACK 역할?
- 클라이언트는 FIN을 받고 확인했다는 ACK을 서버에게 보냅니다
- 아직 서버로부터 받지 못한 데이터가 있을 수 있으므로 TIME_WAIT을 통해 기다립니다
- 이때 TIME_WAIT 상태는 의도치 않은 에러로 인해 연결이 데드락에 빠지는 것을 방지합니다
- 만약 에러로 인해 종료가 지연되다가 타임이 초과되면 CLOSED로 들어갑니다
- 서버는 ACK을 받은 이후 소켓을 닫습니다
- TIME_WAIT 시간이 끝나면 클라이언트도 닫습니다.
💡 만약 Server에서 FIN 세그먼트를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생하면 어떻게 될까?
이러한 현상을 대비하여 Client는 Server로 부터 FIN플래그를 수신하더라도 일정시간동안 TIME_WAIT 상태를 갖습니다. (일정 시간동안 세션을 남겨 놓고 잉여 패킷을 기다리는 과정)
💡 TCP의 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 단계가 차이나는 이유?
Clinet가 데이터 전송을 마쳤다고 해도, 서버는 아직 보낼 데이터가 남아있을 수도 있기 때문에 FIN에 대한 ACK만 보내고 남은 데이터를 모두 전송한 후에 자신도 데이터 전송을 마쳤다는 FIN 플래그를 보내기 때문입니다.
💡 초기 Sequence Number인 ISN을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유?
포트가 커넥션을 맺을 경우 유한 범위 내에서 사용하며 시간이 지나도 재사용됩니다. 따라서 서버측에서 난수가 아닌 순차적인 숫자가 전송된다면 이전 Connection으로부터 오는 패킷으로 인식할 수 있기 때문입니다
✏️ HTTP vs HTTPS
💡 HTTP와 HTTPS를 설명해주세요
가장 큰 차이는 바로 SSL 인증서, 즉 보안성입니다.
뿐만 아니라 SEO 품질도 차이가 있습니다. HTTPS로 전환하게 되면 검색엔진 최적화(SEO)에서도 혜택을 볼 수 있습니다.
-
HTTP : HTTP는 하이퍼 텍스트 전송 프로토콜(Hypertext Transfer Protocol)의 약자로, 서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 프로토콜입니다. 인터넷 초기 모든 웹사이트에서 기본적으로 사용되었던 프로토콜입니다.
-
HTTPS : HTTPS는 하이퍼 텍스트 전송 프로토콜 보안(Hypertext Transfer Protocol Secure)의 약자입니다. 일반 HTTP 프로토콜의 문제점은 서버에서부터 브라우저로 전송되는 정보가 암호화되지 않는다는 것입니다. HTTPS 프로토콜은 이 문제를 SSL(보안 소켓 계층)으로 해결했습니다.
-
SSL : SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버 브라우저가 민감한 정보를 주고받을 때 이것이 도난당하는 것을 막아줍니다. SSL인증서는 사용자가 사이트에 제공하는 정보를 암호화하는데, 쉽게 말해서 데이터를 암호로 바꾼다고 생각하면됩니다. 그 외에도 HTTPS는 TLS(전송 계층 보안) 프로토콜을 통해서도 보안을 유지합니다.
-
TLS : TLS는 데이터 무결성을 제공하기 때문에 데이터 전송 중에 수정되거나 손상되는 것을 방지하고, 사용자가 자신이 의도하는 웹사이트와 통신하고 있음을 입증하는 인증 기능도 제공하고 있습니다.
✏️ HTTP 단점
💡 HTTP의 단점을 설명해주세요
1. 평문(암호화 되지 않은) 통신이기 때문에 도청이 가능합니다. -> 네트워크 상의 흐르는 패킷을 수집하여 도청할 수 있습니다
2. 통신 상대를 확인하지 않기 때문에 위장이 가능합니다.
3. 변조가 가능합니다.
단점을 해결하기 위해선,
SSL이나 TLS를 사용하여 다른 포로토콜과 조합하여 HTTP통신 내용을 암호화해야합니다.
HTTP + 암호화 + 인증 = HTTPS
✏️ HTTP1.0 vs HTTP2.0
💡 HTTP1.1와 HTTP2.0 차이점은 무엇인가요?
가장 큰 차이는 HTTP1.0이 느려서 나온것이 HTTP2.0입니다.
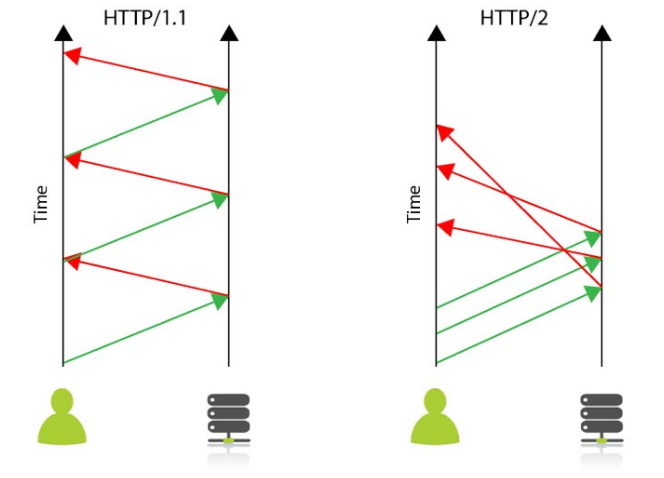
HTTP1.1이 느린이유
-
연결당 하나의 요청과 응답을 처리하기 때문에 동시 전송 문제와 다수의 리소스를 처리하기엔 속도와 성능이 좋지 않았습니다
-
HOL(Head Of Line) Blocking(특정 응답 지연)
- HTTP1.1의 사양상의 제한으로 클라이언트의 리퀘스트 순서와 서버의 응답순서가 동기화되어야 합니다
-
RTT(Round Trip Time) 증가(양방향 지연)
-
헤더가 크가 (특히 쿠키 때문)
- HTTP1.1의 헤더는 많은 메타 정보들이 저장되어 있습니다.
- 사용자가 방문한 웹페이지는 다수의 http 요청이 발생하게 되는데 이 경우 매 요청시마다 중복된 헤더 값을 전송하게 되며 각 도메인에 설정된 쿠키 정보도 매 요청시마다 헤더에 포함되어 전송됩니다
HTTP2.0이 빠른이유
- Multiplexed Streams(한 커넥션에 여러개의 메시지를 동시에 주고 받을 수 있습니다)
- 요청이 커넥션 상에서 다중화 되므로 HOL(Head Of Line) Blocking이 발생하지 않습니다
- 요청 리소스 간 의존관계를 설정합니다
- Header 정보를 HPACK 압축 방식을 이용하여 압축 전송합니다
- Server Push( HTML 문서 상에 필요한 리소스를 클라이언트 요청없이 보내줄 수 있습니다)
- HTTP 1.1과 높은 수준의 호환성 - 메서드, 상태코드, URI및 헤더 필드
- 페이지 로딩 속도 향상
✏️ 비연결성
💡 HTTP는 왜 비연결성인가?
HTTP는 인터넷 상에서 불특정 다수의 통신 환경을 기반으로 설계되었습니다. 만약 서버에서 다수의 클라이언트와 연결을 계속 유지해야한다면, 이에 따른 많은 리소스가 발생하게 됩니다. 따라서 연결을 유지하기 위한 리소스를 줄이면 더 많은 연결을 할 수 있으므로 비연결적인 특징을 갖습니다.
비연결성
비연결성은 클라이언트와 서버가 한번 연결을 맺은 후, 클라이언트 요청에 대해 서버가 응답을 마치면 맺었던 연결을 끊어버리는 성질을 말합니다
- 단점
: 서버는 클라이언트를 기억하고 있지 않으므로 동일한 클라이언트의 모든 요청에 대해, 매번 새로운 연결 시도/해제의 과정을 거쳐야하므로 연결/해제에 대한 오버헤드가 발생한다는 단점이 있습니다.
무상태
비연결성으로 인해 서버는 클라이언트를 식별할 수가 없는데 이를 무상태라고 합니다.
매번 새로운 인증을 해야하는 번거로움이 발생합니다.
상태를 기억하는 방법
1) 쿠키
:쿠키는 사용자 정보가 브라우저에 저장되기 때문에 공격자로부터 공격받을 가능성이 높습니다
2) 세션
:세션은 브라우저가 아닌 서버단에서 사용자 정보를 저장하는 구조입니다. 하지만 세션을 사용하면 서버의 메모리를 차지하고 동시 접속자가 많을 경우 서버 과부하의 원인이 됩니다.
3) 토큰
쿠키와 세션의 문제점을 보완하기 위해 토큰 기반의 인증 방식이 도입되었습니다. 토큰 기반의 인증 방식 핵심은 보호할 데이터를 토큰으로 치환하여 원본 데이터 대신 토큰을 사용하는 기술입니다.
✏️ 공개키 암호화
💡 비대칭키 또는 공개키 암호화 방식은 무엇인가요?
대칭키 암호화 방식은 암복호화에 사용하는 키가 동일한 암호화 방식을 말합니다. 그와 달리 공개키(비대칭키) 암호화 방식은 암복호화에 사용하는 키가 서로 다릅니다. 따라서 공개키 암호화에서는 송수신자 모두 한쌍의 키(개인키, 공개키)를 갖고있게 됩니다.
대칭키, 장단점
대칭키는 암복호화키가 동일하며 해당 키를 아는 사람만이 문서를 복호화해볼 수 있습니다. 대표적인 알고리즘으론 DES, 3DES, AES, SEED, ARIA 등이 있습니다.
공개키 암호화 방식에 비해 속도가 빠르지만, 키를 교환해야한다는 문제가 발생합니다. 키를 교환하는 중 키가 탈취될 수도 있고, 사람이 증가할수록 관리해야할 키가 방대해지기 때문입니다.
이를 위한 해결 방법으로 키의 사전 공유, 키 배포 센터, 공개키 암호에 의한 해결이 있습니다.
공개키, 장단점
위의 대칭키 문제를 해결한 것이 공개키 암호화 방식입니다. 이름 그대로 키를 공개했기 때문에 키를 교환할 필요가 없으며 공개키는 모든 사람이 접근 가능한 키이고 개인키는 사용자만이 가지고 있는 키입니다.
예시입니다
1) B 공개키.개인키 쌍 생성
2) 공개키 등록, 개인키는 본인이 소유
3) A가 B의 공개키를 받아옴
4) A가 B의 공개키를 사용해 데이터를 암호화, 전송
5) B는 B의 개인키로 복호화
✏️ GET, POST
💡 HTTP REQUEST 방식 중 GET과 POST의 차이을 설명해주세요.
GET은 Idempotent, POST는 Non-idempotent하게 설계되었습니다.
GET은 동일한 연산을 여러 번 수행하더라도 동일한 결과가 나타나야합니다. GET이 Idempotent하게 설계되었다는 것은 GET으로 서버에게 동일한 요청을 여러번 전송하더라도 동일한 응답이 돌아와야한다는 것입니다. 그렇기 때문에 GET은 주로 조회할 때 사용해야합니다.
반대로 POST는 서버에게 동일한 요청을 여러번 전송해도 응답은 항상 다를 수 있습니다. 이에 따라 POST는 서버의 상태나 데이터를 변경시킬 때 사용됩니다.
GET과 POST
-
GET은 서버로부터 정보를 조회하기 위해 설계된 메소드입니다. GET은 요청을 전송할 때 필요한 데이터를 Body에 담지 않고 쿼리스트링을 통해 전송합니다. 쿼리스트링을 사용하게 되면 URL에 조회 조건을 표시하기 때문에 특정 페이지를 링크하거나 북마크할 수 있습니다.
-
POST는 리소스를 생성/변경하기 위해 설계되었기 때문에 GET과 달리 전송해야될 데이터를 HTTP 메세지의 Body에 담아서 전송합니다. HTTP 메시지의 Body는 길이의 제한없이 데이터를 전송할 수 있습니다. 그래서 POST 요청은 GET과 달리 대용량 데이터를 전송할 수 있고, 데이터가 Body로 전송되기 때문에 GET보다 보안적인 면에서 안전하다고 볼 수 있지만, POST요청도 크롬 개발자 도구 같은 툴로 내용을 확인할 수 있기 때문에 민감한 데이터는 암호화해야합니다
PUT vs PATCH
둘은 정보를 수정할수 있는 HTTP method입니다. 하지만 차이가 있습니다. PUT은 데이터를 전부 수정하는 메서드라 idempotent하지만, PATCH는 정보의 일부분이 변경되는 부분 수정이기 때문에 Non-idempotent한 설계입니다.
✏️ DNS
💡 도메인과 DNS가 무엇인지 설명해주세요
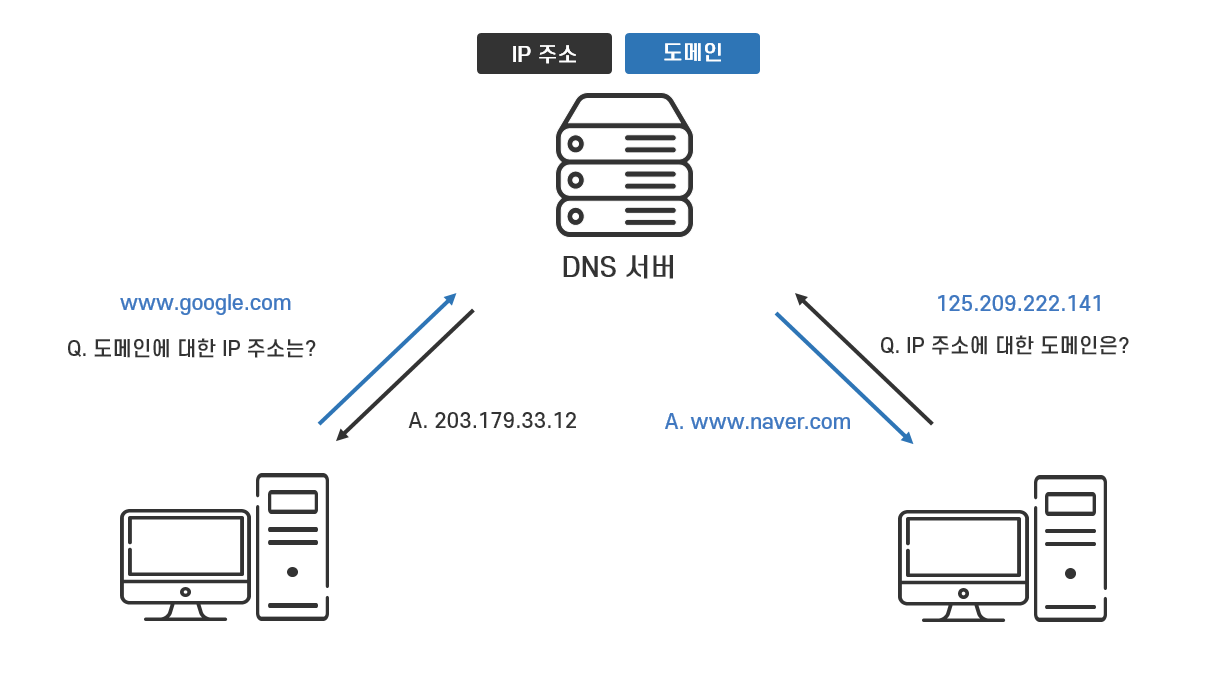
- 도메인: 도메인이란 숫자로 이루어진 네트워크상의 주소, 즉 IP주소를 일정한 규칙에 따라 알기쉬운 문자 형태로 표현한 것입니다.
- DNS: DNS는 IP주소와 도메인을 연결해주는 시스템입니다. 즉 DNS 서버를 통해서 숫자로 이루어진 IP 주소와 일정한 형식을 가진 도메인을 서로 매핑시켜주는 것입니다.
네트워크상으로 이루어진 모든 통신에서는 목적지와 출발지를 찾을 때 숫자로 이루어진 IP주소를 이용해야합니다. 하지만 IP주소는 숫자와 . 으로만 이루어져있어 기억하기가 어렵습니다.
ex)
www.google.co.kr
203.233.10.216
모두 구글과 연결된 주소입니다.
바로 위에 것이 도메인이고, 아래것이 IP입니다. 즉, 도메인은 기억하기 힘든 숫자로만 이루어진 IP주소를 좀 더 보기 좋게 문자로 나타낸 것입니다. 이를 가능하게 해주는 것이 바로 DNS입니다.
✏️ Domain
💡 Domain Name 구조를 설명해주세요.
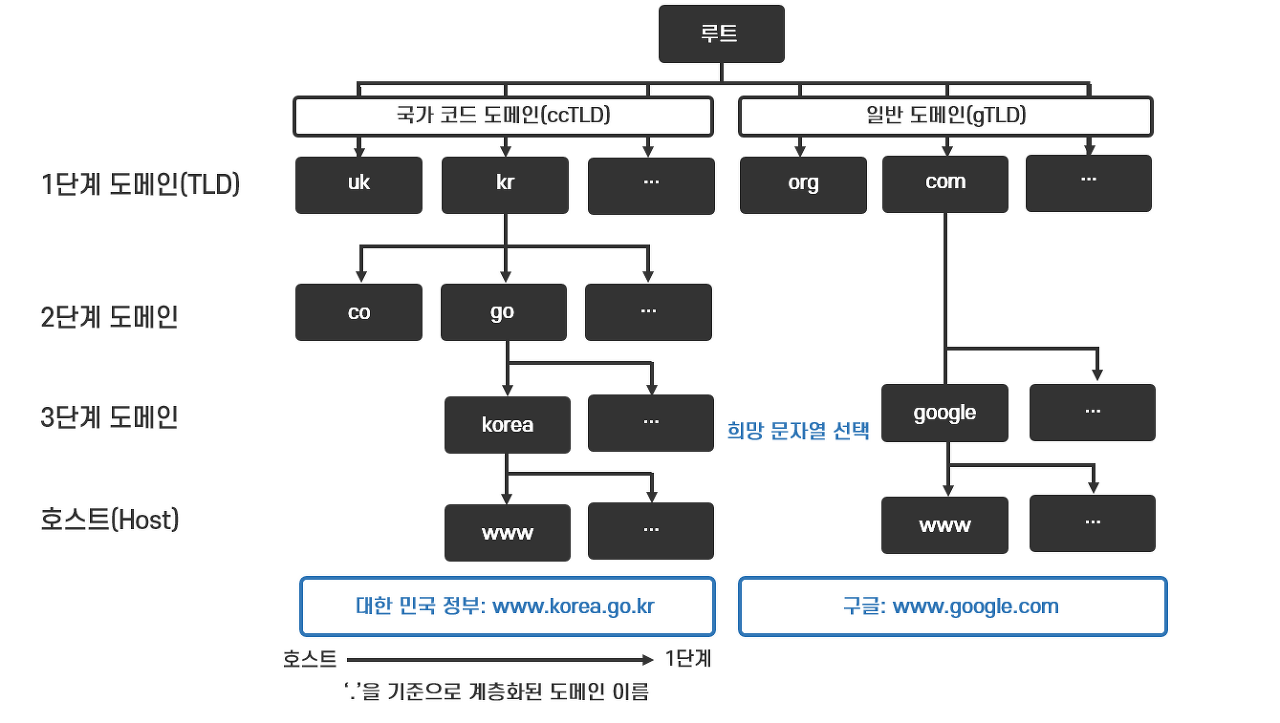
도메인은 체계적인 분류와 관리를 위해 몇개의 잛은 영문자를 '.'(닷)으로 연결한 계층 구조를 갖고 있습니다. 도메인의 계층 구조는 역 트리 구조입니다.
루트 아래로 갈라지는 가지를 단계로 구분하여 'kr'과 같이 국가를 나타내는 국가 코드 도메인이나 'com'과 같이 등록인의 목적에 따라 사용되는 일반 도메인을 1단계 도메인이라고 합니다.
1단계 하위 도메인인 2단계 도메인은 조직의 속성을 구분하는 'co(영리기업)','go(정부 기관)', 'ac(대학기관)'과 같은 도메인이 있습니다.
2단계 하위 3단계 도메인은 조직이나 서비스의 이름을 나타내는 도메인 이름입니다. 그리고 마지막은 컴퓨터의 이름을 나타내는 호스트가 위치합니다.
✏️ Round robin
round robin이란 DNS 서버 구성 방식 중 하나입니다.
프로세스들 사이에 우선순위를 두지 않고 순서대로 시간단위(Time Quantum/Slice)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘입니다.

쉽게 말하면 각 프로세스에 일정시간을 할당하고 할단된 시간이 지나면 그 프로세스는 잠시 보류한 뒤 다른 프로세스에게 기회를 주는, 돌아가며 기회를 부여하는 운영방식입니다.
이는 DNS 서버의 부하에 대한 걱정을 할 필요가 없어집니다.(자동으로 시간에 따라 스케줄링이 변환되기 때문에)
💡 DNS round robin 방식의 문제점을 설명해주세요.
DNS round robin 방식의 문제점은 다음과 같습니다
1. 서버의 수 만큼 공인 IP 주소가 필요합니다
: 부하 분산을 위해 서버 대수를 늘리려면 그만큼의 공인 IP가 필요합니다.
2. 균등하게 분산되지 않습니다
: 스마트폰의 접속은 캐리어 게이트웨이라고 하는 프록시 서버를 경유합니다. 프록시 서버에서는 이름변환 결과가 일정 시간 동안 캐싱되므로 같은 프록시 서버를 경유하는 접속은 항상 같은 서버로 접속됩니다. 또한 PC용 웹 브라우저도 DNS 질의 결과를 캐싱하기 때문에 균등하게 부하 분산 되지 않습니다.
3. 서버가 다운돼도 확인이 불가능합니다.
DNS 서버는 웹 서버의 부하나 접속 수 등의 상황에 따라 질의결과를 제어할 수 없습니다. 웹 서버의 부하가 높아서 응답이 느려지거나 접속수가 꽉 차서 접속을 처리할 수 없는 상황인지 감지할 수 없기 때문에 어떤 원인으로 다운되더라도 이를 검출하지 못하고 유저들에게 제공됩니다.
💡 해결 방법은?
1. 다중화 구성 방식(Synchronous Time-Division Multiplexing): DNS 서버 테이블에 실시간으로 AP 서버의 상태를 확인할 수 있는 컬럼 및 함수를 추가하여 요청될 경우 서버의 상태를 확인하여 우회 루트를 제공하거나 에러를 전송하는 방식입니다.
2. 가중치 편성 방식(Weighted round robin): 각각의 웹 서버에 가중치를 가미해서 분산 비율을 변경합니다. 가중치가 큰 서버일수록 빈번하게 선택되므로 처리능력이 높은 서버는 가중치를 높게 설정하는 것이 좋습니다.
3. 최소 연결 방식(Least connection): 접속 클라이언트 수가 가장 적은 서버를 선택하는 것입니다. 로드밸런서에서 실시간으로 connection 수를 관리하거나 각 서버에 주기적으로 알려주는 것이 필요합니다.
