ERD설계 기준
1. N:M (다대다) 관계를 분리 시켰는가
다대다 매핑이 무엇일까요?
예로 주문 테이블과 상품 테이블은 다대다 관계라고 볼 수 있는데 왜그럴까요?!
- 하나의 주문에는 여러 개의 상품이 포함될 수 있다.
주문 A: 🍔 햄버거 + 🍟 감자튀김 + 🥤 콜라
주문 B: 🍕 피자 + 🥤 콜라
- 하나의 상품이 여러 개의 주문에서 사용될 수 있다.
상품 🍟 감자튀김: 주문 A, 주문 C에 포함됨
상품 🥤 콜라: 주문 A, 주문 B, 주문 C에 포함됨
핵심은 "두 개의 엔티티가 서로 여러 개를 가질 수 있는가?" 입니다!
이런 다대다 관계는 ManyToMany를 사용하여 구현은 가능하나 조인 연산이 많아져 쿼리 성능도 저하되고 데이터 무결성 관리가 어렵기 때문에 실무에서는 다대다 매핑을 지양합니다
해결방법은 중간테이블을 두자!

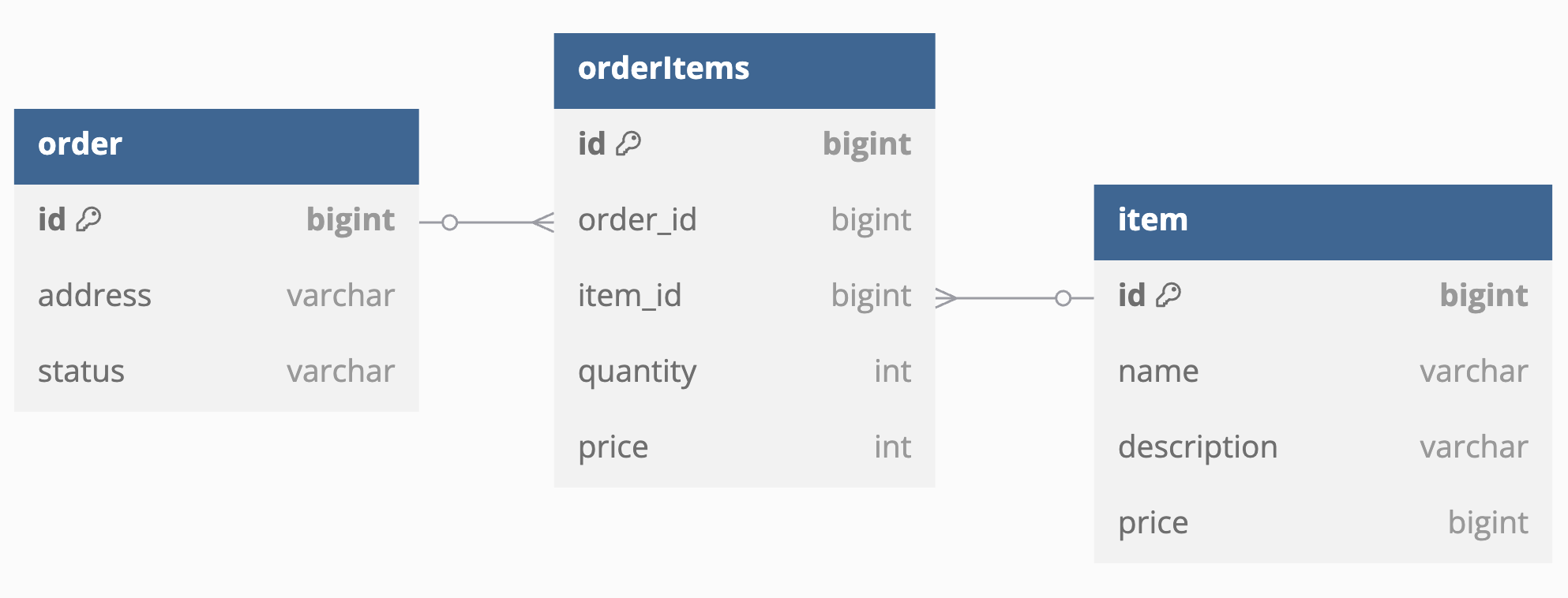
[ 주문 - 주문된 상품 - 상품 ] 과 같이 중간에 연관테이블을 두어 N:1 관계로 변경하도록 합니다
참조는 주인테이블에게 두고 이때 주인이라는 것은 관계를 관리하는 쪽이라고 생각하면 됩니다
PK를 가진 테이블은 관계와 무관하게 독립적인 개체이며 FK를 가진 테이블이 다른 엔티티를 참조하며 관계를 형성하므로 주인테이블은 주문된 상품인 orderItem이 됩니다
이때 N:1 에서 N이 주인 테이블이여야 합니다
1이 주인테이블이 될 경우 데이터 관리가 어렵고 성능 문제가 생기게 됩니다
- 다대다 매핑은 중간테이블을 두어 분리시키자
- 참조키는 관계를 관리하는 주인 테이블에게 두자
- 주인 테이블을 기준으로 했을 때 N:1 매핑을 사용하고 1:N 관계는 지양하자
2. 양방향 VS 단방향 결정했는가
양방향 : 서로 참조
public class OrderItem {
@ManyToOne
@JoinColumn(name = "orderItem_id") // ✅ FK를 가짐
private OrderItem orderItem;
}
public class Order {
@OneToMany(mappedBy = "order") // ✅ OrderItem에서 Order를 참조
private List<OrderItem> orderItems;
}단방향 : 한쪽만 참조
public class OrderItem {
@ManyToOne
@JoinColumn(name = "item_id") // ✅ FK를 가짐
private Item item;
}주문 항목에서 상품정보가 필요하지만 상품 항목에서 주문정보는 필요하지 않다!
단방향으로 설정하게 되면 가볍고 유지보수와 최적화 면에서 유리합니다
하지만 단방향이 아니더라도 양방향으로 해놓고 한쪽만 사용한다거나 아예 조인을 끊고 id만 따로 저장하는 등 여러 방식이 존재합니다
3. Join이 꼭 필요한가
생명주기를 생각하자!
연관관계를 맺는 것은 객체의 '생명 주기'관점에서 바라봐야 합니다
두 객체가 서로 영향을 주고 생성과 삭제가 함께 이루어져야 하는 공생 관계라면 연관관계가 필요하고 아니라면 join에 대해서 다시 생각해 보아야 합니다
예) Order와 OrderItem는 서로 공생관계이다
주문이 없다면 주문된 상품은 존재할 이유가 없고 주문된 상품이 없는 주문은 존재할 수 없습니다
(부모 엔티티의 상태 변화가 연관된 자식 엔티티에도 자동으로 적용되도록 하는 기능인 영속성 전이(Cascade)와도 관련이 있습니다)
public class OrderItem {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "order_id", nullable = false)
private Order order;
}최신 정보 동기화가 필요한가!
join을 걸지 않고 독립적인 필드로 저장해서 사용하려 한다면 그것은 복사의 개념과도 같습니다
join을 걸 경우 최신화된 정보가 동기화 되지만 독립적인 필드로 저장한다면 저장되는 시점의 데이터가 기록됩니다
예) Item과 OrderItem은 동기화가 필요하지 않다
주문 당시의 물품 가격과 현재 등록된 물품 가격은 서로 동일하지 않을 수 있습니다
public class OrderItem {
@Column(name = "item_id", nullable = false)
private Long itemId;
}4. 결론 요약
어떤 경우에 어떤 방법이 좋을까?
| 상황 | 추천 방식 |
|---|---|
| 주문 내역에서 최신 상품 정보도 필요하다 | ✅ 양방향 + 스냅샷 |
| 주문 당시 가격과 이름을 100% 유지해야 한다 (변경 무관) | ✅ 조인 끊기 (독립적 저장) |
| 단순히 상품을 참조해야 하지만, 주문 당시 정보는 중요하지 않다 | ✅ 단방향 (N:1) |
N+1 문제 해결
| 해결 방법 | 장점 | 단점 |
|---|---|---|
| JOIN FETCH | 한 번의 쿼리로 해결 | 페이징 불가능, 데이터 중복 발생 가능 |
| @EntityGraph | 코드 변경 최소화 | 복잡한 연관관계 최적화 어려움 |
| @BatchSize | LAZY 유지하며 최적화 | 모든 상황에서 최적화되는 것은 아님 |
| default_batch_fetch_size | 전역 설정 가능 | 모든 엔티티에 적용됨, 세밀한 조정 어려움 |
| @Fetch(FetchMode.SUBSELECT) | Subquery 활용 최적화 | 쿼리 최적화 필요, 특정 상황에서만 효과적 |
| Pagination + @BatchSize | 페이징과 함께 최적화 가능 | 일부 쿼리는 여전히 비효율적일 수 있음 |
| JPA 2차 캐시 (Hibernate 2nd Level Cache) | 캐시 활용으로 성능 개선 | 캐시 유지 비용 발생, 최신 데이터 반영 어려움 |
| CQRS 패턴 활용 | 읽기/쓰기 분리로 성능 최적화 | 시스템 복잡도 증가, 유지보수 어려움 |
| 메모리 캐시 활용 (Redis, Ehcache 등) | DB 부하 감소, 빠른 조회 가능 | 데이터 동기화 필요, 메모리 사용량 증가 |
| 조회 전용 데이터베이스(Read Replica) | 읽기 성능 극대화 | 추가적인 인프라 비용 발생 |
| Materialized View (물리적 뷰) 활용 | 정해진 시점 기준으로 빠른 조회 가능 | 최신 데이터 반영이 실시간이 아님 |
| ElasticSearch 등 검색엔진 활용 | 대량 데이터 조회 성능 향상 | DB와 동기화 비용 발생, 추가적인 유지보수 필요 |
위에서부터 여러 기준을 두어 join 여부를 결정하는 데 가장 큰 이유는 한 번의 쿼리로 원하는 데이터를 가져오지 못하고 불필요한 N개의 쿼리가 발생하는 N+1 문제 때문인데요
해결할 수 있는 여러 키워드를 제시해 놓았으니 하나씩 고민해보시기 바랍니다

