프로젝트 2 - EDA
- 정형 데이터 분석
- 프로젝트 살펴보기
- EDA
[정형 데이터 분석]
-
정형 데이터 : 엑셀 파일이나 관계형 데이터베이스의 테이블에 담을 수 있는 데이터로, 행과 열로 표현 가능한 데이터다. 행은 데이터 인스턴스 하나를 나타내고 각 열은 데이터의 feature를 나타낸다.
-
비정형 데이터 : 이미지, 비디오, 음성, 자연어 등 정제되어 있지 않아서 테이블로 표시할 수 없는 데이터
정형 데이터는 분야를 막론하고 필수적인 데이터다. 로그를 남겨서 얻을 수 있는 데이터가 정형 데이터 형식이다.
- 정형 데이터 분석의 중요성
귀환한 전투기의 탄환 자국
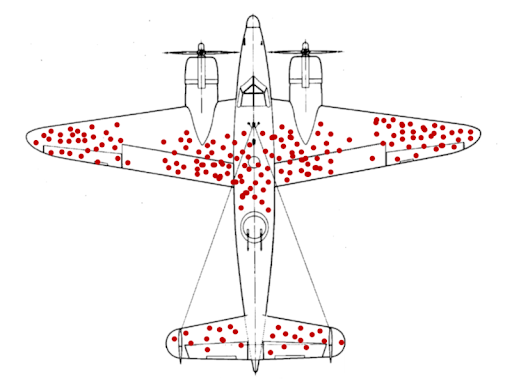
돌아온 전투기가 총을 맞은 곳에 철판을 대서 보강해도 효과가 없다. 진짜 치명적인 곳에 맞은 전투기는 귀환하지 못했기 때문에 오히려 총 맞고 돌아온 위치는 치명적이지 않다는 것
[프로젝트 살펴보기]
사용할 데이터 분석
2009.12~2011.11까지 온라인 상점의 거래 데이터
데이터 행 수는 780502개, 컬럼은 9개로, 고객의 구매 내역이 시간순으로 입력되어 있다.
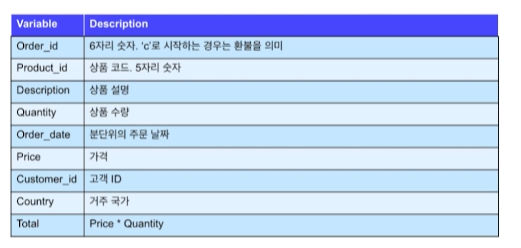
문제 정의
x : 고객 5914명의 2009년 12월부터 2011년 11월까지의 구매 기록
y : 5914명의 고객 각각에 대해 2011년 12월 총 구매액이 300을 초과하는지 여부 (이진 분류 문제)
이 데이터는 타겟 마케팅을 통한 혜택 제공이나 고객 추천에도 써먹을 수 있다.
[평가 지표]
-
accuracy(정확도) : (TP+TN)/(TP+TN+FP+FN)
데이터가 불균형할 때는 부적합. 100명 중에 암 환자가 1명 있는데 전부 건강하다고 예측한 경우 accuracy는 99%지만 암 진단을 정확하게 하는 경우가 더 중요하기 때문에 이와 같은 경우에 좋은 평가 지표가 아님 -
precision(정밀도) : TP/(TP+FP)
모델이 n번 예측했는데 그 중에 맞춘 게 얼마나 되나
모델이 positive라고 예측한 것 중 실제 값이 positive인 것의 비율로, negative를 positive로 분류하면 안 되는 경우에 사용한다. 스팸 메일을 분류하는 경우 스팸이 아닌 일반 메일(negative)를 스팸 메일(positive)로 분류하면 안 된다.
recall(재현율) : TP/(TP+FN)
n개의 정답 중 모델이 맞춘 게 얼마나 되나
실제 값이 positive인 것 중 모델이 positive로 분류한 것의 비율로, positive를 negative로 분류하면 안 되는 경우에 사용한다. 암 진단을 하는 경우 암(positive)을 정상(negative)로 분류하면 안 된다.
[EDA]
각 피쳐의 특성, 서로 연관된 피쳐들 사이의 관계를 살펴보는 과정
가설을 세우고 검증하는 방식으로 데이터를 살펴볼 수도 있다.
가설:이전 달의 총 구매액이 끼치는 영향, 작년 12월의 총 구매액이 끼치는 영향, 거주 국적에 따른 영향, 주로 구매하는 품목 등
가설을 확인하면서 데이터의 특성을 파악하기
12월 구매액은 모르니까 레이블은 다른 걸로 만들어야 함
음수 데이터 : c로 시작하면 환불 주문임(구매액이 음수)
구매 건수가 많다면 구매금액도 높을 것이다.
특정 달의 구매 금액은 작년 같은 달과 관련이 있을 것이다.
비싼 상품들
가장 많이 구매된 상품들
가장 많이 산 사람?
사람이 5914명이라 막대그래프 말고 꺾은선차트로...
[피어 세션]
TN FN어쩌구들 설명을들엇다 이해햇음!
EDA - 상품id에 붙어있는 알파벳 의미를 알아보기 위해? 카테고리 분류
상품적 측면에서 접근? 고객 측면에서 접근? 이 두 개를 앙상블하면?
