프로젝트 2 - 트리 모델
의사 결정 트리
bagging = bootstrap(데이터를 여러번 샘플링) + aggregation(취합)
데이터셋을 샘플링하여 모델을 만듬
샘플링한 데이터셋으로 하나의 의사결정트리를 만든다
생성한 의사결정트리의 결정들을 취합(aggregation)하여 하나의 결정 생성
병렬 모델, 다양한 tree 생성
boosting
처음에 랜덤하게 선택한 데이터셋의 일부로 트리를 만듬
초기에 맞추지 못한 데이터에 가중치를 줘서 또 트리를 만듬
순차적 모델, 정밀한 tree 생성
XGBoost, CatBoost는 균형적 구조
LightGBM은 비균형적 구조
하이퍼파라미터
학습율, 트리의 깊이, 잎사귀 수
column sampling ratio - 트리를 여러 개 만들 때 column을 랜덤하게 골라서 만든다
row sampling ratio - 트리를 여러 개 만들 때 row를 랜덤하게 골라서 만든다
트리 모델마다 하이퍼파라미터 이름이 다르다
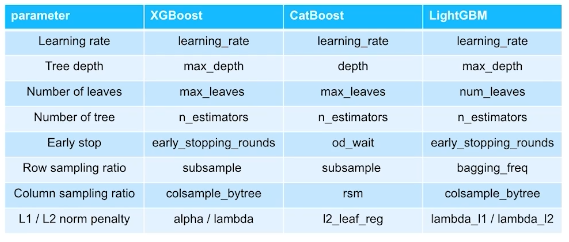
하이퍼파라미터 실습
LigtGBM, CatBoost는 pandas의 category 데이터타입을 사용할 수 있음(각 column/row는 object 타입이라서 얘를 category로 변환해야 하긴 함).
XGBoost는 numeric 데이터만 사용 가능함(labelencoding 등의 전처리 필요)
궁금했는데 알게된거
레이블이 없는데 어떻게 학습을 시키나? > 11년 10월까지의 데이터를 학습으로 사용, 월별로 고객별 총 구매액이 인자로 받는 임계값을 넘는지의 여부를 바이너리 레이블로 생성
