딥러닝
QnA
- Fully Connected Network 에는 1차원형태로 네트워크에 데이터를 주입해야 하는데 어떻게 비정형 데이터(표형태가 아니라 이미지, 음성, 텍스트 등)를 잘 다룰까요?
-> 전처리 레이어에서 이미지, 음성, 텍스트 등을 전처리 하는 기능을 따로 제공합니다. => DNN => CNN => RNN 순으로 배울거에요.
-> DNN(Deep Neural Network)
-
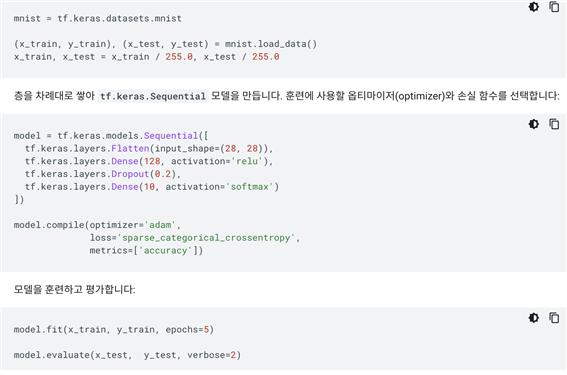
왜 28x28 이미지를 입력받을 때 784 로 입력받을까요?
-> Fully Connected Network 에는 1차원형태로만 주입이 가능하기 때문 네트워크에 데이터를 주입하기 위해서 CNN, RNN 에서는 데이터 전처리를 어떻게 해줄지를 전처리 기능을 제공하고 마지막에는 Fully Connected Network 를 통과하게 됩니다. -
임계값은 활성화 함수 == activation function 의 출력 기준이 됩니다. 이 그림에서 활성화 함수는 무엇일까요?
-> 시그모이드 -
sigmoid 의 단점 어제 슬라이드에서 기억나는 게 있다면?
-> Gradient vanishing -
이 문제를 해결하기 위해 나온 활성화 함수는 무엇이 있을까요?
-> 렐루, 리키렐루 -
dropout 이 무엇일까요?
-> 일부 노드를 제거하고 사용하는 것 -
그럼 왜 dropout을 사용할까요?
-> 과대적합(과적합, 오버피팅)을 방지하기 위해 일부 노드를 제거하고 사용하는 것입니다. -
분류 결과의 품질을 측정하기 위해 Loss 손실함수로 크로스엔트로피를 사용하는데 공식 앞에 마이너스는 왜 있을까요?
-> 양수로 만들어주기 위해서 -
특정 클래스에 대한 출력이 [0.1, 0.05, 0.7, 0.15] 이렇게 결과가 나왔다면 여기에서 예측값의 답을 무엇으로 하면 될까요?
-> 2 -
특정 클래스에 대한 출력이 [0.1, 0.05, 0.7, 0.15] 이렇게 결과가 나왔다면 이 정답 클래스의 종류의 개수는 몇 개일까요?
-> 4개 -
tf.keras.layers.Dropout(0.2)
여기서는 딱 0.2 만 드랍아웃을 하는 건가요? 아니면 그 아래값도 다 dropout 하는 건가요?
-> 노드의 개수 * 0.2 만큼의 수를 드랍아웃(제거) 합니다. 그 아래 값은 출력층이라 상관 없어요. 해당 층에 있는 노드(units)만 제거합니다. -
옵티마이저를 사용하는 이유?
-> loss 함수를 최소로 만들기 위해서 -
MNIST 실습과 FMNIST 실습의 차이점?
-> mnist는 dropout을 해줌
-> FMNIST에서는 출력층에서 softmax안써주고 10 만 써줌
-> 데이터가 다름
딥러닝
완전연결신경망 - Fully Connected Network
층을 깊게 쌓을 수 있기 때문에 Deep Neural Network 라 부릅니다
- W == Weight 의 약자로 보통 가중치로 번역됩니다.
- b == bias 의 약자로 보통 편향으로 번역됩니다.
Dense
output = activation(dot(input, kernel) + bias)
출력 = 활성화함수(행렬곱(input, kernel) + 편향)
tf.keras.layers.Dense(units=128, activation='relu')
=> units(노드) 개수, 층(레이어)수는 하이퍼파라미터입니다.
softmax
각 클래스의 확률을 출력하는데, 다 더하면 1이 된다.
np.argmax
np.argmax 는 가장 큰 값의 인덱스를 반환합니다.
활성화 함수(Activation Function)
- 활성화 함수는 은닉층과 출력층의 뉴런에서 출력값을 결정하는 함수로 가중치 생성(전위를 만들어 신호 생성)
- 입력값들의 수학적 선형 결합을 다양한 형태의 비선형(또는 선형) 결합으로 변환하는 역할
의류 이미지 분류
units == 노트 == 뉴런
탠서플로와 파이토치의 차이
텐서플로 VS 파이토치의 차이는 seaborn VS plotnine 처럼 라이브러리 도구의 API 차이 입니다.
시각화 할 때도 data, x, y, color(hue) 이런 용어를 알고 있다면 API 가 달라지더라도 비슷하게 사용할 수 있는 것과 유사합니다.
직접 딥러닝 모델을 밑바닥부터 짜서 구현할 수도 있지만, 기능들을 함수나 메서드로 감싸서 코드 여러 줄을 한 두줄의 API 를 호출해서 사용할 수 있게 만들어 놓은 도구입니다.
분류
분류:binary_crossentropy(이진분류)
categorical_crossentropy
(다중분류: one-hot-encoding)
sparse_categorical_crossentropy
(다중분류: ordinal Encoding)
epoch
- epoch가 증가할수록 loss가 줄어들고 accuray가 올라간다.
- epoch가 증가할수록 loss가 감소하지 않고, accuracy가 나아지지 않는다면 더 이상 학습하지않고 중단할 수 있다.
- loss는 cross entropy를 사용하는데 확률값이 얼마나 섞여있냐를 본다.
- 0에 가까울수록 다른 확률값이 섞여있지 않은 것이다.
옵티마이저
- 모델이 인식하는 데이터와 해당 손실 함수를 기반으로 모델이 업데이트되는 방식입니다.
Summary
1) 다른 데이터에 적용한다면 층 구성을 어떻게 할것인가? 입력-은닉-출력층으로 구성됩니다.
2) 예측하고자 하는 값이 분류(이진, 멀티클래스), 회귀인지에 따라 출력층 구성, loss 설정이 달라집니다.
3) 분류, 회귀에 따라 측정 지표 정하기
4) 활성화함수는 relu 를 사용, optimizer 로는 adam 을 사용하면 baseline 정도의 스코어가 나옵니다.
5) fit 을 할 때 epoch 를 통해 여러 번 학습을 진행하는데 이 때, epoch 수가 많을 수록 대체적으로 좋은 성능을 내지만 과대적합(오버피팅)이 될 수도 있습니다.
6) epoch 수가 너무 적다면 과소적합(언더피팅)이 될 수도 있습니다.
출력층
- 소프트맥스 일 때 : N개의 노드의 소프트맥스(softmax) 층입니다. 이 층은 N개의 확률을 반환하고 반환된 값의 전체 합은 1입니다.
각 노드는 현재 이미지가 N개 클래스 중 하나에 속할 확률을 출력합니다. - 시그모이드 일 때 : 둘 중 하나를 예측할 때 1개의 출력값을 출력합니다. 확률을 받아 임계값 기준으로 True, False로 나눕니다.
출력층 : - 예측 값이 n개 일 때 : tf.keras.layers.Dense(n, activation='softmax')
- 예측 값이 둘 중 하나일 때 : tf.keras.layers.Dense(1, activation='sigmoid')
학습
배치(batch): 모델 학습에 한 번에 입력할 데이터셋
에폭(epoch): 모델 학습 시 전체 데이터를 학습한 횟수
스텝(step): (모델 학습의 경우) 하나의 배치를 학습한 횟수
출처
- 멋쟁이사자차럼 AI스쿨 박조은강사님
