배치란?
모델의 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음ex) 만약 총 1000개의 훈련 샘플이 있는데, 배치사이즈가 20이라면
20개의 샘플 단위마다 모델의 가중치를 한번씩 업데이트 시킨다.
그래서 가중치가 총 50번 업데이트 된다.
하나의 데이터셋을 총 50개의 배치로 나눠서 훈련을 진행했다고 보면 된다.
배치정규화란?
- 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 학습을 효율적으로 만듭니다.
- 학습하는 과정 자체를 전체적으로 안정화하여 학습 속도를 가속시킬 수 있는 근본적인 방법으로 각 층에서의 활성화값(출력값)이 적당히 분포되도록 조정하는 것
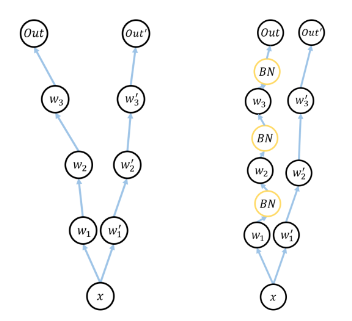
배치 정규화는 2015년 arXiv에 발표된 후 ICML 2015에 게재된 아래 논문에서 나온 개념
Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
Internal Covariance Shift
배치정규화 논문에서는 학습에서 불안정화가 일어나는 이유를 ‘**Internal Covariance Shift**’라고 주장하는데, 이는 네트워크의 각 레이어나 Activation 마다 입력값의 분산이 달라지는 현상을 뜻한다.Covariate Shift: 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상Internal Covariate Shift: 레이어를 통과할 때 마다 Covariate Shift가 일어나면서 입력의 분포가 약간씩 변하는 현상
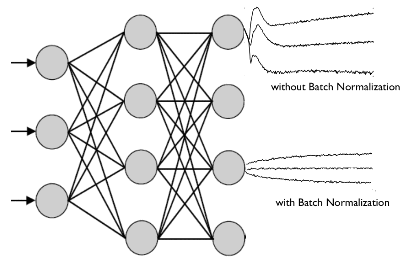
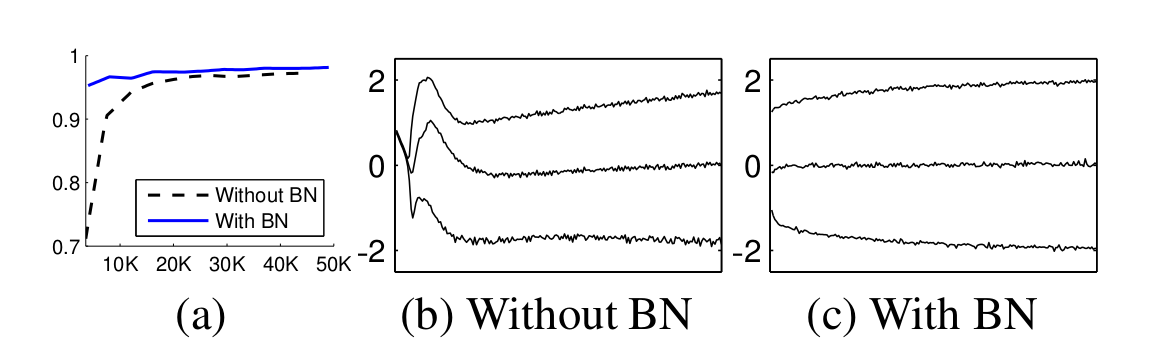
MNIST 에서의 배치 정규화 실험 결과 이다.- 딥러닝에서 층에서 층으로 이동될 때마다 이전 층들의 학습에 의해 가중치 값이 바뀌게 되면, 현재 층에 전달되는 입력 데이터의 분포와 현재 층에 학습했던 시점의 분포와 차이가 발생한다.
- 이러한 층 별로 입력데이터 분포가 달라지는 현상을 내부 공변량 변화(Internal Covariate Shift)라고 한다.
배치 정규화가 이루어지는 시점
각 층에서 활성화 함수를 통과하기 전에 수행!
배치정규화 알고리즘

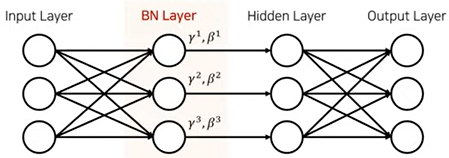
출처: https://youtu.be/58fuWVu5DVU 스크린샷
- 먼저, 은닉층(hidden layer)의 활성화함수 입력값or출력값 상태인 배치의 평균과 분산을 계산한다.
- 이후, 해당 배치를 평균 0, 분산 1이 되도록 정규화한다.
- 엡실론(ε)은 분모가 0 이 되는 것을 막기 위한 아주 작은 숫자(1e-5)이다.
- 정규화 이후, 배치 데이터들을 scale(감마(γ)), shift(베타(β)) 를 통해 새로운 값으로 바꾼다.
- 데이터를 계속 정규화 하게 되면, 활성화 함수의 비선형 성질을 잃게 되는 문제가 발생한다.
- 예를 들면, 아래 그림과 같이 Sigmoid 함수가 있을 때, 입력 값이 N(0, 1) 이라면, 95% 의 입력 값은 Sigmoid 함수 그래프의 중간 (x = (-1.96, 1.96) 구간)에 속하게 된다.
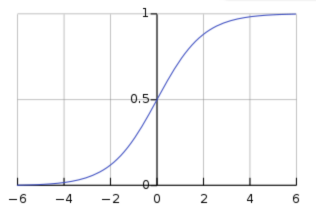
- 해당 부분이 선형이기 때문에, 비선형 성질을 잃게 되는 것이다.
- 하지만, **감마(γ), 베타(β)**를 통해 **활성함수로 들어가는 값의 범위를 바꿔줌**으로써, **비선형 성질을 보존**하게 된다.
- **감마(γ), 베타(β)** 값은 학습 가능한 변수이며, **역전파(Backpropagation)을 통해서 학습**이 된다.배치 정규화의 장점
- 배치 정규화는 단순하게 평균과 분산을 구하는 것이 아니라 감마(Scale), 베타(Shift) 를 통한 변환을 통해 비선형 성질을 유지 하면서 학습 될 수 있게 해줌
- 배치 정규화가 신경망 레이어의 중간 중간에 위치하게 되어 학습을 통해 감마, 베타를 구할 수 있음
- Internal Covariate Shift 문제로 인해 신경망이 깊어질 경우 학습이 어려웠던 문제점을 해결
- gradient 의 스케일이나 초기 값에 대한 dependency 가 줄어들어 Large Learning Rate 를 설정할 수 있기 떄문에 결과적으로 빠른 학습 가능함, 즉, 기존 방법에서 learning rate 를 높게 잡을 경우 gradient 가 vanish/explode 하거나 local minima 에 빠지는 경향이 있었는데 이는 scale 때문이었으며, 배치 정규화를 사용할 경우 propagation 시 파라미터의 scale 에 영향을 받지 않게 되기 때문에 learning rate 를 높게 설정할 수 있는 것임
- 정규화 효과가 있기 때문에 dropout 등의 기법을 사용하지 않아도 된다. (효과가 같기 때문)
- 학습률을 더 천천히 줄일 수 있다.
- 입력의 범위가 고정되기 때문에 saturating 한 함수를 활성화 함수로 써도 saturation 문제가 일어나지 않음 (saturation 문제: 가중치의 업데이트가 없어지는 현상)
- Smoothing 효과 : Batch Normalization은 Optimization Landscape를 부드럽게 만드는 효과가 있다.
- Smoothing효과로 global optimum에 도달하기 쉬워진다.
- Batch Normalization은 2015년 이후 수상작에 모두 적용될 정도로 좋은 기법이다.
배치 정규화의 한계
- Mini - batch에 의해 크게 영향을 받음 너무 작은 배치 크기에서는 잘 동작 x 배치 정규화의 효과가 극단적으로 작용되어 훈련에 악영향을 끼칠 수 있음
- 메모리의 한계로 인해 RNN이나 크기가 큰 CNN에 적용하기 어려움 각 시점마다 다른 통계치를 가지는 RNN은 배치 정규화 적용이 어려움
- 배치의 크기가 너무 커도 잘 동작하지 않음
- 병렬화 연산 효율이 떨어짐
배치 정규화 Traing과 Test
BN은 테스트 시와 학습 시에 적용하는 방법이 다름.
학습 시에 각 mini-batch 마다 γ와 β를 구하고 그 값을 저장해 놓는다.
Test 시에는 학습 시 mini-batch 마다 구했던 γ와 β의 평균을 사용한다는 점이 다르다.
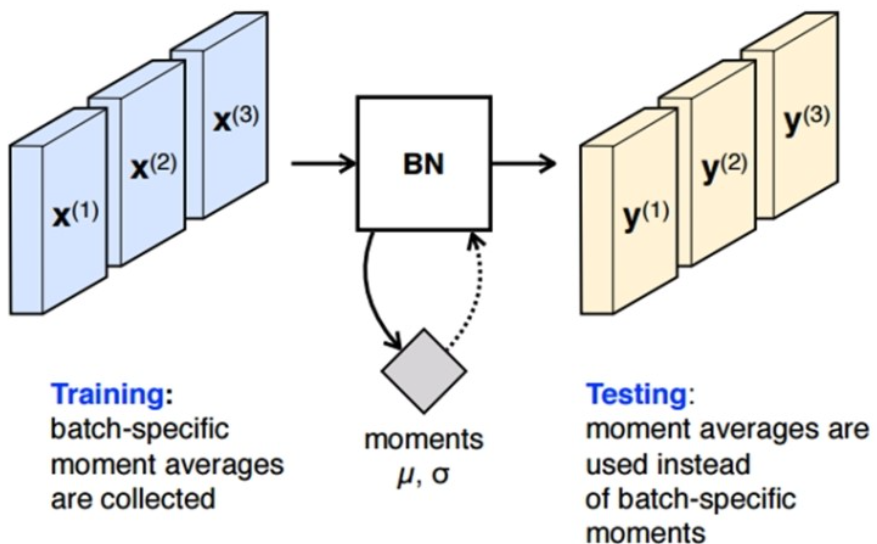
테스트 시의 유사 코드는 아래와 같다. 유사 코드를 보면 알 수 있듯이 평균은 각 mini-batch에서 구한 평균들의 평균을 사용하고, 분산은 분산의 평균에 m/(m-1)을 곱해주는 점이 다르다.
여기서 m/(m-1)을 곱해주는 이유는 통계학적으로 unbiased variance에는 “Bessel’s correction"을 통해 보정을 해주는 것이다. 이는 학습 전체 데이터에 대한 분산이 아니라 mini-batch 들의 분산을 통해 전체 분산을 추정할 때 통계학적으로 보정을 위해 베셀의 보정값을 곱해주는 방식으로 추정하기 때문이다.

배치 정규화 코드
tf.layers.batch_normalization
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization
model1 = Sequential([
# 입력층은 (4,0)의 형태를 가지며, 유닛 64개로 구성
Dense(64, input_shape=(4,), activation="relu"),
# 입력층 다음으로 유닛 128개를 갖는 밀집층을 두 개 구성
Dense(128, activation='relu'),
Dense(128, activation='relu'),
# 유닛 64개로 구성된 밀집층이 두 개 더 있으며, 렐루(ReLU) 활성화 함수 사용
Dense(64, activation='relu'),
Dense(64, activation='relu'),
# 출력층은 유닛 세 개로 구성되며, 소프트맥스를 활성화 함수로 사용
Dense(3, activation='softmax')
]);
model1.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
) ------ ①
history1 = model1.fit(
X_train,
y_train,
epochs=1000,
validation_split=0.25,
batch_size=40,
verbose=2
)
loss_and_metrics = model1.evaluate(X_test, y_test)
print('## 손실과 정확도 평가 ##')
print(loss_and_metrics)
## 아래는 위 코드에 대한 결과
1/1 [==============================] - 0s 1ms/step - loss: 0.5317 - accuracy: 0.9333
## 손실과 정확도 평가 ##
[0.5316773653030396, 0.9333333373069763]- 배치 정규화 적용 O
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization
from tensorflow.keras.initializers import RandomNormal, Constant
model2 = Sequential([
Dense(64, input_shape=(4,), activation="relu"),
# 배치 정규화 과정 추가
BatchNormalization(),
Dense(128, activation='relu'),
# 배치 정규화 과정 추가
BatchNormalization(),
Dense(128, activation='relu'),
# 배치 정규화 과정 추가
BatchNormalization(),
Dense(64, activation='relu'),
# 배치 정규화 과정 추가
BatchNormalization(),
Dense(64, activation='relu'),
# 배치 정규화 과정 추가
BatchNormalization(
momentum=0.95,
epsilon=0.005,
beta_initializer=RandomNormal(mean=0.0, stddev=0.05),
gamma_initializer=Constant(value=0.9)
), ------ ①
Dense(3, activation='softmax')
]);
model2.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
history2 = model2.fit(
X_train,
y_train,
epochs=1000,
validation_split=0.25,
batch_size=40,
verbose=2
)** 배치 정규화에서 사용하는 파라미터는 다음과 같습니다.

ⓐ momentum: 엄청나게 많은 전체 훈련 데이터셋에 대한 평균과 표준편차를 계산하는 것이 어렵기 때문에 미니 배치마다 평균과 표준편차를 구해서 전체 훈련 데이터셋의 평균과 표준편차로 대체합니다. 미니 배치마다 적용되는 수식은 다음과 같습니다.
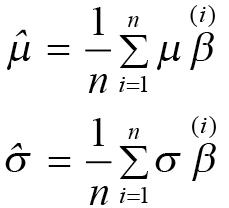
하지만 배치 정규화에서는 이 방법 대신 모델 학습 단계에서 지수 감소(exponential decay)를 이용하는 이동 평균법(moving average)을 사용하여 평균과 표준편차를 계산합니다.
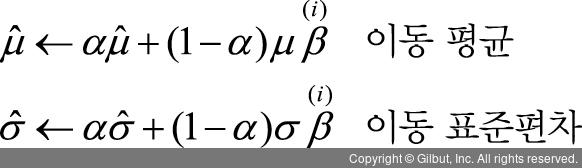
앞의 식은 모멘텀(momentum) 값으로, 일반적으로 1에 가까운 0.9, 0.99, 0.999로 설정합니다. 이러한 이동 평균(moving mean)과 이동 표준편차(moving stddev)는 학습 단계에서 모든 미니 배치마다 업데이트해 줍니다.
ⓑ epsilon: 분산이 0으로 계산되는 것을 방지하기 위해 분산에 추가되는 작은 실수(float) 값
ⓒ beta_initializer: 베타(β) 가중치 초깃값
ⓓ gamma_initializer: 감마(γ) 가중치 초깃값

loss_and_metrics = model2.evaluate(X_test, y_test)
print('## 손실과 정확도 평가 ##')
print(loss_and_metrics)
## 아래는 위 코드에 대한 결과
1/1 [==============================] - 0s 2ms/step - loss: 0.0778 - accuracy: 0.9667
## 손실과 정확도 평가 ##
[0.07776810228824615, 0.9666666388511658]정확도는 큰 차이가 없지만 손실이 53%에서 7%로 낮아졌습니다. 즉, 배치 정규화를 사용할 경우 모델 성능이 좋아지는 것을 확인할 수 있습니다.
참고문헌
