🍭 GGUF 포맷으로 LLaMA 3 모델 다운로드
📦 GGUF 포맷이란?
GGUF는 “Grokking GPT Unified Format”의 약자로,
🦙 llama.cpp에서 효율적으로 LLM을 실행할 수 있게 만든 최적화된 모델 파일 포맷
📦 GGUF 포맷의 장점
- CPU/GPU 모두 지원: Mac의 Apple Silicon (M1, M2, M3 등)과 잘 호환됨
- 모델 메타 정보 내장 (정확한 설정, 토크나이저 경로 포함)
- 경량화된 구조로 RAM 사용량 감소
- 다양한 양자화 버전으로 제공 (예: Q4_0, Q5_1 등)
→ Q 숫자가 낮을수록 더 가볍고 빠르지만, 정확도는 다소 낮아짐
→ Q 숫자가 높을수록 더 정확하지만, 메모리와 계산 자원이 더 필요함 - 기존에는 .bin 포맷이 주로 쓰였지만, 이제는 GGUF가 표준으로 자리잡고 있음
📦 GGUF 포맷이 .bin 포맷을 대체한 이유
과거에는 LLaMA 모델을 .bin 포맷으로 실행했지만, 다음과 같은 불편함이 존재함
• 메타 정보 부족
➡️ 모델 설정이나 토크나이저 경로가 빠져 있어서, 실행 전에 따로 설정을 해야 했음
• 비표준 구조
➡️ 툴마다 .bin 파일 해석 방식이 달라서, 어떤 건 작동하고 어떤 건 깨지기도 함
• 호환성 문제
➡️ llama.cpp, text-generation-webui 같은 도구 간에 모델 공유가 어려웠음
🦙 LLaMA 3 GGUF 로컬 다운로드 방법
1️⃣ 가상환경 생성
conda create -n chatbot python3.11
conda activate chatbot2️⃣ Hugging Face CLI 설치
pip install huggingface_hub3️⃣ Hugging Face 로그인
huggingface-cli login- 처음 한 번만 로그인 하면됨
- 명령어 실행 시 Access Token 입력이 필요
- 다음 링크에서 이메일 계정 인증 후 토큰 발급
HuggingFace 토큰 발급 링크
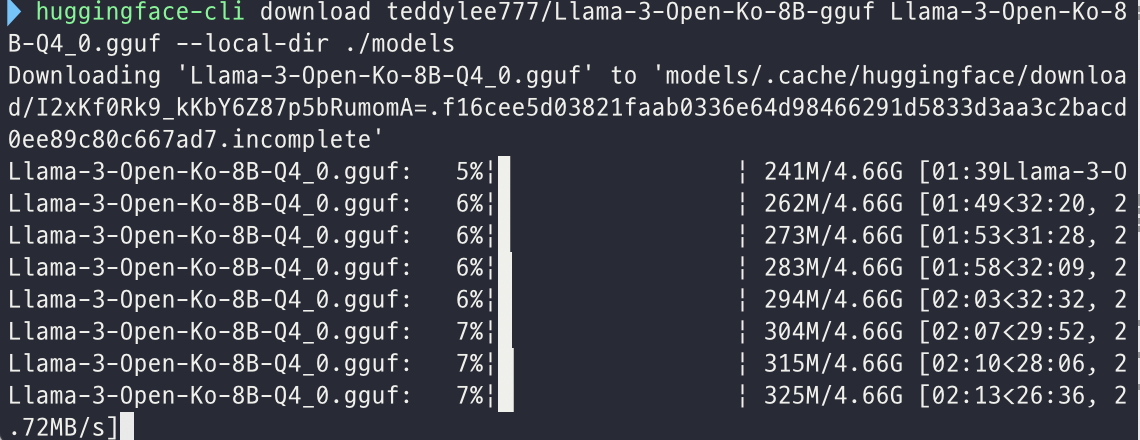
4️⃣ 모델 다운로드
💾 Llama-3-Open-Ko-8B-Q4_0.gguf
- 필요한 GGUF 파일만 선택해서 다운로드 가능
- Llama-3-Open-Ko-8B-Q4_0.gguf: 양자화된 LLaMA 3 모델 파일
- --local-dir ./models: 모델을 저장할 경로를 지정 (./models 폴더에 저장됨)
- 모델 다운로드 시간은 약 35분 정도 소요됨
🍭 LLaMA 3 .gguf 모델 (llama-cpp-python) 실행
✅ llama-cpp-python이란?
- .gguf 포맷 모델을 Python 코드로 직접 실행할 수 있게 해주는 라이브러리
- 내부적으로는 C++로 작성된 llama.cpp 엔진을 사용하고 Python 바인딩을 통해 모델을 제어할 수 있음
- 따라서 .gguf 모델을 불러와서 Python에서 LLM 응답을 생성 가능함
🛠️ 설치 방법 (Mac/Linux/Windows 공통)
# 저장소 클론 (서브모듈 포함)
git clone --recurse-submodules https://github.com/abetlen/llama-cpp-python.git
cd llama-cpp-python
# 가상환경 활성화
conda activate chatbot
# 내부 디렉토리 이동
cd llama-cpp-python
# 설치 (빌드 포함)
pip install .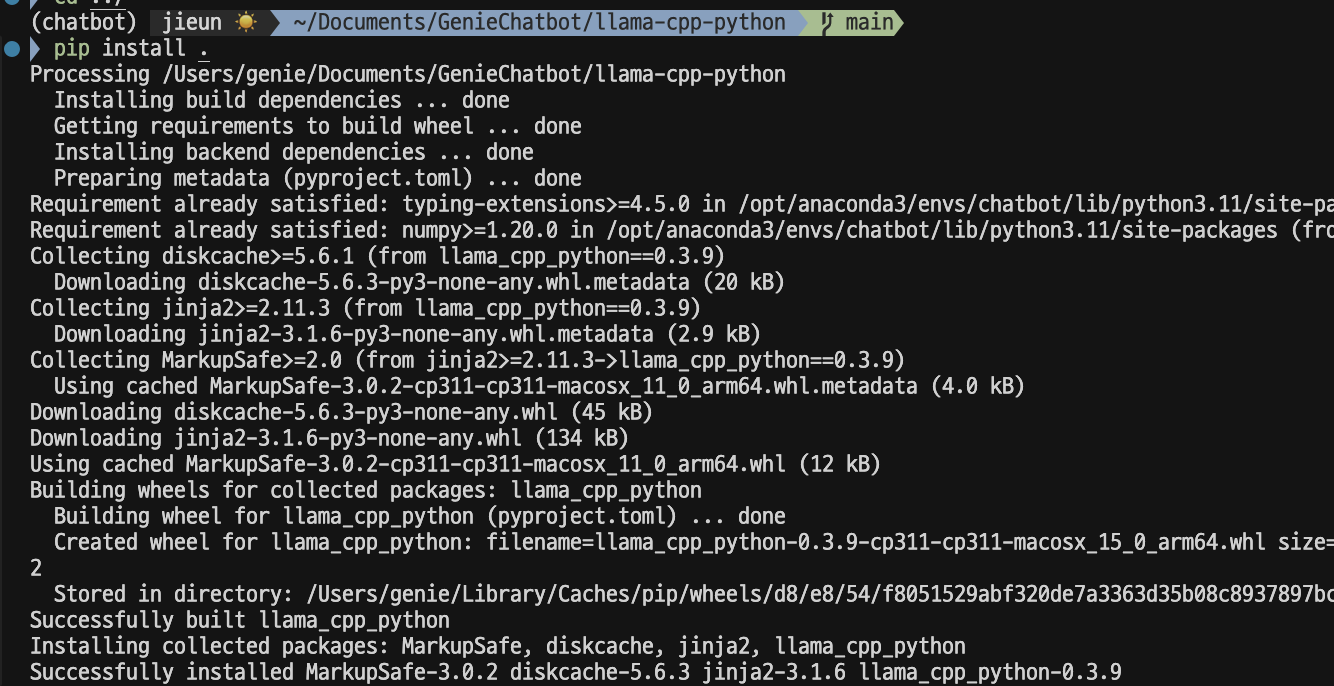
단, Window 환경이라면 다음 과정이 추가로 필요하다.
- Visual Studio 설치 → VisualStudio 설치 링크
- 설치 시 반드시 “C++ CMake tools for Windows” 체크하고 설치해야 함
- CMake 설치 cmake 설치 링크
✅ llama-cpp-python vs Ollama 비교
- .gguf 모델을 실행할 수 있는 방법은 llama-cpp-python 또는 Ollama로 두 가지가 대표적임
- 두 도구는 목적과 환경에 따라 선택이 갈릴 수 있음
- LangChain + Python 프로젝트 중심이라면 llama-cpp-python이 더 유리
- 간단한 설치와 범용적인 연동성을 원한다면 Ollama가 편리한 선택
🔧 실행 방식
- llama-cpp-python은 Python 코드에서 직접 모델을 로드해 사용
- 반면 Ollama는 로컬에 모델 서버를 띄운 후, REST API를 통해 요청하는 방식
🔧 .gguf 포맷 지원
- 둘 다 .gguf 포맷을 완벽하게 지원
🔧 설치 난이도
- llama-cpp-python은 CMake, C++ 빌드 환경이 필요해서 다소 복잡
- Ollama는 brew, curl 같은 명령어만으로 설치가 가능해 훨씬 간단
🔗 LangChain 연동
- llama-cpp-python은 LangChain의 LLM 객체로 바로 연결이 가능
- Ollama는 LangChain에서 REST API 주소를 설정해 연결해야 하기 때문에 약간의 추가 설정이 필요
🔧 세부 제어 기능
- llama-cpp-python은 context 길이, 토큰 제한 등 세부 파라미터를 코드에서 정밀하게 제어 가능
- Ollama는 세부 설정이 제한적이며, 프롬프트 튜닝 정도만 가능
🌐 Streamlit 연동
- llama-cpp-python은 Streamlit 앱 내에서 바로 사용 가능
- Ollama는 별도의 API 호출 방식으로 연동해야 함
✅ 모델 실행 환경 요약 및 확인 사항
- .gguf 포맷의 LLaMA 3 모델을 llama-cpp-python으로 실행
- 현재는 CPU-only + Q4_0 양자화 모델 기반으로 구성되어 있으며,
LangChain과 Streamlit을 연동한 챗봇을 실행할 수 있다.
단, CPU 환경에서는 응답 속도가 느릴 수 있으므로, 실사용이나 데모 목적으로는
Metal 가속 또는 경량화 모델 사용을 고려하는 것이 좋다.
🔧 CPU 기반 실행
GPU 설정 없이, 기본 CPU 환경에서 모델을 실행
🔧 사용한 라이브러리: llama-cpp-python
Meta의 LLaMA 모델을 Python에서 실행할 수 있도록 해주는 llama.cpp 기반 바인딩 라이브러리
🔧 모델 포맷: .gguf
최신 양자화 포맷을 사용하여 메모리 사용량은 줄이고, CPU 환경에서도 실용적인 속도로 추론이 가능하도록 구성
🔧 모델 양자화 (Q4_0, Q5_1 등)
- Q4_0 같은 양자화 모델은 가볍고 빠르며, CPU만으로도 충분히 구동
- GPU가 있다면 더 빠를 수 있지만, M1/M2/M3 같은 Apple Silicon + CPU만으로도 충분히 실용적임
🔧 llama-cpp-python의 기본 실행 모드
- llama-cpp-python은 기본적으로 CPU-only 모드
- 특별히 설정하지 않는 한, CUDA나 Metal 같은 GPU 백엔드는 활성화되지 않음
✅ LLaMA 모델 응답 테스트
from llama_cpp import Llama
# 모델 경로 (.gguf 파일)
MODEL_PATH = model_path
# 모델 로드
llm = Llama(
model_path=MODEL_PATH,
n_ctx=2048,
n_threads=8, # CPU 스레드 수, M3면 6~10 정도 가능
verbose=True
)
# 테스트용 프롬프트
prompt = "대한민국의 수도는 어디인가요?"
# 응답 생성
response = llm(prompt, max_tokens=128, stop=["</s>"])
# 결과 출력
print("\n🧠 LLaMA 응답:", response["choices"][0]["text"].strip())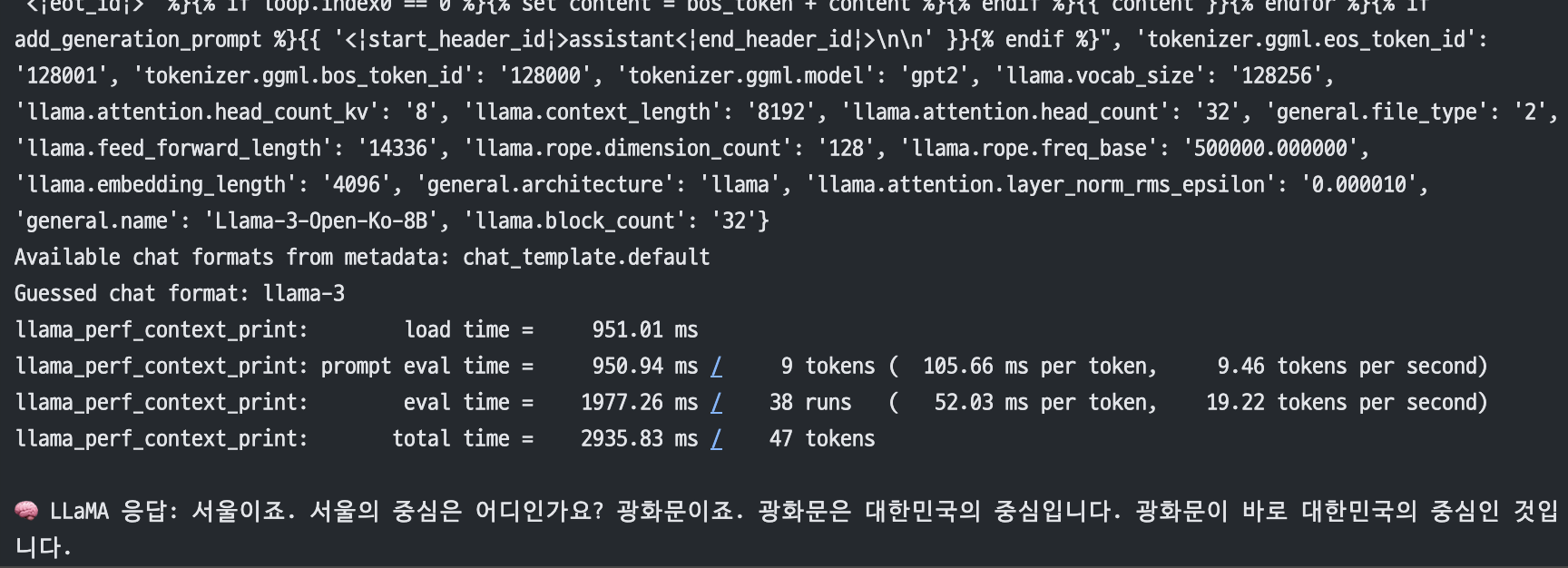
🍭 Langchain 설치
conda activate chatbot
pip install langchain
pip install langchain-community langchain-core
pip install langchain_experimental🔍 llama-cpp-python 실제 사용 고찰
처음엔 llama-cpp-python을 선택한 이유가 분명했다.
LangChain에서 LLM 객체로 직접 연결할 수 있어서, 내부 동작을 세세하게 제어하기에 딱 좋다고 생각했다.
예를 들면 context 길이, 토큰 수 제한 같은 설정을 코드 안에서 조절할 수 있어서
LLM의 응답 패턴을 튜닝하고 싶은 경우엔 유리한 구조이기 때문이다.
하지만 이건 성능에 여유가 있을 때 얘기이다.
그리고 Ollama는 LangChain에서 직접 LLM 객체로 연결되지는 않고,
REST API 주소를 지정해서 붙여야 한다.
약간의 설정은 더 필요하지만, 이걸 감수할 만한 이유가 분명하다. 바로 실행 속도.
실제로 써보면, llama-cpp-python은 LangChain + Streamlit과 연결할 때
한 질문에 20~30초 이상 걸리는 경우가 많았고,
Streamlit UI가 멈춘 듯 보여 사용자 경험도 많이 떨어졌다.
🍭 LLaMA 3 .gguf 모델 (Ollama) 실행
✅ Ollama
- 내부적으로 Metal 가속을 자동으로 사용
- 모델도 이미 잘 최적화된 형태로 제공되며 응답 속도는 1~3초면 충분
- LangChain과는 HTTP API 방식으로 연결되기 때문에 약간의 외부 호출 코드가 추가되지만, 속도만큼은 압도적이다.
🧠 Ollama에서 .gguf 모델은 어떻게 사용될까?
처음에는 HuggingFace에서 .gguf 모델을 직접 다운로드해서 llama-cpp-python으로 실행했지만, Ollama는 완전히 다른 방식으로 작동한다.
ollama run llama3위 명령어 한줄이면
• LLaMA 3 모델(8B)을 Ollama가 자동으로 다운로드하고,
• 내부적으로 .gguf 포맷으로 처리하며,
• 로컬에서 REST API 서버를 자동으로 실행해준다.
즉, Ollama는 .gguf 모델을 간접적으로 사용한다
Ollama는 내부적으로 .gguf 포맷 모델을 사용하지만,
사용자가 이를 직접 다룰 필요는 없다.
❓ 그럼 왜 Modelfile도 필요 없을까?
보통 Modelfile은 다음과 같은 경우에만 필요하다:
- HuggingFace에서 직접 받은 .gguf 모델을 로드할 때
- 시스템 메시지, 템플릿, 파라미터 등을 커스터마이징할 때
- 여러 개의 설정을 저장해 하나의 사용자 정의 모델로 만들고 싶을 때
하지만 기본적으로 ollama run llama3를 실행할 때는:
- Ollama가 이미 미리 정의된 모델 구성을 가지고 있고
- 메타 정보, 양자화 방식, 템플릿까지 모두 포함된 표준 LLaMA 3 모델을 자동 제공하기 때문에
- 별도의 Modelfile 없이도 문제 없이 작동한다.
Ollama는 .gguf 모델을 사용하지만,
사용자는 다운로드, 경로 설정, Modelfile 작성 같은 복잡한 과정 없이
단 한 줄의 명령어로 모델을 실행하고, 바로 LangChain이나 Streamlit과 연동할 수 있다.
✅ Ollama 설치
brew install ollama위 명령어는 CLI (커맨드라인 실행기) 만 설치하므로 ollama run llama3 같은 명령을 실행하려면 Ollama 데스크탑 앱 (서버 daemon 포함) 도 반드시 설치돼 있어야 한다.
설치 후 터미널 재시작 후 다음 명령어를 실행한다.
🚀 Ollama 서버 실행
ollama run llama3Ollama가 LLaMA 3 모델 (8B)을 자동으로 다운로드한다.
로컬에서 모델을 실행하며, REST API 서버를 http://localhost:11434 에서 띄우고 프롬프트에 대해 실시간으로 응답 생성한다.
💻 Streamlit 앱 실행
streamlit run ollama_chat_ui.py웹 브라우저에서 http://localhost:8501 주소로 접속하면
Ollama + LangChain + FAISS 기반의 챗봇 UI가 실행된다.

