XAI (eXplainable AI)
XAI는 인공지능 모델이 어떤 근거로 예측을 하는지 그 이유(Why)를 설명하는 분야다.
(모델의 의사결정 과정을 이해할 수 있도록 만드는 방법)
Modeling을 통해서 높은 예측력을 보이면 되는 문제도 있지만, 현실의 많은 문제는 왜 그러한 예측력을 보이는지 Why에 관심이 많다.
아래에서는 이러한 Why 를 알 수 있는 4가지 방법들을 소개한다.
- 문제 발단
-
복잡도가 증가하는 딥러닝, Black-Box Model은 어떻게 해석해야 할까?
-
다양한 알고리즘을 동일한 기준으로 해석해 볼 수는 없을까?
-
모델에 의존적이지 않게 해석하고 싶다.
⇒ 쉬운 방법으로는 각각의 개별변수만 남기던가 빼서 학습하여 비교하면 어떤 변수가 중요 변수인지 알 수 있다. → 시간 오래 걸리며 비효율적
-
1. Permutation Importance (순열 중요도)
- 목적 각 특성(Feature)이 예측에 얼마나 중요한지 측정한다.
- 원리
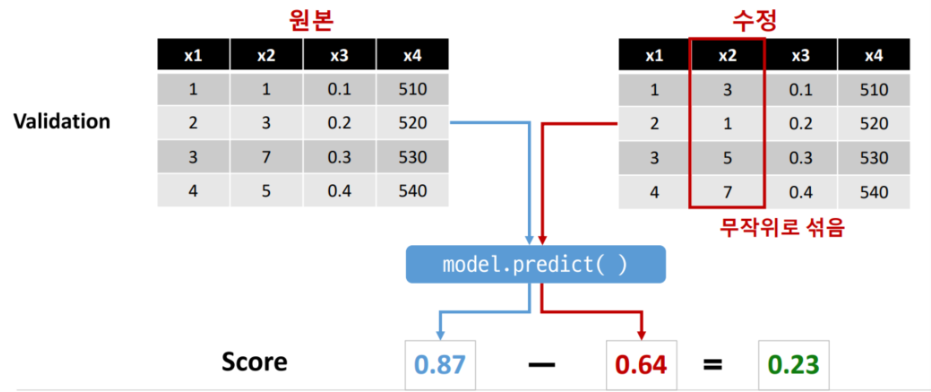
하나의 특성 값(변수 값)을 무작위로 섞은 뒤, 성능(정확도)이 얼마나 떨어지는지 확인하여 중요도를 측정한다.
- 재학습 하지 않고, 기존의 학습된 모형에 Original set vs Permutation set을 예측하여 오차를 비교한다.
- 중요한 특성을 무작위로 섞으면 성능이 크게 떨어진다.
- 중요하지 않은 특성을 섞으면 성능이 거의 떨어지지 않는다.
- 장점
- 이미 학습된 모델을 활용하여 중요도를 쉽게 측정할 수 있어 계산 비용이 낮다.
- 특성(Feature) 간의 중요도 비교가 매우 명확하고 직관적이다.
- Feature 간의 상호작용(Interaction)을 자동적으로 고려한다.
- 모델과 무관하게 모든 머신러닝 모델에서 적용 가능하다. (Model-agnostic)
- 단점
- 특성이 증가하면 예측이 어떻게 바뀌는지 영향의 방향성(양/음)을 알 수 없다.
- 이상치가 있을 경우 중요도가 왜곡될 수 있다.
- 무작위로 특성 값을 섞는 방식이므로 수행할 때마다 결과가 약간씩 변할 수 있다. (중요도가 다르게 나타나는 불안정성)
- 특성 간 상관관계가 높으면 결과가 부정확할 수 있음
- 고려사항 ① 어떤 Dataset을 활용해야 할까? [ Train data set vs Test data set ]
-
Train Data Set를 활용하는 경우
- 모델은 학습 과정에서 어떤 Feature가 중요한지 이미 학습했기 때문에, 학습 데이터의 경향성을 잘 반영하는 특성 중요도를 계산한다.
-
Test Data Set를 활용하는 경우
- Test 데이터를 활용하면 모델의 일반화 능력(새로운 데이터에 대한 성능)을 보다 객관적으로 평가할 수 있다.
- 특히 모델이 과적합되었는지를 잘 드러낼 수 있다.
- 일반적으로 Test 데이터를 사용하는 것이 신뢰도가 높다고 평가된다.② Permutation FI가 (-)값이 나온다면?
Permutation Importance는 기본적으로,
특정 Feature의 값을 무작위로 섞으면(Permutation) 예측 성능이 나빠질 것이란 가정에서 출발한다.
정상적이라면, Permutation 이후 예측 오차(Error)는 원래 모델의 오차보다 커져야 하므로, 중요도 값은 일반적으로 양수(+)여야 한다.
하지만, 음수(-)가 나온다는 것은 해당 Feature를 섞었더니 오히려 모델의 성능이 더 좋아졌다는 의미이기도 하다.
즉, 섞기 전 이 Feature가 모델 예측에 오히려 방해가 되고 있음을 의미하기도 한다.그러나 대부분의 경우, 음수 값이 나오면 신뢰할 수 없는 값으로 간주하고, 추가적으로 다시 평가하거나 분석이 필요하다.
-
- 코드 예시
sklearn.inspection.permutation_importance를 사용하여 Permutation Importance 구하기# 필요한 라이브러리 불러오기 import numpy as np import pandas as pd from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from sklearn.inspection import permutation_importance # 데이터 불러오기 및 분리 boston = load_boston() X, y = boston.data, boston.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) # 모델 학습 (RandomForest 예시) model = RandomForestRegressor(random_state=42) model.fit(X_train, y_train) # Permutation Importance 계산 (Test 데이터 기준) perm_importance = permutation_importance( model, X_test, y_test, n_repeats=30, random_state=42 ) # Feature Importance 출력 importance_df = pd.DataFrame({ 'feature': boston.feature_names, 'importance_mean': perm_importance.importances_mean, 'importance_std': perm_importance.importances_std }).sort_values(by='importance_mean', ascending=False) print(importance_df)- Permutation Importance 함수의 주요 매개변수
model: 학습이 완료된 모델X_test, y_test: 중요도를 측정할 테스트 데이터n_repeats: 특성을 몇 번 섞어서 평균값을 낼지 결정 (클수록 안정적 결과)
- 결과로 출력되는
importance_mean값이 클수록 Feature의 중요도가 높다. - 표준편차(
importance_std)는 특성을 섞을 때마다 중요도의 변동성을 나타낸다.
- Permutation Importance 함수의 주요 매개변수
2. Surrogate Model (대리 모델)
- 목적 복잡한 모델(Black-box)을 간단한 모델(해석이 쉬운 모델)로 근사하여 설명하는 방법입니다. → 딥러닝의 예측력을 활용하면서, 가볍고 해석 가능한 다른 모델(대리 모델)의 설명력을 활용해보자.
- 원리 복잡한 모델의 입력과 출력을 기반으로, 해석하기 쉬운 간단한 모델(예: 선형 회귀, 결정 나무)을 만들어서 원래 모델을 설명한다.
- 장점
- 설명이 직관적이고 명확함
- 복잡한 모델의 내부 구조를 몰라도 사용 가능
- 단점
- 간단한 모델이 원본 모델을 완벽히 표현하지 못할 수 있음
- 설명이 실제 모델의 성능과 다를 수 있음
- 고려사항 ① 좋은 Surrogate Model의 조건
- 원본 블랙박스 모델(Original Model)의 예측력과 유사해야 한다.
- 동시에 해석 가능성을 제공해야 한다.
- 가볍고 바른 모델이어야 한다. (연산 비용이 낮을 것)
- Surrogate Model 성능 측정 방법 대리 모델(Surrogate Model)의 성능이 Original Model의 예측 성능과 얼마나 근사한지는 어떻게 측정할까? 성능 측정 방법: R2R^2R2 (결정계수, Coefficient of Determination)Surrogate Model이 얼마나 Original Model의 성능과 근사한지 측정할 때, 대표적으로 사용하는 지표는 결정계수(R2R^2R2)입니다. 결정계수(R2R^2R2) 공식은 아래와 같습니다. R2=1−RSSTSS=1−∑i=1n(y^surr(i)−y^orig(i))2∑i=1n(y^orig(i)−y^ˉorig)2R^2 = 1 - \frac{RSS}{TSS}
= 1 - \frac{\sum{i=1}^{n}( \hat{y}^{(i)}{surr} - \hat{y}^{(i)}{orig} )^2}{\sum{i=1}^{n}( \hat{y}^{(i)}{orig} - \bar{\hat{y}}{orig} )^2} R2=1−TSSRSS=1−∑i=1n(y^orig(i)−y^ˉorig)2∑i=1n(y^surr(i)−y^orig(i))2 여기서 각 항목은 다음과 같습니다.-
y^surr(i)\hat{y}^{(i)}_{surr}y^surr(i) : Surrogate Model이 예측한 값
-
y^orig(i)\hat{y}^{(i)}_{orig}y^orig(i) : Original Model이 예측한 값
-
y^ˉorig\bar{\hat{y}}_{orig}y^ˉorig : Original Model 예측값의 평균값
🔍 R2R^2R2 해석 방법
R2R^2R2 값 의미 R2R^2R2 ≈ 1 Surrogate Model의 예측 성능이 Original Model과 매우 유사 (우수한 근사) R2R^2R2 ≈ 0 Surrogate Model의 예측이 Original Model과 거의 무관 (낮은 근사) 즉, R2R^2R2 값이 높을수록(1에 가까울수록), Surrogate Model이 Original Model의 예측 성능을 효과적으로 근사한다고 평가할 수 있습니다.
📌 시각적 설명 (사진 참고)
-
Regression Line(빨간색) : Surrogate Model이 Original Model의 예측값을 얼마나 잘 따라가는지 나타냅니다.
-
Residual(잔차) : Original Model과 Surrogate Model 예측값의 차이
-
RSS (Residual Sum of Squares) : 잔차를 제곱하여 합한 값 (예측 간 차이)
-
TSS (Total Sum of Squares) : Original Model의 예측값과 Original Model의 평균 예측값 간의 차이를 제곱하여 합한 값 (기준점 대비 차이)
📌 정리 및 핵심 요약
-
Surrogate Model의 성능을 평가할 때는 결정계수(R2R^2R2)를 사용합니다.
-
결정계수(R2R^2R2) 값이 1에 가까울수록 좋은 Surrogate Model입니다.
R2R^2R2 값 범위 Surrogate 성능 근사도 0.8 ~ 1.0 매우 우수 0.5 ~ 0.8 보통~우수 0 ~ 0.5 낮음 (적합하지 않음) 이렇게 결정계수를 사용하면 Surrogate Model이 Original Model과 얼마나 비슷한 성능을 나타내는지 쉽게 평가할 수 있습니다.
Q1 ) 만약 R2값이 0.94라면?? : 굳이 예측 모델을 따로 쓸 필요 있나?!! Surrogation model을 예측 모델로도 사용하면 된다
Q2 ) 만약 R2값이 0.1정도라면?? 사용 못한다! 예측모델과 성능이 거의 유사하지 않아서 믿을 수 있는 해석이 아니다.
-
3. LIME (Local Interpretable Model-agnostic Explanation)
- 목적 특정 데이터 하나의 예측 결과를 국소적으로 설명하는 방법입니다.
- 원리 설명하고자 하는 데이터 주변에 유사 데이터를 생성하고, 간단한 모델(예: 선형 회귀)을 이용해 국소적으로만 근사하여 중요한 특성을 찾아냅니다.
- 장점
- 특정 예측 결과를 쉽게 이해할 수 있음
- 모든 모델에 적용 가능(Model-agnostic)
- 단점
- 주변 데이터의 범위를 임의로 설정해야 하므로, 설정에 따라 설명이 달라질 수 있음
- 국소적 설명이라 전역적 설명이 어려움
4. SHAP (SHapley Additive exPlanations)
- 목적 예측 결과에 각 특성이 얼마나 기여했는지를 정량적으로 측정하여 설명하는 방법입니다.
- 원리 게임 이론에서의 Shapley value라는 개념을 이용하여, 각 특성이 결과에 기여한 정도를 공정하고 수학적으로 엄밀하게 계산합니다.
- 장점
- 수학적으로 명확하고 이론적 근거가 강력함
- 개별 데이터(국소적)와 전체 데이터(전역적) 모두 설명 가능
- 단점
- 계산량이 많아 큰 데이터에서는 시간이 오래 걸릴 수 있음
- 완벽한 Shapley value 계산이 어렵기 때문에 근사 방법을 주로 사용함
🔍 간단한 비교 요약
| 방법 | 특징 | 설명 범위 | 계산 비용 |
|---|---|---|---|
| Permutation Importance | 특성의 중요도 순위 | 전역적(Global) | 낮음 |
| Surrogate Model | 간단한 모델로 근사하여 설명 | 전역적(Global) | 낮음~중간 |
| LIME | 특정 데이터 한 개씩 국소적 설명 | 국소적(Local) | 중간 |
| SHAP | 특성별 정확한 기여도(수학적 근거 있음) | 전역적+국소적 | 높음 |
사진 출처 : https://juhans.tistory.com/2
