Primary Key
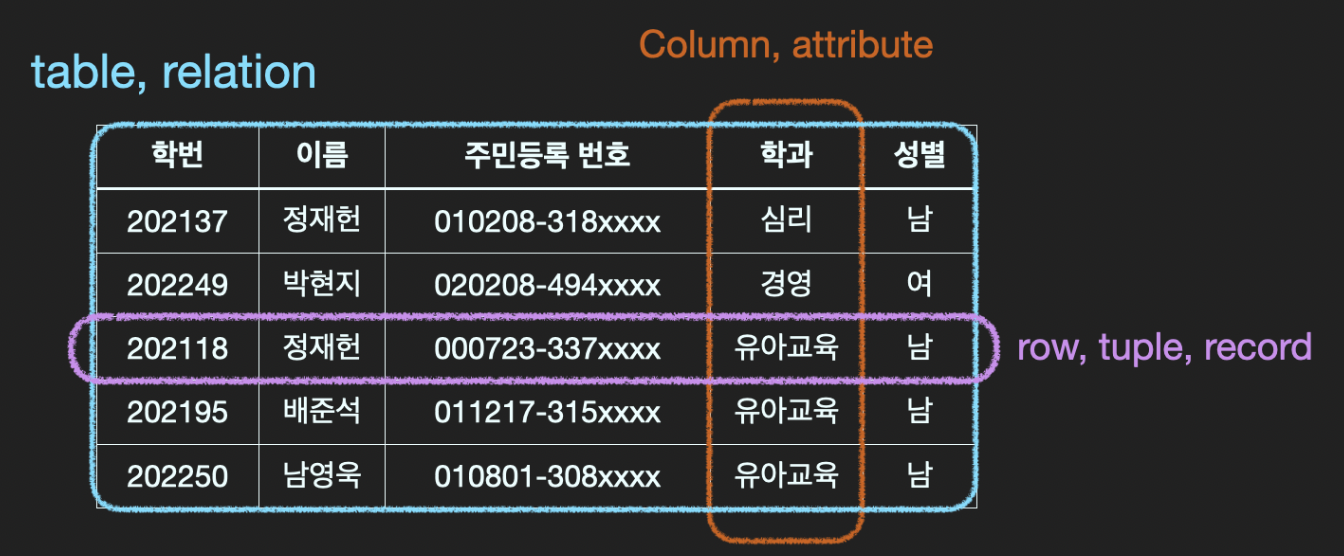
위와 같은 데이터베이스 테이블을 가정해보자.
Super Key
슈퍼키는 각 row를 유일하게 식별할 수 있는 하나 또는 그 이상의 속성들의 집합이다.
즉, "유일성"을 만족하면 슈퍼키가 될 수 있다.
유일성은 하나의 Key 값으로 특정 row만을 유일하게 찾아낼 수 있어야 한다는 특성이다.- (학번)
- (학번, 이름)
- (학번, 이름, 학과)
- (주민등록번호)
- (주민등록번호, 학과, 성별)
...
Candidate Key
후보키는 슈퍼키 중에서 더 이상 쪼개질 수 없는 슈퍼키를 말한다.
즉, 각 row를 유일하게 식별할 수 있는 최소한의 속성들의 집합이다.
따라서 후보키는 유일성과 최소성의 속성을 가진다.
- (학번)
- (주민등록번호)
Primary Key
기본키는 후보키 중에서 선택된 메인키이다.
각 row를 구분하는 유일한 열이며, Null값을 가질 수 없고 중복된 값 또한 가질 수 없다.
기본키는 테이블 당 한 개만 지정되어야 하며, 유일성과 최소성의 속성을 가진다.
Alternative Key
대체키는 후보키가 두 개 이상일 경우, 기본키로 지정되지 않은 남은 후보키들을 의미한다.
Foreign Key
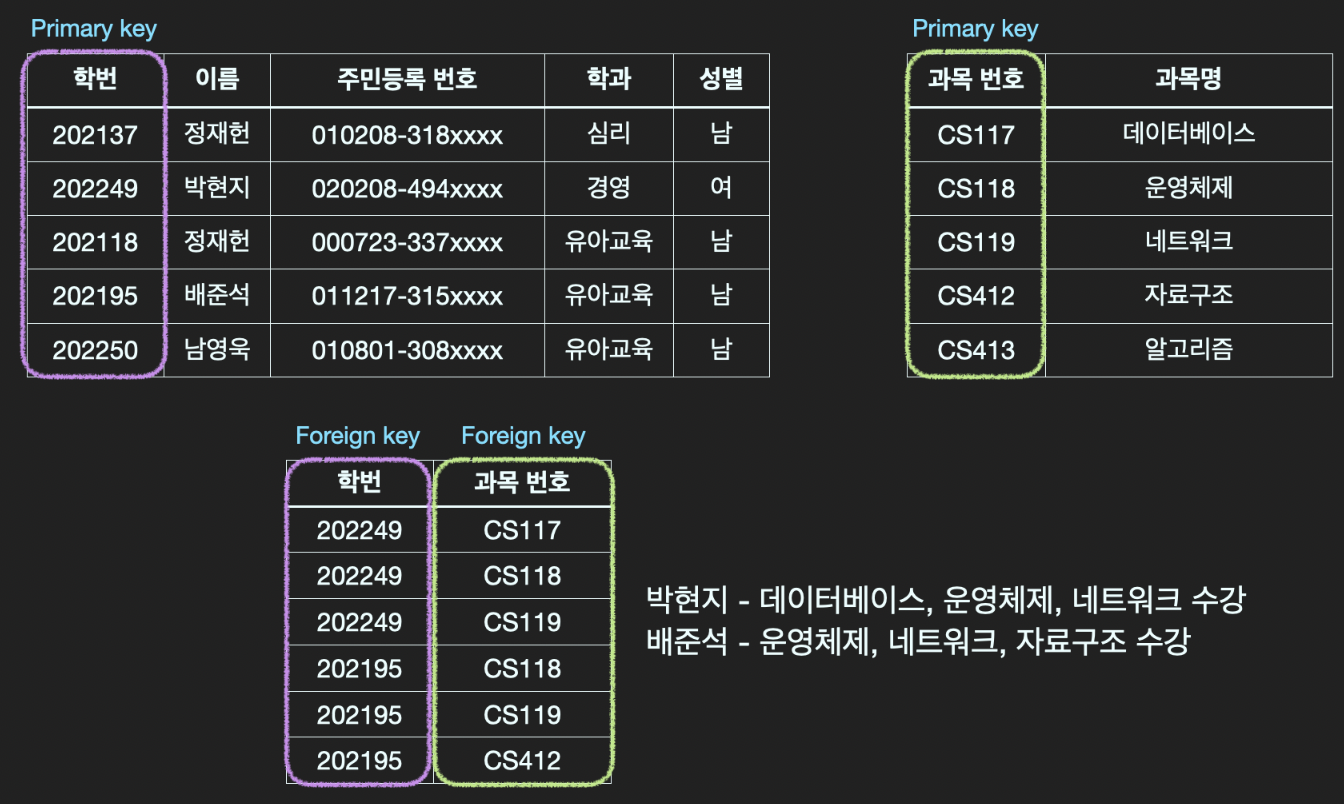
외래키는 다른 테이블의 Primary key column과 연결되는(참조되는) 테이블의 컬럼을 의미한다.
Composite Key
복합키는 테이블에서 각 row를 식별할 수 있는 두 개 이상의 column으로 구성된 후보키를 의미한다.
즉, 복합키는 유일성과 최소성을 만족하면서, 위의 예시처럼 학번, 주민등록번호와 같이 하나로만 구성되지 않은 경우를 뜻한다.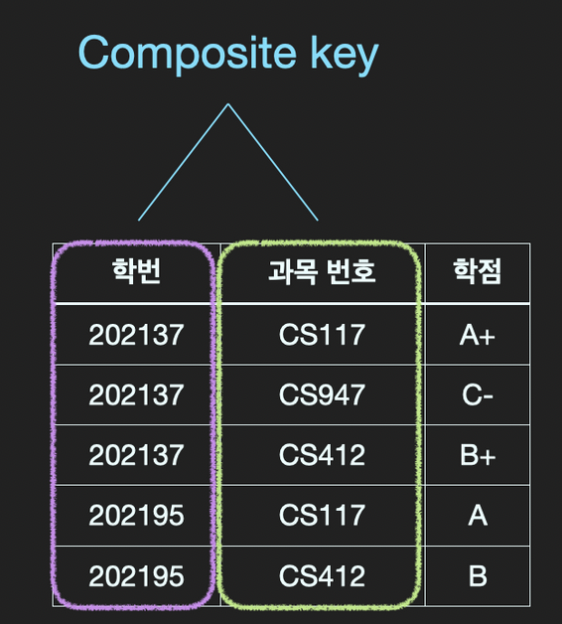
위의 예시의 경우 학번이나 과목번호만으로는 row를 식별해낼 수 없고, 두 개를 묶어 사용해야만 row를 식별할 수 없다.
(학번, 과목 번호)는 더 이상 쪼개질 수 없으므로 후보키의 조건을 만족하는 복합키이다.
N:M
엔티티 관계는 크게 다음 3가지 경우가 있다.
- 1:1
- 1:N
- N:M
가장 자주 등장하는 1:N의 예시는 다음과 같다.
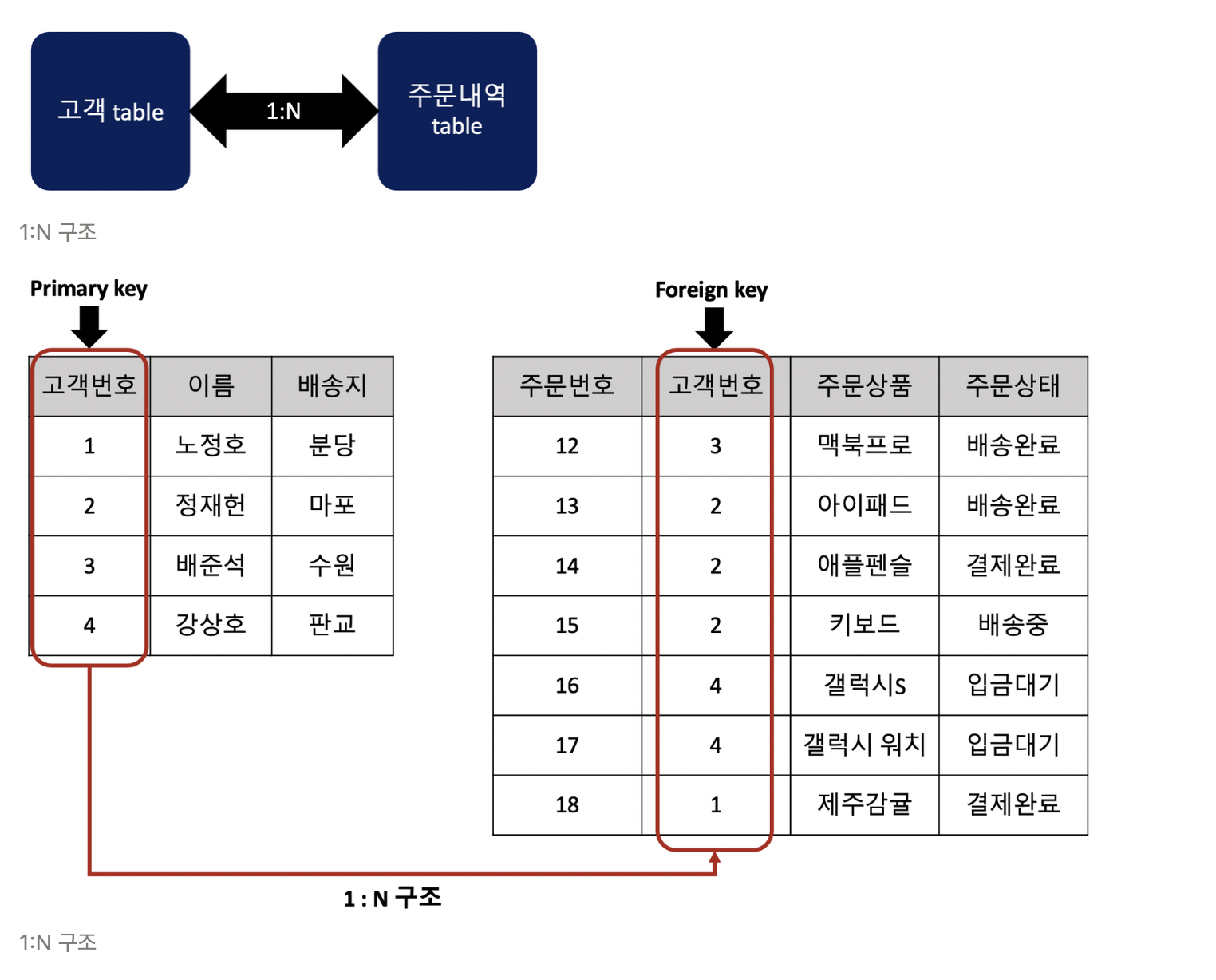
주문내역 테이블에서, 고객 테이블의 Primary key와 연결된 고객 번호 컬럼이 주문내역 테이블의 Foreign key이다.
테이블의 외래키가 다른 테이블의 기본키가 되는 것이다.
하나의 테이블의 정보를 바꾸더라도 다른 테이블의 정보까지 바꿀 필요가 없다는 장점이 있다.
다음으로는 N:M 관계이다.
양쪽 엔티티 모두가 서로에게 1:N 관계를 갖는 구조이다.
이럴 땐, 중간에 mapping table을 하나 더 만들어, 각각 mapping table에 대해 1:N의 관계를 갖도록 설계한다.
JOIN
Outer join과 inner join
Outer join에는 left outer join과 right outer join이 있다.
left와 right가 의미하는 것은 연관 테이블 중 기준이 왼쪽이냐 오른쪽이냐를 의미한다.
아래 사진에서는 왼쪽 테이블을 기준으로 outer join을 진행하기 때문에 이를 left outer join이라 한다.
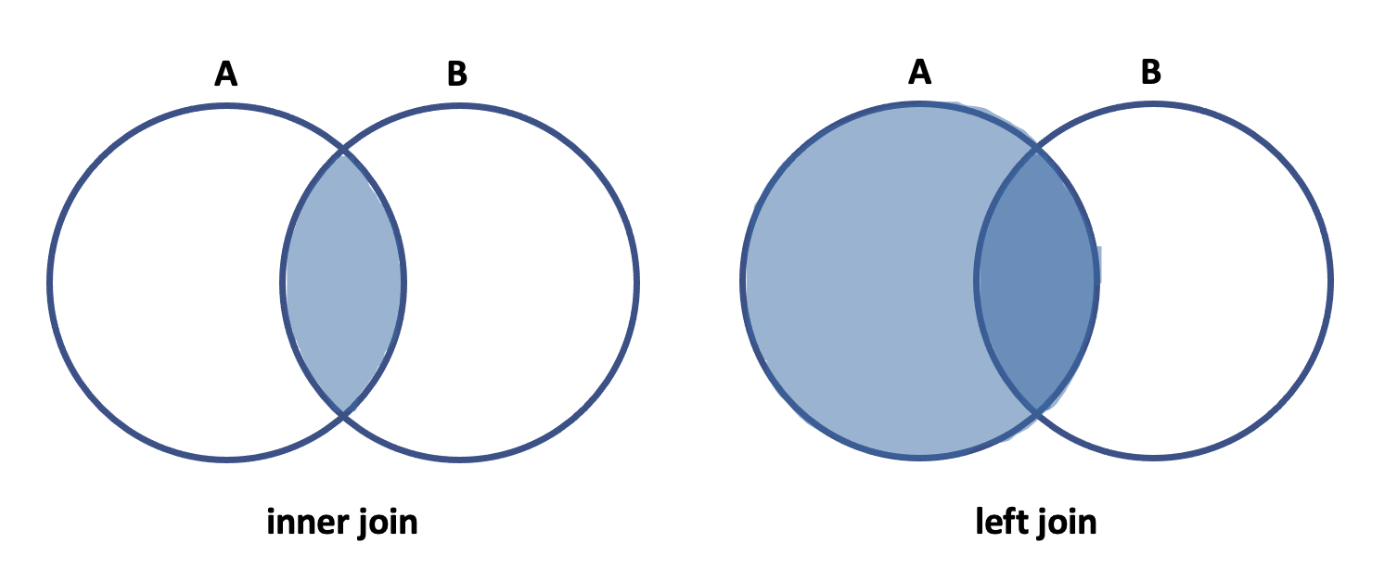
inner join
inner join은 가장 많이 사용되는 방식으로, inner를 생략해서 사용하기도 한다.
이는 두 테이블에 공통된 데이터가 존재하는 행에 대해서만 데이터를 검색한다.
select * from video inner join youtuber on video.y_id = youtuber.id;
select * from video, youtuber where video.y_id = youtuber.id;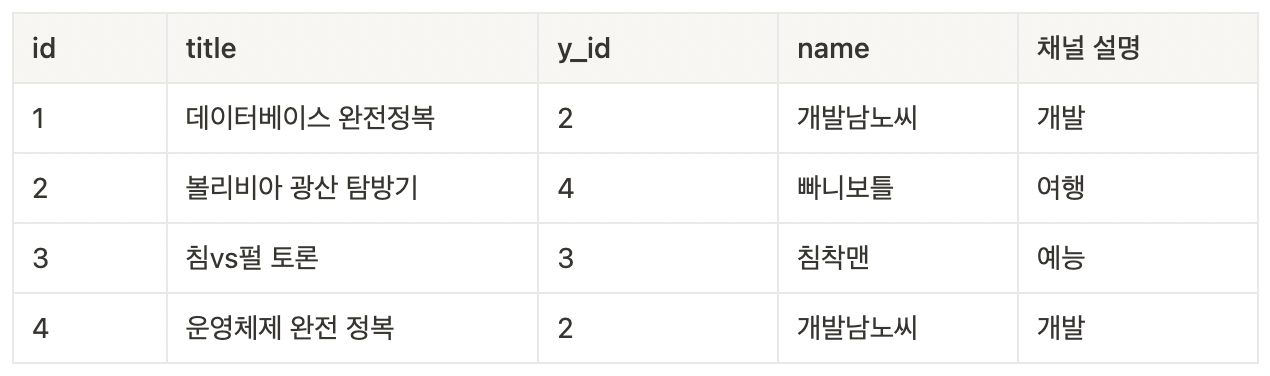
left outer join
outer join은 공통된 데이터가 아니더라도, 모든 데이터를 포함하여 데이터를 검색한다.
select * from video left join youtuber on video.y_id = youtuber.id;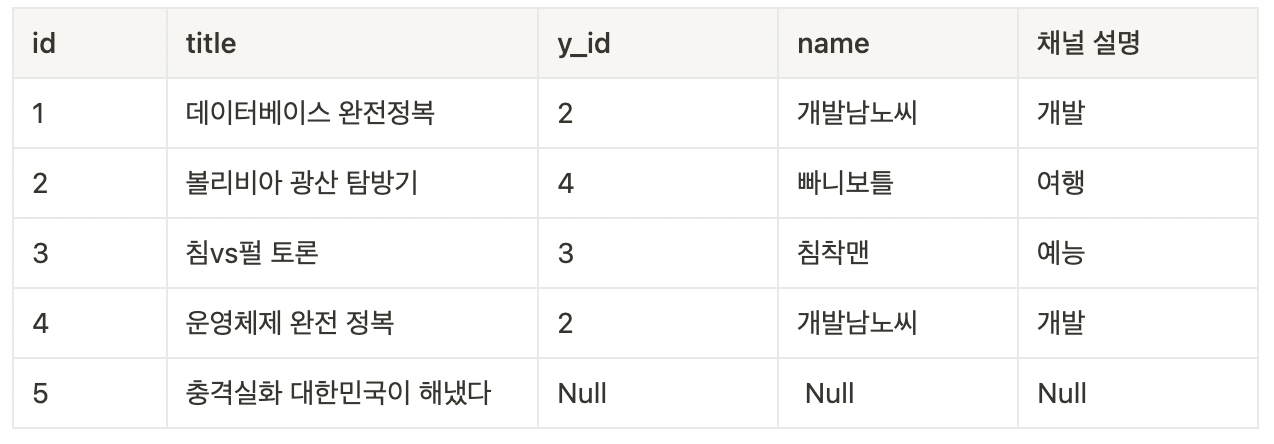
Transaction
트랜잭션에 대해선 비교적 최근에 포스팅한 바 있으나, 조금 더 정제된 말로 표현하기 위해... 간단히 하겠다.ㅎ
트랜잭션은 데이터베이스 내에서 수행되는 작업의 최소 단위이다.
이는 데이터베이스의 무결성을 유지하며 DB의 상태를 변화시키는 기능을 수행한다.
(데이터베이스 무결성이란, 저장된 데이터의 일관성과 정확성을 지키는 것을 의미한다.)
예를 들어, A가 B에게 100만원을 송금해야 한다면, A에서 100만원이 출금되는 update문과, B에게 100만원이 입금되는 update문 두 개가 단일 업무로써 함께 수행되어야 한다는 것이다..
트랜잭션이 필요한 이유는, 데이터를 다룰 때 장애가 일어나는 경우 트랜잭션은 장애 발생 시 데이터를 복구하는 작업의 단위가 되기 때문이다.
또한 데이터베이스에서 여러 작업이 동시에 같은 데이터를 다룰 때가 자주 발생하는데, 트랜잭션을 통해 이 작업을 서로 분리하고 이를 통해 오류가 발생하지 않게 한다.
(운영체제에서 배운 멀티 스레드, 멀티 프로세스의 동기화 문제와 비슷한 것 같다.)
start transaction
update customer set balance = balance - 100 where name = 'A';
update customer set balance = balance + 100 where name = 'B';
commitACID
트랜잭션은 앞서 언급한 데이터베이스의 무결성을 유지하기 위해 원자성, 일관성, 고립성, 지속성의 성질을 갖는데 이를 ACID 라고 한다.
- Actomicity (원자성): 트랜잭션의 포함된 작업은 전부 수행되거나 전부 수행되지 말아야 한다. all or nothing
- Consistency (일관성): 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 트랜잭션 전후의 잔액 data type이 integer를 유지해야함을 예로 들 수 있다.
- Isolation (고립성): 여러 트랜잭션은 동시에 수행된다. 각 트랜잭션은 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하여 독립적으로 작업을 수행한다. 따라서 동시에 수행되는 트랜잭션이 동일한 데이터를 가지고 충돌하지 않도록 제어할 수 있다. (동시성 제어 concurrency control)
- Durability (지속성): 성공적으로 수행된 트랜잭션은 데이터베이스에 영원히 반영되어야한다. 정전, 장애, 오류 등에 영향을 받지 않음을 의미한다.
동시성 제어 concurrency control
여러 개의 트랜잭션이 한 개의 데이터를 동시에 update할 때 어느 한 트랜잭션의 update가 무효화 될 수 있는데 이를 갱신손실이라한다.
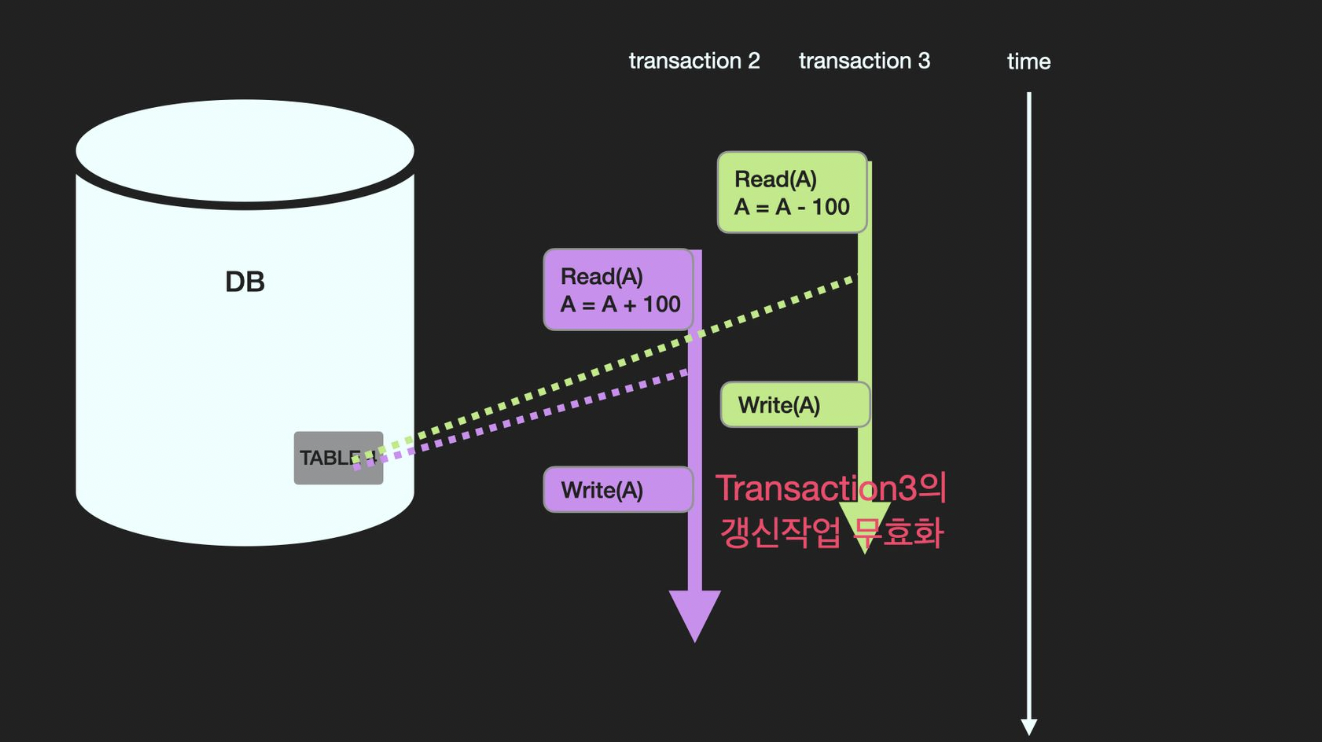
위의 예시를 살펴보자.
값이 1,000인 A가 있다고 가정해보자.
100을 더하려는 트랜잭션2와 100을 빼려는 트랜잭션3이 진행된 이후에 A값은 여전히 1,000이어야 한다.
먼저, 트랜잭션3이 A에 접근해서 100을 빼서 900을 만드려고 한다.
따라서 Read(A)를 통해 A의 값을 읽어왔다.
그리고 100이 빠진 A를 저장하기 위해 Write(A) 연산을 할 것이다.
그런데 이 사이에 트랜잭션2가 끼어들어 A에 100을 추가하는 연산을 진행하려 한다.
그래서 Read(A)를 통해 A의 값을 읽어왔다.
그리고 트랜잭션2가 Write(A) 연산을 진행하려 할 때, 트랜잭션 3이 먼저 Write(A) 연산을 수행하는 것이다.
그렇다면 현재 A의 값은 900으로 저장이 되어 있을 것이다.
이 후, 트랜잭션2의 연산이 마저 수행되면 Write(A)를 통해 100이 더해진 1,100이 덮어 씌어질 것이다.
최종적으로 A는 1,100의 값을 갖게 되고 트랜잭션3의 연산은 무효화된다.동시성 제어는 이러한 갱신손실을 미리 막을 수 있게 한다.
즉, 트랜잭션이 동시에 수행될 때 일관성을 해치지 않도록 트랜잭션의 데이터접근을 제어하는 DBMS의 기능이 바로 동시성제어이다.
동시성제어의 대표적인 방법 중 하나는 Lock을 사용하는 것이다.
먼저 수행된 트랜잭션은 데이터에 Lock을 걸어, 다른 트랜잭션의 접근을 막는다.
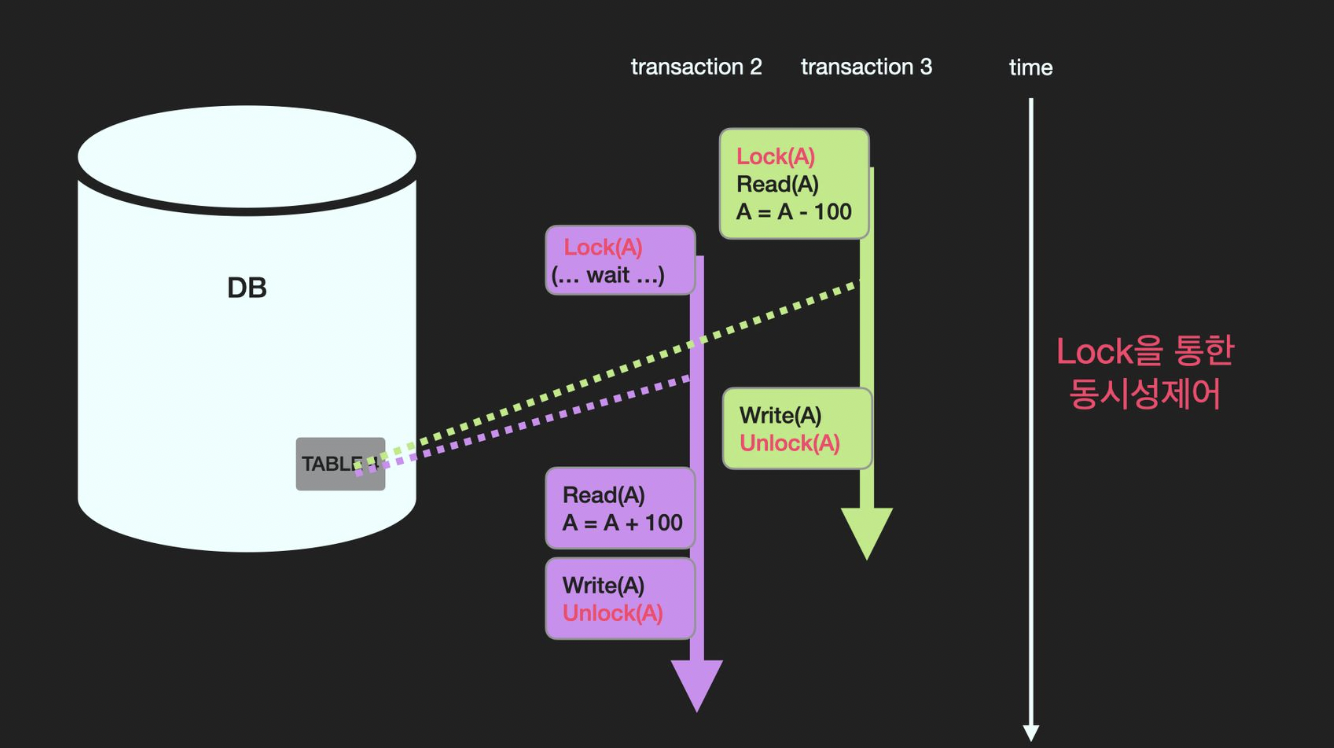
위의 예시를 살펴보자면, 먼저 수행되는 트랜잭션3이 A의 데이터에 Lock을 걸어두었다.
이후에 A에 접근하려는 트랜잭션2는 A에 Lock이 걸려있기 때문에 계속 waiting을 하다가,
트랜잭션3이 A에 대해 Unlock 연산을 수행하면 그제야 비로소 A에 접근할 수 있게 된다.DeadLock
데이터베이스 DeadLock(교착 상태)이란, 여러 트랜잭션이 각각 자신의 데이터에 대하여 Lock을 획득한 상태에서 Unlock이 수행되지 않은 채, 상대방 데이터에 대하여 접근하고자 대기를 할 때, 교차 대기를 하게 되어 서로 영원히 기다리는 상태를 말한다.
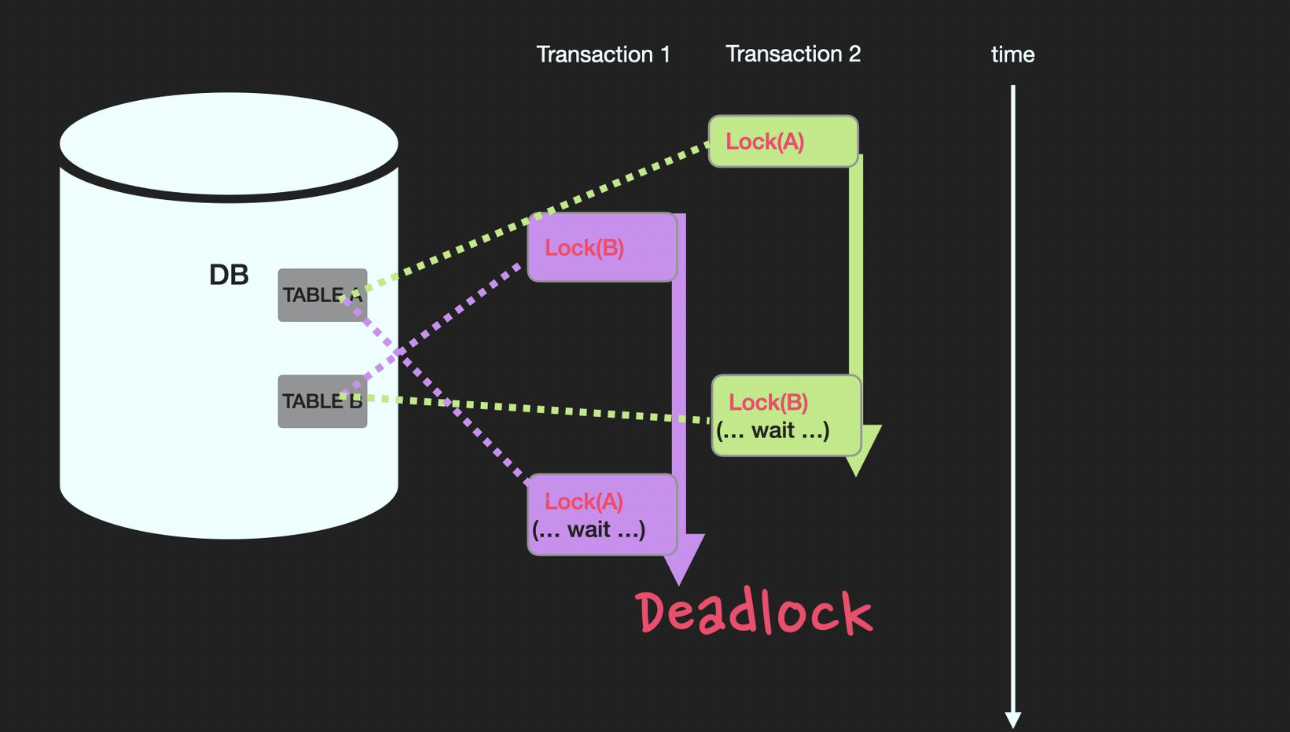
트랜잭션2는 B에 대한 접근을 기다리느라, 트랜잭션3은 A에 대한 접근을 기다리느라
무한정 waiting 해야하는 상황에 놓였다.이를 해결하기 위한 방법은 다음과 같다.
- 예방기법: 각 트랜잭션이 실행되기 전에 필요한 데이터를 모두 Locking 하는 것이다. 하지만 Locking 해야하는 데이터가 많다면 사실상 모든 데이터를 전부 Locking 한 것과 동일하여 트랜잭션의 병행성을 보장하지 못할 수 있다는 단점이 있다.
- 회피기법: 자원을 할당할 때, Timestamp를 이용하여 데드락이 일어나지 않도록 회피하는 기법이다.
- 탐지/회복 기법: 트랜잭션이 실행되기 전에는 아무런 검사를 하지 않고, 데드락이 발생하면 이를 감지하고 회복시키는 방법이다.
Commit & Rollback
커밋과 롤백 명령어를 통해 데이터의 무결성을 보장할 수 있다.
커밋은 트랜잭션의 작업을 완료했다고 확정하는 명령어로, 트랜잭션 작업 내용을 실제 DB에 저장하고 DB를 변경한다.
롤백은 작업 중 문제가 발생했을 때, 트랜잭션 처리과정에서 발생한 변경 사항을 취소하고 이전 커밋의 상태로 되돌린다.
Index
인덱스는 데이터베이스에서 테이블의 검색 성능을 높여주는 대표적인 방법 중 하나이다.
우리가 책에서 원하는 파트를 찾고 싶을 때 목차를 사용하는 것과 비슷한 원리이다.
일반적인 RDBMS에서는 B+Tree 구조로 된 인덱스를 사용하여 검색 속도를 향상시킨다. (이외에도 Btree, Hash, Bitmap 등이 있다.)
인덱스 기능을 사용하면 Full Table Scan을 하지 않아도 Index Scan을 통해 조회를 할 수 있기 때문이다.
구조
인덱스를 생성하게 되면 특정 column의 값을 기준으로 정렬하여 데이터의 물리적 위치와 함께 별도 파일에 저장한다.
이때, 인덱스에 저장되는 속성의 값을 search-key값이라고 하고 실제 데이터의 물리적 위치를 저장한 값을 Pointer라고 한다.
즉, 인덱스는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 테이블보다 적은 공간을 차지한다. (주로 10%)
사용하는 이유
우리가 인덱스를 사용하는 이유는, 테이블에 데이터를 지속적으로 저장하게 되면 내부적으로 순서 없이 쌓이기 때문에 검색 성능이 저하되기 때문이다. (Full table scan)
반면, 특정 column에 대한 인덱스를 생성해놓은 경우 해당 속성에 대하여 search-key가 정렬된 상태로 저장되어 있개 때문에 조건 검색 속도가 향상된다.
Clustering Index & Secondary Index
인덱스의 종류에는 클러스터형 인덱스와 보조 인덱스, 2가지가 있다.
- Clustering Index: 특정 column을 기본키로 지정하면 자동으로 클러스터형 인덱스가 생성되고, 해당 column 기준으로 정렬이 된다.
테이블 자체가 정렬된 하나의 인덱스인 것이다. (ex. 영어사전 책처럼)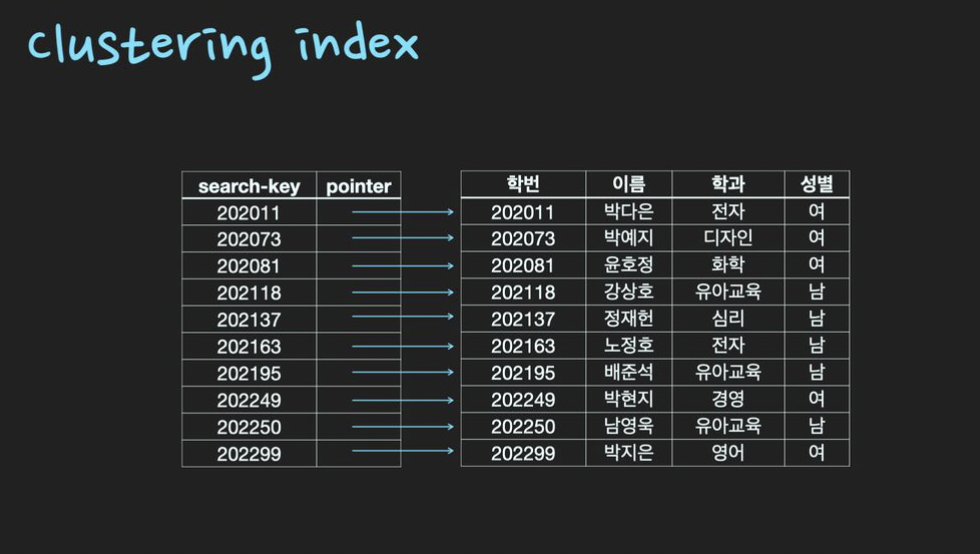
- Secondary Index: 일반 책의 찾아보기와 같이 별도의 공간에 인덱스가 생성이 된다.
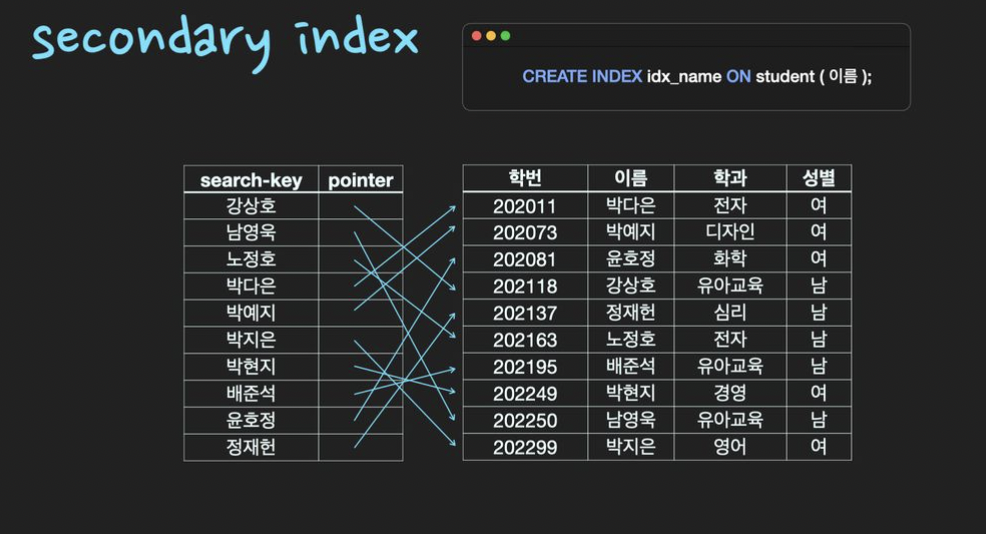
인덱스를 활용한 조회는 다음과 같다.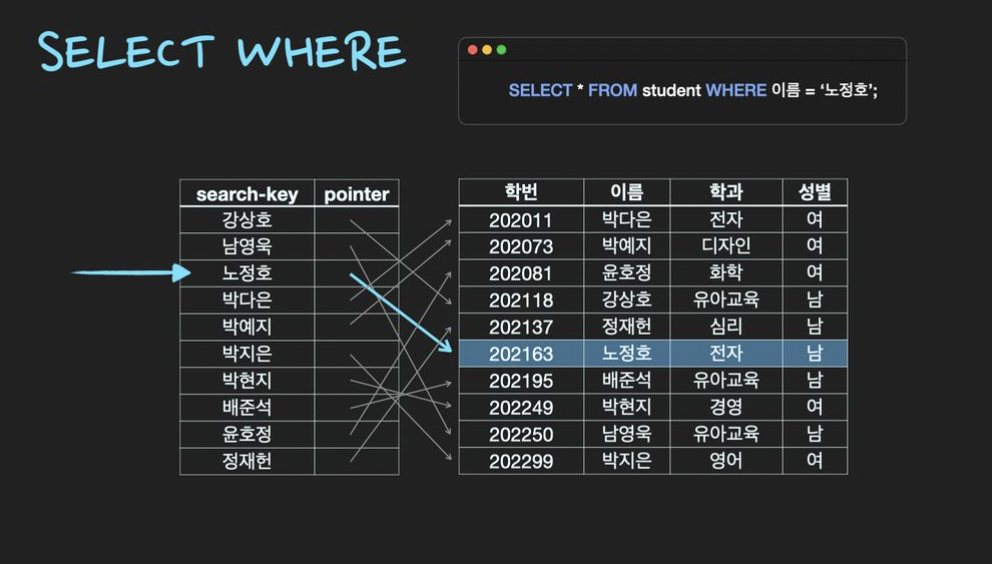
장단점
인덱스의 최대 장점은 검색 속도 향상 이다.
순서없이 뒤죽박죽 저장된 테이블에 검색 기준을 세워주는 것과 마찬가지이기 때문이다.
반면 단점으로는 아래의 두가지가 있다.
- 추가 저장공간 필요
보통 테이블 크기의 10% - 느린 데이터 변경 작업
검색이 아닌 Insert, Update, Delete 연산을 할 때가 문제이다.
인덱스는 보통 B+Tree로 구현되는데, 위의 연산 수행마다 트리의 구조가 변경될 수 있기 때문이다.
따라서 인덱스의 재구성이 필요하므로 추가적인 자원이 소모된다.
이러한 단점을 이유로 어느 column에 인덱싱을 할지가 키포인트이다.
어느 column에 인덱스를 저장할까?
인덱스는 where절에서 자주 조회되고, 수정 빈도가 낮으며, 데이터 중복이 적은 column일수록 적합하다.
또한 데이터의 양이 많을수록 인덱스로 인한 성능 향상이 크다.
데이터의 양이 너무 적다면 인덱스의 혜택보단 손해가 더 클 수도 있다.
Join 조건으로 자주 사용되는 column의 경우에도 인덱스가 효과적일 수 있다.
B+Tree
Hash Table의 데이터 탐색 시간복잡도는 O(1)이다.
hash 값만 계산하면 데이터를 찾을 수 있기 때문이다.
반면 B+Tree의 데이터 탐색 시간복잡도는 O(logN)으로 비교적 느리다.
그래도 B+Tree가 자주 사용되는 이유는 부등호 연산 때문이다.
Hash table의 경우 데이터가 정렬되어 있지 않기 때문에 부등호 연산에 매우 비효율적이다.
B+Tree의 B는 Balanced로 알고 있지만, 동작은 마치 Binary Tree와 같다.
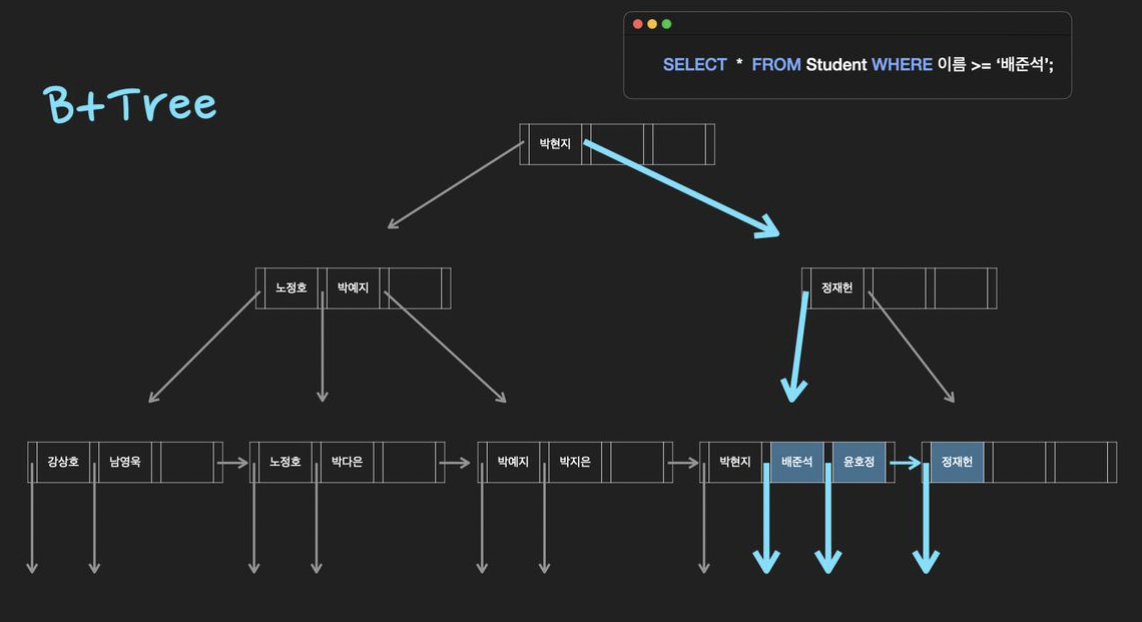
Hash Index는 오직 등호(=)연산에만 특화되어 있어 잘 사용하지 않는다.
