모델을 돌리려면 끊임없이 피처를 만들어내야 하는데 이 피처들이 일단은 피처스토어에 저장되있다고해도 아무래도 네트워크를 계속 거치면 비용이 있으니 이 피처들을 더 빠르게 가져올 궁리를 하게 되어있다. 이 포스팅에서는 자기들 시스템이 변화해온 것을 3단계로 정리하고 있다.
1) 모델이 도는 서버에 in-memory 캐시 놓기
2) 모델이 도는 서버에 in-memory + SSD cache 놓기
- GPU에서 모델을 돌리면서 batch request가 필요해져서 기존처럼 피처를 샤딩해서 저장하기가 힘들어졌다 -> 피처를 샤딩하지 말고 다 저장하자
- 요새 NVMe SSD가 워낙 빠르니까 2nd tier 캐시로 쓰면 가성비가 좋다
3) 모델이 도는 서버랑, 피처 서버 분리
- 점점 GPU가 보틀넥이 되면서 피처를 네트워크를 거쳐서 가져와도 별 손해가 없게 되었다 - 오히려 GPU서버에 램을 적게 써도 되서 이득
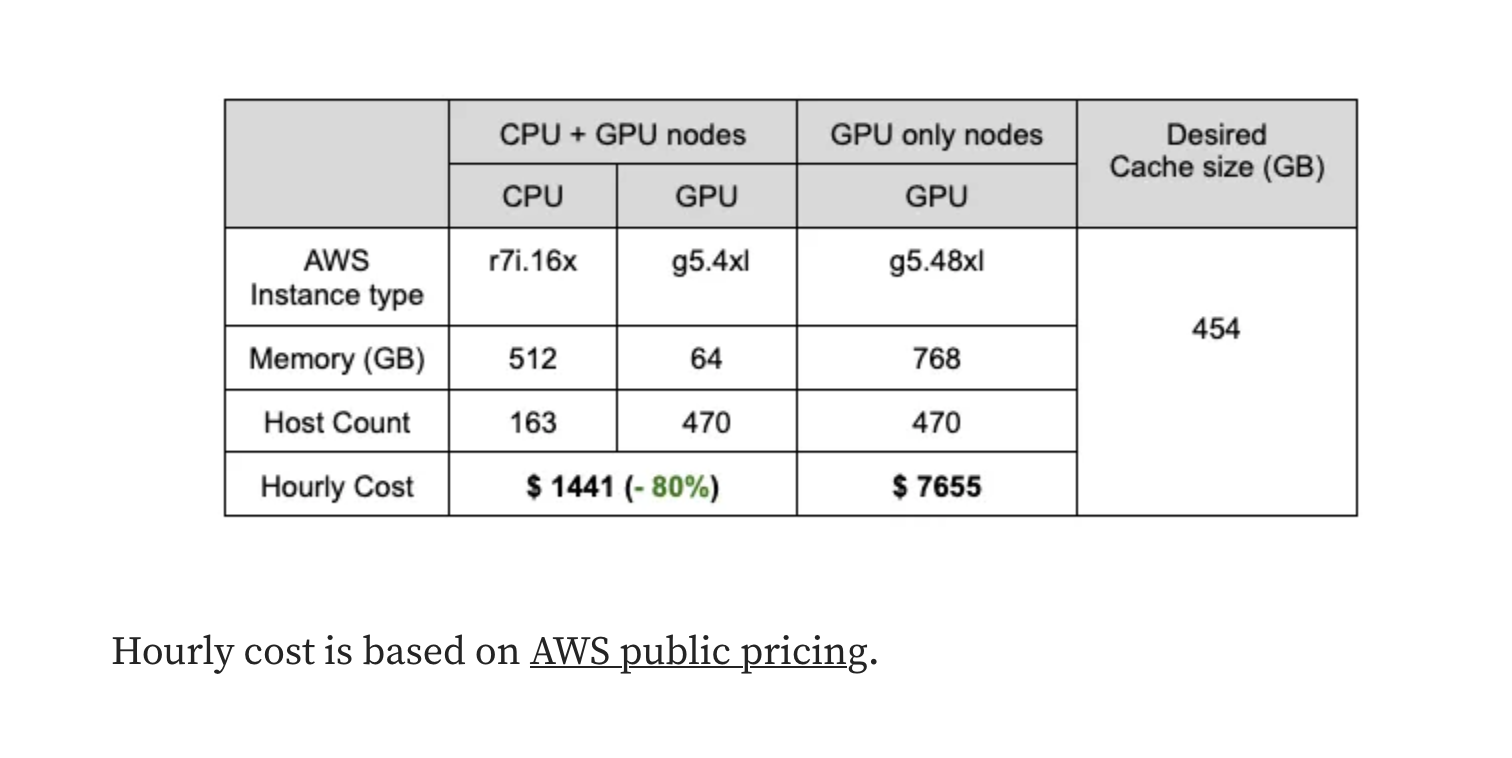
회사에서 현재 쓰는 방식을 보고서 피처 캐시가 모델이랑 같이 있는게 좋을까, 따로 있는게 좋을까 고민만 했었는데 (당연하게도) 상황마다 답이 다른 것이었다.

노션 대용 velog