이 글은 절판도서 "웹 개발자를 위한 대규모 서비스를 지탱하는 기술" 을 개인적인 용도로 정리한 글입니다. 모든 내용을 정리한 것이 아니라 필요한 부분만 정리했다는 점 양해 부탁드립니다
문제/오류가 있을 시 댓글로 알려주면 감사하겠습니다
+ 진짜 마지막이다 정말 감격의 순간| 현대 웹서비스 구축에 필요한 실전 기술
성장하는 서비스에 대응하기 위해서
- 대규모 서비스, 대규모 데이터 처리와 관계 깊은 기술로 작업큐 시스템, 스토리지 선택(RDBMS key-value 스토어), 캐시 시스템, 계산 클러스터 기술을 소개
작업큐(Job-Queue) 시스템
TheSchwartz, Gearman
| 웹 서비스와 요청
- 웹서비스는 기본적으로 동기적으로 시작된다(요청에 기인하는 모든 처리가 끝난 후 응답 반환)
- 데이터가 축적되면서 성능이 악화되게 된다
- 작업큐 시스템을 사용하면서 나중으로 미뤄도 되는 처리를 비동기로 실행할 수 있고 사용자 경험도 개선할 수 있다(동기로 하면 수초~수십초 대기 발생)
| 작업큐 시스템 입문
- 가장 간단한 방법은 비동기화 하고자 하는 처리를 독립된 스크립트로 해서 해당 스크립트를 어플리케이션 내부에서 호출하는 방법
- 하지만 스크립트 시작과 초기화의 오버헤드가 크다
- 또한 일시적으로 대량의 비동기 처리를 실행하면 그 수만큼 프로세스를 실행시키게 되기 때문에 단점이다
-> 비동기를 안전하게 처리하기 위해서는 작업큐와 워커를 세트로 한 작업큐 시스템을 사용하게 된다
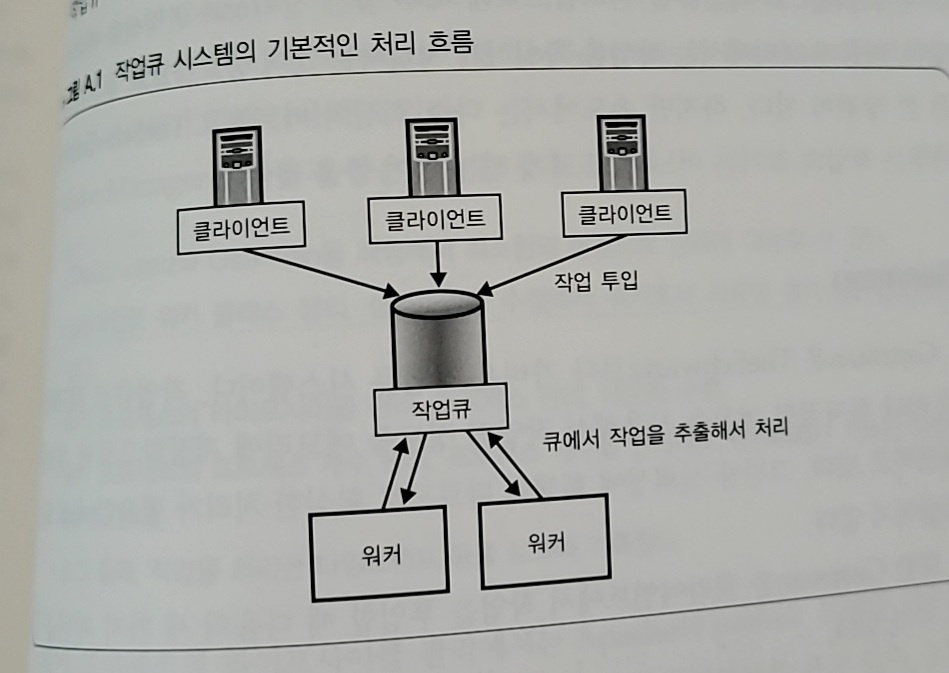
- 작업큐를 통해 작업을 등록하고, 워커카 큐에서 작업을 추출해서 실제로 처리한다
- 작업큐를 통해 일시적으로 대량의 처리가 등록되었을 때 부하의 변동을 흡수할 수가 있다
- 워커는 항상 실행해 작업을 처리할 때 초기화 오버헤드를 없앨 수 있다
| 하테나의 작업 큐
- 하테나는 TherSchwartz와 Gearman을 사용한다(Perl이므로 간단하게 기능만 설명)
TheSchwartz
- RDBMS를 사용하는 작업큐이며 매우 높은 신뢰성과 안정성을 확보한다
- 비동기는 확실하게 작업을 처리하는 것이 중요하기 때문에 신뢰성은 장점이지만 속도는 느리기 때문에 TheSchwartz에서 다루는 작업의 크기는 어느정도 크게 해야한다
Gearman
- TheSchwartz보다 가벼운 작업큐
- RDBMS가 아니라 독자적인 데몬을 작업큐로 사용해 작업의 정보를 메모리에 저장해 성능을 확보하다(신뢰성은 낮은 편)
- 작업을 처리할 때는 다음의 패턴을 따른다
- 동기적으로 순번대로 처리
- 동기적으로 병렬로 처리
- 비동기적으로 백그라운드로 처리 - 병렬처리로 상호 의존하지 않는 처리를 병행해서 처리함으로써 전체 처리시간을 크게 단축시킬 수 있다
WorkerManager에 의한 워커 관리
- 위 두 작업큐 시스템은 워커 프로세스를 세세하게 지원하는 기능은 제공하지 않아 자체 개발한 WorkerManager을 이용해 위 두 프로세스를 관리한다
- TheSchwartz와 Gearman을 래핑해서 최소한의 변경으로 양쪽에 대응
- 설정 파일로 워커 클래스 정의. 설정 파일만 수정해서 워커로서 사용할 클래스를 변경할 수 있따
- 워커 프로세스의 라이프사이클 관리. 프로세스 관리, 데몬화 수행
- 워커 프로세스의 프로세스 개수 관리. 프로세스 개수를 관리하고 병행처리가 가능한 작업수를 제어한다
-로그 출력. 작업을 처리한 타임스탬프 등을 로그에 기록한다 - 부모 프로세스에서 지정된 수의 자식 프로세스를 생성하게 하며 워커 프로세스 라이프사이클 관리(Apache prefork 모델 참고)
- 자식 프로세스별로 작업 수 지정
- 워커 프로세스의 메모리가 증가할 경우 일정한 횟수로 자식 프로세스를 재생성함으로써 메모리 낭비 억제
| 로그 분석
- 처리시간과 지연시간을 측정해 투입된 작업 종류의 양에 대해 워커의 처리 능력이 충분지 여부를 확인한다
- 지연시간이 길어졌을 때는 비동기 처리여도 사용자 경험상 문제가 되는 경우가 있으므로 워커의 튜닝과 보강을 생각한다
스토리지 선택
RDBMS와 Key-value 스토어
| 증가하는 데이터 저장
- 큰 데이터를 다루는 스토리지는 약간의 구성변경, 엑세스 패턴 변화로 응답속도 저하가 되는 경우가 많다
-> 데이터량, 스키마, 액세스 패턴에 맞는 스토리지 선택
| 웹 어플리케이션과 스토리지
- 스토리지 : 에플리케이션 데이터를 영속적/일시적으로 저장하기 위한 기술 (원본 데이터, 액세스 랭킹, 검색용 인덱스 데이터, 캐시 등)
- 원본 데이터는 신뢰성과 연관되어 가장 중요하기 때문에 많은 비용을 들여야한다(반면 캐시 같은 데이터는 성능을 높이고 비용을 낮춘다)
- 데이터 크기, 갱신 빈도, 성장 속도도 중요하다
| 적절한 스토리지 선택의 어려움
- 저장하고자 하는 데이터의 특성에 맞는 스토리지를 선택하는 것이 비용가 성능, 안정성의 균형을 높은 차원으로 달성하기 위한 열쇠가 된다
- 스토리지를 옮기는 것 보다는(시간도 많이 걸리고 까다로움) 특성에 맞는 스토리지를 선택해 하나의 스토리지를 오래도록 사용하는 것이 바람직하다
- 스토리지를 선택할 때는 액세스 패턴을 고려해야하며, 아래 지표가 중요한 포인트가 된다
평균 크기, 최대 크기, 신규추가빈도, 갱신빈도, 삭제빈도, 참조빈도 - 크기에 요구되는 신뢰성, 허용 가능 장애레벨, 사용할 수 있는 하드웨어, 예산도 중요하다(+ SSD 를 고려해본다거나 등등)
| 스토리지 종류
RDBMS : MySQL, PostgreSQL 등
분산 key-value 스토어 : memcached, TokyoTyrant 등
분산 파일 시스템 : MogileFS, GlusterFS, Lustre
그 밖의 스토리지 : NFS 꼐열 분산 파일시스템, DRBD, HDFSRDBMS
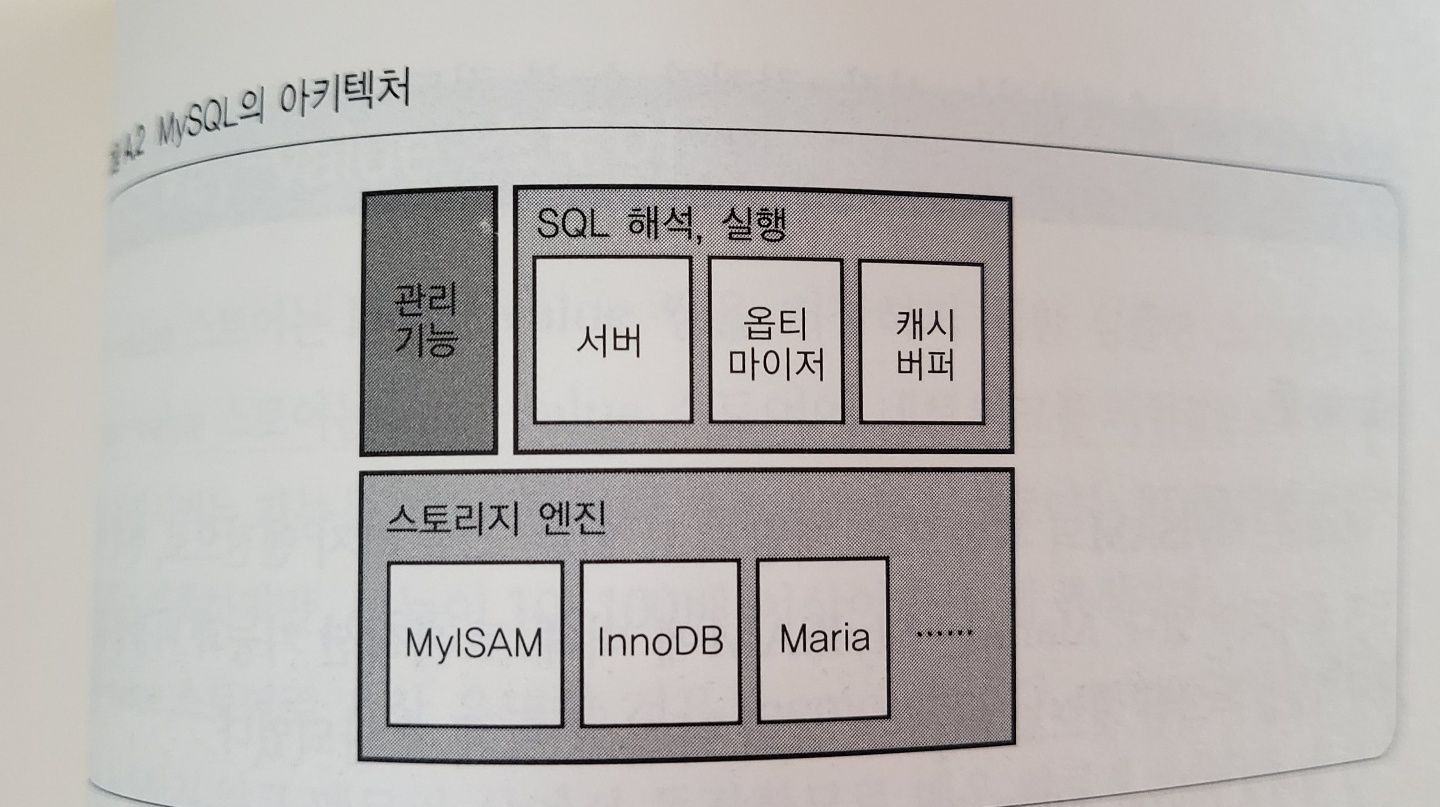
- MYSQL : SQL 실행 블록과 데이터 보관 기능 블록이 분리되어있다(후자는 스토리지 엔진)
- 스토리지 엔진에는 MyISAM, InnoDB, Maria가 있다
- 혼용해서 쓰지 않는다
1.MyISAM
- MyISAM은 1개의 테이블이 실제 파일 시스템 상에 3개의 파일(정의, 인덱스, 데이터)로 표현된다
- update, delete 한 적 없는 테이블에 대해 insert를 빠르게 할 수 있고 시작/정지 등도 빠르다
-하지만 테이블 파손 가능성이 높고 트랜잭션이 없고 테이블락으로 되어있어 갱신용으로는 어렵다
- InnoDB
- 스토리지 엔전 전체에서 사전에 정의한 소수의 파일에 데이터를 저장
- 트랜젝션 지원, 비정상 종료시 복구 기능 있음, 데이터 갱신이 로우락으로 되어있음
- 느림
분산 key - value 스토어
- key-value 쌍을 저장하며 RDBMS에 비해 기능적으로는 부족하지만 10 ~ 100배이상의 성능을 가짐
- 메모리상에서 동작하기 때문에 서버 재시작시 데이터가 모두 사라진다
- memcached, TokyoTyrant 등이 있다
- memchaced
- 클라이언트 라이브러리로 운영, 서버의 증감의 영향을 비교적 받지 않는다
- 원본 데이터 저장으로는 부적합, 재생성 시에 시간이 걸리는 가공 데이터 저장에도 부적합
- 캐시용 스토리지로 사용하는 것이 좋다
- 캐시로 한정할 경우 서버에는 메모리만 충분히 탑재해두면 되며, CPU나 I/O 성능은 그다지 요구되지 않는다
- 고가인 RDBMS 대수를 줄이는 구성 가능해짐
분산 파일시스템
- 파일시스템의 특성상 보통은 어느정도 이상인 크기의 데이터를 저장하는데 적합하다
- NFS와 같이 그것이 고려되고 있는 구현을 제외하고 작은 데이터가 대량으로 존재하는 용도에는 적합하지 않다
- 스토리지 서버 상에서 개개의 파일은 실제 파일시스템 상에서도 하나의 파일로 저장되며 통상 하나의 파일은 3중으로 다중화되어 일부 스토리지 서버가 고장나 데이터가 손실돼도 시스템 전체로는 계속 동작할 수 있게 한다
NFS 계열 분산 파일 시스템
- 특정 서버의 파일 시스템을 다른 서버에서 마운트해서 해당 서버의 로컬 파일시스템과 마찬가지로 조작할 수 있도록 하는 기술이다
- 커널 레벨에서 구현돼있는 경우가 많아 서버 측에 장애가 발생하면 클라이언트의 동작도 덩달아서 정지하는 경우 발생함
WebDAV 서버
- NFS와 같이 커널 계층에 구현돼있는 경우 불안정하므로 HTTP 기반인 WebDAV프로토콜을 지원하는 스토리지를 사용할 수 있다
DRBD
- 네트워크 계층의 RAID
- 블록 디바이스 레벨에서 분산, 다중화 할 수 있는 기술로 2대의 스토리지 서버의 블록 디바이스간 동기를 실현
HDFS
- Hadoop 용 분산 파일 시스템
캐시 시스템
Squid, Varnish
| 웹 애플리케이션 부하와 프록시/캐시 시스템
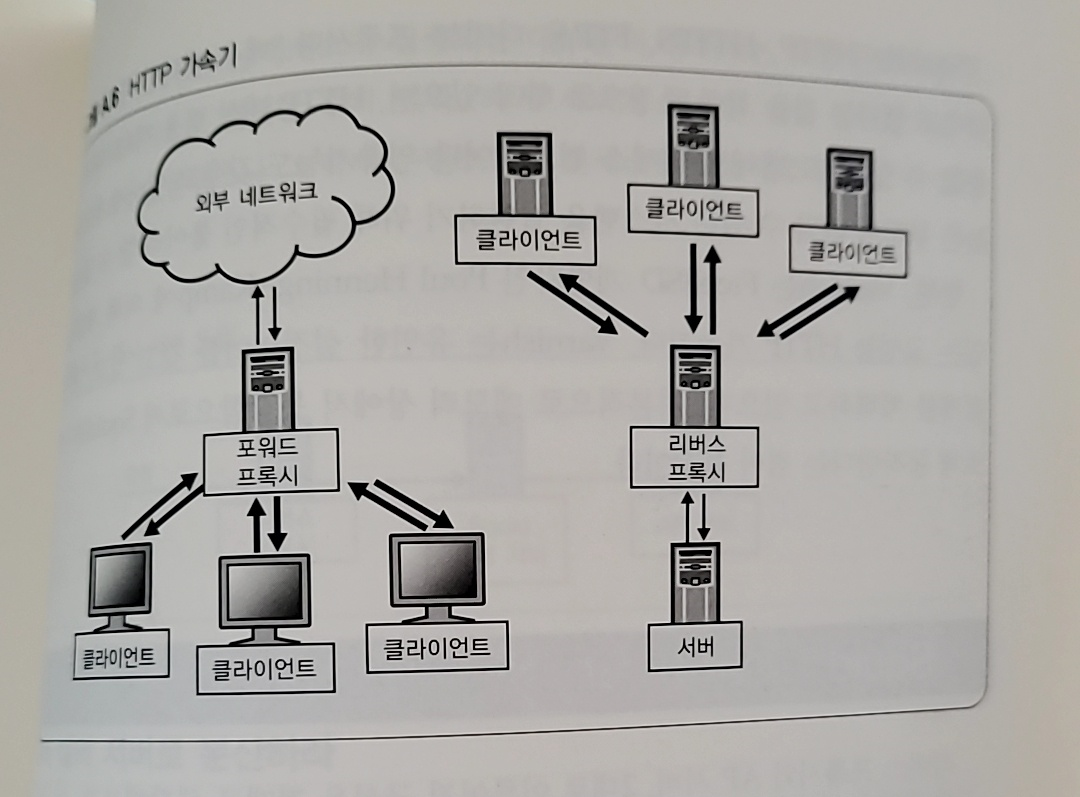
- HTTP 레벨의 캐싱을 수행하는 HTTP 가속기를 사용해 시스템 용량 부족에 대한 대응을 할 수 있다
- HTTP 가속기는 포워드 프록시, 리버스 프록시 2종류가 있다
- 포워드 프록시 : 클라이언트가 외부 서버에 액세스할 때 두는 프록시
- 리버스 프록시 : 외부의 클라이언트가 내부 서버에 액세스 할 때 두는 프록시 (ex Squid, nginx)
- 프록시에서는 요청에 대한 응답을 캐싱해둠으로써 다음에 같은 요청이 전달됐을 때 캐싱해둔 응답을 반환할 수 있다
- 웹 에플리케이션 세계에서는 포워드 프록시보다는 리버스 프록시가 많이 사용된다
| Squid
요청은 다음과 같이 이루어진다
요청 -> 리버스 프록시 -> 캐시 -> AP 서버 - 캐시 서버를 편입시키면 다음과 같은 효과를 얻을 수 있다
- 안정적으로 요청이 발생할 때
- 이 경우에는 일정 비율의 요청을 캐시 서버에서 반환하는 것을 기대할 수 있다
- 이에 따라 AP 서버로 전송되는 요청 수를 줄일 수 있다
-> AP 서버의 대수 증가를 억제/감소 할 수 있다 - AP 서버보다 캐시 서버가 요청 1건당 필요한 서버 리소스가 적다
- 액세스 집중이 될 경우
- 방대한 요청으로 인해 시스템 전체의 수용능력을 넘어서는 것을 막는 효과를 기대할 수 있다
- 이를 위해 액세스가 집중된 콘텐츠를 캐시 서버에 캐싱한다(보통 액세스 집중은 특정 콘텐츠에 된다)
- 캐시 서버가 캐싱된 것을 반환함으로써 엑세스가 집중된 콘텐츠나 그 밖의 콘텐츠로의 액세스도 평소대로 반환할 수 있게 된다
| 여러 대의 서버로 분산
- Squid 서버를 2대 나열함으로써 다중성을 띄게 할 수 있다
- 1대를 스탠바이로 남겨두거나 각각을 독립된 캐시 서버로서 동작시키는 등 몇가지 설정이 가능하다
- 2대의 서버를 연계해서 동작하도록 설정함으로써 효율이 좋게 동작시킬 수가 있다(ICP 사용 기본)
- ICP(Inter-Cache Protocol)을 사용하는 것이 기본이며, 이는 Internet-Draft로 정의되어있는 프로토콜의 일종이다
- ICP를 이용해 캐시를 제어할 수 있는데 한쪽 캐시 서버가 수신한 요청에 대한 응답이 캐싱되지 않은 경우, 반대편 캐시 서버가 콘텐츠를 보유하고 있지 않은지 질의할 수 있다
- 두 캐시 서버 모두 보유하고 있지 않은 경우에만 부모 서버인 AP 서버로 질의하게 된다
| 2단 구성 캐시 서버
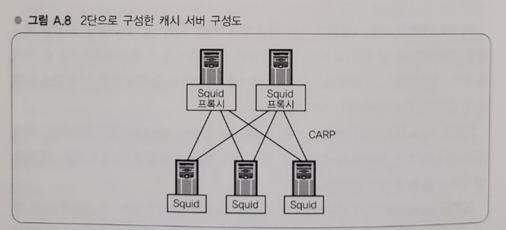
- 크기가 큰 파일을 캐싱하게 되면서 캐시 서버의 부하가 높아지면 용량이 부족할 수 있는데 서버를 2단으로 구성함으로써 보다 확장성이 높은 캐시 서버군을 구성할 수 있다
- 상단 Squid 프록시는 요청을 받아 Squid 캐시서버로 요청을 보낸다 이 때 CARP(Cache Array Routing Protocol)라고 하는 프로토콜에 따라 URL을 키로 적절한 Squid 캐시 서버로 전송한다
- URL을 키로 해서 하단 캐시 서버를 선택함으로써 특정 URL에 대해 특정 캐시 서버만 사용하게 된다
- 캐시 서버가 늘어나도 효율적으로 캐싱할 수 있다
| COSS 크기 결정방법
- COSS(Cyclic Object Storage System) : Squid의 캐시 스토리지 I/O 원리 중 하나. 성능이 뛰어난 점이 특장점
- 히트율을 위해서는 충분한 캐시 용량을 준비해둘 필요는 있지만 크면 클수록 좋은 것은 아니고 과부족이 없으면 최적이다
캐시 용량이 너무 크면 다음과 같은 단점이 있다
- 초기 시작시에 COSS 파일 생성 시에 시간이 걸림
- 서버 재시작 등으로 메모리가 초기화 된 후 디스크 상의 파일이 메모리에 올라가고 Squid 성능이 안정되기까지 시간이 걸림
- 디스크 용량을 압박한다
반면 너무 작으면
필요한 오브젝트를 저장하지 못해 캐시 히트율이 떨어지게 된다 - 최적의 용량은 1초당 저장된 오브젝트수 오ㅂ젝트 평균 크기 오브젝트의 평균 유효시간
| 투입 시 주의점
- Squid의 효율을 높이면 Squid에 장애가 발생했을 때의 영향이 커짐
ex) 2대로 부하를 분산하고 있는데 1대가 고장나고 1대로 감당하기 어려움
-> 고장나도 문제 없을 정도로 서버를 준비
ex2) 재시작/새로 구성 시 Squid 서버거 요청을 처리하기 위한 준비가 안돼있을 때가 있음
-> 사전에 평상시에 접수되는 요청을 보내서 워밍업을 해둘 필요가 있다
-> 로드밸런서에 추가할 때 트래픽 비율을 조장해 통상 운용 시에 비해 적은 트래픽부터 흘려보낸다 | Varnish

- 리버스 프록시로 캐시 서버에 특화된 구현이며 모던한 아키텍처를 채택함으로써 Squid 보다 높은 성능을 확보할 수 있다
- 고속화를 극한까지 추구한 설계
- 다음과 특징이 있다
- 오브젝트는 mmap에 의해 디스크상의 파일에 저장되고 프로세스를 재시작하면 캐시는 모두 사라진다
- 서버 재시작 후 캐싱한 내용이 모두 사라져 캐싱 히트율이 0이 되어 모든 요청이 어플리케이션 서버로 전송된다
- 주의깊게 재시작, 투입하는 것이 중요
- Varnish를 최소 3대 이상 운용해 1대를 재시작해도 전체 캐시 히트율에 큰 타격을 주지 않도록 한다
- 기본적인 설정(ex port 번호)는 명령줄 옵션으로 주고 프록시로서의 규칙은 설정파일(VCL)에 기술한다
- VCL(Varnish Configuration Language)는 설정언어로 내부에 C코드를 기술할 수 있도록 한다
- 설정은 읽어들일 때 내부에 내장된다
- 설정은 동적으로 변경 가능해서 캐싱한 내용을 없애지 않고도 미세한 조정이나 튜닝을 할 수 있다
- varnish 내에는 로그파일을 기록하는 기능이 없고, 공유 메모리상에 기록한다
계산 클러스터
Hadoop
| 대량 로그 데이터의 병렬처리
- 대규모 웹 서비스를 운영하면 대용량 로그 데이터가 쌓인다
- 통계처리나 분석을 빠르게 하기 위해서는 병렬처리가 가능한 계산 클러스터가 필요하다
| MapReduce의 계산 모델
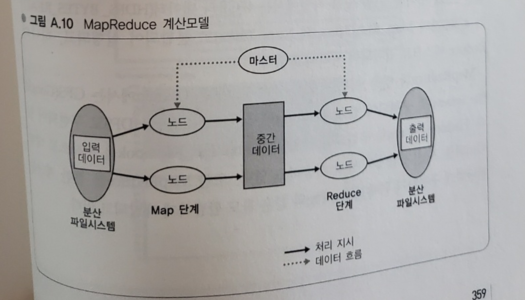
- Hadoop이라는 MapReduce의 오픈소스 구현을 사용
- MapReduce는 Google이 2004년에 발표한 계산모델이다
- MapReduce는 거대한 데이터를 빠르게 병렬로 처리하는 것을 목적으로 하며 이 계산 시스템은 다수의 계산 노드로 구성된 클러스터와 대량 데이터를 분산해서 저장하기 위한 분산 파일 시스템으로 구성된다
- MapReduce 계산모델은 key와 value 쌍의 리스트를 입력 데이터로 해서 최종적으로 value의 리스트를 출력한다
- 계산은 기본적으로 Map단계와 Reduce 단계로 구성된다
- Map 단계
- 마스터 노드에서 입력 데이터를 잘게 분할 해서 각 노드로 분산한다
- 각 노드에서는 분할된 입력 데이터를 계산하고 계산 결과를 key-value 쌍으로 구성된 중간데이터로 출력한다
(k1, v1) -> list (k2, v2)- Reduce 단계
- Map단계에서의 출력 데이터를 key(k2)별로 정리해서 key(k2)와 key 대응하는 값의 리스트(list(v2))로 재구성한다
- 각각의 key를 각 노드로 분산한다 (shuffle pahse)
- 각 노드에 있는 key(k2)와 key에 대응하는 값의 리스트(list(v2))를 입력 데이터로 해서 각 리스트(list(v3))를 최종적인 출력데이터로 하는 처리를 수행한다
(k2, list(v2)) -> (k2, list(v3))- 최종적으로 각 노드에서 값의 리스트(list(v3))을 집약하면 계산이 완료된다
- MapReduce 계산 모델에서는 Map과 Reduce라는 두 가지 처리를 수행하는 함수를 준비하는 것만으로 대량의 데이터를 빠르게 처리할 수 있다(로그 분석, 검색엔진의 인덱스 생성도 가능)
- MapReduce 계산모델 실행에서는 대량의 입력 데이터를 읽어들이는 부분이 병목이 될 수 있기 때문에 분산 파일 시스템과 병용하는 것이 좋다(다수의 노드에 사전에 데이터를 분산 배치, 실제로 처리를 실행할 때 가능한 한 데이터가 로컬에 존재하는 노드에서 처리를 실행하도록 한다)

나는야 누워있는 개발머신