
이전 글에서 정적인 웹 페이지에서 웹 스크래핑하는 방법을 살펴보았다. 하지만 이러한 방법만으로만 스크래핑을 진행하기엔 한계가 존재한다. 웹 페이지가 정적인 형태로만 존재하는 것이 아니기 때문다.
첫 번째 한계는 정적 웹 페이지와는 달리 동적 웹 페이지의 동작은 비동기 방식이다. 따라서 상황에 따라 데이터가 완전하지 않은 경우가 존재하고, 응답 후 렌더링이 될 때까지의 지연시간이 존재하기 때문에 바로 정보를 추출하기 어렵다. 두 번째 한계는 키보드 입력, 마우스 클릭 등의 이벤트가 발생했을 때 처리가 불가능하다는 것이다.
이같은 문제를 해결하기 위한 방법이 존재한다. 첫 번째 한계의 해결 방법은 임의로 시간을 지연한 후, 데이터 처리가 끝난 후 정보를 가져오면 된다. 두 번째 한계의 해결 방법은 프로그래밍을 통해 사용자 입력과 같은 이벤트를 발생시키는 것이다. 이 같은 문제를 해결하기 위해 이번 글에선 웹 브라우저를 자동화하는 라이브러리인 Selenium의 활용법을 살펴볼 것이다.
Python으로 동적인 웹 페이지에서 웹 스크래핑하기
Selenium이란
Selenium은 웹 어플리케이션을 자동화하고 테스트하는 데 사용되는 오픈소스 프레임워크이다. Selenium은 웹 브라우저의 자동화를 가능하게 한다. 이를 통해 웹 어플리케이션을 테스트하거나 스크래핑하기 위해 프로그래밍적으로 브라우저를 제어할 수 있다.
이전 장에서 살펴본 BeautifulSoup은 HTML 및 XML과 같은 정적 웹 페이지의 구문 분석을 위해 사용된다. Selenium은 주로 웹 어플리케이션의 테스트 자동화 및 스크래핑을 위해 사용된다. 이러한 도구들은 서로 보완적이며, 목적에 맞게 사용해야 한다.
Selenium 설치 및 사용
다음은 Selenium 프레임워크를 설치하는 명령어이다. Jupyter notebook 환경이라면 앞에 '%'를 추가로 붙여야한다.('%'를 이용해서 노트북(.ipynb) 환경에서 터미널 코드를 실행할 수 있다.)
pip install bs4웹 브라우저와 연동을 위해서는 WebDriver가 필요하다. WebDriver는 웹 브라우저를 제어할 수 있는 자동화 프레임워크이다. 이 실습에서는 Chrome을 기준으로 설명하겠다.
pip insall을 통해 webdriver를 관리하는 라이브러리 webdriver-manager를 설치한다.
pip install webdriver-manager다음으로 설치한 패키지들을 활용하는 방법을 알아보자.
# selenium으로부터 webdriver 모듈을 불러온다.
# 웹 브라우저와 연동을 위해
from selenium import webdriver
# Chrome 객체의 인자로 넣기 위해
from selenium.webdriver.chrome.service import Service
# 사용 중인 Chrome version과의 싱크를 맞추기 위해
from webdriver_manager.chrome import ChromeDriverManager
# Selenium을 활용하여 조작하기 위해서 driver 객체 생성
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 위 명령을 통해 웹 브라우저를 실행하고 파이썬과 연동할 수 있음
# .get(url)을 활용해 요청을 보낼 수 있음
driver.get("http://www.example.com")
# 응답을 받은 후, page_source 속성을 통해 Response의 HTML 문서를 확인할 수 있음
print(driver.page_source)보통 위 같은 코드는 with-as 구문을 통해 주어진 명령이 끝나면 driver를 종료하도록 설정하는 것이 일반적이다. 따라서 위 명령들을 with-as 구문을 활용하여 다시 작성한 것은 아래와 같다.
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("http://www.example.com")
print(driver.page_source)Driver에서 특정 요소 추출하기
selenium은 받아온 응답으로부터 특정 요소를 추출할 수 있다. 따라서 응답을 가지고 있는 driver/요소에 대해서 다음과 같은 메서드를 적용할 수 있다.
-
요소 하나 찾기
.find_element(by, target)
by: 대상을 찾는 기준 : ID, TAG_NAME, CLASS_NAME, ...
target: 대상의 속성 -
요소 여러개 찾기
.find_elements(by, target)
by: 대상을 찾는 기준 : ID, TAG_NAME, CLASS_NAME, ...
target: 대상의 속성
아래는 예시 링크에서 p 태그에 해당하는 요소를 찾아서 출력하는 코드이다.
# p 태그에 해당하는 요소 하나를 찾아서 출력
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("http://www.example.com")
print(driver.find_element(By.TAG_NAME, "p").text)
# p 태그에 해당하는 요소 여러개를 찾아서 출력
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("http://www.example.com")
for element in driver.find_elements(By.TAG_NAME, "p"):
print(element.text)Selenium Wait
Selenium은 동적 웹 사이트에 대한 지원을 진행하기 위해 명시적 기다림(Explicit Wait) 과 암묵적 기다림(Implicit Wait) 을 지원한다.
- Explicit Wait : 로딩이 다 될 때까지 지정한 시간 동안 기다림 (e.g. 다 로딩이 될 때까지 5초동안 기다려!)
- Implicit Wait : 특정 요소에 대한 제약/조건을 통한 기다림 (e.g. 이 태그를 가져올 수 있을 때까지 기다려!)
Selenium의 Wait 실습
해당 사이트에 있는 공연의 이름들을 스크래핑하는 실습을 진행하겠다.
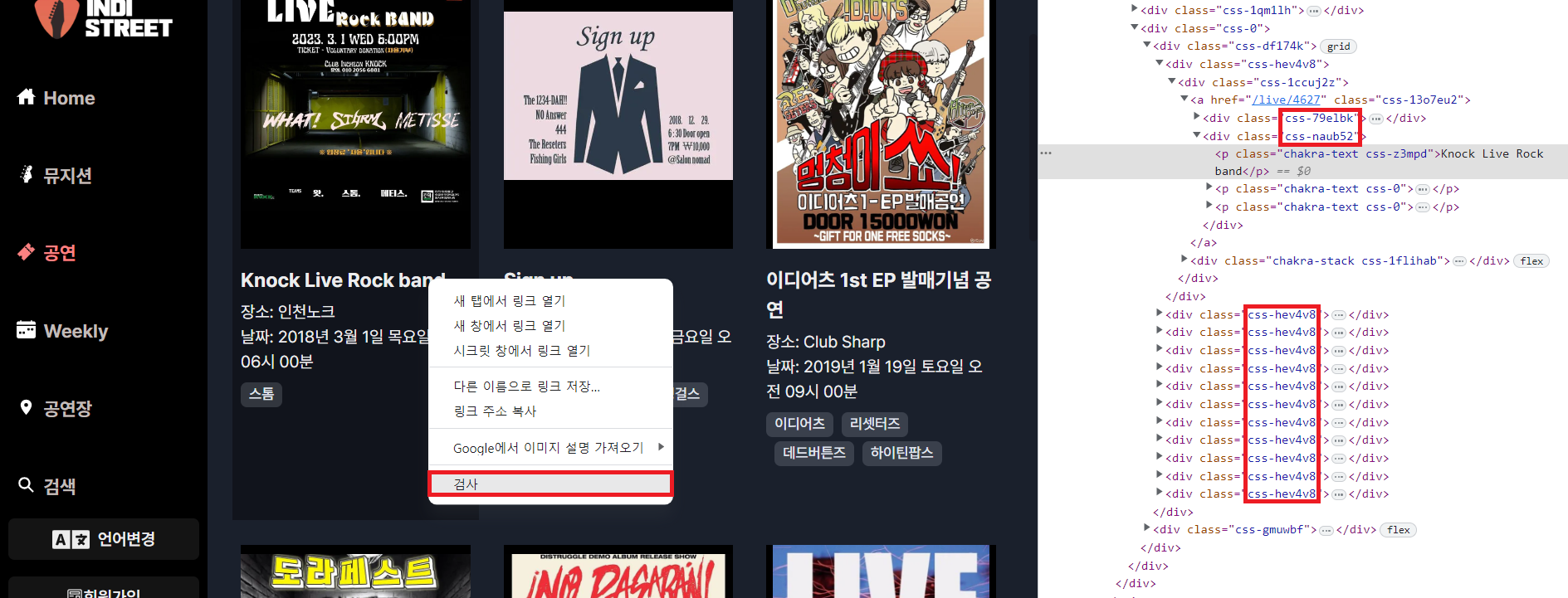
공연 제목의 검사창을 통해 개발자 도구를 쉽게 띄울 수 있다. html 내용을 살펴보면 class명이 일련번호처럼 특이한 것을 확인할 수 있다. 이는 최근 웹 사이트에서 스크래핑을 방지할 목적으로 랜덤하게 class 이름을 생성하기 때문이다.
이러한 경우에서 쓸 수 있는 방법이 여러가지가 있는데, 그 중 한 가지 방법인, 위치를 활용한 방법을 알아보도록 하겠다. 위치를 활용한 방법으로 XPath를 활용할 수 있다. XPath는 XML, HTML 문서 등의 요소의 위치를 경로로 표현하는 것을 의미합니다. class 이름이 아닌 절대적인 위치를 이용하기 때문에 정확한 스크래핑이 가능하다.
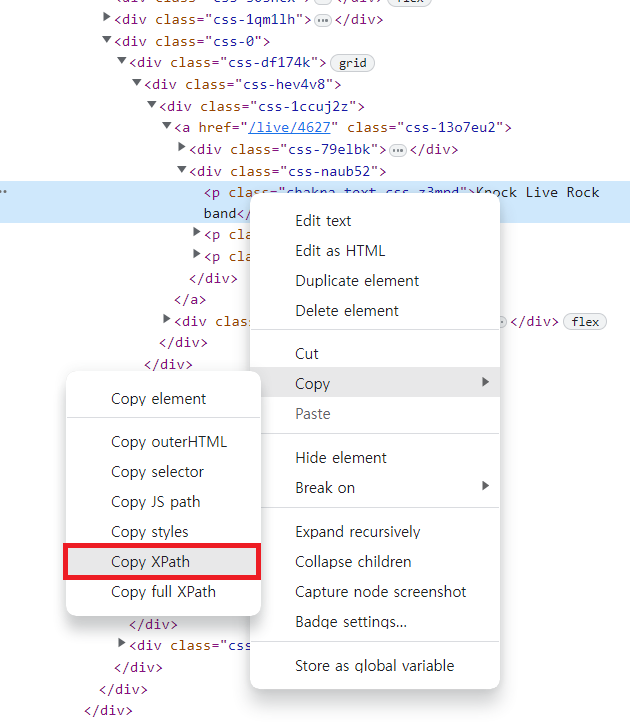
XPath를 알고자하는 태그에서 마우스 오른쪽 버튼을 통해 XPath를 손쉽게 알 수 있다.
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]')위의 코드처럼 XPath를 활용해 예시 사이트에 요청을 진행하고, 예시 사이트의 첫 번째 이벤트의 제목을 가져오려고 시도하면 오류가 발생한다. 이는 해당 웹 페이지가 동적 웹페이지이기 때문이다. 동적 웹 페이지를 성공적으로 스크래핑하기 위해서는 Wait을 사용해야한다.
Implicit Wait을 사용하는 방법
.implicitly_wait()을 활용해서 암시적 기다림을 적용할 수 있다.
주의할 점으로 반드시 해당 시간을 기다리는 것이 아니라, 로딩이 다 될때까지의 한계 시간의 의미를 가진다.
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
driver.implicitly_wait(10) # 최대 10초까지 기다리는데, 중간에 응답이 오면 다음 명령어를 수행
print(driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]').text)Explicit Wait을 사용하는 방법
WebDriverWait()과 아래 두 메서드를 활용해서 명시적 기다림을 적용할 수 있다.
until(): 인자의 조건이 만족될 때까지until_not(): 인자의 조건이 만족되지 않을 때까지
예를 들어, id가 target인 요소가 존재할 때까지 기다린 후 다음 명령을 진행하는 명령어는 아래와 같다.
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "target")))이때, EC는 expected_conditions로, selenium에서 정의된 조건들이다. (~가 존재하면, ...)
이곳에서 더 자세한 정보를 확인할 수 있다.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
# 주어진 XPath가 등장할 때 까지 Wait을 진행함
# expected_conditions의 .presence_of_element_located() 활용
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]')))
print(element.text)여러 공연 제목 가져오기
여러 공연의 제목들을 가져오기 위해 XPath를 관찰해보면, 특정 규칙을 발견할 수 있다.
//*@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[1]/div/a/div[2]/p[1]
//*@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[2]/div/a/div[2]/p[1]
//*@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[3]/div/a/div[2]/p[1]
이를 일반화해서 가장 먼저 등장하는 10개의 이름을 추출하는 코드는 다음과 같다.
with webdriver.Chrome(service=Service(ChromeDriverManager().install())) as driver:
driver.get("https://indistreet.com/live?sortOption=startDate%3AASC")
driver.implicitly_wait(10)
for i in range(1, 11): # 1~10
element = driver.find_element(By.XPATH, '//*[@id="__next"]/div/main/div[2]/div/div[4]/div[1]/div[{}]/div/a/div[2]/p[1]'.format(i))
print(element.text)동적인 웹 페이지에서 이벤트 처리하기
마우스 이벤트 처리하기
마우스에서 발생할 수 있는 대표적인 이벤트는 다음과 같다.
- 마우스 움직이기(move)
- 마우스 누르기(press down)
- 마우스 떼기(press up)
selenium을 활용하여 해당 사이트에서 '로그인'창에 접속하려고 한다. 이를 위해서는 버튼을 찾은 후 이를 클릭해야 한다. 마우스 입력은 크게 다음과 같은 과정을 거친다.
- 입력하고자 하는 대상 요소를 찾는다.(
find_element()이용) - 입력하고자 하는 내용을
click을 통해 전달한다. .perform()을 통해 동작한다.
navigation bar에 있는 로그인 버튼의 클래스를 먼저 확인한다.
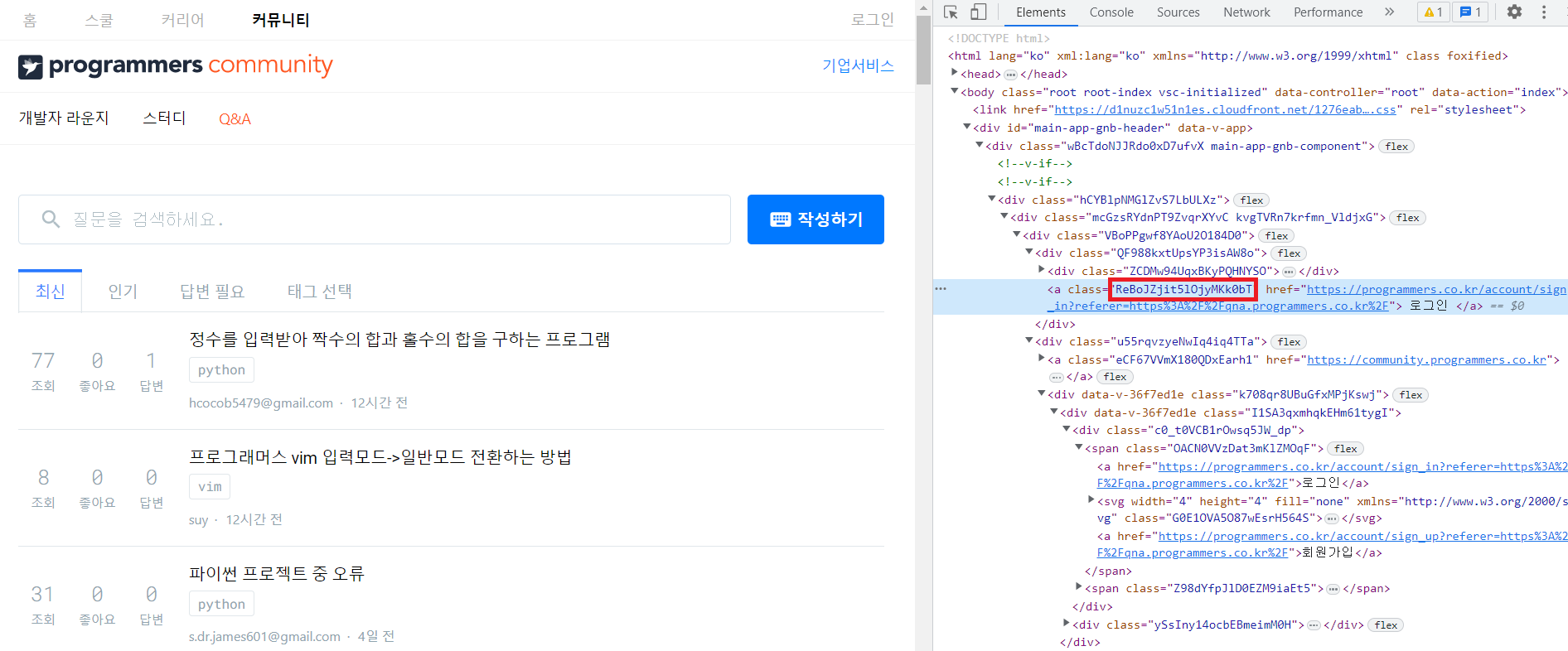
다음은 사이트에 접속 후 '로그인' 창을 띄우는 코드이다.
# 스크래핑에 필요한 라이브러리 선언
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://qna.programmers.co.kr/")
driver.implicitly_wait(0.5)
# 해당하는 클래스 요소 찾기
button = driver.find_element(By.CLASS_NAME, "ReBoJZjit5lOjyMKk0bT")
# 찾은 요소 클릭을 수행
ActionChains(driver).click(button).perform()키보드 이벤트 처리하기
키보드에서 발생할 수 있는 대표적인 이벤트는 다음과 같다.
- 키보드 누르기(press down)
- 키보드 떼기(press up)
selenium을 활용하여 해당 사이트에서 아이디와 비밀번호를 입력하고 로그인을 하려고 한다. 키보드 입력의 과정은 다음과 같다.
- 입력하고자 하는 대상 요소를 찾는다.(
find_element()이용) - 입력하고자 하는 내용을
send_keys_to_element를 통해 전달한다. .perform()을 통해 동작한다.
개발자 도구에서 아래 화면 속의 각 요소의 클래스를 찾는다.

다음은 사이트에 접속 후 아이디와 비밀번호 입력을 하고 로그인 버튼 클릭까지의 과정을 진행하는 코드이다.
# 스크래핑에 필요한 라이브러리 선언
from selenium import webdriver
from selenium.webdriver import ActionChains
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.actions.action_builder import ActionBuilder
from selenium.webdriver import Keys, ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# driver를 이용해 해당 사이트에 요청 보내기
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://programmers.co.kr/account/sign_in?referer=https%3A%2F%2Fqna.programmers.co.kr%2F")
time.sleep(1)
# "아이디" input 요소에 본인의 아이디를 입력
id_input = driver.find_element(By.ID, "user_email")
ActionChains(driver).send_keys_to_element(id_input, "본인의 아이디").perform()
time.sleep(1)
# "패스워드" input 요소에 본인의 비밀번호를 입력
pw_input = driver.find_element(By.ID, "user_password")
ActionChains(driver).send_keys_to_elemnet(pw_input, "본인의 패스워드").perform()
time.sleep(1)
# "로그인" 버튼을 눌러서 로그인을 완료
login_button = driver.find_element(By.ID, "btn-sign-in")
ActionChains(driver).click(login_button).perform()
time.sleep(1)