ETL/ELT 도구들이 Ingestion and Transformation에 있음
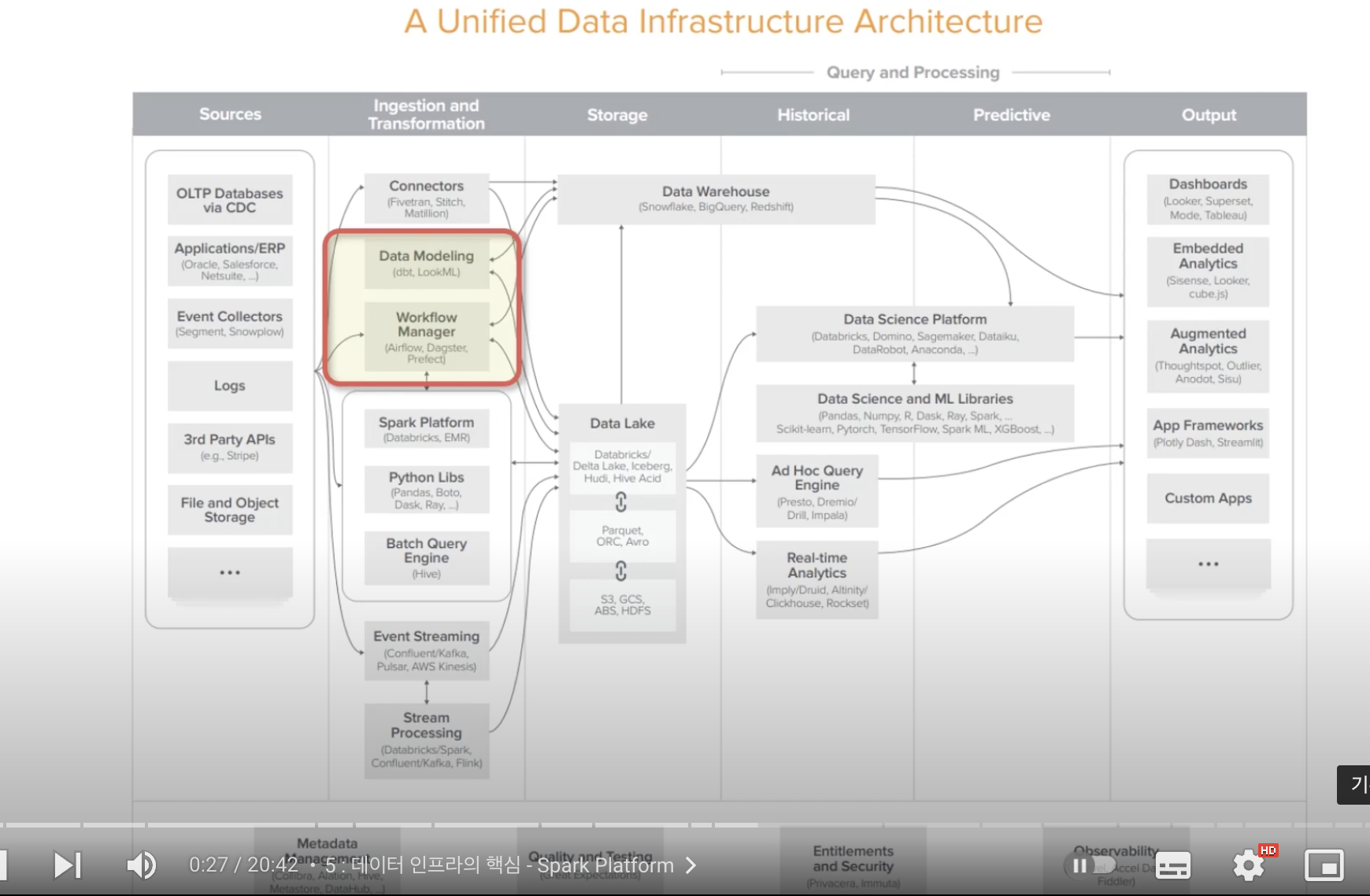
Ingestion and Transformation
Connectors
-
데이터 웨어하우스나 데이터 레이크로 전달
-
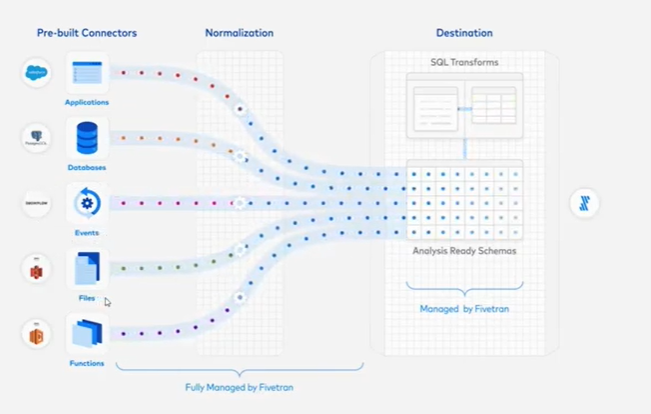
Fivetran
- ELT 도구
- Normaliztion, Destination을 모두 수행해줌
-
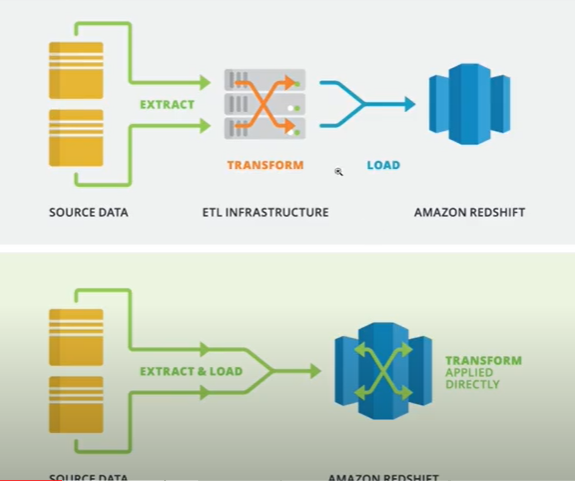
ETL -> ELT로 변환하는 이유?
- 저장공간 비용은 저렴해지고, 변환 컴퓨팅 파워가 더 고비용
- load가 더 싸지기 때문
-
Panoply
- ELT도구 & 아마존 레드쉬프트 기반으로 데이터웨어하우스까지 같이 가지고 있는 서비스
- 데이터 extract => 웨어하우스에 저장
-
Stitch
- data ELT 도구
- 대부분의 비즈니스 서비스 제공
-
Matillion
- data ELT 도구
- extract load 완전 무료
Data Modeling
-
source에서 오진 않는다
-
데이터웨어하우스, 데이터레이크와 주고 받음
-
dbt(data build tool)
- 데이터 분석가들을 위한 엔지니어링 도구
- analysist 들에게 개발환경 제공
- +version control
- test해볼 수 있게 제공
-
LockML
- BI 도구
Workflow Manager
-
데이터 웨어하우스로 옮길 때 workflow 단위로 옮기는 것
-
Apache Airflow
- schedule and monitor workflows
- task scheduling
- 언제 어떤 task
- distribbution execution
- 분산해서 실행
- dependency management
- 앞의 workflow가 끝나기전에 실행하면안된다는 의존!
- 동시에 실행될 수는 있음..
- Dag
- Directed Acyclic Graph
- 방향 o cycle x
- Scalable(worker만 늘리면 무한대로 늘릴 수 있음)
- 파이썬 코드로만 구현
-
Dagster
- airflow와 유사
- DAG으로 구성, 파이썬
- 구성요소 구현 -> 파이프라인 연결
- Data Application 을 만들겠다!
- data 기반으로 움직임

-
Prefect
- = airflow, 더 최근, 더 사용하기 쉬움
- workflow를 자동화하는 엔진
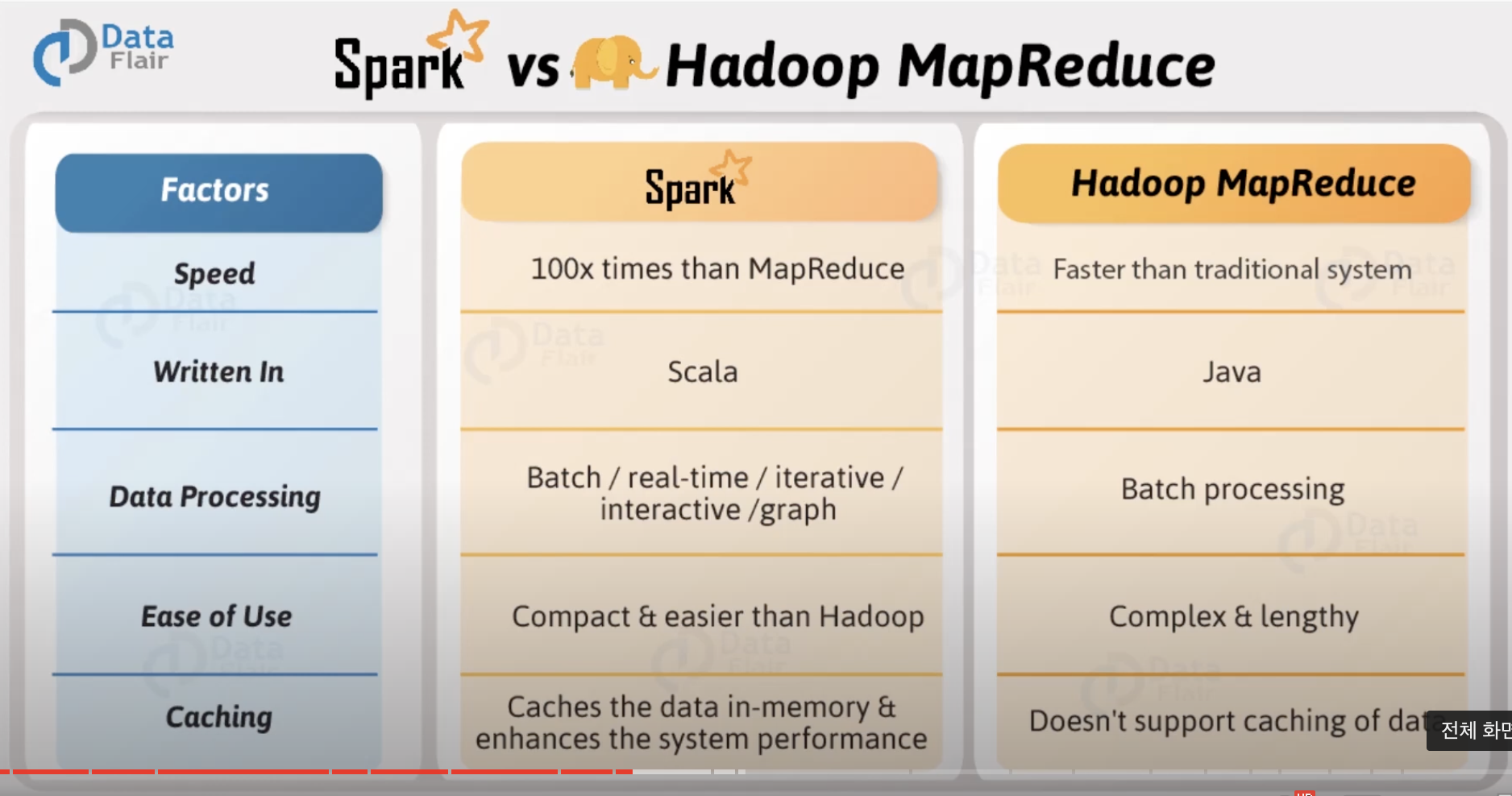
Spark
-
RDD 기반으로 SQL, Streaming, MLlib, GraphX 처리
-
RDD=> DataFrame=> Dataset
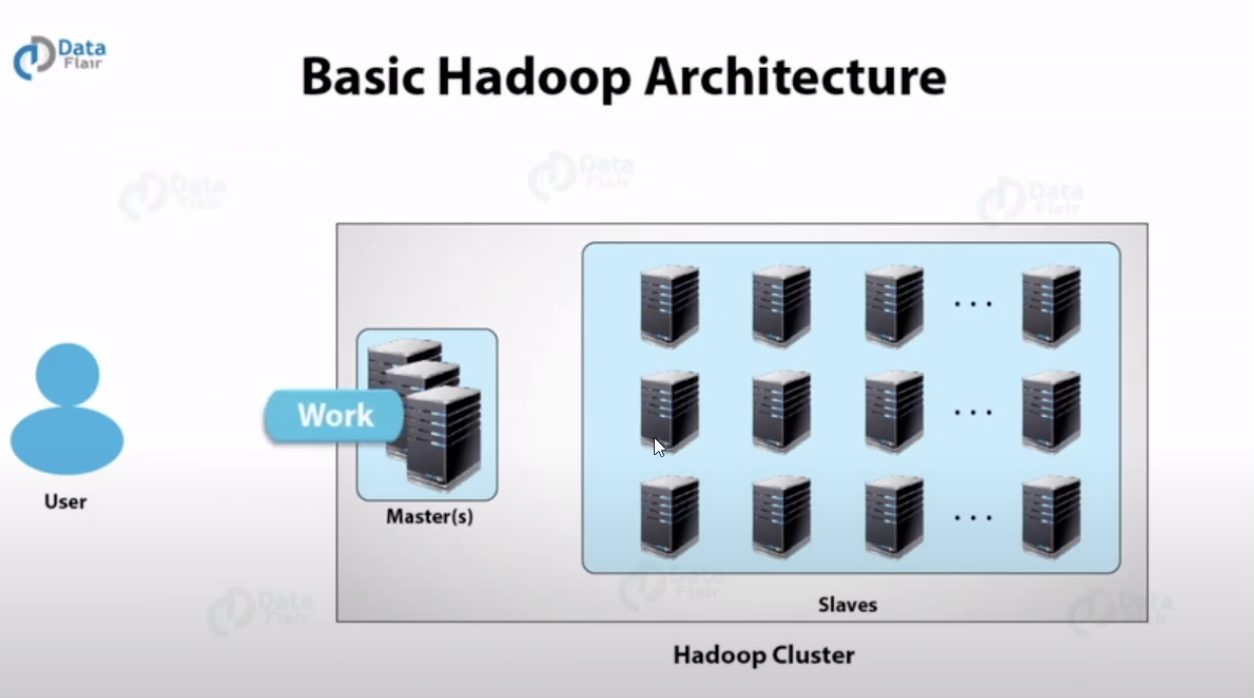
Hadoop
Master가 여러개의 서버에 Work에 쪼개고 나눠서 수행(=Map-Reduce, Map-Reduce)
APACHE Spark
- open-source distributed general-purpose cluster computing framework
Spark가 왜 빠를까?
- Hadoop 약점
- 복잡하고,multi-stage한 처리
- interactive하고 ad-hoc한 쿼리
=> 특수목적 분산 프레임웍 등장
근본적인 해결책? => Spark
-
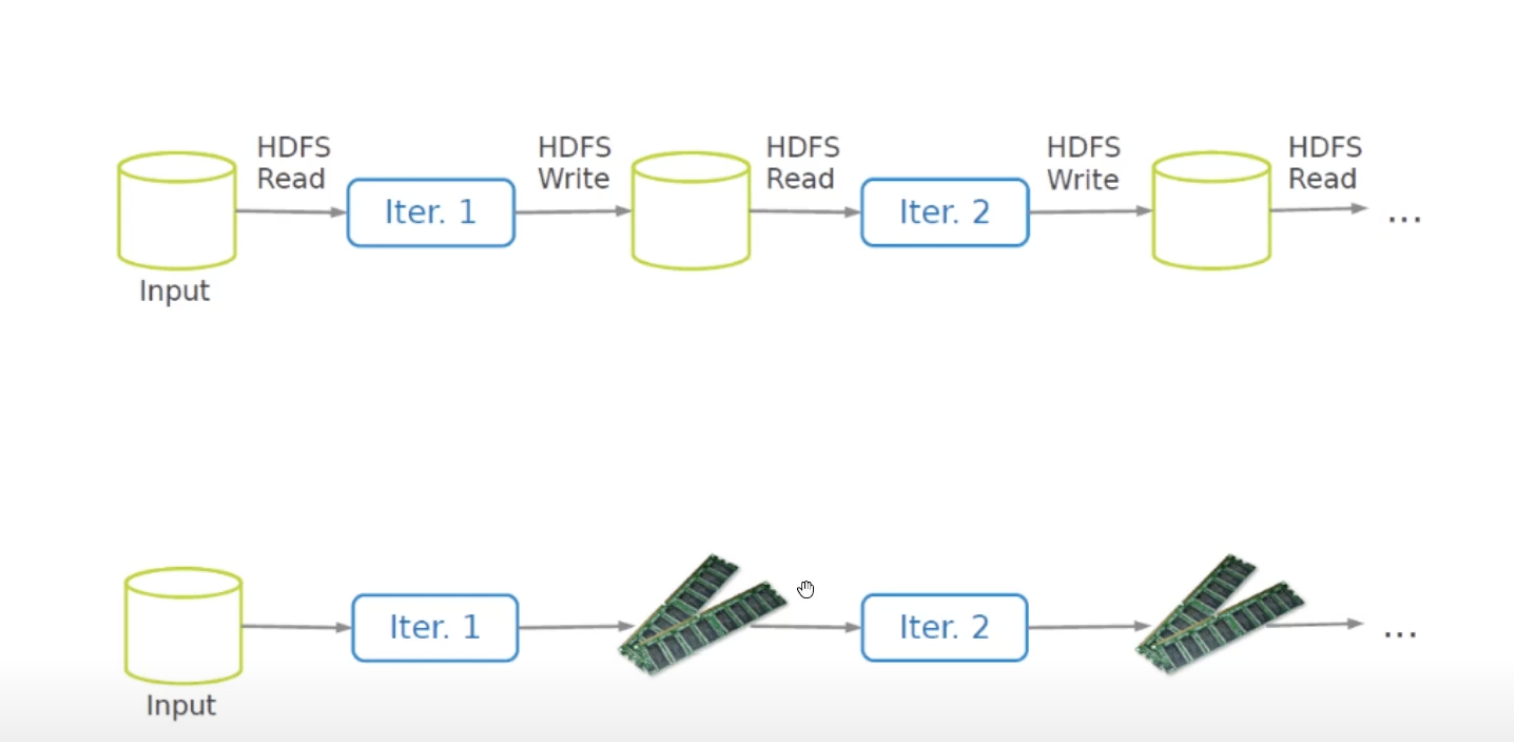
HDFS(HADOOP FILE SYSTEM)를 읽고쓰고 하면 느림 -> RAM으로 대체(저렴)
-
but 중간에 error나면 fault는 어떻게 해결하는가?(RAM은 중간에 깨지면 없어짐)
-
어떻게하면 fault-tolerant & efficient한 램스토리지를 만들 수 있을까?
-
RDD로 해결(Resilient Distributed Datasets)
- RAM을 READ ONLY로 사용(ROM 처럼)
- Immutable, partitioned collections of records
- 계보만 기록해도 fault-tolerant
- 어떻게 만들어졌는지만 기록해두면 또 만들 수 있음
-
코딩은 실제 계산 작업 x 점점 더 나아가며 lineage 계보를 directed acyclic graph(DAG)로 디자인 해 나가는 것
-
RDD operator
- transformations & actions
-
lazy-execution
- transformation들로 코딩하고 있으면 아무 일도 안일어남
- lineage만 생성
- action에 해당하는 명령이 불리면 그제서야 쌓였던 것 실행
Databricks
- Spark 기반 Unified Data Analytics Platform
- Just-in-Time Data Platform
Spark -> 자동차 엔진
Databricks -> 자동차 한대
EMR
- Elastic Map Reduce
- Amazon의 Data Bricks, 좀더 확장성
Python Libs
Pandas
- python, opensource
- panel data
- Python data analysis
- Tabular data를 다룸, DataFrame으로 처리
- 특정 row, column을 처리하여서 데이터를 처리
- 여러개 table 코드로 처리
Boto
- Amazone Web Service for Python
Dask
- natively scale
- 병렬로 여러개의 서버에서 처리
- 데이터 프레임을 여러개의 서버가 나뉘어서 처리

Ray
- 파이썬 코드를 분산 컴퓨팅 할 수 있게
Dask <-> Ray
Dask: centralized scheduler, 여러 대의 서버에서 데이터사이언스에서 분산 처리
Ray: Bottom-up scheduling(을 위해 task latency와 throughput 향상), 여러 대의 서버에서 머신러닝
Batch Query Engine
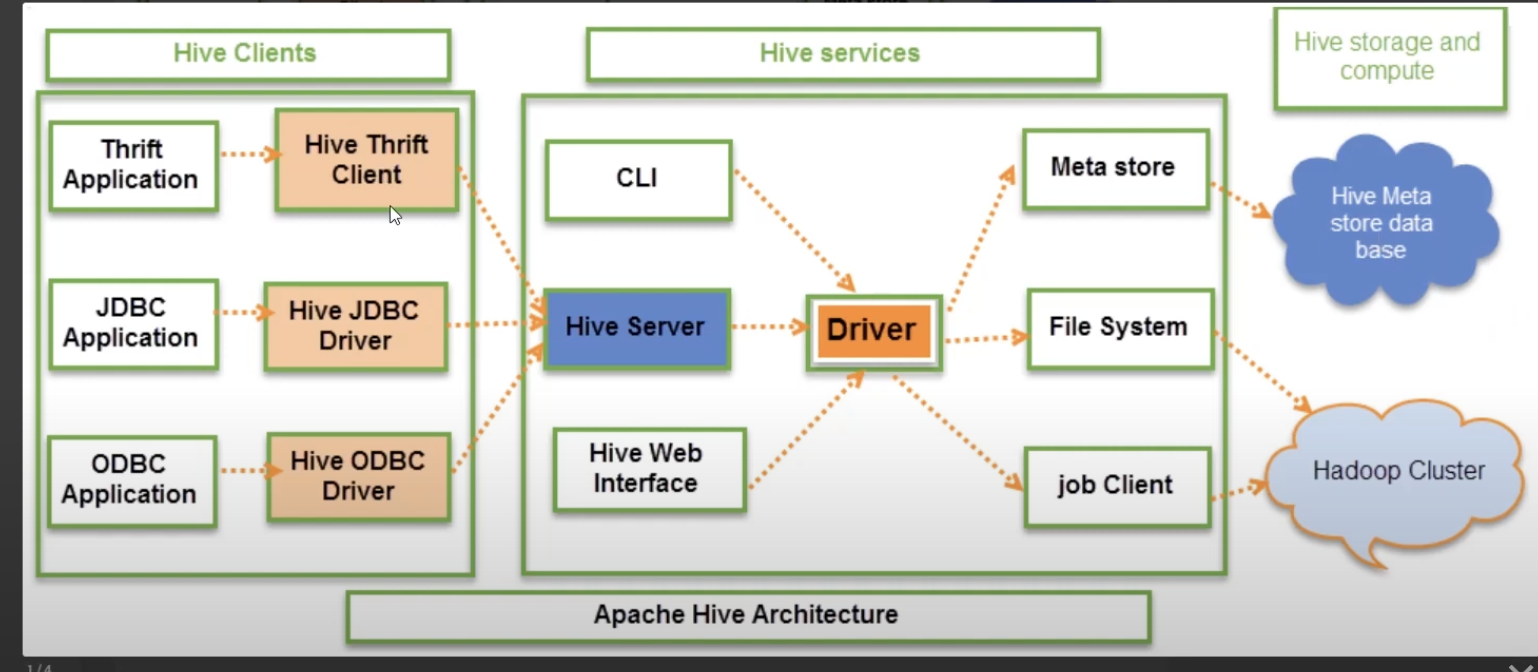
Hive
- Hadoop과 연결, Meta Store 연결
- 기존에 HDFS에 있는걸 Spark에 연결
Event Streaming
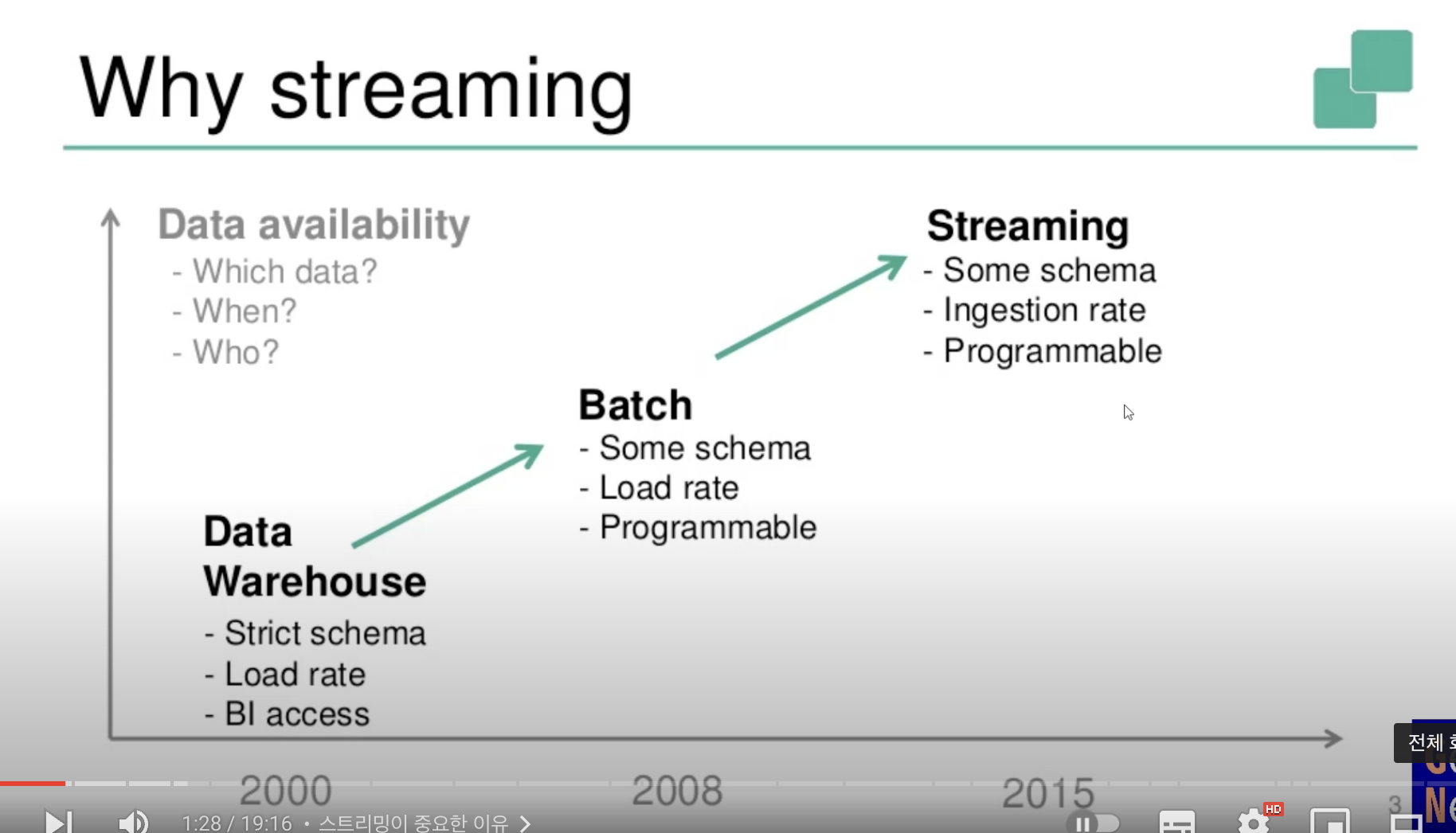
- Event Streaming이 중요한가?
- Data 가용성이 중요
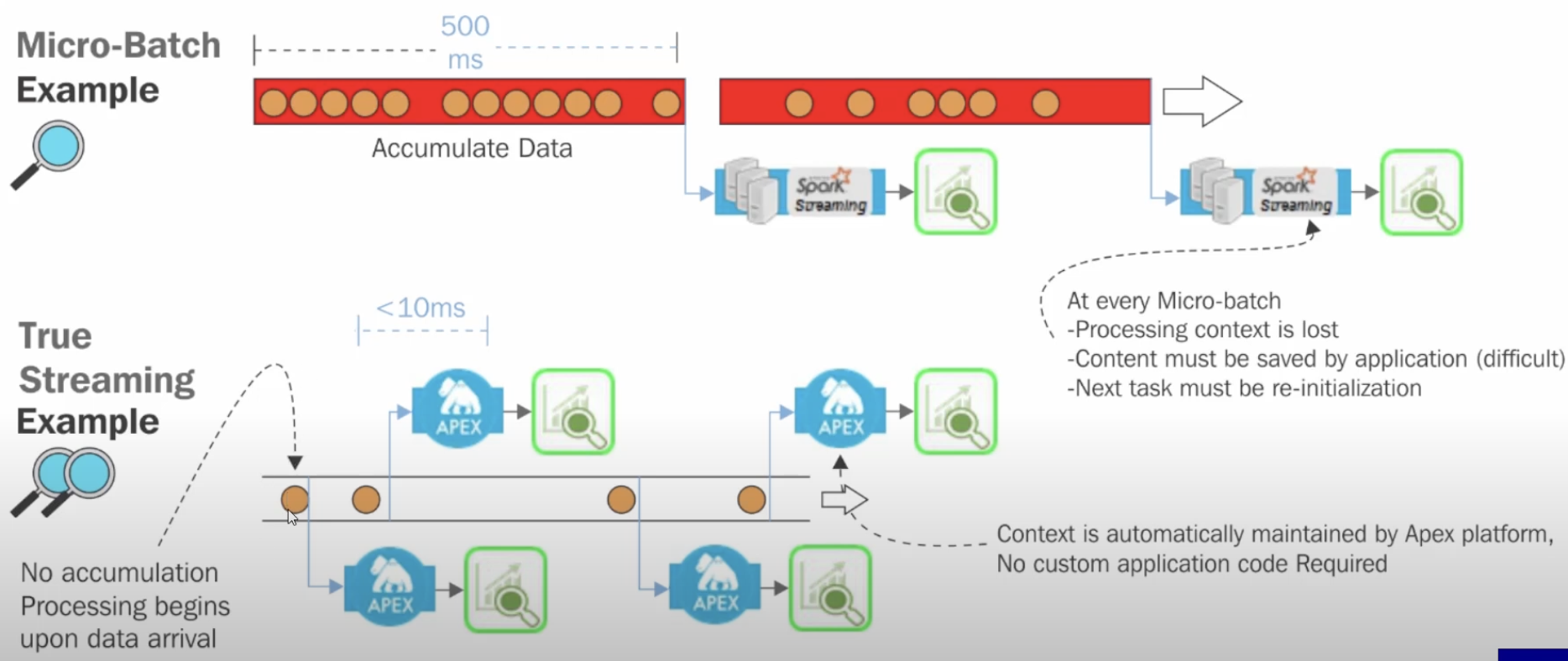
- Spark batch 기반
APACHE KAFKA
-
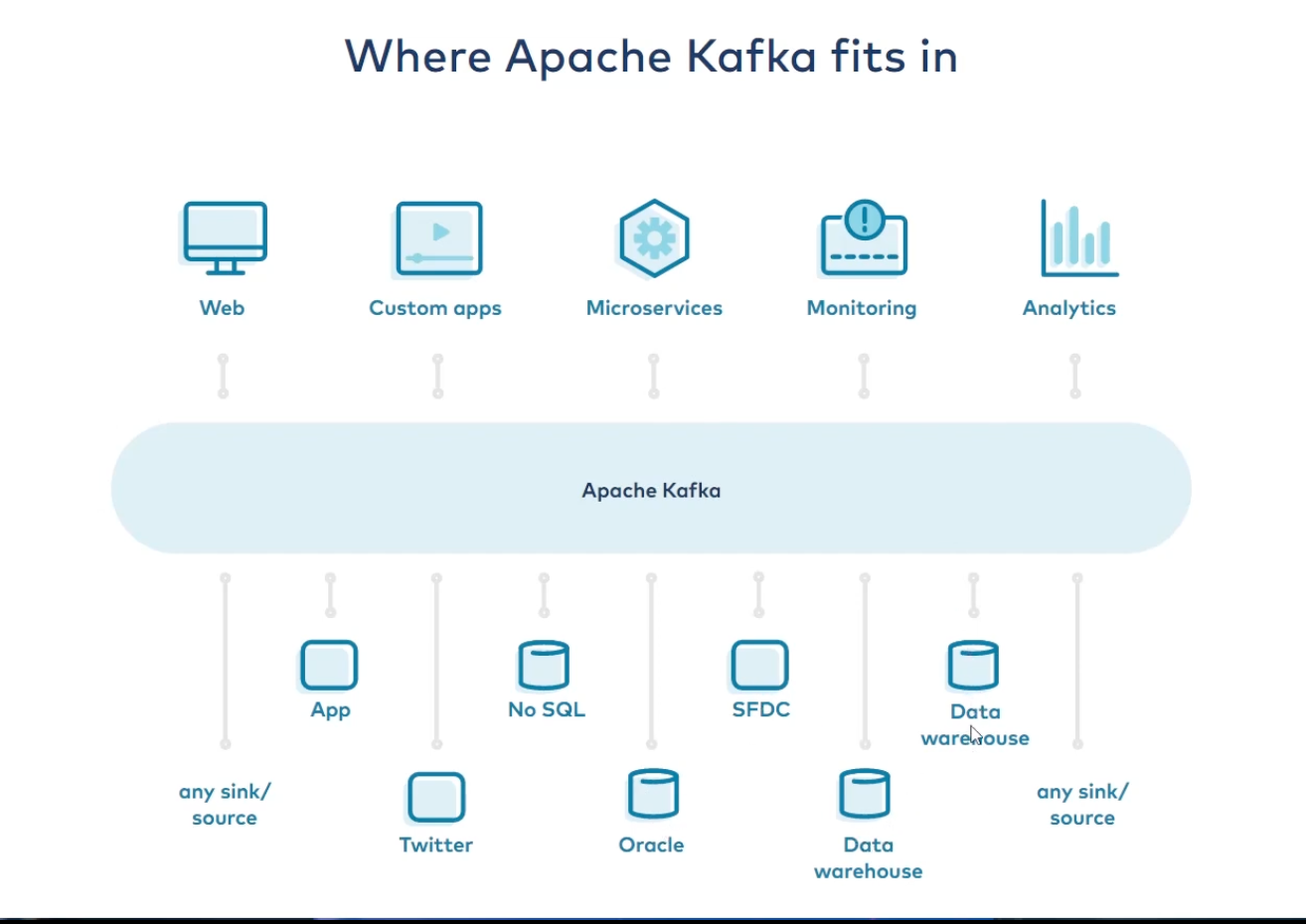
open-source distributed event streaming platform
- High Throughput
- Scalable
- Permanent Storage
- High Availability

-
partition을 늘이면 줄일 수 없음
- 또 다른 토픽 만들고 복사 후 제거..
-
단점
- setup 어려움, scale 까다로움
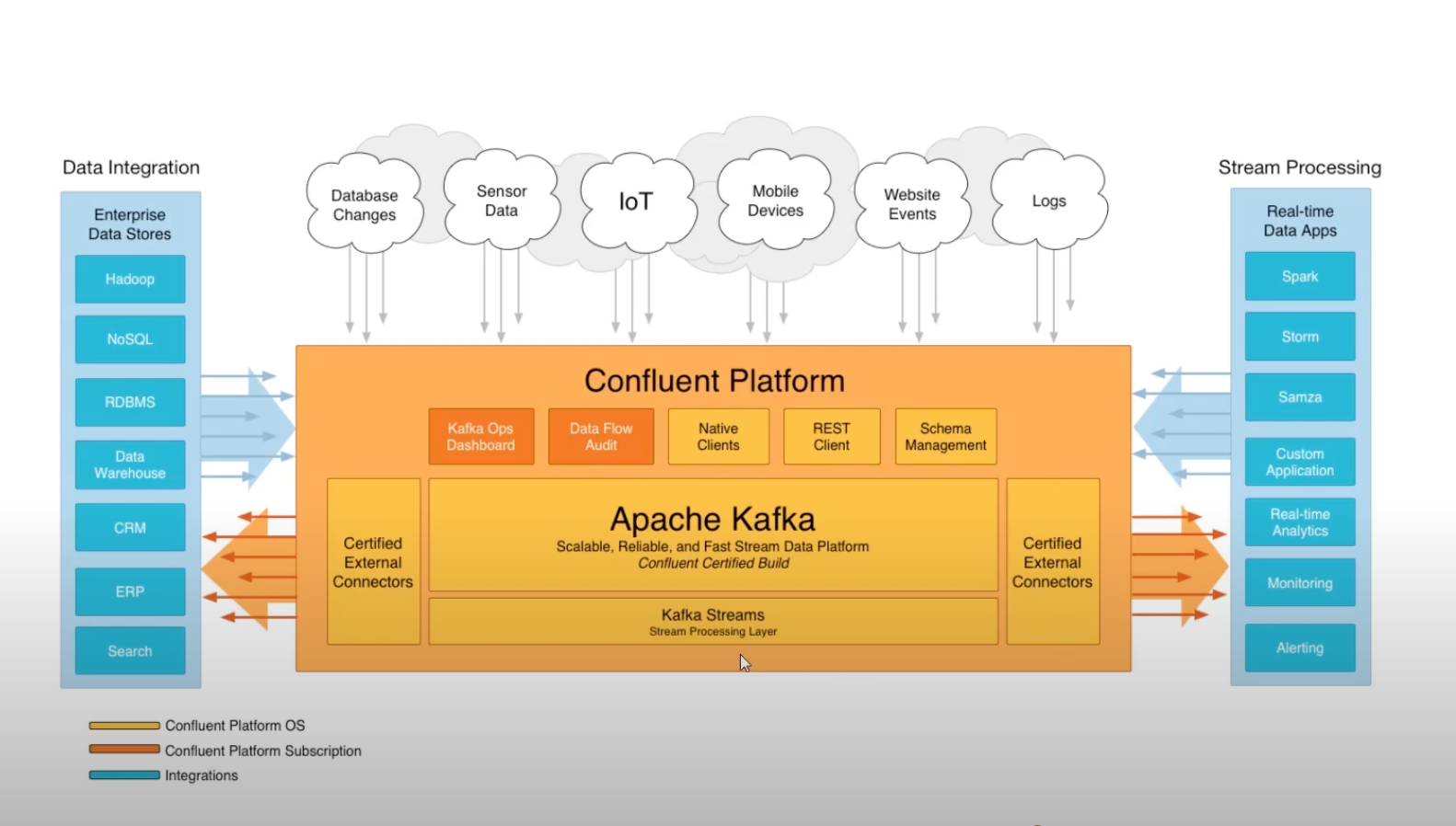
CONFLUENT
- KAFKA를 쓰기 쉽게
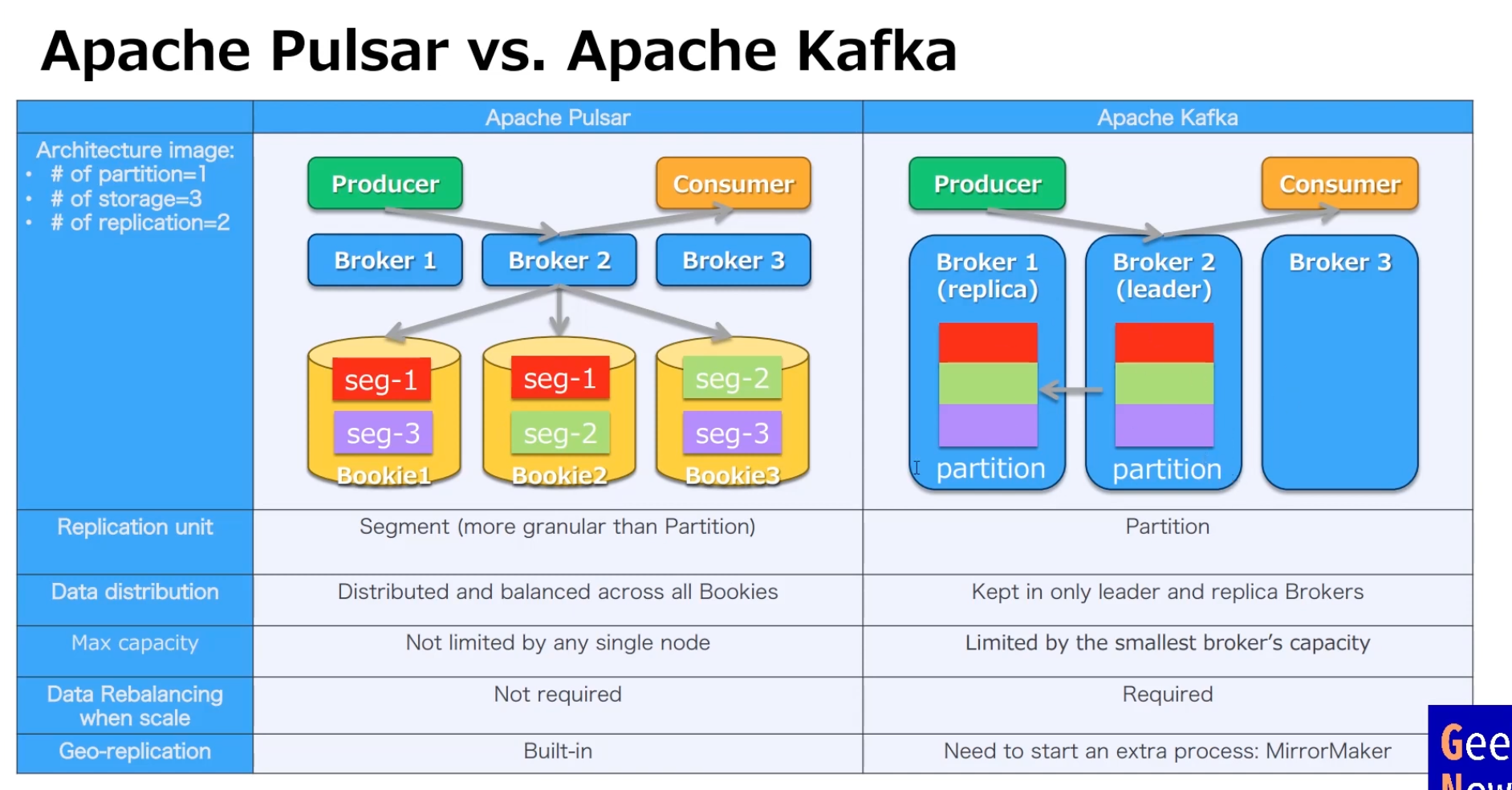
Pulsar
- Push하는 방식 , but pull하는 것처럼 보임
- segment 단위로 쪼개서 저장
Kinesis
- Amazon이 만듦
- 유사
- 늘이고 줄이는게 다 된다!
Kinesis vs Kafka
Kafka 훨씬 빠름
(일주일 이상 유지, 빠름)
Stream Processing
- streaming 발생하면, 쌓이는 이벤트 처리
- Batch, Real-time 둘다 가능
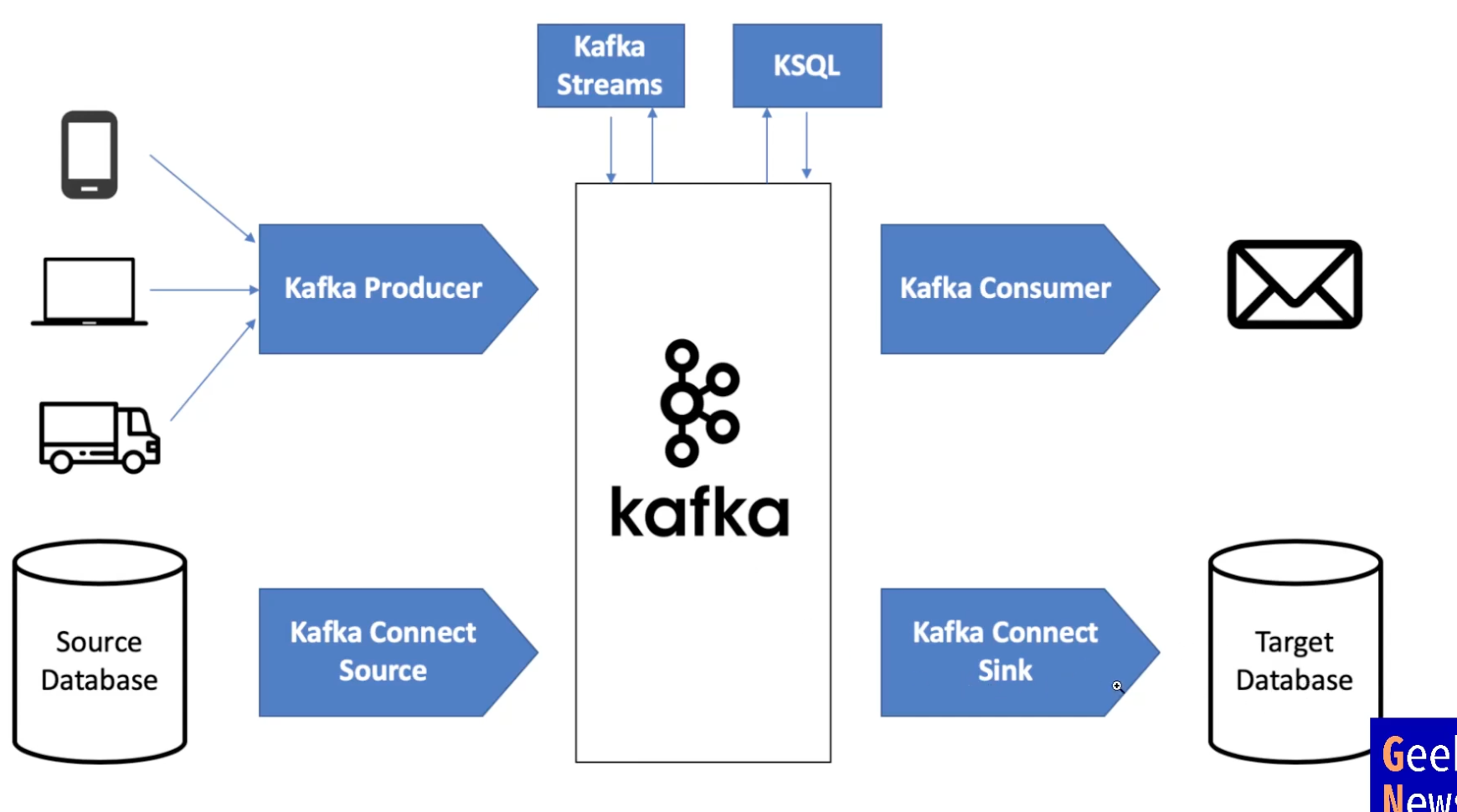
Kafka Streams API
- Flink
- Stateful Computations over Data Streams
- Focused on large-scale data analytics
