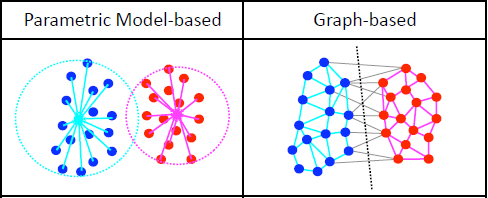
clustering은 Parametric-based 와 Graph-based 알고리즘이 존재한다
K-means, k-평균
우선 비지도 학습 중에서 Clustering이지
군집은 데이터분석, 차원축소기법, 이상치 탐지, 이미지 분할 등에 사용된다!
알고리즘이 찾을 클러스터 개수 k를 지정해야한다.
K-means algorithm
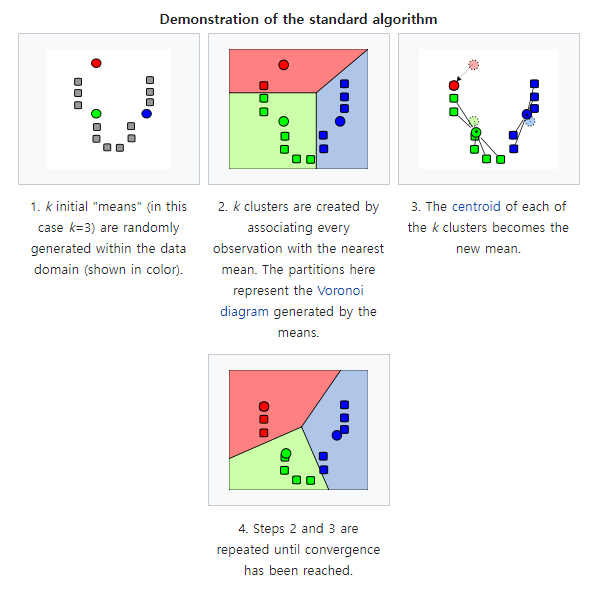
- algorithm
1.k개의 임의의 중심점(centroid)을 배치하고
2.각 데이터들을 가장 가까운 중심점으로 할당한다(군집을 형성하는 것)
3.군집으로 지정된 데이터들을 기반으로 해당 군집의 중심점을 업데이트한다
4.2번,3번 단계를 수렴이 될 때까지, 즉 더이상 중심점이 업데이트 되지 않을 때까지 반복한다
식을 외워야할까??

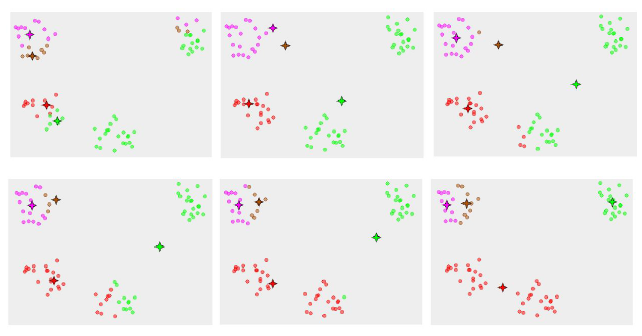
K-means choices
초기 중심점 선택하기
- random으로 K-point(초기 cluster center)들을 고른다
- 잔차를 최소화하기위해 greedy하게 고른다
distance measures
- 전통적으로는 Euclidean하거나 딴거 아무거나!
Optimization(최적화)
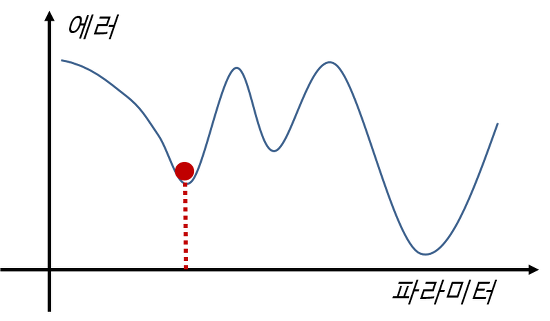
- local minimum으로 수렴하는 값 찾기
- restart를 여러번 수행할 수도!
cluster 개수는 어떻게 고를거야?
k가 너무 작으면 별개의 클러스터를 합치고, k가 너무 크면 하나의 클러스터가 여러개로 나뉜다
validation set을 둬서, 다른 개수의 클러스터를 시도해보고 성능을 비교한다
When building dictionaries, more clusters typically work better.(?뭔소리)
어떻게 cluster를 초기화할거야?
https://lovit.github.io/nlp/machine%20learning/2018/03/19/kmeans_initializer/
k-means의 학습 결과가 좋지 않은 경우는 initial points로 비슷한 점들이 여러 개 선택된 경우이다! 이 경우만 아니면 k-means는 빠른 수렴 속도와 안정적인 성능을 보여준다 그렇기 때문에 서로 거리가 먼 initial points를 선택하려는 연구들이 진행되었다 -> k-means++
- k-means++initialization

pros and cons
-
Pros
-conditional variance를 최소화하는 군집 center를 찾는다 -> data 분포를 표현하기 좋다
-간단하고 빠르다(느릴 수 있음:O for N)
-구현하기 쉽다 -
Cons
-k를 골라야한다
-이상치에 민감!
-local minima에 빠지기 쉽다! <-> global minimum을 찾기 어렵게 함
-모든 군집이 같은 파라미터를 가져야한다
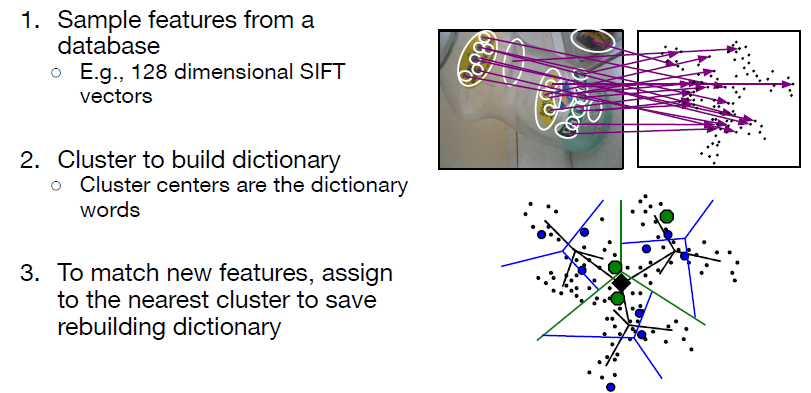
building Visual Dictionaries

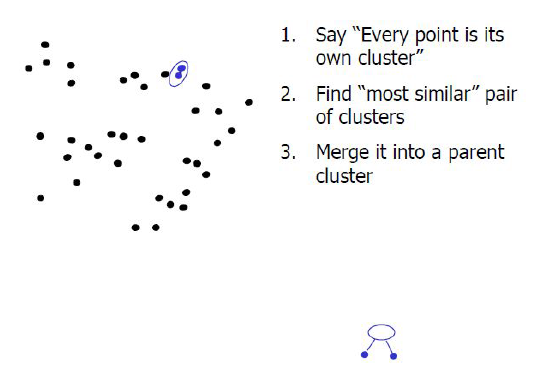
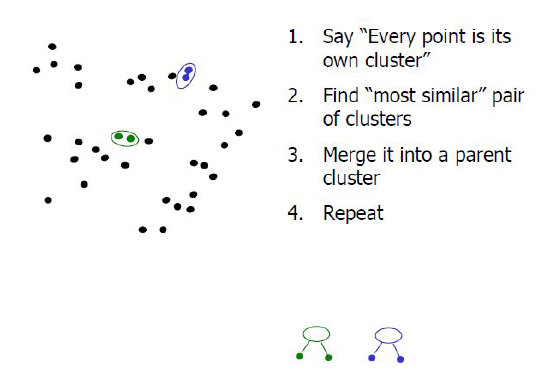
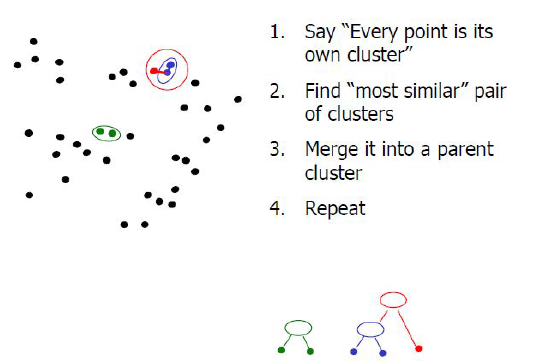
병함 군집(agglomerative cllustering)
시작할 때 각 포인트를 하나의 클러스터로 지정하고, 종료조건을 만족할 때까지 가장 비슷한 두 클러스터를 합친다.(종료조건 : 클러스터 갯수, 지정된 갯수의 클러스터가 남을 때까지 비슷한 클러스터를 합친다)
cluster 유사도를 어떻게 정의하는가?
-점들 사이의 평균 거리, maximum 거리, minimum 거리
-평균이나 medoid 사이의 거리
medoid?중앙자! 중앙 값
k-medoid:중앙값을 대표값으로 가져가기 때문에 절대오차를 기준으로 알고리즘이 진행된다
k-means: 평균을 대표값으로 가져가기 때문에 분산을 기준으로 알고리즘이 진행된다
k-medoid는 이상치의 영향을 덜받기 때문에 안정적, but 비용 높음
https://knuit-factory.blogspot.com/2017/08/k-medoid-algorismk.html
cluster는 얼마나 많은가?
-Clustering이 dendrogram을 생성한다(a tree)
-cluster 최대값 또는 결합사이의 거리를 기반으로 하는 Threshold
pros and cons
-
good
-구현하기 쉽고, 광범위한 적용
-adaptive shape를 가진다
-군집의 계층적 구조를 제공 -
Bad
-불균등한 cluster를 가질지 모름
-cluster,threshold의 수를 골라야한다
-의미있는 계층구조를 얻기위해 ultrametric을 사용해야한다.


Mean-Shift
-
clustering-based segmentation을 위한 다용도의 기술
-
non parametric density의 mode를 찾기
우선 density estimation이란?
관측된 데이터들의 분포로부터 원래 변수의 분포 특성을 추정하고자 하는 것
parametric density vs non parametric density
parametric 밀도추정은 pdf(probability density function)에 대한 모델을 정해놓고 데이터들로부터 모델의 파라미터만 추정하는 방식 but 모델이 미리 주어진다는 가정은 사치스러운 가정이 될 수 있다 그래서 어떠한 사정정보나 지식 없이 순수 관측 데이터만으로 확률 밀도함수를 추정해야하는데 이를 non-parametric density estimation이라 부름
non-parametric 밀도추정의 가장 간단한 형태가 바로 히스토그램, 관측된 데이터들로부터 히스토그램을 구한 후 구해진 히스토그램을 정규화하여 확률밀도함수로 사용하는 것
출처:https://darkpgmr.tistory.com/147
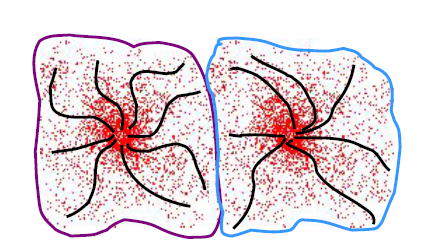
Attracion basin
- attraction basin: 모든 궤적이 동일한 모드로 이어지는 영역
- Cluster: mode의 attraction basin에 있는 모든 데이터 점들
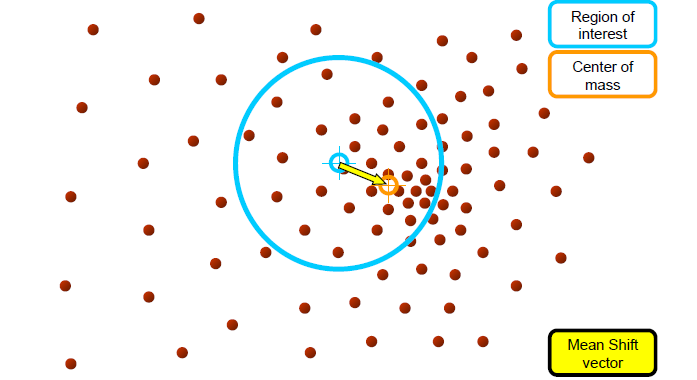
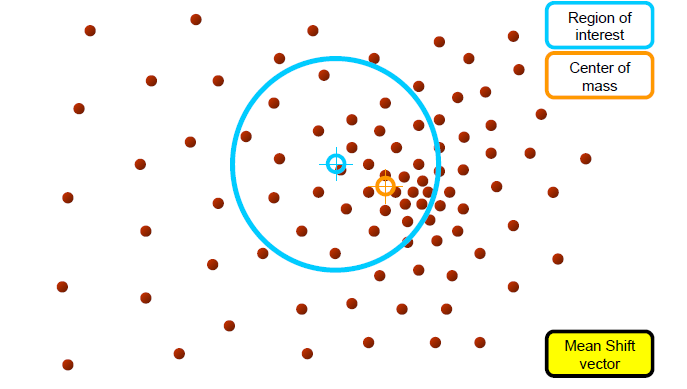
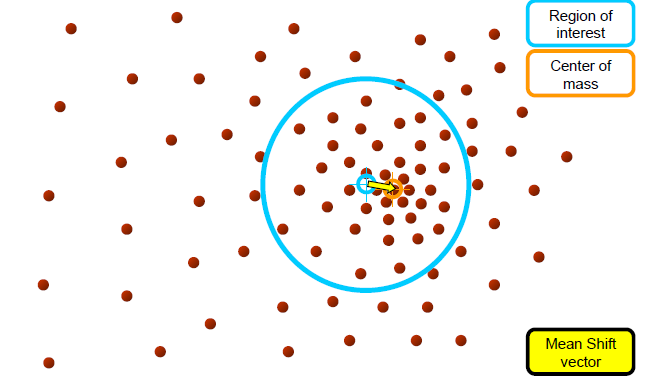
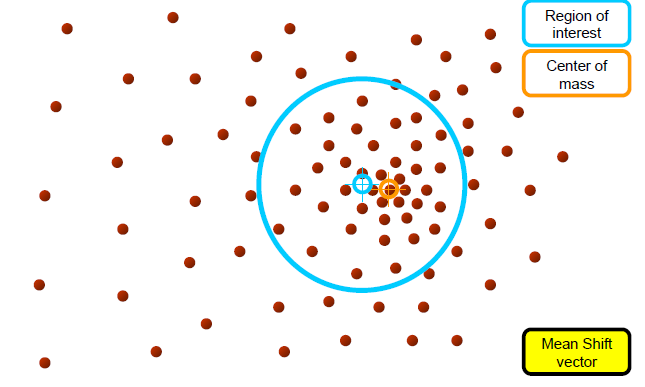
mean shift process
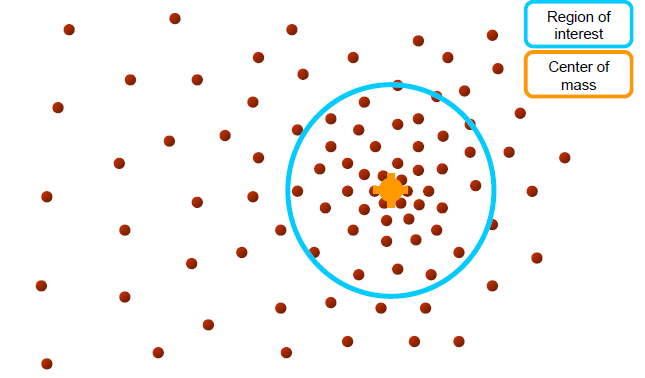
Kernel density estimation
이전 non parametric 밀도추정에서 히스토그램 방법은 bin의 경계에서 불연속성이 나타난다는 점, bin의 크기 및 시작 위치에 따라서 히스토그램이 달라진다는 점, 고차원 데이터에는 메모리 문제 등으로 사용하기 힘들다는 점 등의 문제점을 가짐
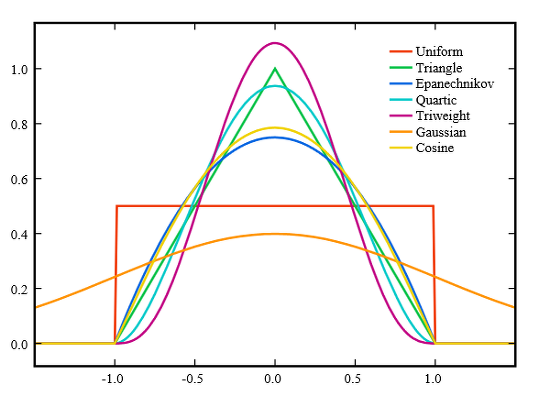
-> 개선한 방법: kernel function을 이용한 커널 밀도 추정 방법
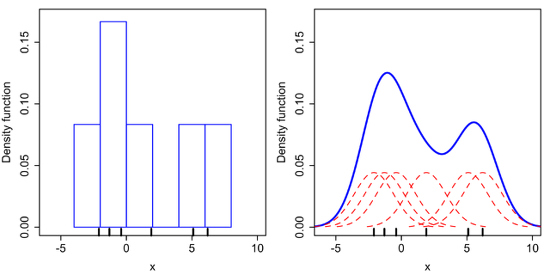

- 즉 KDE를 통해 얻은 확률밀도함수는 히스토그램 확률밀도 함수를 스무딩한 것으로도 볼 수 있다!
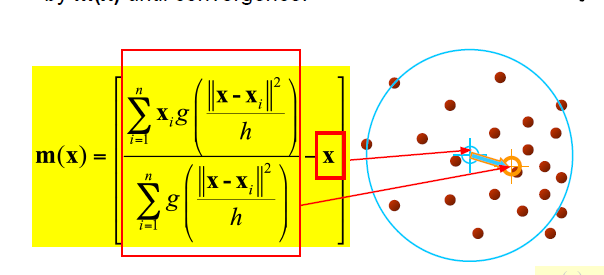
Computing the Mean shift
- Simple Mean Shift procedure:
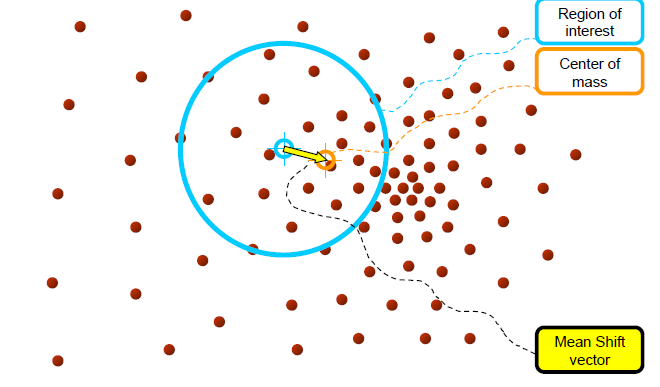
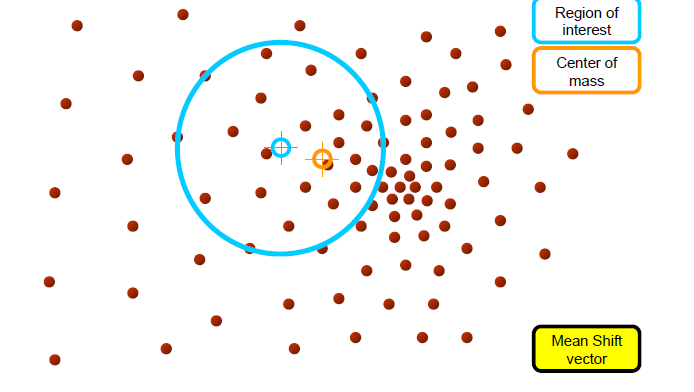
1.mean shift vector m(x)를 계산한다
- m(x)에 의해 kernel window가 수렴할때까지 반복한다
Mean shift clustering
- mean shift 알고리즘은 주어진 point set의 모드를 찾는다
- kernel과 bandwidth를 고른다
- 각 point에 대해:
a. wiondw의 중심을 해당 point에 맞춘다
b. search window에서 데이터의 평균을 계산한다
c. search window를 새로운 평균 위치에서 중심을 맞춘다
d. b,c를 수렴할 때까지 반복 - 인접 모드로 이어지는 점을 동일한 군집에 할당한다
Segmentation by Mean Shift
- 각 픽셀에 대해 feature를 계산한다 (color, gradients, texture)
- kernel size를 feature와 position에 맞게 정한다
- 각 픽셀 위치에 대해 window를 초기화한다
- mean shift를 각 window가 수렴할 때까지 수행한다
- window들을 합친다
Mean shift 장단점
-
Pros
결과가 좋다
영역 형태와 개수에 대해 유연함
이상치있어도 괜찮다 -
Cons
kernel size를 사전에 골라야한다
고차원 feature에 대해서는 적합하지 않다 -
When to use it
Over segmentation
Multiple segmentations
Tracking,clustering, filtering application들
Spectral clustering
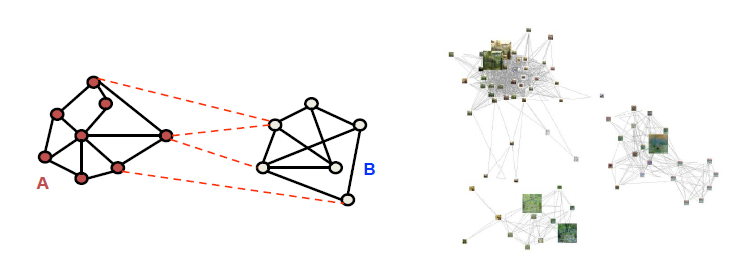
Graph-based 클러스터링 모델은 각 데이터의 점들과 다른 점 사이에 선을 긋고 두 데이터의 유사도에 따라 가중치를 부여
- 다음과 같이 graph-based 방식이고, edge cost 방식
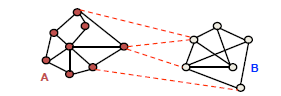
- neighborhodd-ness or local smoothness
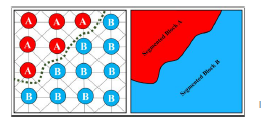
어느 알고리즘을 쓸까?
- Quantization/Summarization : K-means
원본 데이터의 분산을 보존하기 위해
새로운 point를 클러스터에 쉽게 할당 가능

- Image segmentation: agglomerative clustering
거리 측정에 더 유연함(e.g.boundary prediction을 기반으로 할 수 있당)
특정 데이터에 더 잘 적용
계층화가 유용할 수 있음
요약
K-means clustering-> summarization, building dictionaries of patches, general clustering

Agglomerative clustering -> segmenation, general clustering
Spectral clustering -> 관련성 결정, summarization, segmentation