
(1) 관계대수
관계대수와 JOIN
- 관계대수 :
- 일반집합 연산자 : 합집합(union), 교집합(intersection), 차집합(difference)
관계대수는 테이블에서 튜플을 검색하기 위해 필요한 연산자들을 모은 것으로서 테이블(릴레이션)을 처리하는 연산의 집합이다. 모두 8개의 연산자로 구성되며, 이중 4개는 집합 연산자이고, 나머지 4개는 관계연산자 인데, 집합 연산자는 수학에서 사용되는 일반적인 집합 연산자로 , 합집합(union), 교집합(Intersection), 차집합(Difference), 카테시언 곱(Cartesian product)으로 구성된다. 집합 연산자는 테이블에만 적용 할 수 있는 검색 연산자로서 Selection, Projection, Join, Division으로 구성된다.
- 집합 연산자
- 합집합(union)
- 교집합(Intersection)
- 차집합(Difference)
- 카테시언 곱(Cartesian product)
- 관계 연산자
- Selection
- Projection
- Join
- Division
(2) 집합 연산자
합집합(union)
집합 A의 원소와 집합B의 원소를 모두 합한 전체를 A와B의 합집합이라 하며 A∪B 또는 A+B로 나타낸다. 즉, 원소 ⓧ가 A∪B에 속한다는 것은 ⓧ가 A,B 중의 적어도 한쪽에 속한다는 것이다.
교집합(Intersection)
집합 A의 와 집합 B의 양쪽에 공통으로 속해 있는 원소 전체의 집합을 A와 B의 교집합이라 하고, A∩B 로 나타낸다.
차집합(Difference)
집합 A와 집합 B를 생각할 때, 집합 A에 속하고 집합 B에는 속하지 않는 원소 집합을 집합 A에 대한 집합 B의 차집합이라 하고, A-B로 표시한다.
카테시언 곱(Cartesian product)
집합 A와 집합 B를 곱한 집합이고 A×B로 표시한다.
집합 A = {1,2,3,4}이 있고 집합 B = {3,4,5,6} 이 있을 때
합집합 A+B = {1,2,3,4,5,6}
교집합 A∩B = {3,4}
차집합 A-B = {1,2,3}
곱집합 A×B = {(1,3),(1,4),(1,5),(1,6),(2,3),(2,4),(2,5),(2,6),(3,3),(3,4),(3,5),(3,6),(4,3),(4,4) ,(4,5),(4,6)}이 되며, 이제 우리가 알고 있는 DATABASE의 TABLE과 T-SQL로 표현을 하여 보자.

A반 번호와 B반 번호를 모두 추출하여라.
Select
From (
Select From [A반번호]
Union
Select * From [B반번호]
) As A
A반 번호에도 있고 B반 번호에도 존재하는 값을 추출하여라.
SELECT *
FROM [A반번호] Inner Join [B반번호]
ON [A반번호].[A반번호] = [B반번호].[B반번호]
A반 번호에는 있고 B반 번호에는 없는 것을 추출하여라.
SELECT *
FROM [A반번호] AS A
WHERE (SELECT TOP 1 [B반번호] FROM [B반번호] AS B WHERE B.[B반번호] = A.[A반번호])IS NULL
A반 번호 테이블의 모든 행들과 B반 번호 의 모든 행을 조인 하여라
SELECT *
FROM [A반번호] AS A cross join [B반번호] AS B
(3) 관계 연산자
Selection
Selection은 relational의 어떤 선택조건을 만족하는 Tuple들을 선택하는 것이다. 여기서 relational은 우리가 알고 있는 Table이라고 생각하면 되고, Tuple은 Table의 row라고 생각하면 된다. Selection의 기호는 σ(시그마) 이며, 표현 식은 σ(조건)R 이렇게 된다.
Projection
Projection은 relational에서 Attribute 리스트에 명시된 Attribute만 선택하는 것이다. Projection의 기호는 π (파이) 이며, 표현 식은 π (속성리스트)R 이다.
Join
Join은 두 relational으로부터 관련 있는 Tuple들을 결합하여 하나의 새로운 Tuple로 생성하는 것이다. 기호는 ▷◁ 이며. 표현 식은 ▷◁<속성=속성>S 이다.
Division
Division은 한 relational에서 다른 relational의 Attribute를 제외한 속성만 선택하는 것이다. 기호는 % 이며, 표현 식은 R1(속성%속성)R2 이다.
User Table

<표 1-1>
위 <표 1-1> 기준으로 σ(Base Level<40)User Table 이라고 하였을 때, Base Level이 40보다 작은 Tuple만 선택하면 되는 것이다.

다시 <표 1-1>을 기준으로 π (Nick Name, Job Level)User Table 이라고 가정을 하였을 때, User Table에서 Nick Name와 Job Level 만을 선택하면 되는 것이다.

Join을 예로 들기 위해 <표 1-2>를 만들었다.
Billing Table

<표 1-2>
<표 1-1>과 <표 1-2>를 기준으로 Billing Table▷◁User Table 이라고 하면, Billing Table과 User Table의 공통된 부분인 Nick Name을 이용하여 Nick Name 중심으로 새로운 relational을 생성 하면 되는 것이다.

Division 을 설명하기 위해 <표 2-1>와 <표 2-2>를 만들었다.
구매 Table
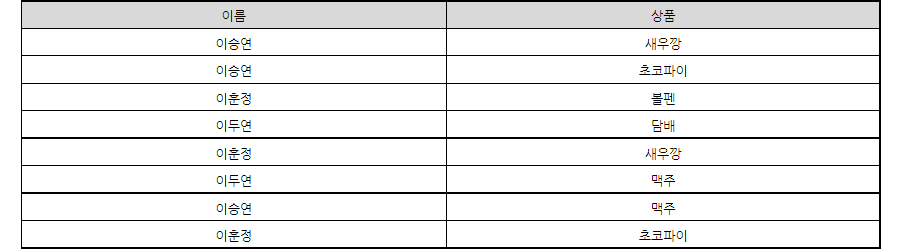
<표 2-1>
상품 Table

<표 2-2>
두 Table을 기준으로 구매 Table(상품 % 상품)상품 Table을 하면, 피제수 Table에서 상품 column이 ‘새우깡, 초코파이’인 것만 선택해 주면 된다.

이와 같이 새우깡, 초코파이를 구매한 사람들이 선택이 되며, 중복을 제거하면 이승연, 이훈정만 선택되게 된다. 이것이 Division 이다. 다시 한번 Division의 정의를 내려 보자면, 피제수 Table(나누어지는 Table)을 제수 Table(나누는 테이블)로 나누어 몫 Table을 구하는데 사용하는 것을 말한다.
