
예시

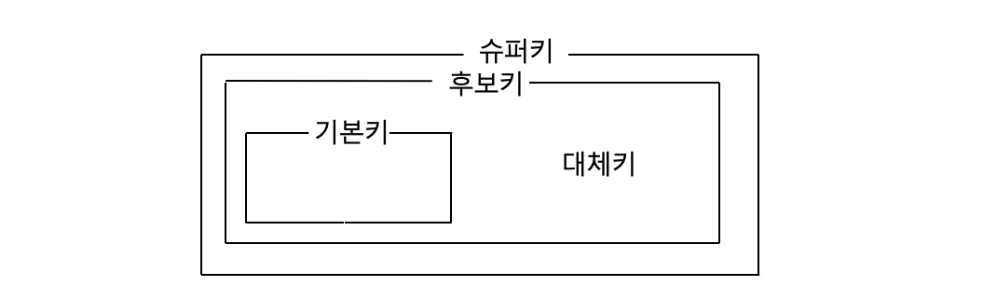
(1) 슈퍼키 (Super Key)
-
각 행을 유일하게 식별할 수 있는 속성들의 집합이다.
-
서로 구분만 할 수 있다면 '슈퍼키'라고 할 수 있다.
-
학번 : 학번만 가지고 학생들을 구분할 수 있으므로 슈퍼키가 맞다.
-
주민등록번호 : 주민등록번호만 가지고도 학생들을 구분할 수 있으므로 슈퍼키가 맞다.
-
이름 : 이름은 서로 같을 수 있기 때문에 구분하지 못하므로 슈퍼키가 아니다.
-
생년월일 : 생년월일 역시 서로 같을 수 있기 때문에 슈퍼키가 아니다.
-
이름, 생년월일 : 이름과 생년월일의 조합으로 학생들을 구분할 수 있으므로 슈퍼키가 맞다.
-
이 외) [학번, 주민등록번호], [학번, 이름], [학번, 생년월일], [주민등록번호, 이름], [주민등록번호, 생년월일], [학번, 주민등록번호, 이름], [학번, 주민등록번호, 생년월일], [학번, 이름, 생년월일], [주민등록번호, 이름, 생년월일], [학번, 주민등록번호, 이름, 생년월일]
-
(O) : 구분할 수 있는 속성이 포함되기만 하면 각 행을 식별할 수 있으므로 슈퍼기라고 할 수 있다.
(2) 후보키 (Candidate Key)
-
각 행을 유일하게 식별할 수 있는 "최소한의" 속성들의 집합이다.
-
서로 구분할 수 있으면서 불필요한 속성들이 없어야 '후보키'라고 할 수 있다.
-
이 외) [학번, 주민등록번호], [학번, 이름], [학번, 생년월일], [주민등록번호, 이름], [주민등록번호, 생년월일], [학번, 주민등록번호, 이름], [학번, 주민등록번호, 생년월일], [학번, 이름, 생년월일], [주민등록번호, 이름, 생년월일], [학번, 주민등록번호, 이름, 생년월일]
(X) : 마찬가지로 [학번] 하나 또는 [주민등록번호] 하나만 가지고도 구분할 수 있는데 불필요한 속성들이 붙어있으므로 후보키가 아니다.
(3) 기본키 (Primary Key)
- 최소성을 가진다.
- 후보키들 중에서 하나를 메인으로 선택한 키다.
- 위의 테이블에서는 [학번]을 메인으로 선택했으므로 [학번]이 기본키가 된다.
- MySQL의 'PRIMARY KEY' 를 떠올리시면 된다.
- 비유: 명문대 합격생들 중에서 대표로 선정된 학생이 기본키라고 할 수 있다.
(4) 대체키 (Alternate Key)
- 기본키를 제외한 나머지 후보키들을 의미한다.
- 위의 테이블에서는 [학번]을 메인으로 선택했으므로 [학번] 이 외에 [주민등록번호]가 대체키가 된다.
- MySQL의 'UNIQUE' 를 떠올리시면 된다.
- 비유: 명문대 합격생들 중 대표로 선정된 학생 이 외의 나머지 학생들이 대체키라고 할 수 있다.
(5) 외래키 (Foreign Key)
- 한 테이블이 다른 테이블의 기본키를 참조해서 테이블 간의 관계를 만드는 것을 의미한다.
- 어떤 테이블의 식별자를 끌어와서 그것에 대한 정보를 또 추가한다고 이해하시면 된다.
- MySQL의 'FOREIGN KEY' 를 떠올리시면 된다.
- 취미 테이블의 [학번]은 학생 테이블의 [학번]을 참조해서 학생마다 취미가 무엇인지를 나타내고 있으므로 외래키이다.
(6) 유니크키(Unique Key, Unique Index)
-값 중복을 허용하지 않는다.
-NULL값을 허용한다.
-테이블에서 여러 개 생성 가능하다.
(7) 최소성과 유일성
- 유일성 : 하나의 키값으로 튜플을 유일하게 식별할 수 있는 성질
여러개의 튜플이 존재할 때 각각의 튜플을 서로 구분할 수 있어야 합니다. 한마디로 각각의 튜플을 유일해야 한다는 의미입니다. 예를 들어 (주민번호, 나이, 사는곳, 혈액형)이라는 속성이 있을 때 나이, 사는곳, 혈액형을 충분히 중복될 수 있는 속성입니다. 하지만 주민번호는 모두 다르기 때문에 각각의 튜플을 중복되는 속성 값이 존재할 수는 있지만 주민번호는 절대 중복할 수 없습니다. 이렇게 각각의 튜플을 구분할 수 있는 성질을 유일성이라고 합니다.
- 최소성 : 키를 구성하는 속성들 중 꼭 필요한 최소한의 속성들로만 키를 구성하는 성질
- 사원번호(유일성) + 주민등록번호(유일성) = 최소성 : 공간낭비이다.
- 어차피 학번, 주민번호, 학번... 으로 유일한 튜플(ROW)을 구분할 수 있는데 왜 주민등록번호를 넣느냐? > 공간낭비를 하므로 최소성 성립이 안된다.
쉽게 설명하면 키를 구성하는 속성들이 진짜 각 튜플을 구분하는데 꼭 필요한 속성들로만 구성되어 있냐?를 의미합니다. 굳이 없어도 될 속성들을 넣지 말자는 말입니다. 예를 들어 다음과 같은 키(주민번호, 이름, 나이)가 있다면, 물론 현재의 키는 각 튜플을 구분할 수 있습니다. 주민번호, 이름, 나이가 모두 같은 사람을 없을 테니깐요. 근데 생각해보면 이름, 나이가를 빼고도 주민번호만으로 각 튜플을 유일하게 식별할 수 있습니다. 이때 이름, 나이를 빼면 해당 키는 최소성을 만족합니다.
