
1. SQL JOINS
(1) SQL JOINS
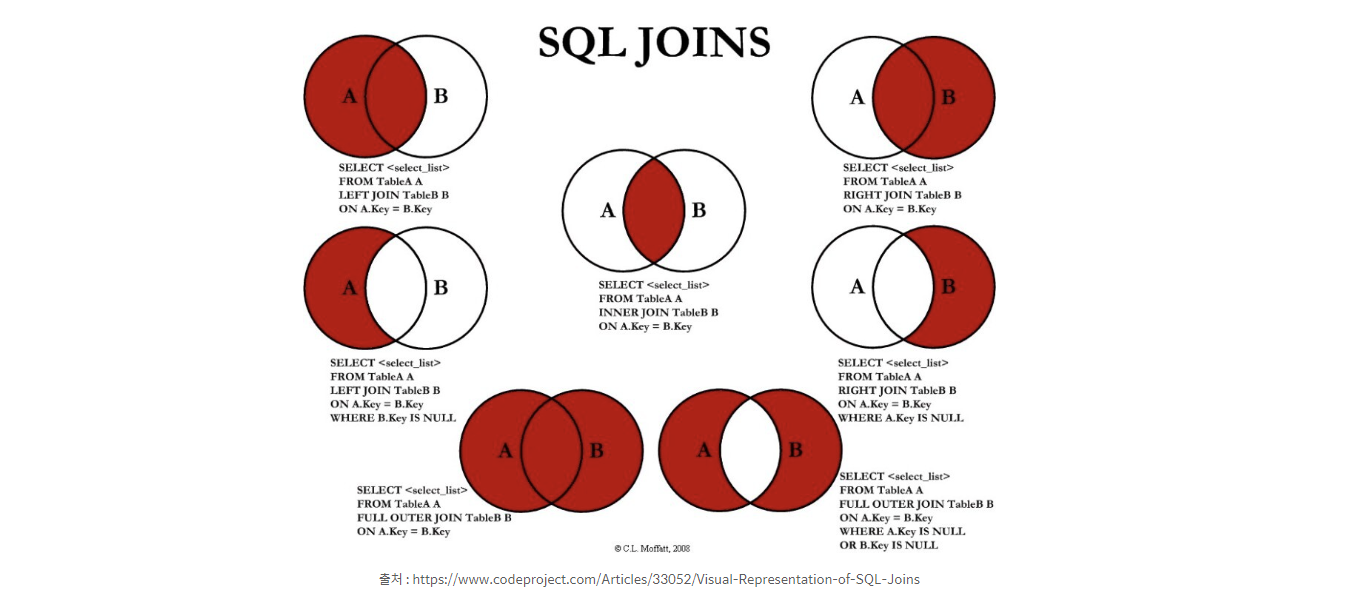
빨간색 영역 = 튜플
- 순수관계연산자 : select(where) , project(컬럼찾기), join divide 집합을 (xy로나누면) xy를 모두가지고있는 컬럼(값) 찾는다
- JOIN : 이미지
- SELECT : 일정 튜플만 가져오는 행위 (SQL문 작성할 때 사용한 WHERE절과 같은 의미, 조건을 만족하는 일정 튜플만 가져온다.)
- PROJECT : 특정 컬럼만 가져오는 행위 (SQL문 작성할 때 사용한 SELECT와 같은 의미)
- DIVISION : X ⊃ Y인 2개의 릴레이션에서 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
(2) 정리
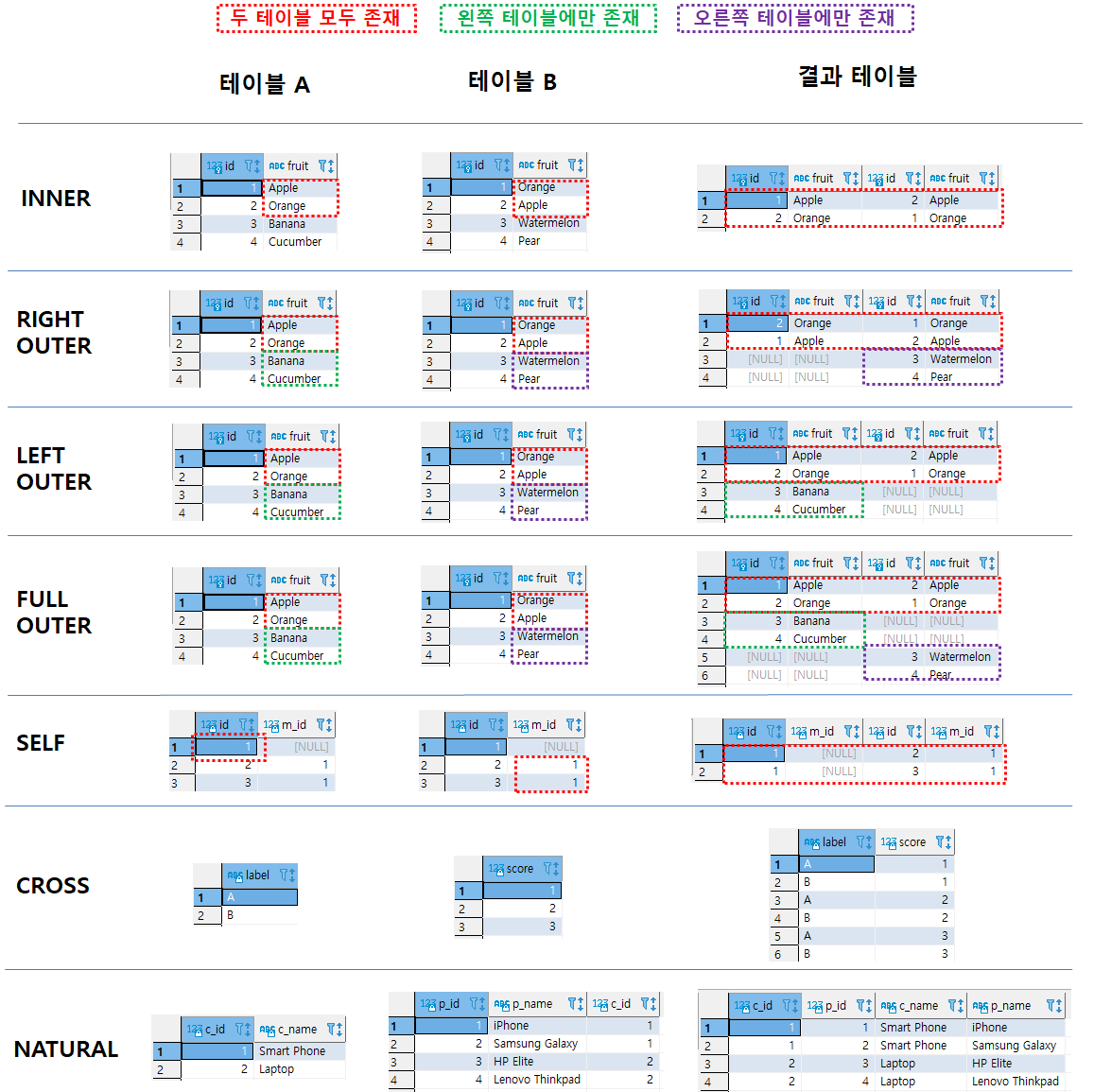
2. JOIN
JOIN : 여러 개의 테이블을 연결하여 데이터를 검색하는 것으로 일반적으로 외래키를 조인 속성으로 이용하며 계산식에 많이 사용한다. 특정 컬럼의 연관성을 기준으로 출력한다. (아무런 관련도 없이 출력하기는 어렵다 > 외래키 기준으로 서로 관계가 있다면 테이블끼리 같은 컬럼 기준으로 붙일 수 있다.)
2. INNER JOIN
JOIN은 두 개의 테이블의 관계에서 공통점을 기준으로 정보를 출력하는 것.
3. WHERE절 같이 사용하기
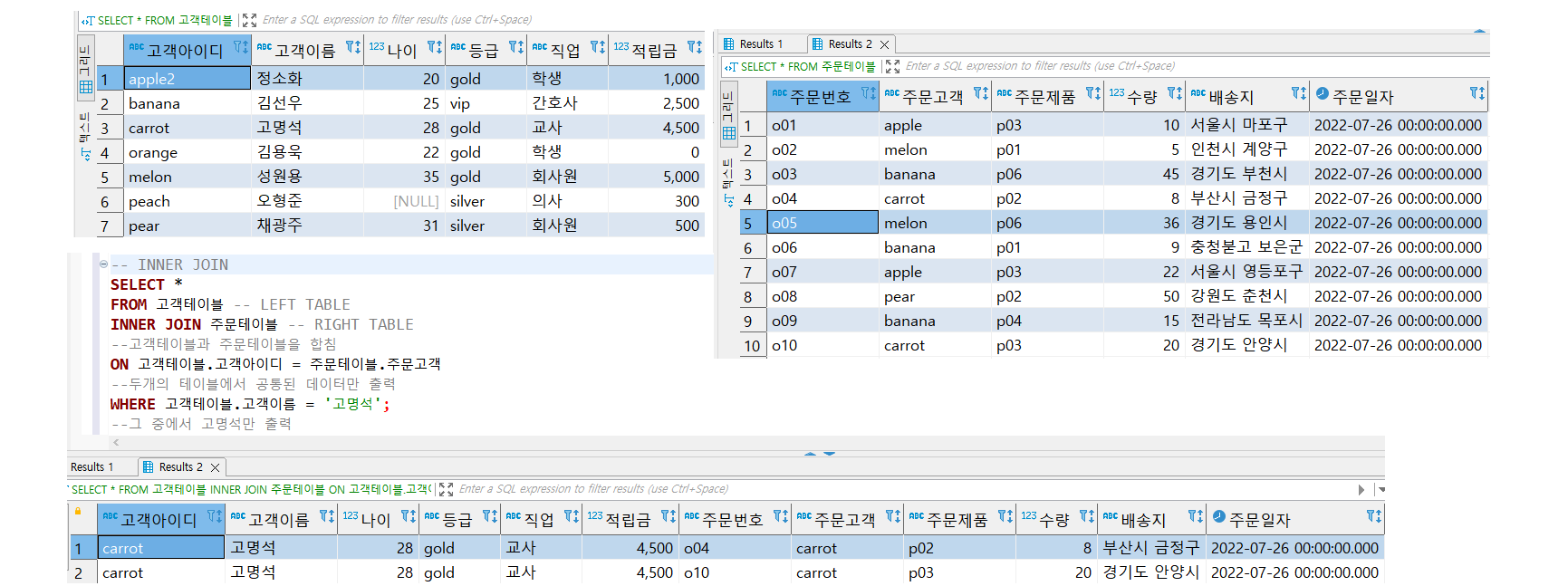
전부 공통점이 있기 때문에 출력 > WHERE절로 '고명석'만 출력시 공통된 김선우의 튜플이 출력된다.
4. RIGHT OUTER JOIN
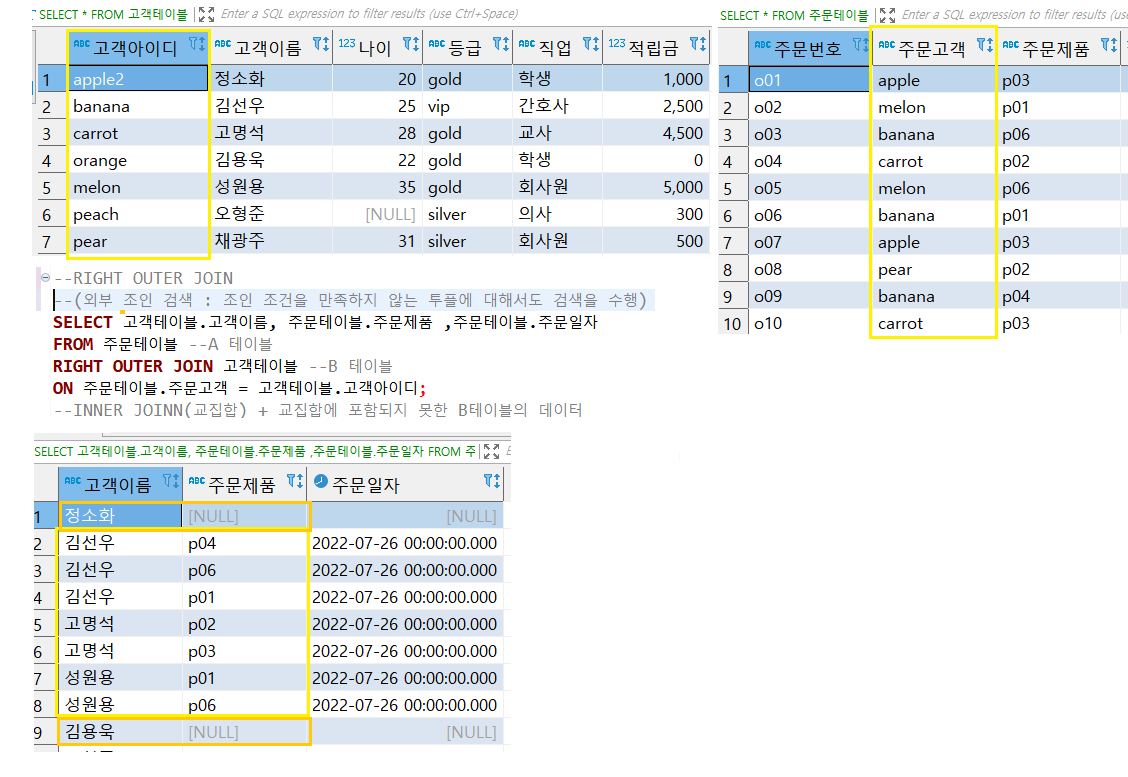
5. LIGHT OUTER JOIN

(5)의 내용과 반대
6. FULL OUTER JOIN
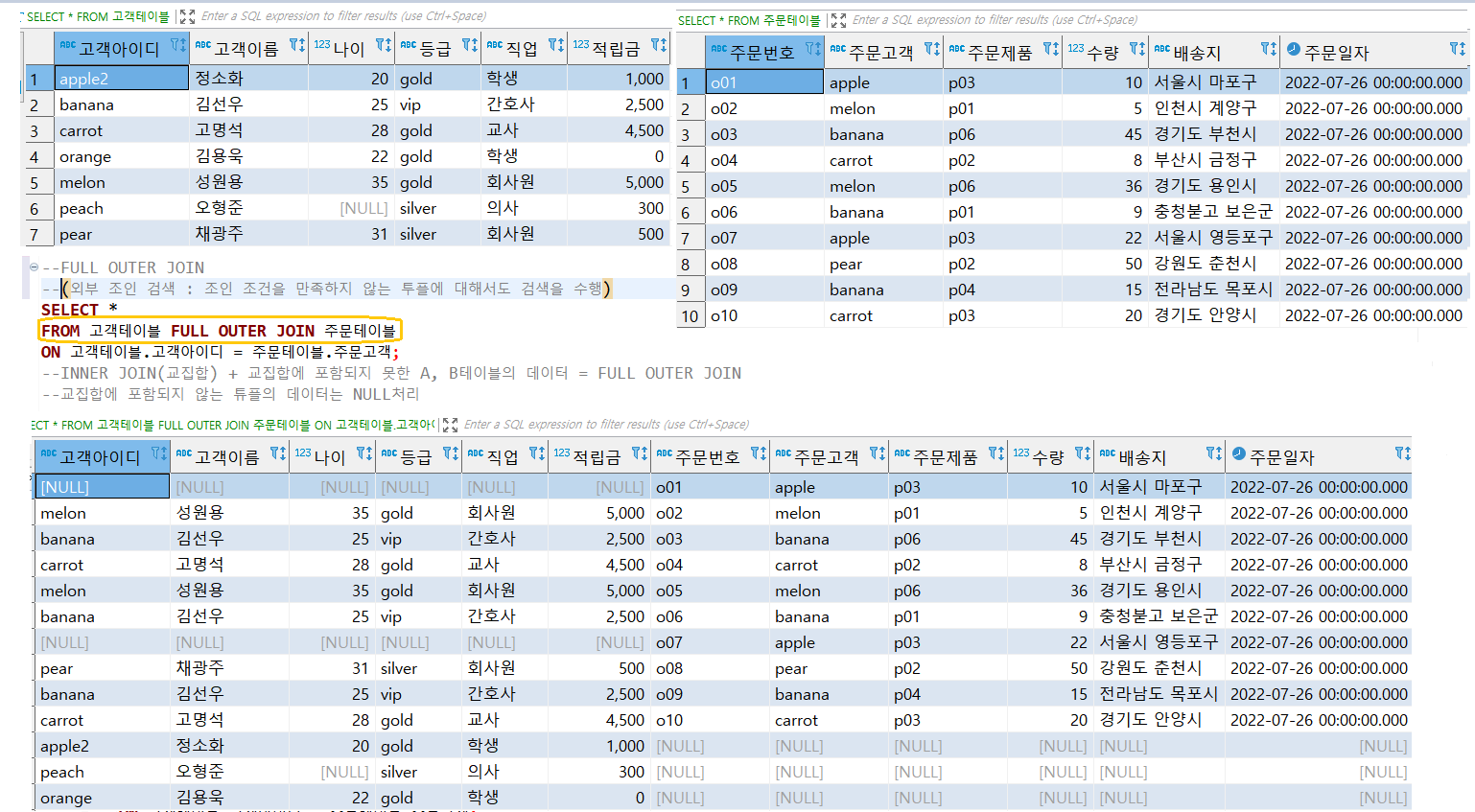
(7) 하나씩 실행해보기
CREATE TABLE basket_a (
id VARCHAR(20) NOT NULL,
fruit VARCHAR(10) NOT NULL,
id_category VARCHAR(20)
);
DROP TABLE basket_a;
---------------------------------------------------------
CREATE TABLE basket_b (
id VARCHAR(20) NOT NULL,
fruit VARCHAR(10) NOT NULL,
id_category VARCHAR(20)
);
DROP TABLE basket_b;
---------------------------------------------------------
CREATE TABLE basket_c (
id VARCHAR(20) NOT NULL,
recipe VARCHAR(10) NOT NULL
);
DROP TABLE basket_c;
---------------------------------------------------------
INSERT INTO basket_a VALUES ('1', 'Apple', NULL);
INSERT INTO basket_a VALUES ('2', 'Orange', NULL);
INSERT INTO basket_a VALUES ('3', 'Banana', '1');
INSERT INTO basket_a VALUES ('4', 'Cucumber', '1');
---------------------------------------------------------
INSERT INTO basket_b VALUES ('1', 'Apple', NULL);
INSERT INTO basket_b VALUES ('2', 'Orange', NULL);
INSERT INTO basket_b VALUES ('3', 'Watermelon', '1');
INSERT INTO basket_b VALUES ('4', 'Pear', '1');
---------------------------------------------------------
INSERT INTO basket_c VALUES ('1', '쥬스');
INSERT INTO basket_c VALUES ('2', '생과일');
---------------------------------------------------------
SELECT * FROM basket_a;
SELECT * FROM basket_b;
SELECT * FROM basket_c;
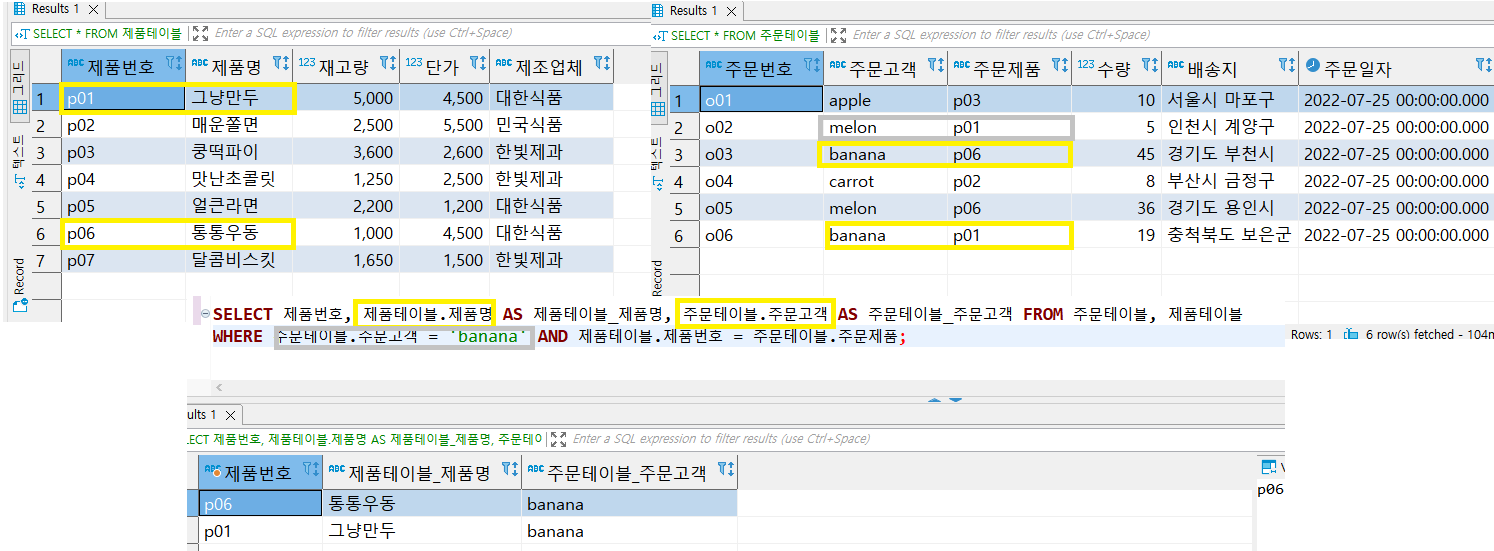
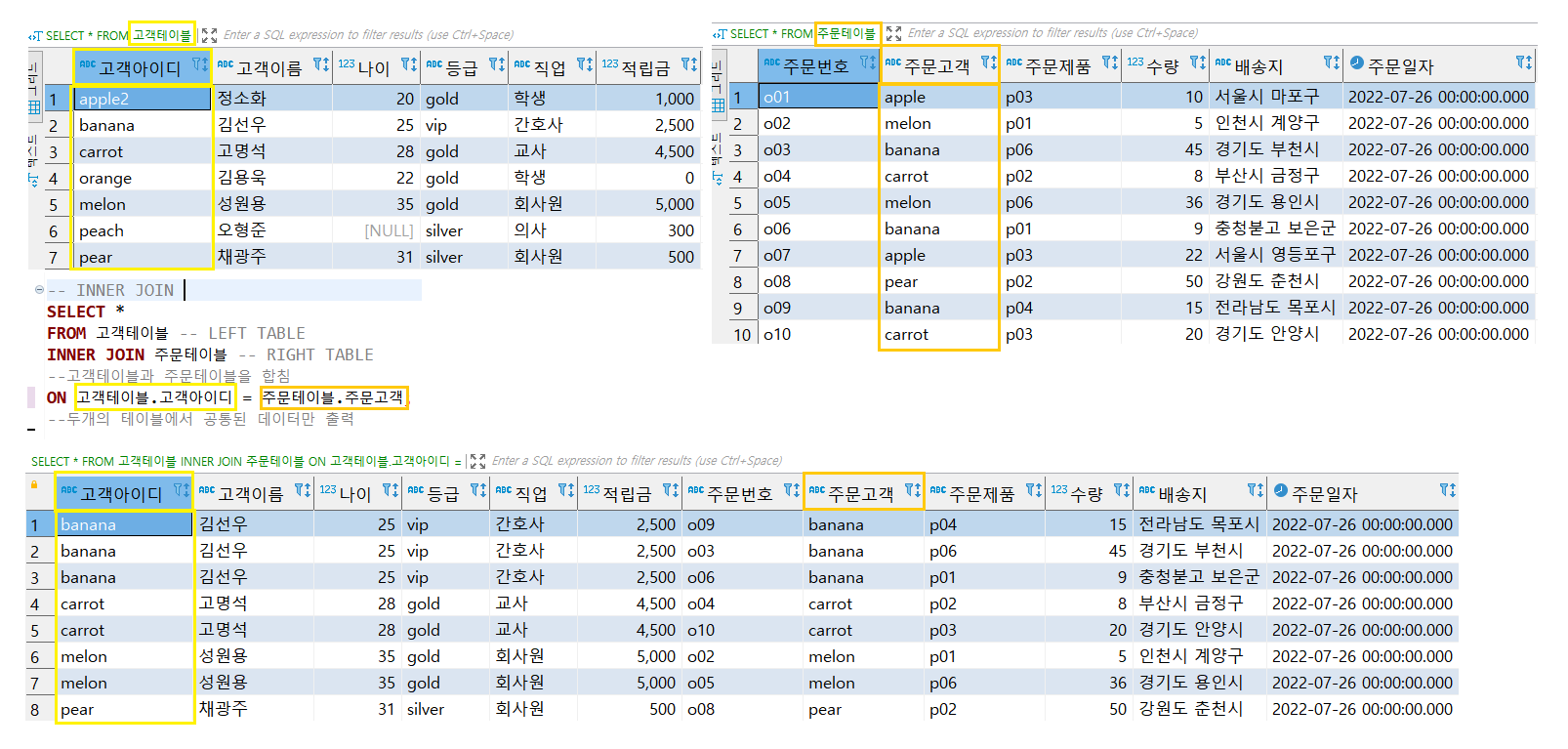
--INNER JOIN (교집합)
SELECT * FROM basket_a ba --별명 ba로 짓는다.
INNER JOIN basket_b bb --basket_a와 JOIN할 테이블 명
ON ba.fruit = bb.fruit; --JOIN을 엮을 기준(조건)
--basket_a의 fruit컬럼의 데이터와 basket_b의 fruit컬럼의 데이터가 같은 튜플(row)를 찾아라
---------------------------------------------------------
--LEFT OUTER JOIN (INNER JOIN + 왼쪽 테이블의 나머지 튜플(row))
SELECT * FROM basket_a ba
LEFT OUTER JOIN basket_b bb
ON ba.fruit = bb.fruit;
---------------------------------------------------------
--FULL OUTER JOIN
--INNER JOIN 튜플(row) + 왼쪽 테이블의 나머지 튜플(row) 더한 후에 오른쪽 테이블의 나머지 튜플(row)
SELECT * FROM basket_a ba
FULL OUTER JOIN basket_b bb
ON ba.fruit = bb.fruit;
---------------------------------------------------------
SELECT * FROM basket_a ba
INNER JOIN basket_a bb
ON ba.id = bb.id_category;
--SELF JOIN : 자기 자신의 컬럼 중 동일한 값을 가진 컬럼을 매칭해서 조회한다.
SELECT ba.id, ba.id_category, bb.id, bb.id_category
FROM basket_a ba
INNER JOIN basket_a bb
ON ba.id = bb.id_category;
---------------------------------------------------------
--CROSS JOIN : 튜플을 곱한다 (뻥튀기 = N*N),
--a테이블의 각 튜플마다 b테이블 각 튜플을 연결해서 출력한다.
SELECT * FROM basket_a ba
CROSS JOIN basket_b bb;
---------------------------------------------------------
--NATURAL JOIN : 튜플을 늘린다
--(쓰는 이유는 하나의 튜플에 여러 컬럼 데이터를 첨가하기 위해서 사용하지만 사용은 비추한다.)
SELECT id, fruit, id_category, recipe
FROM basket_a NATURAL JOIN basket_c;
---------------------------------------------------------일반 JOIN
- Fetch JOIN과 달리 연관 Entity에 JOIN을 걸어도 실제 쿼리에서 SELETE하는 Entity는 오직 JPQL에서 조회하는
주체가 되는 Entity만 조회하여 영속화
조회의 주체가 되는 Entity만 SELETE해서 영속화하기 때문에 데이터는 필요하지 않지만 연관 Entity가 검색조건에는 필요한 경우에 주로 사용됨
Fetch JOIN
- 조회의 주체가 되는 Entity 이외에 Fetch JOIN이 걸린 연관 Entity도 함께 SELETE 하여 모두 영속화
Fetch JOIN이 걸린 Entity 모두 영속화하기 때문에 FetchType이 Lazz인 Entity를 참조하더라도 이미 영속성 컨텍스트에 들어있기 때문에 따로 쿼리가 실행되지 않은 채로 N+1 문제가 해결된다.
