1. 부속 질의문과 상위 질의문
(1) 기본 사용방법
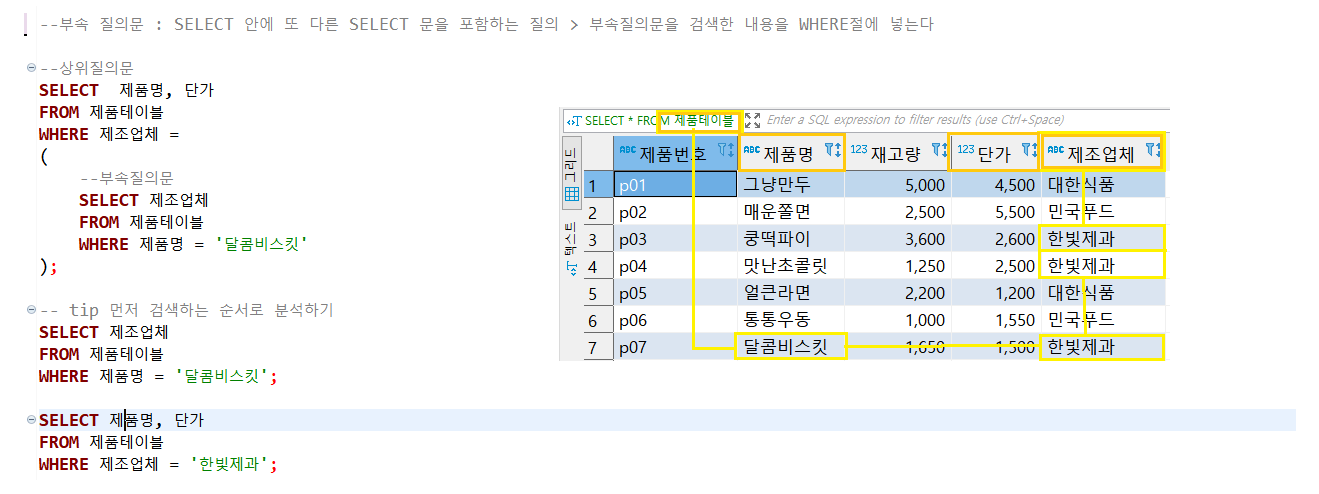
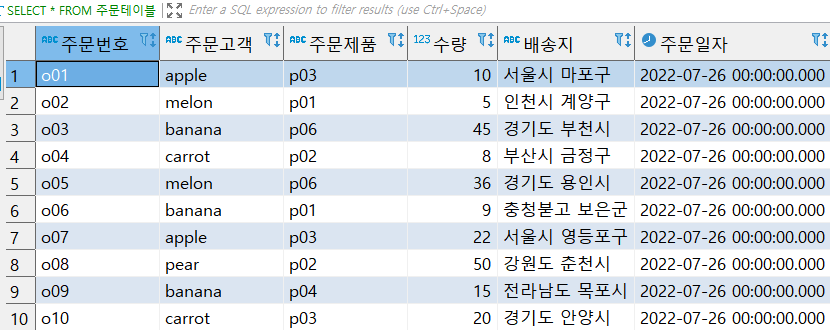
- 부속 질의문의 조건 : 제품명의 데이터가 달콤비스킷인 것만 출력
- 상위 질의문 조건 : 제조업체 = 부속 질의문이다 (부속 질의문은 현재 제품명 출력시 달콤비스킷만 출력이 가능함.)
상위 질의문의 제조업체를 출력하였을 때, 부속 질의문의 조건으로 인하여 제조업체 '한빛제과'만 출력 가능.
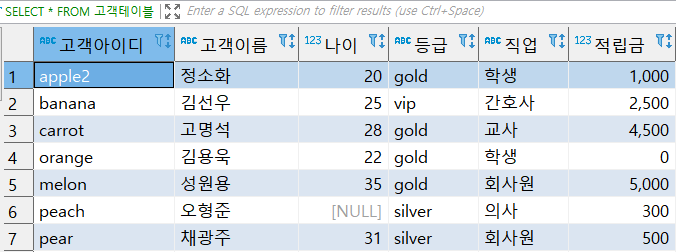
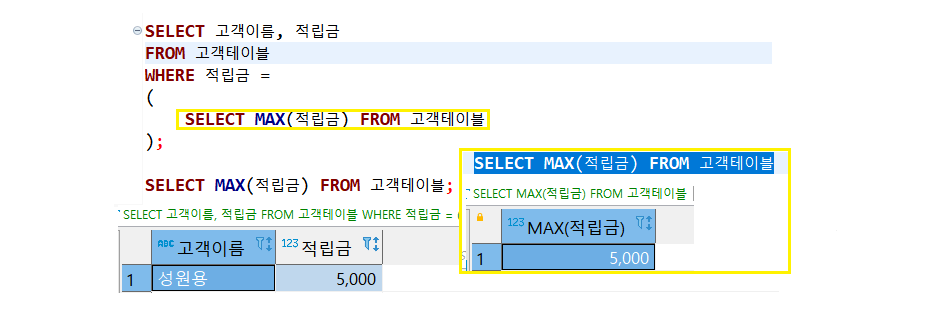
(2) 집계함수 사용방법
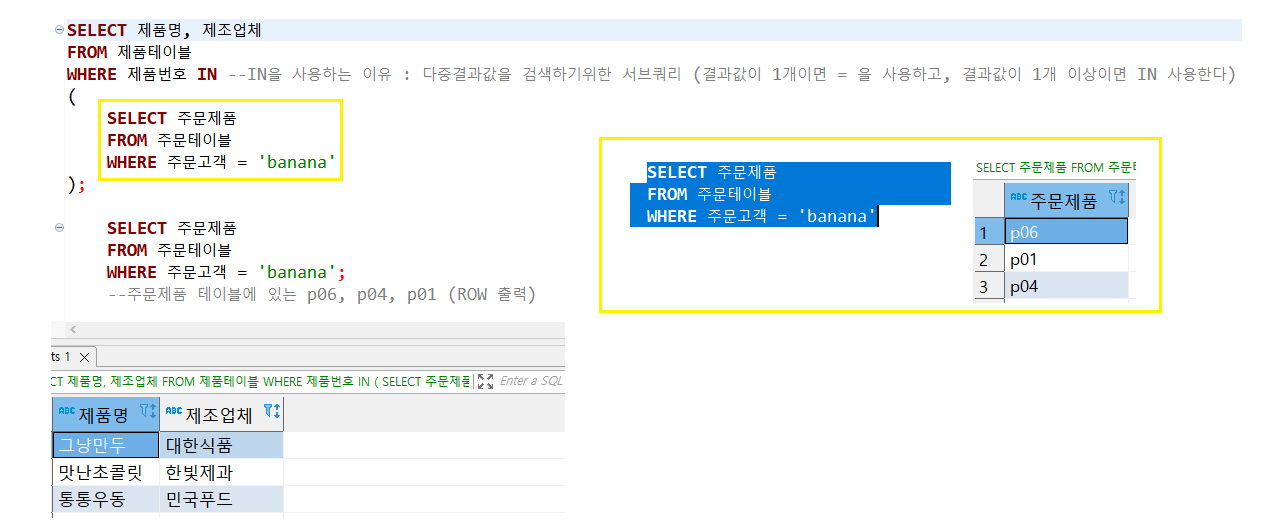
(3) IN 사용방법 (다중결과)
2. 테이블 & 컬럼 전체조회 : TABS, COLS
테이블의 모든 정보는 어딘가에 정리되어있다.
-
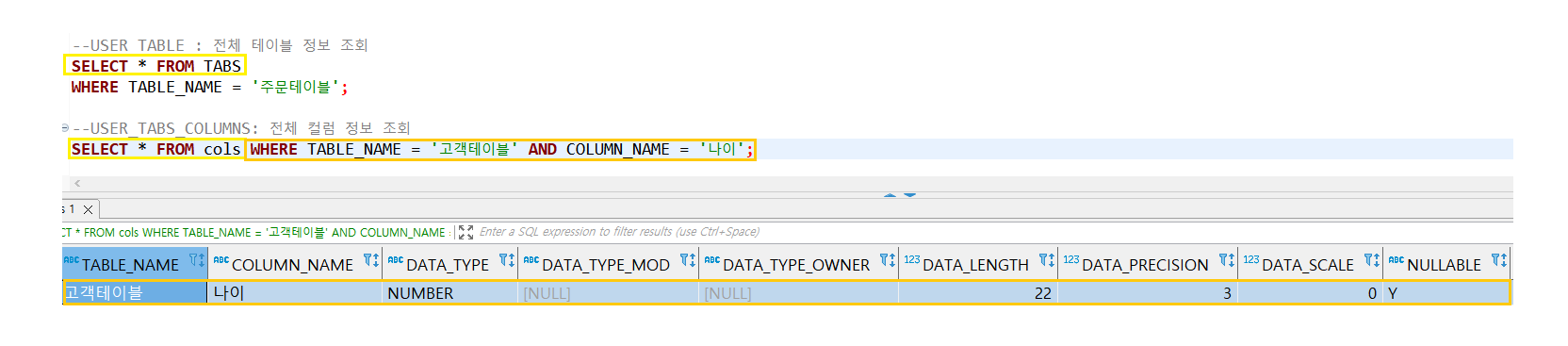
스키마 or 메타데이터 : TABLE의 모든 데이터(정의된 데이터 한정)가 정리되어 있는 것.
- 스키마를 저장하는 테이블도 있다. -
관계형 데이터베이스(의 종류 : 오라클, mysql, mssql, sqlite...)는 테이블로 저장된다.
-
TABLESPACE : 오라클에만 존재한다. 계정마다 TABLESPACE가 있고 TABLESPACE에 속한 테이블들이 있다.
3. INDEX OPTION
- INDEX OPTION : 특정 컬럼의 조회 속도를 높이기 위해 사용한다.
- 단, 공간적인 부분(테이블)과 절차적인 부분(튜플, insert할 때 마다 index가 저장하기 때문)에 저장공간을 많이 차지해서 비용이 발생하기 때문에 적절하게 사용해야한다.
- CREATE INDEX [INDEX이름] ON [테이블명][컬럼명] 작성
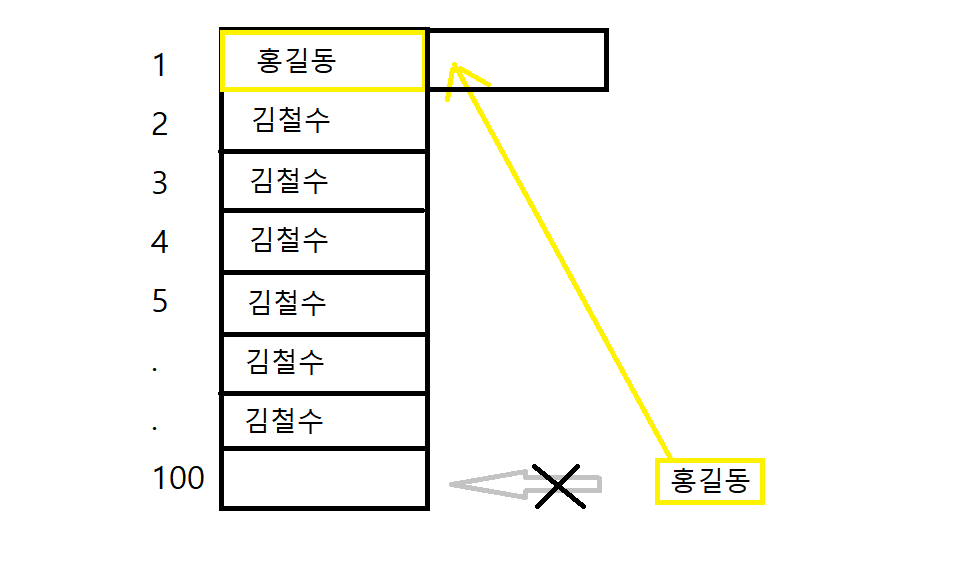
- 예시로 INDEX를 사용하기 전에는 고객테이블의 나이를 찾을 때 고객테이블을 뭉텅이로 가져와서 하나하나 찾았지만, INDEX를 사용하고나선 특정 컬럼마다 번호(실제론 번호가 아니라 아스키코드나 다른 것들이다.)가 있으니 그 번호를 찾아 1번~ 2번 등으로 바로 찾는 것이다.
-
첫번째 인덱스 방식 : 내가 찾으려는 값이 홍길동 일 때 그리고 그 값이 첫번째에 있을 때, 인덱스를 안쓰면 첫번째에 홍길동이 있는 걸 확인을 했어도 1~100번째 까지 전부 확인한 후에 첫번째 홍길동을 출력하는데, 인덱스를 사용하면 첫번째에 있는 홍길동을 바로 찾고, 그 이후에 백번째에 홍길동이 들어오게 되면 백번째로 들어가는게 아니라 첫번째 홍길동의 옆으로 붙는다.
-
두번째 인덱스 방식 정렬 : 홍길동 옆에 김철수가 있을 때, 홍길동의 동일 객체가 온다. 홍길동의 옆자리를 차지하면 검색할 때 홍길동 좌우 주소만 찾으면 한번에 검색이 가능하다.
-
세번째 인덱스 방식 : 튜플은 순서가 없다. KEY VALUE 값으로 홍길동이라는 KEY가 있다. VALUE에는 각각 홍길동이 들어가 있는 주소가 있다. KEY를 통해 VALUE를 찾으면 빠르게 찾을 수 있다.
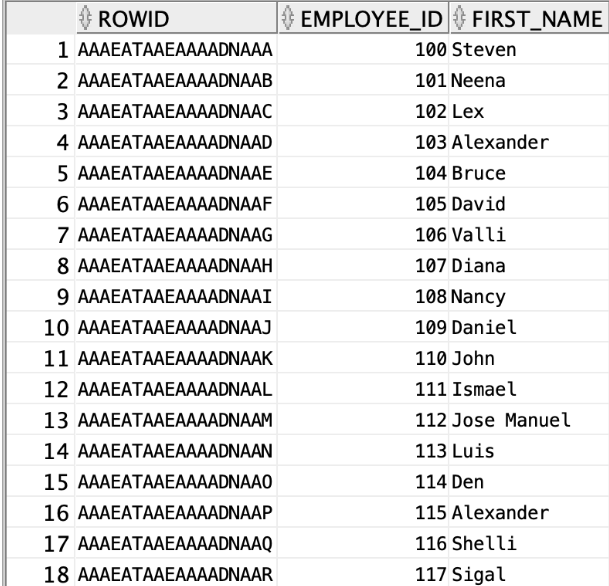
모든 테이블에는 ROWID라는 칼럼이 있다. ROWID = FILE 번호 + BLOCK 번호 + ROW번호로 구성되어 있다. "7번파일에 132번 블록에 3번째" 이런 식으로 해당 데이터의 주소라고 볼 수 있다. INDEX는 이런 ROWID를 통해 DATA BLOCK에 접근 한다. INDEX는 데이터를 빠르게 찾기 위해 오름차순으로 정렬된 주소체계(라고 표현하고 싶)다.
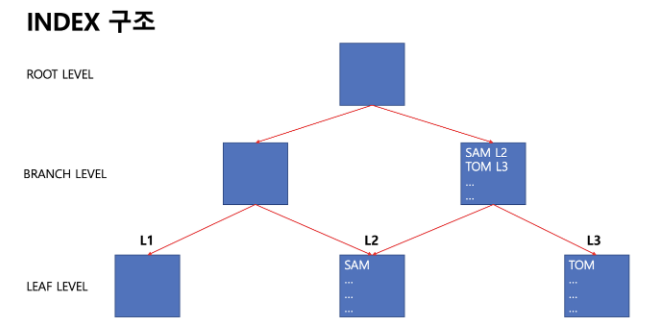
INDEX는 ROOT, BRANCH, LEAF로 구성되어 있는 계층적 구조를 갖고 있다. 오라클 서버에서 FULL SCAN보다 INDEX SCAN이 유리하다고 판단 되었을 때 생성된 INDEX의 ROOT 부터 찾는다. ROOT에는 BRANCH 블럭의 시작점에 대한 정보를 갖고 있어 찾고자 하는 데이터의 위치가 어느 BRANCH에 위치하는지 알 수 있다. BRANCH LEVEL에서도 마찬가지로 LEAF 블럭에 대한 시작점 정보를 갖고 있어 어느 LEAF에 포함되어 있는지 알 수 있다. 마지막으로 LEAF에서 해당 데이터의 ROWID를 알 수 있다. 찾았을때 BLOCK의 ROWID를 알아냈으니, 바로 해당 데이터로 찾아갈 수 있어 빠른 검색이 가능하다.
INDEX 유지보수
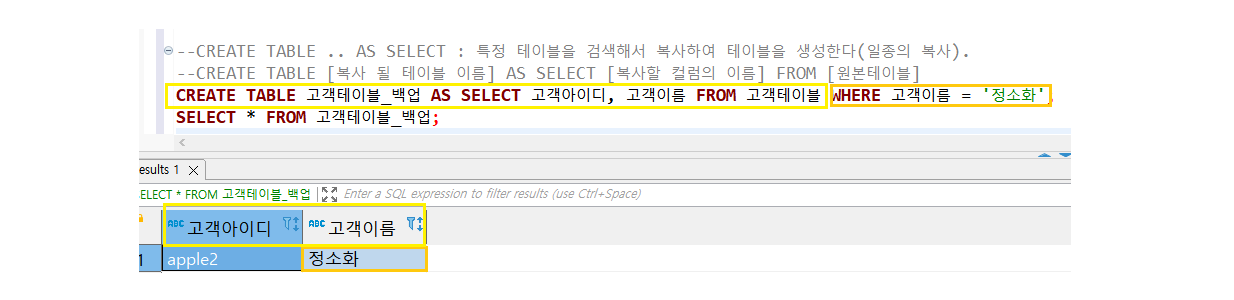
4. 복사 : CREATE TABLE .. AS SELECT