문제 출처
https://school.programmers.co.kr/learn/courses/30/lessons/42747(프로그래머스)
학습 키워드
정렬
시도 방법
이 문제는 내용에 대한 말들이 많았다. (다소 H-index의 개념을 복잡하게 설명했다는 느낌이었다.) 그래서 질문에 안성희님께서 정리해주신 H-index 개념을 토대로 문제를 풀었다.
질문 출처 : https://school.programmers.co.kr/questions/64629
요지는 논문 n편 중에 a번 이상 인용된 논문이 b편 이상일 경우 a와 b 중 작은 값이 h-index라는 것이었다.
내가 작성한 코드
import java.util.Arrays;
import java.util.Collections;
class Solution {
public int solution(int[] citations) {
Arrays.sort(citations);
int maxH = 0 ;
for(int i = 0 ; i<citations.length; i++) {
int paper = citations[i]; //논문
int citationCount = citations.length - i ; //인용횟수
int result = Math.min(paper , citationCount);
if(maxH < result) {
maxH = result;
}
}
return maxH;
}
}코드설명
가장 먼저 논문별 인용횟수를 의미하는 citations를 오름차순 정렬했다.
정렬이 된다면 이후 논문 개수만 파악하면 되기 때문이다.
그래서 반복문을 돌리면서 인용된 논문 횟수 (citations[i]) 와 전체 논문 - 현재 논문 ( 그러니까 현재 내 기준 이후의 논문들 개수) 를 비교하여 Math.min으로 최솟값을 선택한 뒤, 해당 최솟값이 maxH 와 비교해 더 크다면, 더 큰 값이 maxH가 된다.
예를 들어 [3 4 5 8 10] 로 정렬이 되었다고 하자.
3회이상 인용된 논문 수는 5개 (3,4,5,8,10) 이다.
4회이상 인용된 논문 수는 4개 (4,5,8,10) 이다.
5회이상 인용된 논문 수는 3개 (5,8,10)이다.
8회이상 인용된 논문 수는 2개 (8,10) 이다.
10회이상 인용된 논문 수는 1개 (10) 이다.
이 때 a 회 이상 인용된 논문 수 b 개 라고 정의한다면 a와 b중 작은 값이 h-index이다.
따라서 순서대로 h-index 가 3 , 4 , 3 , 2 , 1 이 되고 가장 큰 값인 4가 답이 된다
실행결과
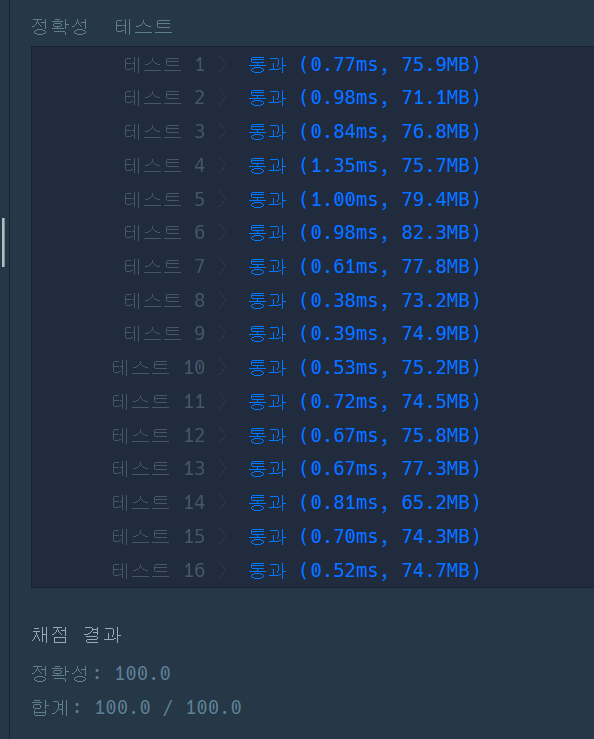
새롭게 알게된 점
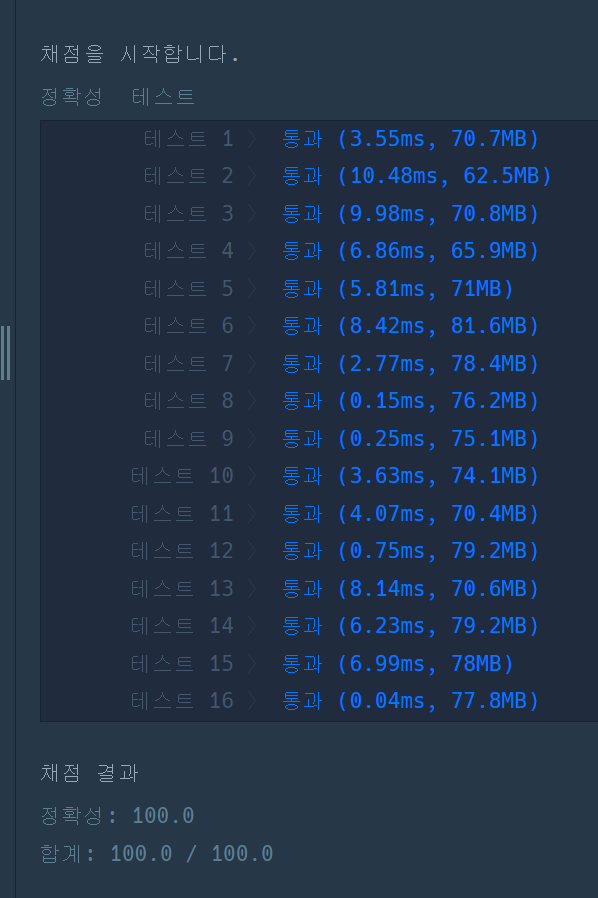
정렬을 하지 않고 이중 for문으로 문제를 풀어보았을 때 확실히 시간이 더 걸린다는 것을 알 수 있었다.
class Solution {
public int solution(int[] citations) {
//정렬없이 풀어보자
int citationCount = 0;
int count = 0 ;
int result = 0 ;
for(int i = 0 ; i<citations.length; i++) {
citationCount = citations[i];
count = 0 ;
for(int j = 0 ; j<citations.length; j++) {
if (citationCount <= citations[j]) {
count++;
}
}
result = Math.max(result , Math.min(citationCount , count) );
}
return result;
}
}실행결과
다음에 풀어볼 문제 - 카펫
#99클럽 #코딩테스트 준비 #개발자 취업 #항해99 #TIL
