배열의 경우, 연속된 메모리 공간이 필요하다는 단점이 있었다.
이를 해결하기 위해서는 데이터를 분산 저장한 후, 이를 서로 연결해주면 될 것이다.
이 때 노드(Node)를 만들어 사용하게 되는데, 노드는 데이터를 담는 변수 하나와 다음 노드를 가리키는 변수 하나를 가지고 있다.

위와 같은 구조를 연결리스트라고 한다.
연결리스트는 첫 노드의 주소만 알고 있으면 다른 모든 노드에 접근이 가능하다.
연결리스트
연결리스트의 경우, 배열과 달리 빈 메모리 공간 아무 곳에나 데이터를 생성한 뒤, 그것을 연결만 해주면 되기 때문에 배열의 초기 크기를 가늠할 필요가 없다.
배열의 경우 중간에 데이터를 삽입하면, 이후의 값들이 모두 뒤로 밀리기 때문에 오버헤드가 많이 든다. 반면 연결리스트는 중간에 데이터를 삽입하더라도 다음에 가리키는 노드만 바꿔주면 되기 때문에 비교적 간단하다.
배열은 메모리의 연속된 공간에 할당되어 있어 시작 주소만 알고 있다면 그 이후의 데이터에 접근하는 것이 용이하다. O(1)의 성능을 갖는다.
반면 연결리스트의 경우 데이터가 떨어져 있으므로 다음 데이터까지의 접근이 용이하지 않다. 노드를 계속 타며 원하는 데이터에 접근해야 하므로 O(n)의 성능을 갖는다.
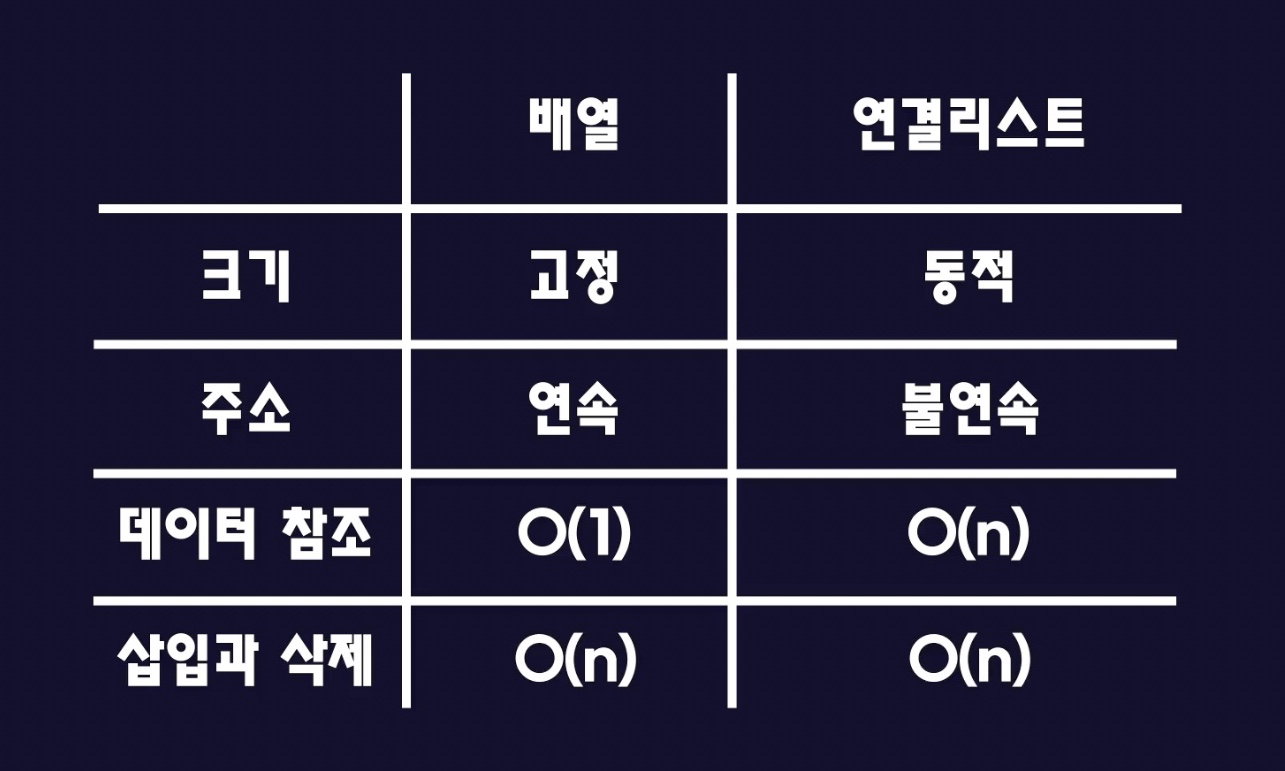
배열과 연결리스트 비교
- 크기 : 배열은 크기 고정 / 연결리스트는 필요에 따라 동적인 크기의 배열 사용 가능
- 주소 : 배열은 연속된 메모리 공간에 값 할당 / 연결리스트는 불연속적인 메모리 공간에 값 할당한 후 노드를 이용해 그를 연결
- 데이터 참조 : 배열은 메모리의 연속된 공간에 할당되기 때문에 메모리 접근이 굉장히 빠르다. O(1)의 성능 / 연결리스트는 데이터 참조를 위해 앞에서부터 해당 노드까지 접근해야 하기 때문에 배열에 비해 느리다. O(n)의 성능
- 삽입과 삭제 : 배열에서 데이터를 삽입하려면 기존 모든 데이터를 옮겨야 하므로 O(n)의 성능을 갖는다. / 연결리스트는 데이터의 삽입 혹은 삭제를 위해 원하는 위치까지 노드를 타며 이동해야 하므로 O(n)의 성능을 갖는다.
데이터의 변경은 잘 일어나지 않고, 잦은 참조를 해야 한다면 => 배열
데이터의 삽입 및 삭제가 빈번할 경우 => 연결리스트
