
문제
정수 집합 S가 주어졌을때, 다음 조건을 만족하는 구간 [A, B]를 좋은 구간이라고 한다.
A와 B는 양의 정수이고, A < B를 만족한다.
A ≤ x ≤ B를 만족하는 모든 정수 x가 집합 S에 속하지 않는다.
집합 S와 n이 주어졌을 때, n을 포함하는 좋은 구간의 개수를 구해보자.
링크 참조
풀이 설명
주어진 집합 S의 원소와 겹치지 않는 부분집합을 구한다고 생각하면 된다.
단, 부분집합의 [a,b] 중 a가 더 작아야 한다.
첫 번째로는 집합 S의 크기가 주어진다.
두 번째는 집합 S의 원소들이 주어진다.
세 번째로는 부분집합 안에 꼭 포함되어야 하는 원소 n이 주어진다.
S의 크기가 4이고 {1, 7, 14, 10}을 갖는다. 이후 2가 꼭 포함된 부분 집합의 개수를 구하는 것이 목표이다.
여기서는 {2,3}, {2,4}, {2,5}, {2,6} 만 가질 수 있다. 총 4개가 가질 수 있기에 출력은 4가 된다.
결론적으로, 원소 n을 기준으로 해당 값이 집합에서 어느 값들 사이에 위치해있는지 확인 한 후,
해당 값들이 포함되지 않은 부분집합의 개수를 구하면 된다.
코드
L = int(input())
S = list(map(int,input().split()))
n = int(input())
answer = []
if n in S:
print(0)
else:
S.append(n)
S.sort()
index = S.index(n)
if (index):
prev = S[index-1]
else:
prev = 0
N = S[index]
next = S[index+1]
#N이 속해진 앞 뒤 부분 추가
for i in range(prev+1, N+1):
for j in range(N, next):
answer.append(((i,j)))
print(len(set(answer))-1)L은 집합 S의 길이, S은 집합, n은 포함되어야 할 원소의 수이다.
정답 배열 리스트를 answer로 정의하였다.
첫 번째로는 포함되어야 할 원소 n이 집합 S에 이미 있는 경우이다. 이 경우에는 이미 중복되어있는 경우이기에 바로 0을 출력한다.
그 외에 n이 집합 S에 포함되어 있지 않는 경우에 구하는 것을 시작한다.
S에 필수요소 n을 더해준 다음 정렬한다.
그렇게 되면 n이 리스트 S에 몇 번째 위치인지 알 수 있게 된다.
그 다음 index 함수를 이용하여 n의 위치를 저장한다.
n의 위치가 첫 번째이게 된다는 것은 1부터 다음 요소까지의 집합을 구해야 함으로
prev 값을 0으로 지정한다. (뒤에서 +1부터 시작할 것이기 때문에 0으로 저장!)
n의 위치가 첫 번째가 아닌 경우에는 그 앞에 다른 원소들이 있다는 것이다.
따라서 n의 위치 바로 앞에 있는 인덱스의 값을 prev로 저장하고,
현재 n의 값은 N로 저장하고, n의 위치 뒤에 있는 값은 next로 저장한다.
그 다음 이중 for문을 이용하여 i는 이전의 값보다 +1 인 값부터 N까지,
j은 N부터 다음값인 next보다 -1인 값까지 돌도록 한다.
이렇게 answer에 i,j의 쌍을 추가해주면 된다.
그 다음 set으로 answer내의 있는 중복 요소를 제거한 다음 -1을 빼준다.
-1을 뺴주는 경우는 자신부터 자신까지인 경우이다.
예를 들어, {1, 7, 14, 10} 에 2를 포함하는 부분 집합이라고 생각하면
{2,3} {2,4} {2,5} {2,6} 만 가져야 한다.
하지만 나의 코드는 {2,2} 도 포함되게 된다. 따라서 -1을 해주는 것이다.
💌💢
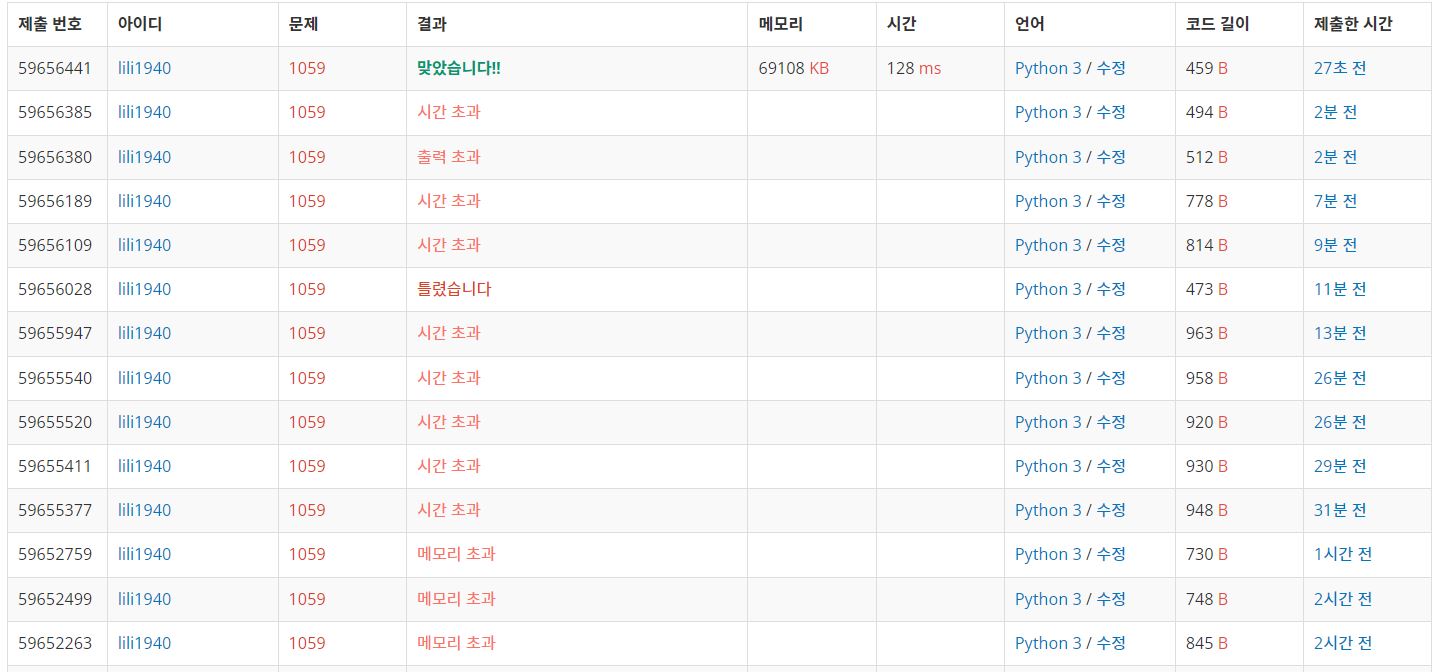
-광기 그 잡채-
후기
하 ........ 이 문제는 참 나를 힘들게 했다 😂
첫 번째로는 나는 for문이 아니라 while문을 이용했다.
심지어 3개를 이용해서 이전부터 N까지 / N부터 다음까지 / 이전부터 다음까지
이렇게 총 3번을 중복 검사 하면서 돌게 했다.
그렇게 하다 보니 메모리 초과가 발생했다 .. ㅜㅜ (당연함)
변수도 최대한 없애보고 중복 검사 하고 넣어보고 별 난리를 치다보니
이젠 시간초과로 바뀌었다 하하하 ..
그래서 gpt의 도움도 받아봤지만 (?) 큰 도움이 되지 못했고
gpt의 아이디어를 참고하여 차근히 생각해봤더니 하나로 묶어서 생각할 수 있었다!
44%의 시간초과 늪에서 드디어 탈추울 ㅎㅎ .. 🤍
