개인적인 서론...
졸업프로젝트를 위해 이제 막 딥러닝을 공부하기 시작했습니다. 최종적으로 구현하고자하는 기능은 '글씨체 교정'인데요, 관련해서 저희 프로젝트를 간단하게 설명드리겠습니다.
ㅡ
저희는 [패드용 글씨체 연습 앱]을 만들고자합니다. 사용자에게 줄노트와 글씨 교본을 제공해준 후 사용자가 쓴 글을 보고 어떠한 부분을 교정해야할지 알려주는 것이 메인 기능입니다. 즉, 글자를 검출하고 자음 및 모음으로 인식을 한 후 저희가 정한 '악필 기준'에 따라 계산하는 과정이 필요합니다.
그 중 딥러닝을 통해 한글 자음 모음을 인식하기. 이것이 저의 최종 목표입니다. 하지만 문제가 있다면 제가 딥러닝에대해 아주 햇병아리라는 것입니다. 그래도 이런 말이 있지 않습니까?
급할수록 돌아가라.
..네 딥러닝에 익숙해지는 것을 목표로 차근차근 진행해보려합니다.
첫 시도는 'CNN을 이용하여 한글 분류해보기'입니다.
이번 포스트에서는 환경설정과 dataset에 대해 다룹니다.
Colab
코랩이란 주피터 노트북을 기반으로 웹에서 코딩을 할 수 있도록 구글에서 제공하는 서비스입니다. 구글에서 제공하는 클라우드와 가상 서버를 활용할 수 있기때문에 컴퓨터 성능에 큰 제약을 받지 않는다는 장점이 있습니다. 웹 브라우저를 통해 제어하지만 실제 코드 실행은 구글 클라우드의 가상서버에서 이루어지기 때문입니다. 무료로 GPU를 사용할 수 있는 좋은 서비스이죠!
(간단한 것들은 무료버전으로 충분하지만 무거운 작업을 수행한다면 정신 건강을 위해 유료 버전 -- Google Colab Pro을 추천합니다.)
https://colab.research.google.com/?hl=ko
위 링크를 통해 코랩을 사용할 수 있습니다.

코랩에 노트북을 만든 후 '런타임 - 런타임 유형'에서 GPU 사용설정을 할 수 있습니다.
한글 OCR에 대해
한글은 영어에 비해 매우 다양한 조합을 가지고 있습니다. 가능한 음절의 수는 무려 11,172자에 달합니다. 이러한 글자들을 모두 인식하는 것은 매우 낭비가 심한 일입니다. 따라서 KS X 1001 완성형에 포함되는 한글 2,350자만 사용하도록 하겠습니다.
* . KS X 1001 실제로 발음 되어 한국어에서 사용빈도가 높은 글자들을 모은 것입니다.
Dataset 생성
학습에 필요한 데이터는 AI Hub에서 얻었습니다. (https://aihub.or.kr/aidata/133)
현대 한글을 가장 많이 활용하는 폰트(글자서체) 50종을 선정하여 해당 글자체의 이미지와 어노테이션 데이터를 포함한 인쇄체와 다양성을 확보하기 위해 성별, 연령층별로 손글씨 작성인력을 확보하여 직접 작성 제작한 손글씨 이미지와 어노테이션이 데이터셋에 포함되어 있습니다.
이제 데이터를 불러와보겠습니다.
from google.colab import drive
drive.mount('/gdrive')구글 colab에 구글 드라이브를 마운트 해줍니다.
import json
with open('./data/handwriting_data_info1.json') as f:
data = json.load(f)
with open('./data/KS_2350.txt') as f:
KS_2350 = f.read()
KS_2350 = KS_2350.split()json 라이브러리를 import하고, AI Hub에서 받아온 손글씨 데이터를 읽어옵니다.
그리고 모든 한글 음절이 아닌 2,350자만 사용할 것이기때문에 사용할 한글 음절을 따로 파일로 만들어 주었습니다.
그럼 데이터셋을 살펴봐볼까요?
import json
with open('./data/handwriting_data_info1.json') as f:
syllable_data = json.load(f)
with open('./data/KS_2350.txt') as f:
KS_2350 = f.read()
KS_2350 = KS_2350.split()syllable_data.keys() # dict_keys(['info', 'images', 'annotations', 'licenses'])AI Hub에서 제공하는 한글 손글씨 데이터는 'info', 'images', 'annotations', 'licenses'라는 key들로 이루어져 있습니다.
그 중 annotations를 살펴볼까요?

첫번째 데이터만 가져와보았습니다.
손글씨를 작성한 사용자와 글씨 타입, image에 접근할 id, text내용이 있네요!
저는 음절 단위의 태깅 데이터만 필요하기때문에 annotations 값에서 attributes['type']== '글자(음절)'로 골라내겠습니다.
id = []
text = []
for i, data in enumerate(syllable_data['annotations']):
if data['attributes']['type'] == '글자(음절)':
if data['text'] in KS_2350:
id.extend([data['id']])
text.extend([data['text']])image_id와 id값이 같기때문에 id로 가져왔습니다.
images = []
for i, ID in enumerate(id):
if i < 28345:
Image_addr = './data/images/1_syllable/' +str(ID)+'.png'
elif i < 152432:
Image_addr = '/gdrive/MyDrive/Colab Notebooks/cnn/2_syllable/' +str(ID)+'.png'
image = Image.open(Image_addr)
image = image.resize((32, 32))
img_array = np.array(image)
images.append(img_array)이미지 파일을 불러와줍니다.
데이터 양이 많아 '00001698'~'00192280'은 1_syllable 폴더에, '00200001' ~ '01197748'은 2_syllable 폴더에 위치하고 있습니다.
이미지 크기는 32 * 32로 해주었습니다.
이렇게 AIHub의 데이터 중 필요한 음절만 뽑아내어 dataset을 만들었습니다.
정수 인코딩(Integer Encoding)
정수 인코딩은 원-핫인코딩을 위해 필요한 과정입니다.
글자는 그 자체로 index가 될 수 없기때문에 글자에 Index를 부여해주는 과정입니다.
syllable = list(set(text))
syllable_to_index = {syllable: index for index, syllable in enumerate(syllable)}
index_to_syllable = {index: syllable for index, syllable in enumerate(syllable)}덧. anaconda에서 keras 사용하기 (window)
지금까지 코랩으로 진행했지만 가상환경을 사용할 수도 있습니다. 코랩에 데이터셋을 추가하는 과정에서 데이터 누락이 일어나 아나콘다에서 데이터셋을 좀 더 다듬어보려합니다. 따라서 막간을 이용하여 아나콘다 환경구축에 대해서도 짧게 다루어보겠습니다. 참고로 위의 과정은 파일 경로를 제외하고 아나콘다에서도 동일하게 진행할 수 있습니다.
아나콘다는 Python 및 Numpy, Pandas, Matplotlib과 같은 데이터사이언스에서 유용한 라이브러리들을 쉽게 설치 및 관리할 수 있게 해주는 도구입니다.
가상환경을 만들어 필요한 패키지를 설치하여 같은 컴퓨터 위에서도 프로젝트를 분리하여 실행할 수 있습니다. 여러 가상환경을 구축해두고, 상황에 따라 필요한 환경을 activate하여 사용하면됩니다.
https://www.anaconda.com/distribution/
위 링크에서 아나콘다를 설치할 수 있습니다.
설치가 완료되면 Anaconda Prompt를 실행시켜줍니다.
익숙한 cmd창이 나오네요. 그럼 이제 keras를 설치하기 위한 가상환경을 만들어주도록 하겠습니다.
conda create --name keras python=3.6'keras'라는 이름의 가상환경을 생성해주었습니다.
keras는 Python 2.7 ~ 3.6과 호환이 되기때문에 python은 3.6버전으로 함께 설치해주었습니다.
conda activate keraskeras 가상환경을 활성화시켜줍니다. *. 비활성화시엔 deactivate를 사용해주면됩니다
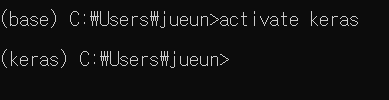
(base)에서 (keras)로 바뀐 것을 통해 가상환경이 실행되었음을 알 수 있습니다!
그럼 이제 필요한 패키지들을 설치해주면됩니다.
우선 keras부터 설치해줍시다.
conda install -c anaconda kerasCPU버전으로 설치해주었습니다.
위 명령어를 입력할 경우 Tensorflow(2.x버전 -- 1.x버전과 사용법이 다르니 유의), CUDA, cuDNN이 함께 설치됩니다.
그 외에 필요한 패키지가 있다면 (pandas, 사이킷런 등...) keras를 설치해준 것과 마찬가지로 설치해줄 수 있습니다.
conda install -c anaconda pandas # 데이터 조작 및 분석에 사용
conda install -c anaconda scikit-learn # 사이킷런
conda install pillow # 이미지 처리저는 우선 이렇게 설치해주었습니다.
이제 코드 에디터를 설치해주려는데, Jupiter notebook도 많이 사용하지만 개인적으로 spyder가 더 사용하기 편하다고 느꼈기때문에 spyder를 사용하려합니다.
conda install spyder
spyderspyder를 설치하고 실행해줍니다
이제 코드를 실행할 수 있습니다. 확인용으로 keras 버전을 확인해주겠습니다.
import tensorflow as tf
import keras as k
print("tensorflow ", tf.__version__)
print("keras ", k.__version__)위 코드를 통해 텐서플로우와 케라스의 버전을 확인할 수 있어야하는...데??
ModuleNotFoundError: No module named 'tensorflow_core.estimator' for tensorflow 2.1.0
라는 에러가 뜹니다.
모듈을 찾을 수 없다하니 spyder를 끄고 다시 cmd로 돌아가 패키지를 확인해보겠습니다. 설치된 패키지 확인은 conda list 명령어로 확인할 수 있습니다.
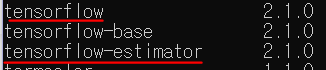
현재는 버전이 같으나, 에러가 날 당시에는 tensorflow와 tensorflow-estimator의 버전이 달랐습니다. conda install tensorflow-estimator=2.1.0을 통해 버전을 맞춰줍니다.
다시 spyder를 실행하여 확인해볼까요?
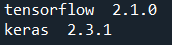
잘 작동하네요!
이제 가상환경에서 keras를 사용할 수 있습니다.

잘 봤어요~ 김현수교수