
개요
졸업 프로젝트인 태블릿PC용 글씨 연습 어플에서 글씨 분석 기능을 위해 사용한 딥러닝 기술에 대해 써 본 글입니다.
저희 프로젝트는 사용자 글씨가 잘 쓰여졌는가를 글자 크기, 비율 등으로 판단하고자하기때문에 딥러닝을 사용하여 한글 이미지에서 초성, 중성, 종성(이후 글에서는 자음, 모음, 받침으로 통일하겠습니다) 영역을 추출하였습니다.
프로젝트에서 딥러닝 파트를 처음 맡아보았기때문에 모르는것도 많았고 그래서 간단한 것들에서도 헤매는게 많았던 프로젝트였네요... 그래서 저의 삽질기를 바탕으로 데이터셋 생성부터 모델 학습까지의 내용을 최대한 0부터 1까지 써보았습니다.
(추후 저희 프로젝트에서 사용한 또 다른 딥러닝 모델과 모델 배포등에 대한 내용도 업로드 할 예정입니다)
전체 코드: https://github.com/0ju-un/pytorch-fpn-segmentation
개발 환경 (제 이전 글을 참고하시면 좋습니다):
- Apple Silicon M1
- Python 3.8
관련연구
이번 글에서는 관련 연구에 대한 것은 짧게 요약하여 적었기때문에 이런 기술을 썼구나 정도로 읽어주시면 좋을 것 같습니다. :)
Segmentation
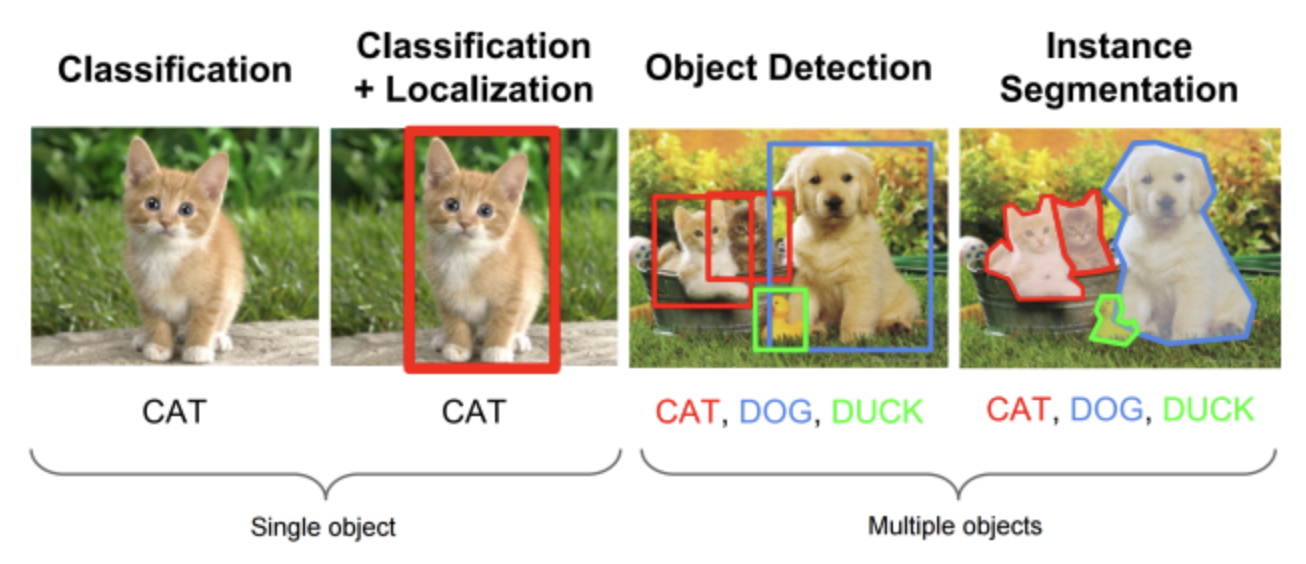
segmentation은 이미지내에서 픽셀 단위로 해당하는 클래스로 분류하는 것을 목적으로 합니다.
위 그림을 보면 classification, object detection, 그리고 segmentation의 차이를 한 눈에 이해할 수 있는데요.
저희 프로젝트의 경우 한글 음절에서의 자음, 모음, 받침의 위치가 필요하기때문에 세그멘테이션 기술을 적용하였습니다.
FPN
FPN은 Feature Pyramid Network의 준말입니다.
사실 처음엔 U-NET으로 세그멘테이션을 진행하였는데요. 실제 손글씨 이미지로 추론해보니 잘못 인식되는 경우가 많았습니다. 🥲
FPN에 대해 간단히 설명해보면, FPN은 각 레벨에서 독립적으로 특징을 추출하여서 고해상도와 저해상도 특징 맵을 결합합니다. 즉 하나의 이미지에서 다양한 크기의 특징 피라미드를 얻어 객체를 탐지합니다. 이렇게 추출된 각 특징들을 upsampling한 후에 pixel-wise summation을 통해 픽셀 단위의 세그멘테이션 결과를 냅니다. 서로 다른 크기의 특징 맵에서의 예측을 통해 정확도를 높일 수 있는 것이죠
(혹시 틀린 내용이 있다면 언제든 댓글로 말씀주세요)
이는 아래에서 파이토치로 구현해 볼 예정입니다 ^_^
글씨를 감지하려면 좀 더 전체를 보아야할 것 같아서 정확도를 높이고자 FPN 모델을 사용하였습니다.
아래는 전체 모델 구조입니다. 자세한 내용은 논문을 참고하시면 좋을 것 같습니다.
Dataset 생성
한글 자모 이미지 인식에서 가장 힘들었던 점은 관련 데이터셋이 없었다는 것입니다.
ai허브 등에 가보면 한글 손글씨 데이터셋이 아주 잘 만들어져있지만 안타깝게도 위 데이터셋은 단어, 음절 단위까지의 어노테이션만을 제공합니다..
그래서 손글씨 폰트를 사용하여 데이터셋을 직접 만들었습니다.
음절 이미지 몇만장을 하나하나 라벨링하기엔 시간과 비용이 부족했기때문에 음절을 이루는 음소(초성, 중성, 종성)에 대한 마스크를 생성한 후 이를 합치는 것이 이번 데이터셋 생성의 메인 아이디어입니다.
초성, 중성, 종성 요소 이미지 생성
초성, 중성, 종성 이미지를 만드는 방법은 간단합니다. 음절 이미지를 만든 후, 각 음소만 남기고 지웠습니다. '가' 이미지를 두 장 만들어서 ㄱ과 ㅏ를 각각 남기는 식으로요. 즉 노가다입니다.
애초에 음소만 이미지로 만들 수도 있겠지만, 위치와 모양이 달라 이러한 방법을 썼습니다.
예를 들어 '각'만 보더라도 초성의 ㄱ과 종성의 ㄱ의 위치와 모양이 다른 경우 등을 고려하였습니다.

이런 식으로요!
이미지 생성은 NAVER CLOVA의 손글씨 폰트를 사용하였습니다.
## 1. resize input images
input_src_list = os.listdir(input_src_dir)
for dir in input_src_list:
if dir == '.DS_Store':
continue
src_dir = os.path.join(input_src_dir, dir)
img_dir = os.path.join(input_images_dir, dir)
if not os.path.exists(img_dir):
os.mkdir(img_dir)
src_list = [file for file in os.listdir(src_dir) if file.endswith('.png')]
src_list.sort()
for i, src in enumerate(src_list):
src_path = os.path.join(src_dir, src)
img_path = os.path.join(img_dir, src)
img = Image.open(src_path).convert('L')
img = img.point(lambda p: 255 if p < threshold else 0)
img.save(img_path, 'PNG')생성한 요소 이미지는 배경은 0, 글씨는 1로 이진화 해줍니다.
이미지 크기도 224 x 224로 변경해주었습니다
흑백 이미지에서 0은 검정, 255는 흰색을 나타내기때문에 픽셀값이 170보다 낮으면 0이되도록 thresholding해줍니다.
음절 데이터셋 생성
# main.py
for syllable in ks_list:
character_index = jamo.getIndex(syllable) # 초성 중성 종성과 이미지위치 매핑
img = np.zeros(img_size, dtype=np.uint8)
mask = np.zeros(img_size, dtype=np.float32)
# 초성, 중성, 종성 이미지 가져와 하나의 음절 이미지 생성
for i, index in enumerate(character_index):
input_img = Image.open(os.path.join(input_img_dir, img_list[index])).convert('L')
input_img = np.asarray(input_img)
# 이미지 변형
trans_element = transform_element[i]
input_img = trans_element(image=input_img)['image']
# mask[i][input_img != 0] = 1
# 이미지, 마스크 생성
mask[input_img != 0] = i + 1
img[input_img != 0] = 255
transformed = transform(image=img, mask=mask)
data.append(transformed['image'])
target.append(transformed['mask'])
img = Image.fromarray(transformed['image'])요소 이미지에서 글씨 부분이 자음이면 1 , 모음이면 2, 받침이면 3으로 마스크를 생성합니다.
한글 음절은 무려 11,172자의 조합이 가능합니다. 그 중 자주 쓰이는 음절 2350자에 대해 음절 데이터를 만들었습니다.
넘파이를 이용해해 간단한 코드로 이미지가 0(배경)이 아니라면 라벨값으로 바꾸어 줄 수 있습니다.
그런데 값을 그대로 합쳐버리면 모두 자음, 모음, 받침의 글씨 모양들이 모두 같은 위치, 모양으로 조합이 되어버립니다.
따라서 image augmentation으로 음절로 합치기 전후로 이미지에 변화를 줍니다.
import albumentations as A
## Transform Function
# for 음절 이미지
transform = A.Compose([
A.ShiftScaleRotate(
shift_limit=0.03,
scale_limit=(-0.2, 0.2),
rotate_limit=0,#(-10, 10),
p=0.6),
A.Affine(shear=[-5, 5], p=0.6),
A.PiecewiseAffine(scale=0.02, p=1.0)
])
# for 자음
transform_0 = A.Compose([
A.ShiftScaleRotate(
shift_limit_x=(-0.02, 0.005),
shift_limit_y=(0, 0.01),
scale_limit=(-0.2, 0.1),
rotate_limit=5,
p=0.7),
A.PiecewiseAffine(scale=0.01, p=1.0)
])
# for 모음
transform_1 = A.Compose([
A.ShiftScaleRotate(
shift_limit_x=(0, 0.02),
shift_limit_y=(0, 0.01),
scale_limit=(-0.2, 0.1),
rotate_limit=5,
p=0.7),
A.PiecewiseAffine(scale=0.01, p=1.0)
])
# for 받침
transform_2 = A.Compose([
A.ShiftScaleRotate(
shift_limit_x=(-0.005, 0.02),
shift_limit_y=(-0.025, -0.015),
scale_limit=(-0.2, 0.1),
rotate_limit=5,
p=1.0),
A.PiecewiseAffine(scale=0.01, p=1.0)
])
transform_element= [transform_0, transform_1, transform_2]augmentation은 albumentations을 사용하였습니다.
자음, 모음, 받침 변형은 위치와 크기에만 변화를 주었습니다.(회전을 주면 글씨가 중구난방이 되어버리더군요...)
자음같은 경우 너무 내려가면 안되는 등 한글이 가지는 기하학적인 특징이 있기때문에 각각에 대한 transform 함수를 정의해주었습니다.

짠! 데이터셋이 만들어졌습니다. 제법 손으로 쓴 글자같지않나요?
합쳐지면서 받침등이 너무 겹쳐 글시 같지 않게 나온 경우들은 삭제하여 데이터셋을 정제하였습니다.
손글씨 폰트 25종 X 음절 2350 = 총 58,750장의 자음, 모음, 받침으로 라벨링된 음절 이미지들을 생성하였습니다.
from sklearn.model_selection import train_test_split
## split train, val, test
print(len(data), len(target))
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.1, shuffle=True, random_state=34)
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.11, shuffle=True, random_state=34)
print(len(x_train), len(x_val), len(x_test))생성한 데이터셋은 tran, val, test으로 나누어줍니다.

이런 데이터셋 폴더 안에
input_0.npy
label_0.npy
이런식으로 인풋이미지와 라벨이미지가 들어있습니다
모델 생성 - PyTorch
이제 모델 만들어주어야겠죠!
참고한 깃허브는 다음과 같습니다:
https://github.com/qubvel/segmentation_models.pytorch
https://github.com/gasparian/multiclass-semantic-segmentation
model
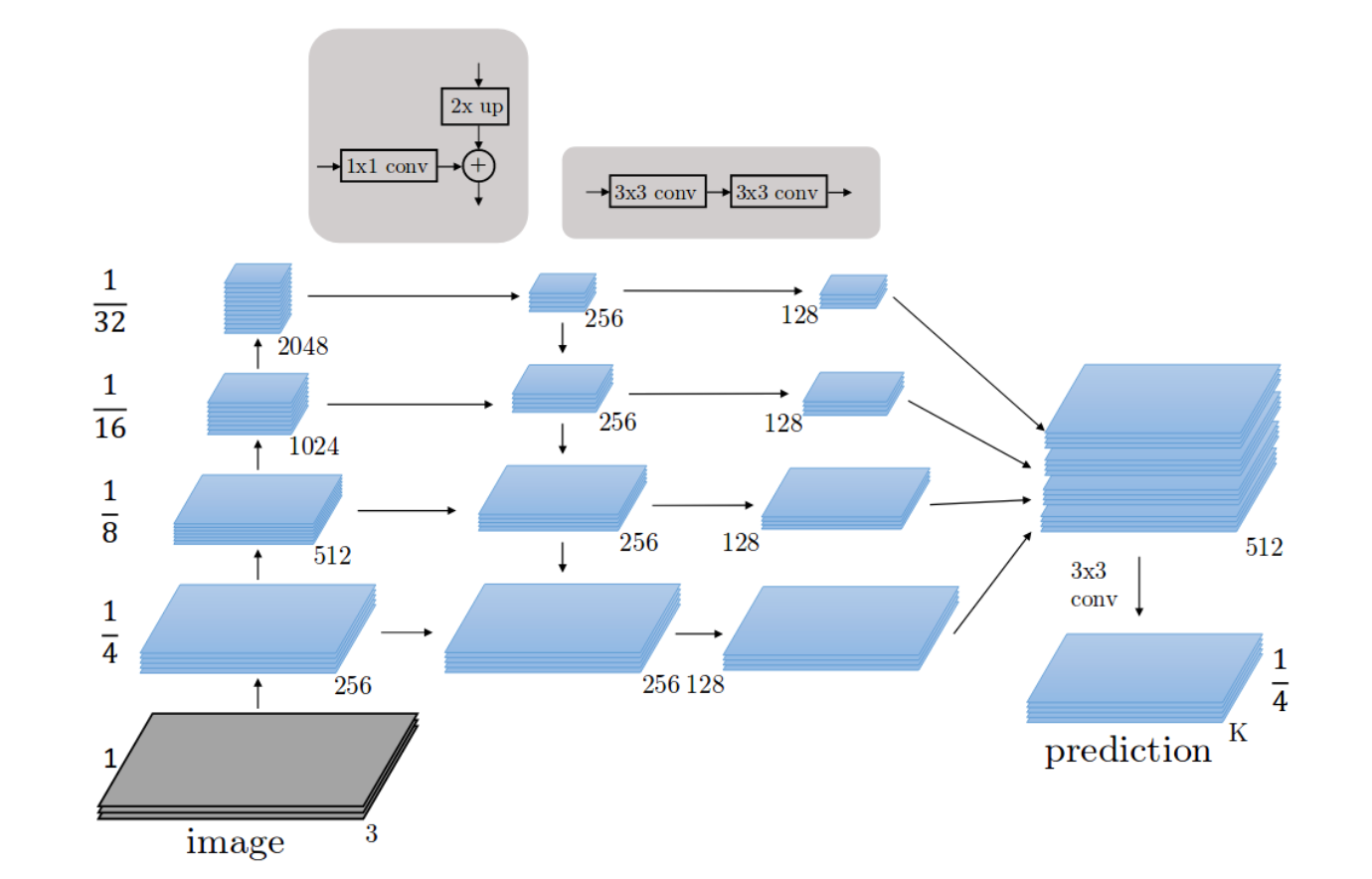
모델 구조는 다음과 같습니다.
백본은 파이토치에서 제공하는 pretrained된 resnext50을 사용하였고,
FPN으로 특징을 추출하고 segmentation을 진행합니다.
모델 구현은 fpn.py에 하였으며 전체 소스는 깃허브에 있습니다
너무 길기때문에 이번 글에서는 해당 코드에 대한 설명은 생략하였습니다.
# train.py
## 트레이닝 파라메터 설정
n_class = 3
lr = 1e-3
batch_size = 16
num_epoch = 100
num_workers = 0
mode = "FPN"
backbone = "resnext50"
필요한 파라미터들을 설정해 줍니다.
Dataset & DataLoader
import os
import numpy as np
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
lst_data = os.listdir(self.data_dir)
lst_label = [f for f in lst_data if f.startswith('label')]
lst_input = [f for f in lst_data if f.startswith('input')]
lst_label.sort()
lst_input.sort()
self.lst_label = lst_label
self.lst_input = lst_input
def __len__(self):
return len(self.lst_input)
def __getitem__(self, idx):
label = np.zeros((3, 224, 224), dtype=np.float32)
input = np.load(os.path.join(self.data_dir, self.lst_input[idx]))
mask = np.load(os.path.join(self.data_dir, self.lst_label[idx]))
for i in range(3):
label[i][mask==i+1] = 1
input = input.reshape(1, 224, 224).repeat(3, axis=0).transpose([1, 2, 0])
if self.transform:
input = self.transform(input)
return [input, label]
파이토치에서는 데이터셋과 데이터로더 클래스를 제공하여 좀 더 편하게 데이터 샘플을 처리하도록 하고있습니다.
데이터셋을 만들면 폴더에서 인풋과 마스크를 이미지를 읽어옵니다.
현재 저희 데이터셋의 마스크는 자음:1, 모음:2, 받침:3으로 라벨링이 되어있는데요.
이를 파이토치 모델에 넣기위해선 원핫인코딩을 해주어야합니다.
모듈을 사용할 수도 있는데, 해당 코드에선 그냥 반복문으로 구현하였습니다.
처음엔 데이터셋을 만들 때부터 원-핫 인코딩을 적용시켰는데, 그랬더니 넘파이 파일 크기가 너무 커져 데이터셋을 읽어오는데에 문제가 있었습니다 :)..
Training
이제 본격적으로 학습을 해봅시다
## 데이터셋 생성
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # imagenet
])
train_set = MyDataset(os.path.join(data_dir, "train"), transform=trans)
val_set = MyDataset(os.path.join(data_dir, "val"), transform=trans)
dataloaders = {
'train': DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0),
'val': DataLoader(val_set, batch_size=batch_size, shuffle=True, num_workers=0)
}학습을 시키기 위한 데이터셋을 가져옵니다.
입력이 이미지이거나 넘파이 형식일 경우 파이토치에서 사용하는 텐서로 바꾸어주기위해 transforms.ToTensor()를 적용해주어야합니다
(배열 순서와 값을 자동으로 텐서에 맞게 조정해줍니다.)
그후 nomalization 해주는 것까지 trans 함수로 함께 지정하여줍니다.
이렇게 만든 함수를 데이터셋에 넘기면 데이터를 가져오며 해당 함수를 적용시켜줍니다.
## 네트워크 생성
if mode=="FPN":
model = FPN(encoder_name=backbone,
decoder_pyramid_channels=256,
decoder_segmentation_channels=128,
classes=n_class,
dropout=0.3,
activation='softmax',
final_upsampling=4,
decoder_merge_policy='add')
## 네트워크 학습
model_trainer = Trainer(model=model, dataloaders=dataloaders, optimizer=optim.Adam,
lr=lr, batch_size=batch_size, num_epochs=num_epoch,
model_path=ckpt_dir, load_checkpoint=load_checkpoint)
model_trainer.start()네트워크를 initialize 한 후 학습을 합니다.
학습 관련 코드도 간단하게 살펴보겠습니다
def load_model(self, ckpt_name="best_model.pth"):
"""Loads full model state and basic training params"""
path = "/".join(ckpt_name.split("/")[:-1])
chkpt = torch.load(ckpt_name)
self.start_epoch = chkpt['epoch']
self.best_metric = chkpt['best_metric']
self.net.load_state_dict(chkpt['state_dict'])
self.optimizer.load_state_dict(chkpt['optimizer'])
self.optimizer.load_state_dict(chkpt['optimizer'])
logging.info("******** State loaded ********")학습이 중간에 끊어질 수도 있으니 이런 식으로 모델을 로드해서 사용할 수 있도록합시다
def forward(self, images, targets):
"""allocate data and runs forward pass through the network"""
# send all variables to selected device
images = images.to(self.device)
masks = targets.to(self.device)
# compute loss
outputs = self.net(images)
loss = self.criterion(outputs, masks)
return loss, outputsforward 함수입니다
모델에 인풋을 넣어 결과값을 받습니다.
loss는 BCEDiceLoss를 사용하였습니다.
이제 학습을 해봅시다!
실제 학습은 로컬에서 할 경우 너무 오래 걸리기때문에 코랩 혹은 gpu 서버에서 진행해주었습니다.
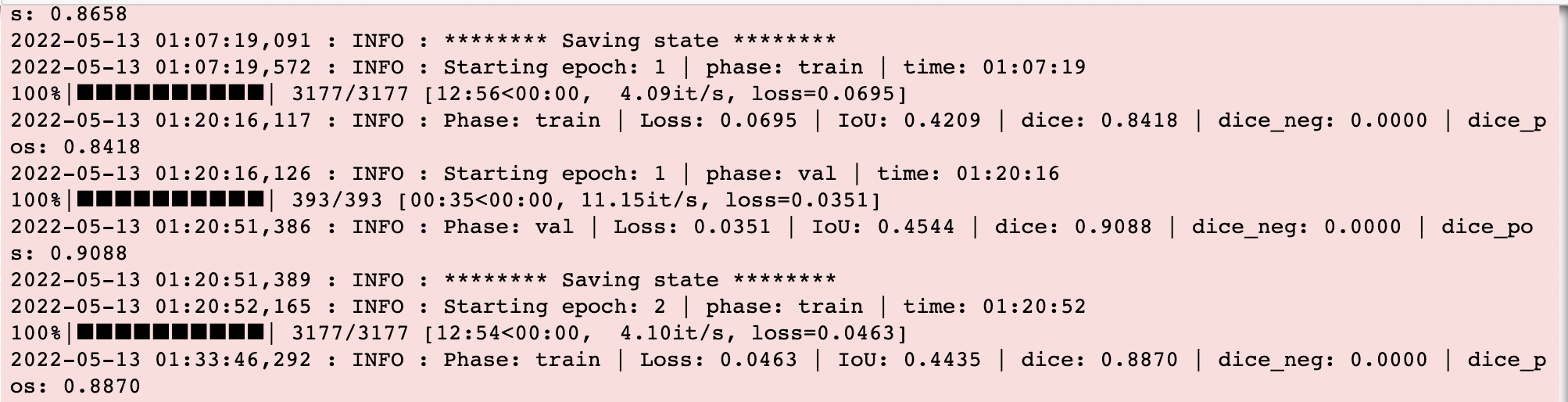
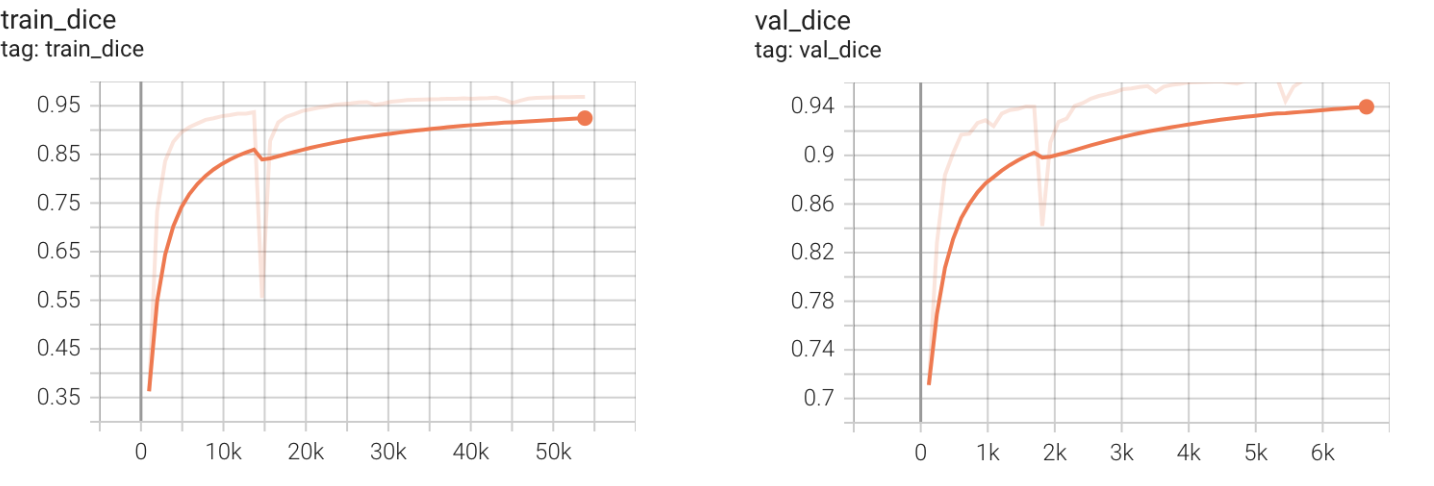
평가지표는 mdice와 mIoU를 사용하였습니다.
위에서 생성한 테스트 데이터셋에 대한 정확도는 다음과 같습니다
Prediction done in 38 sec.; IoU: 0.48227472603321075, Dice: 0.9645494520664216
(이상하게 iou가 유독 낮게 나오는데 당장 서비스에 적용해야하고, 추론 결과가 나쁘지않아 우선 사용하였습니다.)
Predict Sample Image
실제 손글씨 이미지를 모델에 넣고 확인해 보겠습니다
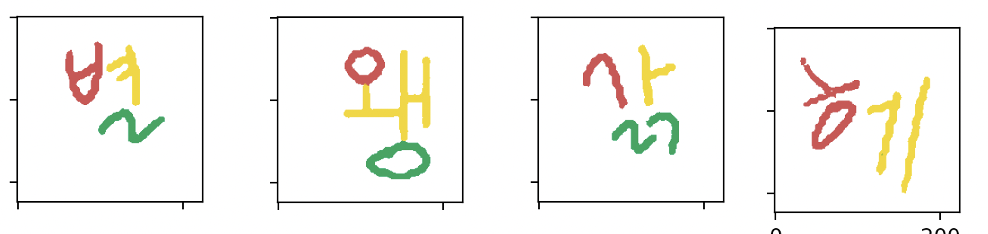
자음, 모음, 받침으로 분류된 것을 볼 수 있습니다!
참고로 U-NET 모델 결과는 아래와 같습니다

정확도도 그렇고 FPN이 더 개선된 것을 알 수 있습니다.
이렇게 FPN으로 segmentation을 해보았습니다. 😀


안녕하세요 FPN을 이용해 Project를 진행한 것에 대해 박수를 드립니다.
혹시 Dataset을 공유받을 수 있을까요?