참고자료
템플릿 원본 깃허브
https://github.com/victoresque/pytorch-template/tree/master/data_loader
템플릿 설명 관련 참고 자료
https://cow-coding.github.io/posts/day6_torch2/
Pytorch-Template 왜 필요할까?
1. 좀 더 체계적이고 생산적인 딥러닝 프로젝트 제작이 가능하다.
- Pytorch-Template를 이용하여 이런 여러가지 기능을 모듈화하여 체계적으로 관리할 수 있습니다.
- Pytorch-Template에서는 프로젝트를 새로 시작하기 위한 Project initialization을 제공합니다.
- CLI에서 사용하기 위한 기본 코드가 제공됩니다.(아주 좋소!)
배운점 1. cli로 관리하는 용이성
배운점 2. 체계적으로 관리하는 법을 템플릿을 통해 익히자!
2. 협업시 관리 용이성과, 통일성 있는 프로젝트 운영이 가능해진다.
사전에 같은 템플릿을 사용하기로 협의한다면, 다른 사람의 코드를 이해하기 쉽습니다.
마찬가지로 다른 사람의 코드를 내 프로젝트 템플릿에 이식하기 쉽습니다.
3. 한번 작성하면, 직접 코드를 들여다 볼 일이 줄어든다.(config.json을 이용한 manage)
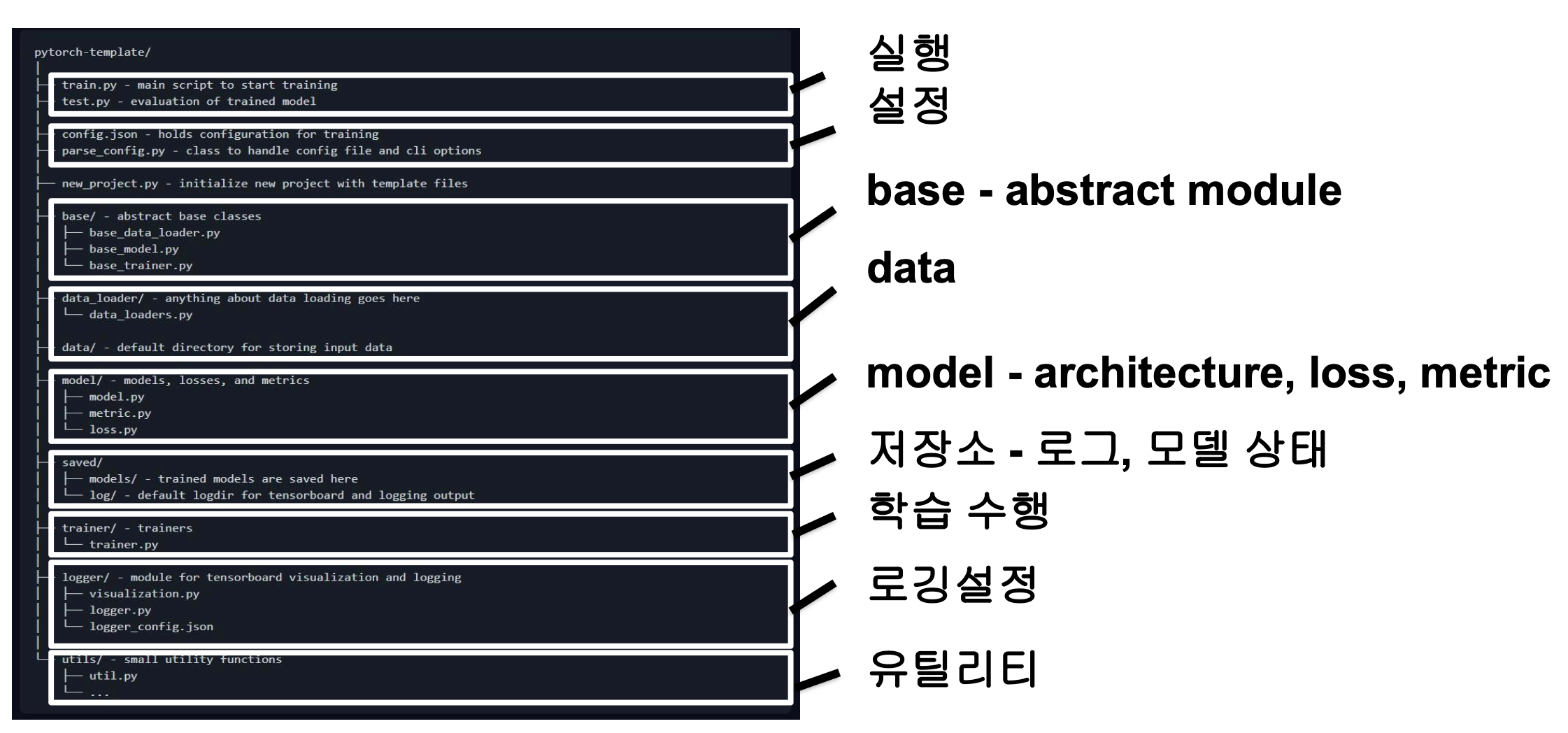
pytorch-template/
│ #실행
├── train.py - main script to start training
├── test.py - evaluation of trained model
│ #설정
├── config.json - holds configuration for training
├── parse_config.py - class to handle config file and cli options
│
├── new_project.py - initialize new project with template files
│ #데이터
├── base/ - abstract base classes
│ ├── base_data_loader.py
│ ├── base_model.py
│ └── base_trainer.py
│
├── data_loader/ - anything about data loading goes here
│ └── data_loaders.py
│
├── data/ - default directory for storing input data
│ #모델 - architecture, loss, metrics
├── model/ - models, losses, and metrics
│ ├── model.py
│ ├── metric.py
│ └── loss.py
│ #저장소
├── saved/
│ ├── models/ - trained models are saved here
│ └── log/ - default logdir for tensorboard and logging output
│
├── trainer/ - trainers
│ └── trainer.py
│
├── logger/ - module for tensorboard visualization and logging
│ ├── visualization.py
│ ├── logger.py
│ └── logger_config.json
│
└── utils/ - small utility functions
├── util.py
└── ...train.py
import argparse
import collections
import torch
import numpy as np
import data_loader.data_loaders as module_data
import model.loss as module_loss
import model.metric as module_metric
import model.model as module_arch
from parse_config import ConfigParser
from trainer import Trainer
from utils import prepare_device
# fix random seeds for reproducibility
SEED = 123
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(SEED)
def main(config):
logger = config.get_logger('train')
# setup data_loader instances
data_loader = config.init_obj('data_loader', module_data)
valid_data_loader = data_loader.split_validation()
# build model architecture, then print to console
model = config.init_obj('arch', module_arch)
logger.info(model)
# prepare for (multi-device) GPU training
device, device_ids = prepare_device(config['n_gpu'])
model = model.to(device)
if len(device_ids) > 1:
model = torch.nn.DataParallel(model, device_ids=device_ids)
# get function handles of loss and metrics
criterion = getattr(module_loss, config['loss'])
metrics = [getattr(module_metric, met) for met in config['metrics']]
# build optimizer, learning rate scheduler. delete every lines containing lr_scheduler for disabling scheduler
trainable_params = filter(lambda p: p.requires_grad, model.parameters())
optimizer = config.init_obj('optimizer', torch.optim, trainable_params)
lr_scheduler = config.init_obj('lr_scheduler', torch.optim.lr_scheduler, optimizer)
trainer = Trainer(model, criterion, metrics, optimizer,
config=config,
device=device,
data_loader=data_loader,
valid_data_loader=valid_data_loader,
lr_scheduler=lr_scheduler)
trainer.train()
if __name__ == '__main__':
args = argparse.ArgumentParser(description='PyTorch Template')
args.add_argument('-c', '--config', default=None, type=str,
help='config file path (default: None)')
args.add_argument('-r', '--resume', default=None, type=str,
help='path to latest checkpoint (default: None)')
args.add_argument('-d', '--device', default=None, type=str,
help='indices of GPUs to enable (default: all)')
# custom cli options to modify configuration from default values given in json file.
CustomArgs = collections.namedtuple('CustomArgs', 'flags type target')
options = [
CustomArgs(['--lr', '--learning_rate'], type=float, target='optimizer;args;lr'),
CustomArgs(['--bs', '--batch_size'], type=int, target='data_loader;args;batch_size')
]
config = ConfigParser.from_args(args, options)
main(config)step1. main함수를 보게 되면
if __name__ == '__main__':
args = argparse.ArgumentParser(description='PyTorch Template')
args.add_argument('-c', '--config', default=None, type=str,
help='config file path (default: None)')
args.add_argument('-r', '--resume', default=None, type=str,
help='path to latest checkpoint (default: None)')
args.add_argument('-d', '--device', default=None, type=str,
help='indices of GPUs to enable (default: all)')여기부터 확인하게 된다.
여긴 config.JSON 의 값을 읽게 된다.
config.json
{
"name": "Mnist_LeNet",
"n_gpu": 1,
"arch": {
"type": "MnistModel",
"args": {}
},
"data_loader": {
"type": "MnistDataLoader",
"args":{
"data_dir": "data/",
"batch_size": 128,
"shuffle": true,
"validation_split": 0.1,
"num_workers": 2
}
},
"optimizer": {
"type": "Adam",
"args":{
"lr": 0.001,
"weight_decay": 0,
"amsgrad": true
}
},
"loss": "nll_loss",
"metrics": [
"accuracy", "top_k_acc"
],
"lr_scheduler": {
"type": "StepLR",
"args": {
"step_size": 50,
"gamma": 0.1
}
},
"trainer": {
"epochs": 100,
"save_dir": "saved/",
"save_period": 1,
"verbosity": 2,
"monitor": "min val_loss",
"early_stop": 10,
"tensorboard": true
}
}
step2. configparser(parse_config에 있음)로 넘어가게 된다.
- configparser는 factory pattern방식임.-> class 및 객체 생성 함수
-__getitem__값을 출력? -> config을 쉽게 접근하게 됨 - self -> 결국 자기 자신을 불러오는 것 = config 파일을 불러오는 것!
configparser 클래스
class ConfigParser:
def __init__(self, config, resume=None, modification=None, run_id=None):
"""
class to parse configuration json file. Handles hyperparameters for training, initializations of modules, checkpoint saving
and logging module.
:param config: Dict containing configurations, hyperparameters for training. contents of `config.json` file for example.
:param resume: String, path to the checkpoint being loaded.
:param modification: Dict keychain:value, specifying position values to be replaced from config dict.
:param run_id: Unique Identifier for training processes. Used to save checkpoints and training log. Timestamp is being used as default
"""
# load config file and apply modification
self._config = _update_config(config, modification)
self.resume = resume
# set save_dir where trained model and log will be saved.
save_dir = Path(self.config['trainer']['save_dir'])
exper_name = self.config['name']
if run_id is None: # use timestamp as default run-id
run_id = datetime.now().strftime(r'%m%d_%H%M%S')
self._save_dir = save_dir / 'models' / exper_name / run_id
self._log_dir = save_dir / 'log' / exper_name / run_id
# make directory for saving checkpoints and log.
exist_ok = run_id == ''
self.save_dir.mkdir(parents=True, exist_ok=exist_ok)
self.log_dir.mkdir(parents=True, exist_ok=exist_ok)
# save updated config file to the checkpoint dir
write_json(self.config, self.save_dir / 'config.json')
# configure logging module
setup_logging(self.log_dir)
self.log_levels = {
0: logging.WARNING,
1: logging.INFO,
2: logging.DEBUG
}
@classmethod
def from_args(cls, args, options=''):
"""
Initialize this class from some cli arguments. Used in train, test.
"""
for opt in options:
args.add_argument(*opt.flags, default=None, type=opt.type)
if not isinstance(args, tuple):
args = args.parse_args()
if args.device is not None:
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
if args.resume is not None:
resume = Path(args.resume)
cfg_fname = resume.parent / 'config.json'
else:
msg_no_cfg = "Configuration file need to be specified. Add '-c config.json', for example."
assert args.config is not None, msg_no_cfg
resume = None
cfg_fname = Path(args.config)
config = read_json(cfg_fname)
if args.config and resume:
# update new config for fine-tuning
config.update(read_json(args.config))
# parse custom cli options into dictionary
modification = {opt.target : getattr(args, _get_opt_name(opt.flags)) for opt in options}
return cls(config, resume, modification)
def init_obj(self, name, module, *args, **kwargs):
"""
Finds a function handle with the name given as 'type' in config, and returns the
instance initialized with corresponding arguments given.
`object = config.init_obj('name', module, a, b=1)`
is equivalent to
`object = module.name(a, b=1)`
"""
module_name = self[name]['type']
module_args = dict(self[name]['args'])
assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
module_args.update(kwargs)
return getattr(module, module_name)(*args, **module_args)
def init_ftn(self, name, module, *args, **kwargs):
"""
Finds a function handle with the name given as 'type' in config, and returns the
function with given arguments fixed with functools.partial.
`function = config.init_ftn('name', module, a, b=1)`
is equivalent to
`function = lambda *args, **kwargs: module.name(a, *args, b=1, **kwargs)`.
"""
module_name = self[name]['type']
module_args = dict(self[name]['args'])
assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
module_args.update(kwargs)
return partial(getattr(module, module_name), *args, **module_args)
def __getitem__(self, name):
"""Access items like ordinary dict."""
return self.config[name]
def get_logger(self, name, verbosity=2):
msg_verbosity = 'verbosity option {} is invalid. Valid options are {}.'.format(verbosity, self.log_levels.keys())
assert verbosity in self.log_levels, msg_verbosity
logger = logging.getLogger(name)
logger.setLevel(self.log_levels[verbosity])
return logger
# setting read-only attributes
@property
def config(self):
return self._config
@property
def save_dir(self):
return self._save_dir
@property
def log_dir(self):
return self._log_dir
parse_config 전체 코드
import os
import logging
from pathlib import Path
from functools import reduce, partial
from operator import getitem
from datetime import datetime
from logger import setup_logging
from utils import read_json, write_json
class ConfigParser:
def __init__(self, config, resume=None, modification=None, run_id=None):
"""
class to parse configuration json file. Handles hyperparameters for training, initializations of modules, checkpoint saving
and logging module.
:param config: Dict containing configurations, hyperparameters for training. contents of `config.json` file for example.
:param resume: String, path to the checkpoint being loaded.
:param modification: Dict keychain:value, specifying position values to be replaced from config dict.
:param run_id: Unique Identifier for training processes. Used to save checkpoints and training log. Timestamp is being used as default
"""
# load config file and apply modification
self._config = _update_config(config, modification)
self.resume = resume
# set save_dir where trained model and log will be saved.
save_dir = Path(self.config['trainer']['save_dir'])
exper_name = self.config['name']
if run_id is None: # use timestamp as default run-id
run_id = datetime.now().strftime(r'%m%d_%H%M%S')
self._save_dir = save_dir / 'models' / exper_name / run_id
self._log_dir = save_dir / 'log' / exper_name / run_id
# make directory for saving checkpoints and log.
exist_ok = run_id == ''
self.save_dir.mkdir(parents=True, exist_ok=exist_ok)
self.log_dir.mkdir(parents=True, exist_ok=exist_ok)
# save updated config file to the checkpoint dir
write_json(self.config, self.save_dir / 'config.json')
# configure logging module
setup_logging(self.log_dir)
self.log_levels = {
0: logging.WARNING,
1: logging.INFO,
2: logging.DEBUG
}
@classmethod
def from_args(cls, args, options=''):
"""
Initialize this class from some cli arguments. Used in train, test.
"""
for opt in options:
args.add_argument(*opt.flags, default=None, type=opt.type)
if not isinstance(args, tuple):
args = args.parse_args()
if args.device is not None:
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
if args.resume is not None:
resume = Path(args.resume)
cfg_fname = resume.parent / 'config.json'
else:
msg_no_cfg = "Configuration file need to be specified. Add '-c config.json', for example."
assert args.config is not None, msg_no_cfg
resume = None
cfg_fname = Path(args.config)
config = read_json(cfg_fname)
if args.config and resume:
# update new config for fine-tuning
config.update(read_json(args.config))
# parse custom cli options into dictionary
modification = {opt.target : getattr(args, _get_opt_name(opt.flags)) for opt in options}
return cls(config, resume, modification)
def init_obj(self, name, module, *args, **kwargs):
"""
Finds a function handle with the name given as 'type' in config, and returns the
instance initialized with corresponding arguments given.
`object = config.init_obj('name', module, a, b=1)`
is equivalent to
`object = module.name(a, b=1)`
"""
module_name = self[name]['type']
module_args = dict(self[name]['args'])
assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
module_args.update(kwargs)
return getattr(module, module_name)(*args, **module_args)
def init_ftn(self, name, module, *args, **kwargs):
"""
Finds a function handle with the name given as 'type' in config, and returns the
function with given arguments fixed with functools.partial.
`function = config.init_ftn('name', module, a, b=1)`
is equivalent to
`function = lambda *args, **kwargs: module.name(a, *args, b=1, **kwargs)`.
"""
module_name = self[name]['type']
module_args = dict(self[name]['args'])
assert all([k not in module_args for k in kwargs]), 'Overwriting kwargs given in config file is not allowed'
module_args.update(kwargs)
return partial(getattr(module, module_name), *args, **module_args)
def __getitem__(self, name):
"""Access items like ordinary dict."""
return self.config[name]
def get_logger(self, name, verbosity=2):
msg_verbosity = 'verbosity option {} is invalid. Valid options are {}.'.format(verbosity, self.log_levels.keys())
assert verbosity in self.log_levels, msg_verbosity
logger = logging.getLogger(name)
logger.setLevel(self.log_levels[verbosity])
return logger
# setting read-only attributes
@property
def config(self):
return self._config
@property
def save_dir(self):
return self._save_dir
@property
def log_dir(self):
return self._log_dir
# helper functions to update config dict with custom cli options
def _update_config(config, modification):
if modification is None:
return config
for k, v in modification.items():
if v is not None:
_set_by_path(config, k, v)
return config
def _get_opt_name(flags):
for flg in flags:
if flg.startswith('--'):
return flg.replace('--', '')
return flags[0].replace('--', '')
def _set_by_path(tree, keys, value):
"""Set a value in a nested object in tree by sequence of keys."""
keys = keys.split(';')
_get_by_path(tree, keys[:-1])[keys[-1]] = value
def _get_by_path(tree, keys):
"""Access a nested object in tree by sequence of keys."""
return reduce(getitem, keys, tree)
test.py
import argparse
import torch
from tqdm import tqdm
import data_loader.data_loaders as module_data
import model.loss as module_loss
import model.metric as module_metric
import model.model as module_arch
from parse_config import ConfigParser
def main(config):
logger = config.get_logger('test')
# setup data_loader instances
data_loader = getattr(module_data, config['data_loader']['type'])(
config['data_loader']['args']['data_dir'],
batch_size=512,
shuffle=False,
validation_split=0.0,
training=False,
num_workers=2
)
# build model architecture
model = config.init_obj('arch', module_arch)
logger.info(model)
# get function handles of loss and metrics
loss_fn = getattr(module_loss, config['loss'])
metric_fns = [getattr(module_metric, met) for met in config['metrics']]
logger.info('Loading checkpoint: {} ...'.format(config.resume))
checkpoint = torch.load(config.resume)
state_dict = checkpoint['state_dict']
if config['n_gpu'] > 1:
model = torch.nn.DataParallel(model)
model.load_state_dict(state_dict)
# prepare model for testing
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
model.eval()
total_loss = 0.0
total_metrics = torch.zeros(len(metric_fns))
with torch.no_grad():
for i, (data, target) in enumerate(tqdm(data_loader)):
data, target = data.to(device), target.to(device)
output = model(data)
#
# save sample images, or do something with output here
#
# computing loss, metrics on test set
loss = loss_fn(output, target)
batch_size = data.shape[0]
total_loss += loss.item() * batch_size
for i, metric in enumerate(metric_fns):
total_metrics[i] += metric(output, target) * batch_size
n_samples = len(data_loader.sampler)
log = {'loss': total_loss / n_samples}
log.update({
met.__name__: total_metrics[i].item() / n_samples for i, met in enumerate(metric_fns)
})
logger.info(log)
if __name__ == '__main__':
args = argparse.ArgumentParser(description='PyTorch Template')
args.add_argument('-c', '--config', default=None, type=str,
help='config file path (default: None)')
args.add_argument('-r', '--resume', default=None, type=str,
help='path to latest checkpoint (default: None)')
args.add_argument('-d', '--device', default=None, type=str,
help='indices of GPUs to enable (default: all)')
config = ConfigParser.from_args(args)
main(config)trainer.py
import numpy as np
import torch
from torchvision.utils import make_grid
from base import BaseTrainer
from utils import inf_loop, MetricTracker
class Trainer(BaseTrainer):
"""
Trainer class
"""
def __init__(self, model, criterion, metric_ftns, optimizer, config, device,
data_loader, valid_data_loader=None, lr_scheduler=None, len_epoch=None):
super().__init__(model, criterion, metric_ftns, optimizer, config)
self.config = config
self.device = device
self.data_loader = data_loader
if len_epoch is None:
# epoch-based training
self.len_epoch = len(self.data_loader)
else:
# iteration-based training
self.data_loader = inf_loop(data_loader)
self.len_epoch = len_epoch
self.valid_data_loader = valid_data_loader
self.do_validation = self.valid_data_loader is not None
self.lr_scheduler = lr_scheduler
self.log_step = int(np.sqrt(data_loader.batch_size))
self.train_metrics = MetricTracker('loss', *[m.__name__ for m in self.metric_ftns], writer=self.writer)
self.valid_metrics = MetricTracker('loss', *[m.__name__ for m in self.metric_ftns], writer=self.writer)
def _train_epoch(self, epoch):
"""
Training logic for an epoch
:param epoch: Integer, current training epoch.
:return: A log that contains average loss and metric in this epoch.
"""
self.model.train()
self.train_metrics.reset()
for batch_idx, (data, target) in enumerate(self.data_loader):
data, target = data.to(self.device), target.to(self.device)
self.optimizer.zero_grad()
output = self.model(data)
loss = self.criterion(output, target)
loss.backward()
self.optimizer.step()
self.writer.set_step((epoch - 1) * self.len_epoch + batch_idx)
self.train_metrics.update('loss', loss.item())
for met in self.metric_ftns:
self.train_metrics.update(met.__name__, met(output, target))
if batch_idx % self.log_step == 0:
self.logger.debug('Train Epoch: {} {} Loss: {:.6f}'.format(
epoch,
self._progress(batch_idx),
loss.item()))
self.writer.add_image('input', make_grid(data.cpu(), nrow=8, normalize=True))
if batch_idx == self.len_epoch:
break
log = self.train_metrics.result()
if self.do_validation:
val_log = self._valid_epoch(epoch)
log.update(**{'val_'+k : v for k, v in val_log.items()})
if self.lr_scheduler is not None:
self.lr_scheduler.step()
return log
def _valid_epoch(self, epoch):
"""
Validate after training an epoch
:param epoch: Integer, current training epoch.
:return: A log that contains information about validation
"""
self.model.eval()
self.valid_metrics.reset()
with torch.no_grad():
for batch_idx, (data, target) in enumerate(self.valid_data_loader):
data, target = data.to(self.device), target.to(self.device)
output = self.model(data)
loss = self.criterion(output, target)
self.writer.set_step((epoch - 1) * len(self.valid_data_loader) + batch_idx, 'valid')
self.valid_metrics.update('loss', loss.item())
for met in self.metric_ftns:
self.valid_metrics.update(met.__name__, met(output, target))
self.writer.add_image('input', make_grid(data.cpu(), nrow=8, normalize=True))
# add histogram of model parameters to the tensorboard
for name, p in self.model.named_parameters():
self.writer.add_histogram(name, p, bins='auto')
return self.valid_metrics.result()
def _progress(self, batch_idx):
base = '[{}/{} ({:.0f}%)]'
if hasattr(self.data_loader, 'n_samples'):
current = batch_idx * self.data_loader.batch_size
total = self.data_loader.n_samples
else:
current = batch_idx
total = self.len_epoch
return base.format(current, total, 100.0 * current / total)
trainer는 base trainer라는 곳에서 기본을 가지고 있음.
base trainer.py
import torch
from abc import abstractmethod
from numpy import inf
from logger import TensorboardWriter
class BaseTrainer:
"""
Base class for all trainers
"""
def __init__(self, model, criterion, metric_ftns, optimizer, config):
self.config = config
self.logger = config.get_logger('trainer', config['trainer']['verbosity'])
self.model = model
self.criterion = criterion
self.metric_ftns = metric_ftns
self.optimizer = optimizer
cfg_trainer = config['trainer']
self.epochs = cfg_trainer['epochs']
self.save_period = cfg_trainer['save_period']
self.monitor = cfg_trainer.get('monitor', 'off')
# configuration to monitor model performance and save best
if self.monitor == 'off':
self.mnt_mode = 'off'
self.mnt_best = 0
else:
self.mnt_mode, self.mnt_metric = self.monitor.split()
assert self.mnt_mode in ['min', 'max']
self.mnt_best = inf if self.mnt_mode == 'min' else -inf
self.early_stop = cfg_trainer.get('early_stop', inf)
if self.early_stop <= 0:
self.early_stop = inf
self.start_epoch = 1
self.checkpoint_dir = config.save_dir
# setup visualization writer instance
self.writer = TensorboardWriter(config.log_dir, self.logger, cfg_trainer['tensorboard'])
if config.resume is not None:
self._resume_checkpoint(config.resume)
@abstractmethod
def _train_epoch(self, epoch):
"""
Training logic for an epoch
:param epoch: Current epoch number
"""
raise NotImplementedError
def train(self):
"""
Full training logic
"""
not_improved_count = 0
for epoch in range(self.start_epoch, self.epochs + 1):
result = self._train_epoch(epoch)
# save logged informations into log dict
log = {'epoch': epoch}
log.update(result)
# print logged informations to the screen
for key, value in log.items():
self.logger.info(' {:15s}: {}'.format(str(key), value))
# evaluate model performance according to configured metric, save best checkpoint as model_best
best = False
if self.mnt_mode != 'off':
try:
# check whether model performance improved or not, according to specified metric(mnt_metric)
improved = (self.mnt_mode == 'min' and log[self.mnt_metric] <= self.mnt_best) or \
(self.mnt_mode == 'max' and log[self.mnt_metric] >= self.mnt_best)
except KeyError:
self.logger.warning("Warning: Metric '{}' is not found. "
"Model performance monitoring is disabled.".format(self.mnt_metric))
self.mnt_mode = 'off'
improved = False
if improved:
self.mnt_best = log[self.mnt_metric]
not_improved_count = 0
best = True
else:
not_improved_count += 1
if not_improved_count > self.early_stop:
self.logger.info("Validation performance didn\'t improve for {} epochs. "
"Training stops.".format(self.early_stop))
break
if epoch % self.save_period == 0:
self._save_checkpoint(epoch, save_best=best)
def _save_checkpoint(self, epoch, save_best=False):
"""
Saving checkpoints
:param epoch: current epoch number
:param log: logging information of the epoch
:param save_best: if True, rename the saved checkpoint to 'model_best.pth'
"""
arch = type(self.model).__name__
state = {
'arch': arch,
'epoch': epoch,
'state_dict': self.model.state_dict(),
'optimizer': self.optimizer.state_dict(),
'monitor_best': self.mnt_best,
'config': self.config
}
filename = str(self.checkpoint_dir / 'checkpoint-epoch{}.pth'.format(epoch))
torch.save(state, filename)
self.logger.info("Saving checkpoint: {} ...".format(filename))
if save_best:
best_path = str(self.checkpoint_dir / 'model_best.pth')
torch.save(state, best_path)
self.logger.info("Saving current best: model_best.pth ...")
def _resume_checkpoint(self, resume_path):
"""
Resume from saved checkpoints
:param resume_path: Checkpoint path to be resumed
"""
resume_path = str(resume_path)
self.logger.info("Loading checkpoint: {} ...".format(resume_path))
checkpoint = torch.load(resume_path)
self.start_epoch = checkpoint['epoch'] + 1
self.mnt_best = checkpoint['monitor_best']
# load architecture params from checkpoint.
if checkpoint['config']['arch'] != self.config['arch']:
self.logger.warning("Warning: Architecture configuration given in config file is different from that of "
"checkpoint. This may yield an exception while state_dict is being loaded.")
self.model.load_state_dict(checkpoint['state_dict'])
# load optimizer state from checkpoint only when optimizer type is not changed.
if checkpoint['config']['optimizer']['type'] != self.config['optimizer']['type']:
self.logger.warning("Warning: Optimizer type given in config file is different from that of checkpoint. "
"Optimizer parameters not being resumed.")
else:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.logger.info("Checkpoint loaded. Resume training from epoch {}".format(self.start_epoch))

AI Engineer / 의료인공지능