Gradient 이해하기
🏖️ 딥러닝 기본 개념 정리
Tensor 클래스
Tensor는 다차원 배열로 구성된 데이터 구조.
d 차원으로 정렬된 숫자들을 포함한 객체로 생각할 수 있으며, 임의의 차원을 가질 수 있다.
생성 예시
x = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 1~6으로 채워진 2차원 텐서(크기 2x3)
y = torch.rand((3, 4)) # 0~1 사이의 임의 값으로 채워진 2차원 텐서(크기 3x4)
z = torch.zeros((1, 2, 3)) # 0으로 채워진 3차원 텐서(크기 1x2x3)x.shape 명령어를 통해 텐서의 크기를 확인할 수 있습니다. 예를 들어, 위의 x의 크기는 torch.Size([2, 3])이다.
텐서 연산
numpy와 비슷하게 다양한 연산을 지원하며, 직관적인 방식으로 사용할 수 있다:
z = x.mean() # x의 모든 원소들의 평균
z = x.sum() # x의 모든 원소들의 합
z = x + y # element-wise 덧셈
z = x @ y # 행렬곱 연산 (x는 N x M, y는 M x R 크기여야 함)함수명이 _로 끝나는 경우는 in-place 연산을 의미합니다. 예를 들어, x.add_(3)는 x에 3을 더하는 in-place 연산이다.
딥러닝과 Gradient Descent
연산 그래프 (Computational Graph)
딥러닝에서의 핵심은 gradient descent입니다. 텐서들의 연산 과정을 그래프로 나타낸 후, 최종 결과를 계산하는 방법을 역추적해 각 변수의 변화를 계산하는 방식입니다.
예를 들어:
x = torch.tensor([3.0], requires_grad=True)
y = torch.tensor([4.0], requires_grad=True)
z = x + y # tensor([7.], grad_fn=<AddBackward>)이때, z는 단순한 값뿐만 아니라 연산 그래프에 따라 z가 어떻게 계산되었는지 기록합니다. requires_grad=True 옵션을 사용하면 이 그래프에서 gradient를 계산할 수 있습니다.
그래디언트 계산
Gradient는 각 변수가 목적함수를 얼마나 변화시키는지를 나타냅니다. 연산 그래프를 통해 최종 결과까지 계산된 연산을 역추적하여 각 변수의 영향을 계산할 수 있습니다.
x = torch.tensor([5.0], requires_grad=True)
y = -1*(x**4) + 10*(x**3) + 10*(x**2) - 15*x - 4
y.backward() # dy/dx가 계산됨
print(x.grad) # tensor([335.])위의 예시에서 x=5인 순간 dy/dx는 335로 계산되며, 이는 x가 변화할 때 y가 얼마나 변하는지를 의미합니다.
복잡한 연산 예시
복잡한 연산에서도 마찬가지로 각 변수의 gradient를 구할 수 있습니다.
x1 = torch.tensor([1.0], requires_grad=True)
x2 = torch.tensor([2.0], requires_grad=True)
x3 = torch.tensor([3.0], requires_grad=True)
y = x1 * x2 * x3 * x3 + 7 * x1 * x2 - x2**2 - 4 * x1 * x3
y.backward()
print(x1.grad) # tensor([20.])
print(x2.grad) # tensor([12.])
print(x3.grad) # tensor([8.])Gradient Descent와 머신러닝
Gradient는 backward() 메서드를 통해 계산되며, 이를 이용해 선형 회귀 문제를 해결할 수 있습니다.
선형 회귀 예시
xs = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
ys = torch.tensor([3.0, 6.5, 5.0, 6.0, 8.0, 12.0])
a = torch.tensor([0.0], requires_grad=True)
b = torch.tensor([7.0], requires_grad=True)
y_pred = a * xs + b
err = ((ys - y_pred)**2).mean() # 평균 제곱 오차(MSE)backward()를 사용하여 gradient를 계산한 후, a와 b를 수정하여 오차를 줄이는 방향으로 값을 업데이트할 수 있습니다:
err.backward()
a.data.sub_(0.01 * a.grad)
b.data.sub_(0.01 * b.grad)반복 학습
이 과정을 반복하면서 점차 오차를 줄여나갈 수 있습니다:
for i in range(num_adjust):
y_pred = a * xs + b
err = ((y_pred - ys)**2).mean()
err.backward()
a.data.sub_(0.01 * a.grad)
b.data.sub_(0.01 * b.grad)
a.grad.zero_() # gradient 초기화
b.grad.zero_()조정 횟수가 증가함에 따라 err 값이 감소하고, 근사가 더욱 정확해집니다. 이 과정은 단순한 선형 회귀 뿐만 아니라 더 복잡한 모델에서도 유사하게 적용할 수 있습니다.
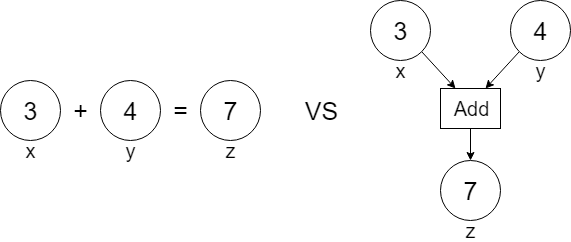
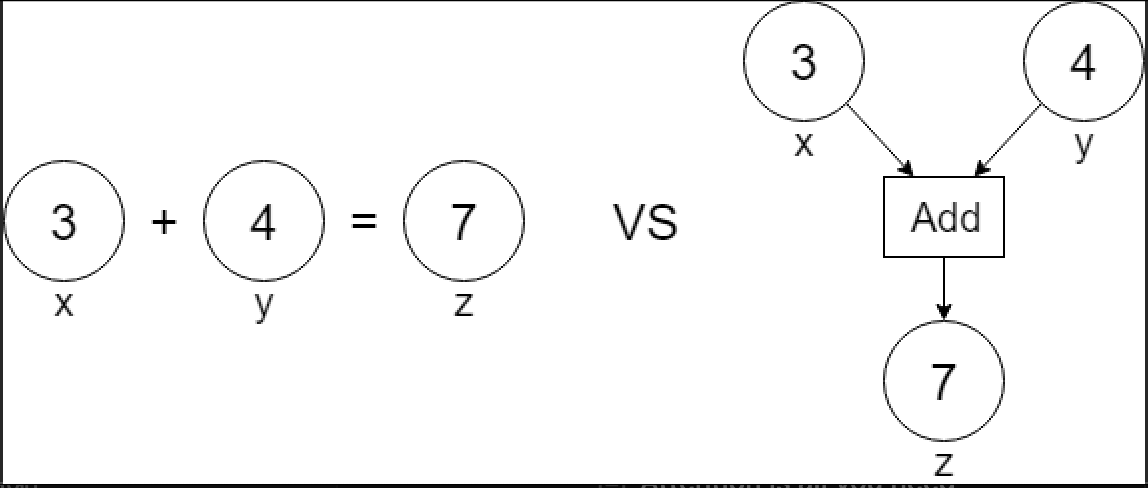
딥러닝에서 연산그래프가 중요한 이유(연산 그래프 VS 일반함수)
기존 함수와 딥러닝에서의 연산 방식에서 gradient 계산이 가능한 이유는 연산 그래프(Computational Graph)를 통해, 연산 과정이 단순한 수학적 계산을 넘어 어떻게 그 값에 도달했는지를 저장하고 추적할 수 있기 때문입니다.
일반적으로 코드를 작성할 때, z = x + y와 같은 코드에서 z는 단순히 값이 7인 상자로만 취급됩니다. 즉, 더하기 연산 이후에는 x와 y가 어떻게 더해졌는지, 또는 z가 어떻게 나왔는지에 대한 정보는 유지되지 않습니다.
그러나 딥러닝에서는 연산 그래프를 통해 각 연산의 흐름이 모두 기록됩니다. 위 그림의 오른쪽에서 볼 수 있듯이, 단순히 x와 y를 더해 z가 되는 것 이상의 정보가 남아 있습니다. 연산 그래프는 각 연산 단계에서 어떤 연산이 수행되었는지(여기서는 더하기)와 입력값이 무엇이었는지를 저장합니다. 이러한 정보는 나중에 backpropagation(역전파)를 수행할 때 미분(gradient) 값을 계산하는 데 사용됩니다.
그래디언트 계산을 가능하게 하는 핵심적인 메커니즘은 requires_grad=True 옵션입니다. 이를 통해 연산 그래프에서 각 변수의 gradient를 자동으로 추적할 수 있습니다. gradient는 목적 함수에 대한 변수가 얼마나 영향을 미치는지를 나타내며, 딥러닝의 핵심 알고리즘인 gradient descent에서 중요한 역할을 합니다.
요약하자면:
- 일반 함수는 단순히 결과값만 반환하고 그 값에 도달한 연산 과정은 저장하지 않음.
- 딥러닝의 연산 그래프는 각 연산의 흐름을 기록하여, 나중에 backpropagation을 통해 각 변수의 gradient를 계산할 수 있도록 함.
연산그래프와 일반 함수의 비교
연산 그래프(Computational Graph)와 함수(Function)의 차이는 어떻게 연산을 처리하고 저장하는지, 그리고 미분(gradient) 계산과 같은 추가 정보를 어떻게 제공하는지에서 크게 나뉩니다. 이 두 개념의 핵심 차이를 살펴보겠습니다.
1. 함수 (Function)
함수는 입력을 받아 출력 값을 반환하는 수학적 개념입니다. 프로그래밍에서 함수는 일반적으로 입력 값을 처리한 뒤 출력 결과를 제공합니다.
예시:
def add(x, y):
return x + y
z = add(3, 4) # z는 7위 예시에서는 함수 add가 두 개의 입력 x와 y를 받아 더한 결과를 반환합니다. 이때 z는 단순히 7이라는 값일 뿐, 더하기 연산이 어떻게 이루어졌는지에 대한 정보는 유지되지 않습니다. 즉, 함수는 연산 과정을 저장하지 않고, 최종 결과만을 반환합니다.
2. 연산 그래프 (Computational Graph)
연산 그래프는 연산 과정의 흐름을 기록하고, 각 단계에서 이루어진 연산을 모두 기억합니다. 단순히 결과만 계산하는 것이 아니라, 각 연산이 어떻게 이루어졌고, 어떤 변수를 통해 결과가 나왔는지에 대한 정보를 그래프 형태로 저장합니다. 이 정보는 역전파(backpropagation) 과정을 통해 미분(gradient) 값을 계산하는 데 사용됩니다.
예시:
import torch
x = torch.tensor([3.0], requires_grad=True)
y = torch.tensor([4.0], requires_grad=True)
z = x + y # tensor([7.], grad_fn=<AddBackward>)이 코드에서 연산 그래프는 z = x + y라는 더하기 연산이 이루어졌음을 기록하고, 이 정보를 grad_fn이라는 속성으로 저장합니다. z는 결과 값 7일 뿐만 아니라, 그 결과가 어떻게 만들어졌는지(연산 과정)를 기억하고 있습니다. 이러한 기록 덕분에 나중에 z.backward()를 호출하면, z를 계산하는 데 사용된 변수들(여기서는 x와 y)에 대해 미분(gradient)을 자동으로 계산할 수 있습니다.
3. 주요 차이점
| 구분 | 함수(Function) | 연산 그래프(Computational Graph) |
|---|---|---|
| 역추적 가능 여부 | 연산 과정이 저장되지 않음 | 연산 과정이 그래프로 기록되며, 역추적 가능 |
| 미분(gradient) 계산 | 미분 계산 불가능 | 그래프를 통해 미분 계산 가능 (역전파) |
| 저장된 정보 | 입력과 출력 값만 저장 | 연산 과정과 그에 따른 연산 노드, 변수 간의 관계 저장 |
| 용도 | 단순히 연산을 처리하고 결과를 반환 | 연산 과정을 기록하고, 미분 계산과 최적화에 사용 |
| 응용 분야 | 수학적 계산, 일반적 프로그래밍 | 딥러닝, 최적화 알고리즘에서 사용 |
연산그래프 작동원리 및 정의
연산 그래프(Computational Graph)는 복잡한 수학적 연산을 여러 단계로 나누어 표현하는 구조로, 딥러닝에서 매우 중요한 역할을 합니다. 이를 통해 미분(gradient)을 효율적으로 계산하고, 모델의 학습을 가능하게 합니다. 연산 그래프는 특히 역전파(backpropagation)를 통해 각 변수에 대한 미분을 계산할 때 그 진가를 발휘합니다.
1. 연산 그래프의 기본 개념
연산 그래프는 노드(node)와 엣지(edge)로 이루어진 그래프입니다.
- 노드(node): 변수 또는 연산을 나타냅니다. 예를 들어, 숫자나 변수(입력값) 또는 더하기, 곱하기와 같은 연산이 노드로 표현됩니다.
- 엣지(edge): 연산의 입력과 출력을 연결하는 선입니다. 이 선을 따라 값들이 이동하며 연산이 이루어집니다.
이러한 그래프에서 입력 값이 들어와 연산을 거쳐 출력 값이 만들어지는 과정을 시각적으로 표현합니다. 이를 통해 최종 출력이 어떻게 계산되었는지 기록할 수 있고, 나중에 이 기록을 통해 미분을 구할 수 있습니다.
2. 연산 그래프의 동작 원리
2.1 순전파 (Forward Propagation)
먼저, 연산 그래프에서 순전파는 입력 값에서 시작해 각 연산을 거쳐 최종 출력을 계산하는 과정입니다. 순전파는 딥러닝의 예측 단계와 관련이 있습니다. 아래 예를 들어보겠습니다:
예시:
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
z = x * y + 5위 코드에서 연산 그래프는 다음과 같은 순서로 계산됩니다:
1. x와 y가 입력되고, 두 값이 곱해져 새로운 값이 만들어집니다 (x * y = 6).
2. 이후 6에 5를 더해 최종 값인 11이 출력됩니다.
이 과정을 그래프로 나타내면 다음과 같이 표현할 수 있습니다:
x ---- * ----> (x * y) ---- + ----> z
y ---- + 5 ----> 11이러한 연산 흐름이 순전파입니다. 중요한 점은 연산 결과뿐만 아니라 각 연산이 어떻게 이루어졌는지가 그래프에 기록된다는 것입니다.
2.2 역전파 (Backpropagation)
역전파는 딥러닝에서 매우 중요한 과정으로, 순전파의 결과를 바탕으로 각 변수에 대한 미분(gradient)을 계산합니다. 역전파는 최종 출력에서 시작해 연산 그래프를 거꾸로 거슬러 올라가며 미분을 계산하는 방식입니다.
미분 계산:
미분(gradient)은 입력 변수가 목적 함수(예: 손실 함수)를 얼마나 변화시키는지를 나타냅니다. 역전파를 통해 목적 함수에 대한 변수들의 기여도를 계산할 수 있으며, 이를 이용해 경사 하강법으로 모델의 파라미터를 업데이트합니다.
3. 연산 그래프에서의 역전파 과정
역전파를 이해하기 위해, 예시에서 연산 그래프를 다시 보겠습니다.
예시:
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
z = x * y + 5이 예시의 역전파 과정은 다음과 같습니다:
1. z = x * y + 5 에서 z는 최종 출력 값이며, z는 x와 y의 연산 결과입니다. 이때 우리는 z를 목적 함수로 보고, z에 대해 x와 y의 미분을 계산할 수 있습니다.
-
dz/dx는 z가 x에 얼마나 의존하는지를 나타내며, dz/dy는 z가 y에 얼마나 의존하는지를 나타냅니다. z는
x * y + 5로 계산되었으므로, 이를 미분하면 다음과 같습니다:- dz/dx = y (곱셈의 미분 규칙에 따라)
- dz/dy = x
-
이제 역전파를 통해 미분 값을 계산할 수 있습니다:
z.backward() print(x.grad) # tensor([3.0]), dz/dx 값 print(y.grad) # tensor([2.0]), dz/dy 값 -
backward()함수는 그래프를 따라 역으로 이동하며 각 변수에 대한 미분을 계산합니다.
4. 연산 그래프와 역전파의 관계
연산 그래프는 모든 연산을 기록하고, 역전파를 수행할 때 이 기록된 정보를 사용해 미분을 계산합니다. 특히 딥러닝에서 중요한 것은, 연산 그래프가 각 연산의 관계를 기록하고 있기 때문에, 최종 목적 함수(손실 함수)까지의 미분 값을 한꺼번에 계산할 수 있다는 점입니다.
역전파 과정에서 각 노드에서 수행되는 미분 계산은 연쇄 법칙(Chain Rule)을 따릅니다. 연쇄 법칙이란, 복합 함수의 미분을 계산할 때 각 부분의 미분을 곱하는 방법을 말합니다.
예시: Chain Rule 적용
만약 z = f(g(x))라면, z를 x로 미분할 때는 f와 g의 미분을 연쇄적으로 적용하여 계산합니다:
dz/dx = (df/dg) * (dg/dx)이 법칙에 따라 연산 그래프에서의 역전파가 효율적으로 미분을 계산할 수 있습니다.
5. 연산 그래프의 주요 특징
- 자동 미분: 연산 그래프는 모든 연산을 자동으로 기록하고, 역전파를 통해 자동으로 미분을 계산합니다. 이로 인해 복잡한 연산도 쉽게 미분을 계산할 수 있습니다.
- 효율적인 계산: 연산 그래프는 미분을 효율적으로 계산할 수 있도록 설계되어 있어, 딥러닝에서 매우 중요한 최적화 작업이 가능합니다.
- 연쇄 법칙 적용: 연쇄 법칙을 사용하여 각 노드에서 미분 값을 차례로 계산하고, 그래프 전체의 미분 값을 구할 수 있습니다.
6. 연산 그래프의 응용
- 딥러닝 모델 학습: 연산 그래프를 통해 손실 함수에 대한 각 파라미터의 미분을 계산하고, 이 미분 값을 이용해 파라미터를 업데이트합니다. 이를 통해 모델의 학습이 이루어집니다.
- 최적화 문제 해결: 연산 그래프는 최적화 문제를 풀기 위해 변수를 효율적으로 조정하는 데 사용됩니다.
🏖️ 경사 하강법(Gradient Descent) 역전파(Backpropagation)의 연관성
그래디언트(Gradient)
그래디언트(Gradient)는 미분 값을 의미한다.
구체적으로, 어떤 함수의 입력값이 변할 때 출력값이 얼마나 변화하는지를 나타낸다.
딥러닝에서는 주로 손실 함수(Loss function)의 출력값이 파라미터(가중치)에 따라 얼마나 변화하는지를 측정한다.
이는 주로 다변수 함수에서 사용되며, 각 파라미터에 대한 편미분 값을 모은 벡터가 바로 그래디언트다.
예시
- 함수 `y = f(x)`에서, **dy/dx**는 `x`가 변할 때 `y`가 얼마나 변화하는지 나타낸다.
- 딥러닝에서, `L(θ)`는 **<span style="color:#f08080">손실 함수(Loss function)</span>**이고, `θ`는 모델의 파라미터다.
**dL/dθ**는 `θ`(가중치 또는 파라미터)가 변할 때 **손실**이 얼마나 변하는지를 의미한다.- 그래디언트는 파라미터를 얼마나 변화시켜야 할지를 결정할 수 있게 해준다.
- 경사 하강법에서 이 그래디언트를 사용하여 모델의 파라미터를 업데이트한다.
경사 하강법(Gradient Descent)
: 경사 하강법은 최적화 알고리즘이다.
딥러닝 모델의 파라미터를 업데이트하여 손실 함수의 값(즉, 모델의 오차)을 최소화하는 방법이다.
경사 하강법의 원리
1. 손실 함수(Loss function)는 종종 곡선이나 다차원 곡면처럼 생겼다.
2. 그래디언트는 그 곡면의 기울기를 나타낸다.
3. 경사 하강법은 그래디언트를 계산하고, 그 그래디언트의 방향과 반대 방향(기울기가 낮아지는 방향)으로 파라미터를 조정한다.업데이트 식
파라미터(θ)를 경사 하강법으로 업데이트하는 식은 다음과 같다:
= - *
- gradient는 손실 함수에 대한 파라미터의 미분 값이다.
- learning rate는 학습 속도를 조절하는 값이다.
이 방식으로 파라미터를 조금씩 업데이트하여 손실 값을 줄여 나간다.
예시
# 경사 하강법에서 파라미터를 업데이트
a = a - learning_rate * a_grad # a_grad는 손실 함수에 대한 a의 그래디언트
b = b - learning_rate * b_grad # b_grad는 손실 함수에 대한 b의 그래디언트역전파(Backpropagation)
: 역전파(Backpropagation)는 딥러닝에서 그래디언트를 효율적으로 계산하는 알고리즘이다.
즉, 역전파는 각 파라미터에 대한 그래디언트를 구하는 과정이다.
역전파의 핵심 원리
1. 먼저, 순전파(Forward Propagation)를 통해 입력 데이터를 모델에 넣고, 예측 값을 계산한다.
2. 예측 값과 실제 값의 차이로 손실 함수를 계산한다.
3. 이후, 역전파가 시작된다. 역전파는 연산 그래프를 거꾸로 거슬러 올라가며, 각 파라미터에 대한 손실 함수의 그래디언트(미분 값)를 계산한다.
각 노드에서 연쇄 법칙(Chain Rule)을 사용하여 이전 단계에서의 기여도를 기반으로 미분을 계산한다.
연쇄체인이란?
벨로그에서는 LaTeX 수식이 깨질 수 있으므로, 텍스트로 수식을 표현하는 방식으로 수정하겠습니다. 이렇게 하면 수식이 깨지지 않고 잘 보일 것입니다.
연쇄 법칙(Chain Rule)이란?
연쇄 법칙(Chain Rule)은 복합 함수의 미분을 계산할 때 사용하는 규칙이다.
즉, 어떤 함수가 다른 함수의 함수로 구성되어 있을 때, 그 함수의 미분을 구하는 방식이다.
딥러닝에서 연쇄 법칙은 역전파 과정에서 각 노드에서 손실에 대한 기여도를 계산하는 데 사용된다.
연쇄 법칙의 수학적 정의
함수 f(g(x))가 있을 때, 이 복합 함수의 미분은 다음과 같이 계산할 수 있다:
d(f(g(x)))/dx = f'(g(x)) * g'(x)즉, 외부 함수의 미분에 내부 함수의 미분을 곱하는 방식으로 계산한다.
예시
함수 y = (2x + 3)^2의 미분을 구한다고 생각해보자.
이 함수는 두 함수로 나눌 수 있다:
- 외부 함수:
f(u) = u^2 - 내부 함수:
g(x) = 2x + 3
이제 연쇄 법칙을 적용하면:
dy/dx = f'(g(x)) * g'(x)- 먼저, 내부 함수
g(x) = 2x + 3의 미분을 구한다:
g'(x) = 2- 그다음, 외부 함수
f(u) = u^2의 미분을 구한다:
f'(u) = 2u- 이제 내부 함수 값을 외부 함수에 대입하고, 두 미분을 곱한다:
dy/dx = 2 * (2x + 3) * 2 = 4 * (2x + 3)딥러닝에서의 연쇄 법칙
딥러닝에서는 여러 층으로 구성된 신경망을 거친 출력 값이 손실 함수로 전달되고, 이를 역전파하여 각 파라미터에 대한 기여도를 계산한다.
연쇄 법칙을 이용해 각 층에서의 미분 값을 차례차례 계산하며, 이를 거꾸로 전파하는 과정이 바로 역전파이다.
딥러닝 예시
딥러닝 모델에서 연쇄 법칙을 적용하는 방식을 간단한 예로 설명하겠다.
예를 들어, 2층 신경망에서 입력 x를 받아 첫 번째 층에서 가중치 w_1와 곱해지고, 두 번째 층에서 가중치 w_2와 곱해진다고 하자:
- 출력
y = w_2 * (w_1 * x)
여기서, 손실 함수 L에 대한 가중치 w_1와 가중치 w_2의 그래디언트를 구하려면 연쇄 법칙을 사용한다.
- 먼저, 출력
y에 대한 손실 함수의 미분을 구한다:
dL/dy- 그런 다음, 가중치
w_2에 대한 미분을 구한다:
dy/dw_2 = w_1 * x- 마지막으로, 가중치
w_1에 대한 미분은 다음과 같이 계산된다:
dy/dw_1 = w_2 * x이를 통해 각 가중치가 손실에 얼마나 기여했는지 계산한 후, 경사 하강법을 통해 가중치를 업데이트할 수 있다.
이처럼 연쇄 법칙은 딥러닝에서 여러 층의 파라미터를 효율적으로 학습시키는 데 핵심적인 역할을 한다.
정리!
- 그래디언트(Gradient): 각 파라미터가 손실 함수에 얼마나 영향을 미치는지를 나타내는것
- 경사 하강법(Gradient Descent): 그래디언트를 사용하여 파라미터를 업데이트하는 알고리즘
- 역전파(Backpropagation): 경사 하강법에 필요한 그래디언트를 계산하는 과정
참고자료
