☑️ 인덱스란?
원하는 데이터를 빠르게 찾는다
책의 목차처럼, 데이터를 빠르게 찾을 수 있도록 도와주는 역할을 한다.
☑️ 인덱스가 필요한 이유
✅ 인덱스가 없을 때 (Full Table Scan)
도서관에 책 10,000권이 있다. 이 중에서 Harry Potter라는 책을 찾으려면, 사서가 책장 1번부터 마지막까지 모든 책을 하나씩 뒤져야 한다. (시간 복잡도 O(N))
✅ 인덱스가 있을 때 (Index Table Scan)
이때 만약 책마다 제목순으로 정리된 카드 목차(index)가 있다면, 목차에서 Harry Potter라는 제목을 검색하고, 그 책이 위치한 서가 번호를 바로 확인한다. (인덱스는 트리구조이므로 시간 복잡도는 O(log N))
☑️ 클러스터에 따른 인덱스의 종류
✅ 클러스터링 인덱스

- 데이터가 물리적으로 정렬된 방식으로 저장된다. → 인덱스의 순서에 따라 데이터가 실제로 디스크에 저장되는 구조
- 각 테이블에 하나만 존재할 수 있다.
- InnoDB에서 Primary Key가 클러스터링된 인덱스로 구현된다.
- Primary Key가 없다면?
첫 번째 UNIQUE 인덱스 중에서 모든 키 컬럼이 NOT NULL로 정의된 인덱스를 클러스터형 인덱스로 사용한다. 만약 테이블에 기본 키나 적절한 유니크 인덱스가 없다면, InnoDB는 GEN_CLUST_INDEX라는 숨겨진 클러스터형 인덱스를 생성한다. 이 인덱스는 행 ID 값을 포함하는 가상의 컬럼을 사용한다. 이 컬럼은 InnoDB가 할당한 행 ID 값을 사용하여 행들을 정렬한다. (참고 : Mysql Documentation)
- Primary Key가 없다면?
- 속도
데이터가 인덱스의 순서대로 저장되므로, 데이터 검색이 더 효율적일 수 있다.
범위 검색 및 정렬 작업에서 성능이 좋다. (BETWEEN,>,<와 같은 범위 쿼리에서는 효율적)
클러스터링 인덱스는 데이터 삽입 시 정렬을 유지해야 하므로, 자주 삽입/삭제가 발생하는 테이블에서는 성능 저하가 있을 수 있다. 따라서 데이터 읽기가 많은 테이블에 적합하다.
✅ 논 클러스터링 인덱스

- 인덱스와 실제 데이터가 별도로 저장되며, 인덱스는 데이터가 저장된 위치를 참조한다.
- 여러 개의 비클러스터링된 인덱스를 생성할 수 있다.
- MyISAM 스토리지 엔진에서 사용된다.
- 유니크, 유니크한 인덱스, 디폴트 인덱스를 생성하면 온 클러스터링 인덱스가 생성된다.
- 별도의 인덱스 페이지 생성 → 추가 공간 필요
- 속도
특정 값에 대한 검색 속도는 인덱스가 있기 때문에 빠르지만, 범위 검색이나 정렬 작업에서는 추가적인 I/O 작업이 필요합니다. 인덱스가 실제 데이터를 가리키는 포인터만 가지고 있기 때문에, 실제 데이터를 찾기 위해 두 번의 조회가 필요할 수 있다.
논 클러스터링 인덱스는 실제 데이터를 별도의 인덱스 페이지로 분리하여 저장하기 때문에, 데이터 수정(insert, update, delete)이 자주 발생하는 테이블에 유리하다.
☑️ 예시
1. 테이블 생성하기
CREATE TABLE users (
id INT,
email VARCHAR(255)
); 다음과 같은 테이블을 만들었다면, 아무런 인덱스가 생기지 않을 것이다.

테이블에 이러한 순서로 데이터가 추가 되었다고 가정한다.
2. PK 제약조건 추가 (클러스터링 인덱스 생성)
ALTER TABLE users
ADD PRIMARY KEY (id);id를 PK로 설정하면 클러스터링 인덱스가 생성된다.
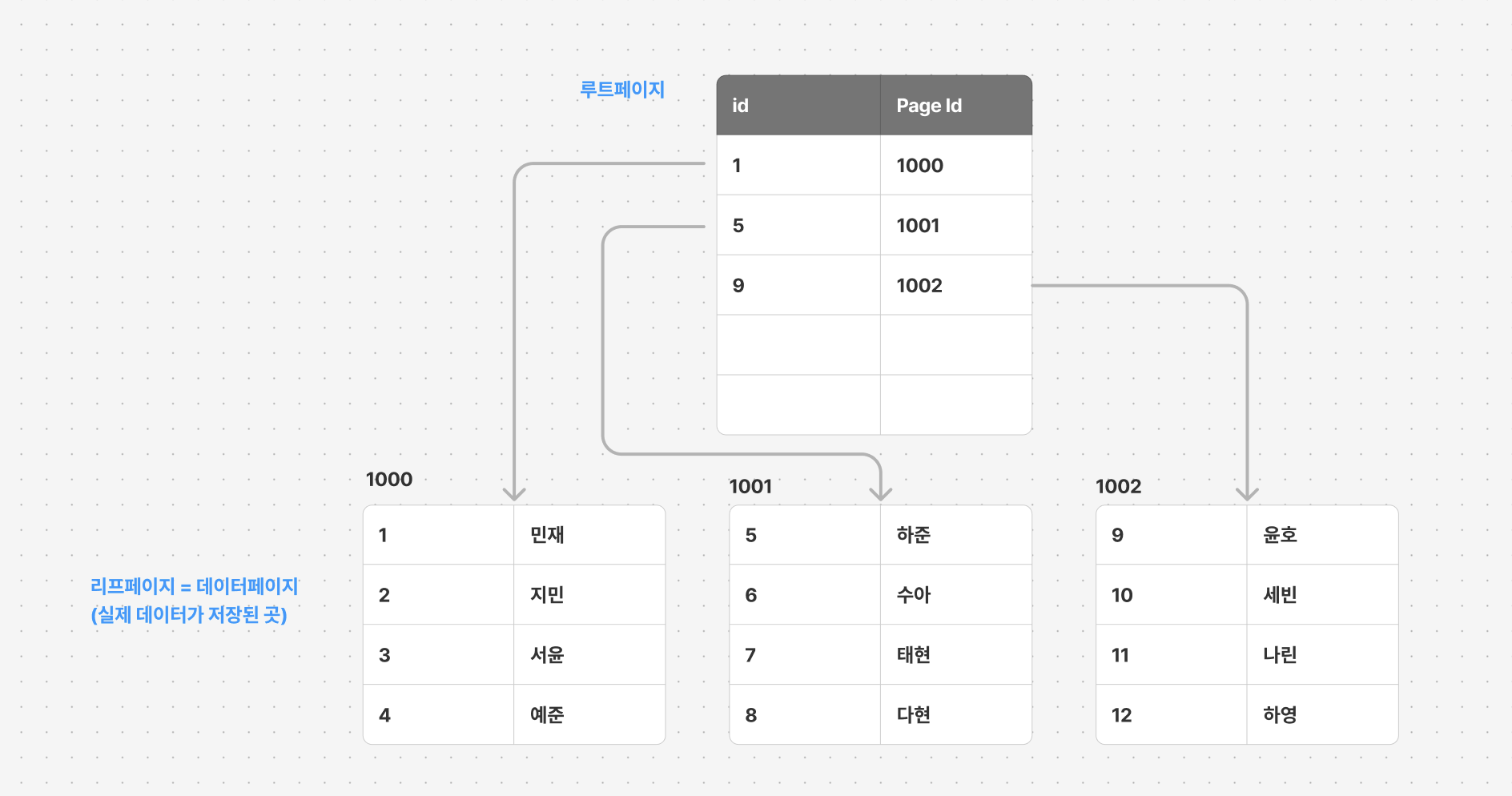
id의 순서에 따라 실제로 데이터가 정렬된다.
3. 유니크 제약조건 추가 (논 클러스터링 인덱스 생성)
ALTER TABLE users
ADD CONSTRAINT unique_name UNIQUE (name);name 칼럼을 유니크로 지정하면 논 클러스터링 인덱스가 생성된다.

그럼 별도의 인덱스 페이지가 생성되고, 테이블에 저장된 데이터는 그대로 인덱스 순서와 상관없이 물리적으로 저장된다.
실제 데이터의 위치(포인터)만 저장하기 때문에, 데이터를 조회할 때 인덱스를 통해 첫 번째 검색을 하고, 이후 포인터를 사용해 실제 데이터를 두 번째로 조회해야 한다. → 두 번의 조회 발생
☑️ 언제 인덱스를 사용할까?
- 자주 검색하거나 조회하는 컬럼
WHERE,JOIN,GROUP BY,ORDER BY에 자주 사용되는 컬럼 (조건절이 없다면 인덱스가 사용되지 않는다)
- INSERT, UPDATE, DELETE 가 자주 발생하지 않는 칼럼
- 유니크한 값이 많을 때
- 고객 ID, 주민등록번호처럼 고유한 값이 많은 컬럼
- 대규모 데이터셋
☑️ 참고
[10분 테코톡] 라라, 제로의 데이터베이스 인덱스
[MySQL] 클러스터드 인덱스와 private key가 존재하지 않는 테이블

진짜를 알면 곁가지를 몰라도 된다