
1969 DNA
문제
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오티드의 첫글자를 따서 표현한다. 만약에 Thymine-Adenine-Adenine-Cytosine-Thymine-Guanine-Cytosine-Cytosine-Guanine-Adenine-Thymine로 이루어진 DNA가 있다고 하면, “TAACTGCCGAT”로 표현할 수 있다. 그리고 Hamming Distance란 길이가 같은 두 DNA가 있을 때, 각 위치의 뉴클오티드 문자가 다른 것의 개수이다. 만약에 “AGCAT"와 ”GGAAT"는 첫 번째 글자와 세 번째 글자가 다르므로 Hamming Distance는 2이다.
우리가 할 일은 다음과 같다. N개의 길이 M인 DNA s1, s2, ..., sn가 주어져 있을 때 Hamming Distance의 합이 가장 작은 DNA s를 구하는 것이다. 즉, s와 s1의 Hamming Distance + s와 s2의 Hamming Distance + s와 s3의 Hamming Distance ... 의 합이 최소가 된다는 의미이다.
입력
첫 줄에 DNA의 수 N과 문자열의 길이 M이 주어진다. 그리고 둘째 줄부터 N+1번째 줄까지 N개의 DNA가 주어진다. N은 1,000보다 작거나 같은 자연수이고, M은 50보다 작거나 같은 자연수이다.
출력
첫째 줄에 Hamming Distance의 합이 가장 작은 DNA 를 출력하고, 둘째 줄에는 그 Hamming Distance의 합을 출력하시오. 그러한 DNA가 여러 개 있을 때에는 사전순으로 가장 앞서는 것을 출력한다.
예제 입력 1
5 8
TATGATAC
TAAGCTAC
AAAGATCC
TGAGATAC
TAAGATGT
예제 출력 1
TAAGATAC
7
예제 입력 2
4 10
ACGTACGTAC
CCGTACGTAG
GCGTACGTAT
TCGTACGTAA
예제 출력 2
ACGTACGTAA
6풀이 과정
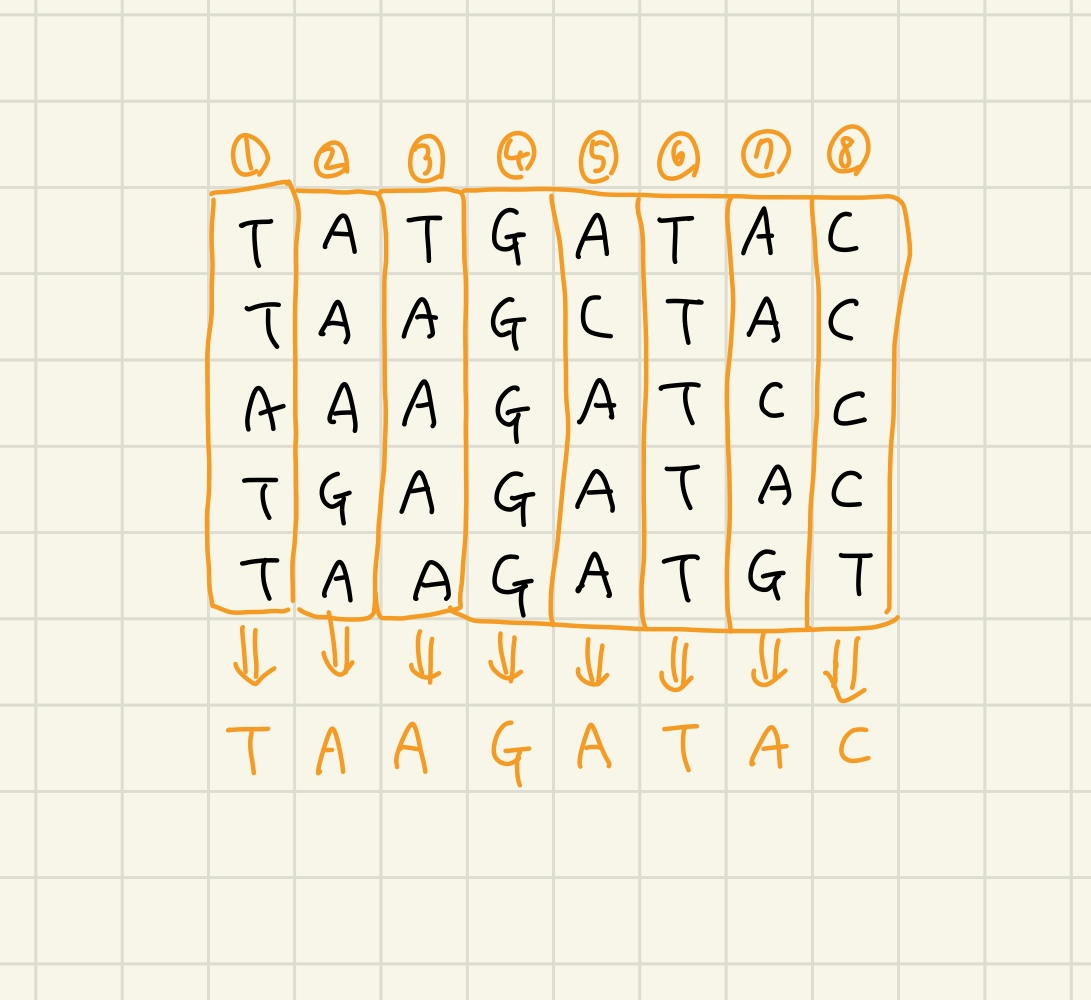
일단 Hamming Distance의 합이 가장 작은 DNA가 하나가 아닌 수 있으므로 dna를 사전 순으로 리스트에 넣었다.
주어진 dna들의 첫번째 값들부터 마지막 값들까지 검사한다.
- 값이 a라면
a_count +=1 - 값이 c라면
c_count +=1 - 값이 g라면
g_count +=1 - 값이 t라면
t_count +=1
가장 count 가 큰 dna를 채택한다.
선택된 dna와 입력값을 비교하여 다르면 hamming_distance 값을 증가시킨다.
선택된 dna와 hamming_distance 값 출력
코드
n, m = map(int, input().split())
list = []
s=''
dna = ['A', 'C', 'G', 'T']
hamming_distance = 0
for i in range(n):
data = input()
list.append(data)
for i in range(m):
a_count, c_count , g_count, t_count = 0,0,0,0
for j in range(n):
if list[j][i]==dna[0]:
a_count += 1
elif list[j][i]==dna[1]:
c_count += 1
elif list[j][i]==dna[2]:
g_count += 1
elif list[j][i]==dna[3]:
t_count += 1
count_list = [a_count, c_count, g_count, t_count]
selected_dna = dna[count_list.index(max(count_list))]
s+=selected_dna
for k in range(n):
if list[k][i]!= selected_dna:
hamming_distance += 1
print(s)
print(hamming_distance)