
⭐ HashMap은 어떻게 동작할까?
아이템11을 이해하기 위해서는 HashMap의 동작원리에 대해 알아야 한다.
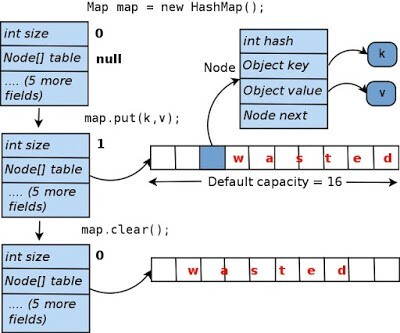
HashMap은 데이터를 담는 공간 버킷 배열(크기 16이고 나중에 필요하다면 늘림)로 만들어져 있다. 그리고 버킷에 Node 들이 LinkedList로 연결되어 있다.
그럼 HashMap에 put()을 하면 어떤 동작을 할까?
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // 1. map에 처음으로 값을 넣는 경우
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 2. 해당 인덱스 버킷에 처음 들어가는 값일 경우 해당 버킷에 Node를 추가.
tab[i] = newNode(hash, key, value, null);
else { // 3. 해당 인덱스 버킷이 null이 아닐 경우
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
...
}put()은 putVal()를 호출한다.
3번 과정 안에 있는 if문 조건문은
(hash가 같아야 함) and {(둘의 Key 참조가 같음) or (equals가 같음)}
이므로
hash가 같아야 하고, equals 비교 했을 때 true -> 같은 식별자
hash가 같아야 하고, == 비교 했을 때 true -> 같은 식별자
라는 말이다.
PhoneNumber number1 = new PhoneNumber(123, 456, 7890);
PhoneNumber number2 = new PhoneNumber(123, 456, 7890);
map.put(number1, 1);
map.put(number2, 2); //이때
만약에 PhoneNumber 객체 number1을 만들어서 HashMap에 put() 해놨다고 가정하자.
이후에 number1과 논리적 동치인 number2를 put하게 되면 putVal()함수가 호출되고 위 3번과정을 수행하게 된다.
PhoneNumber의 hashCode를 재정의하지 않았다면? number1과 number2는 논리적 동치이지만 hashCode가 다르다. 그럼 HashMap에 put() 했을 때 다른 버킷 인덱스에 담기게 되고, get()할 경우 다른 버킷에 있기 때문에 다른 식별자라고 판별한다.
출처/참고 : HashMap은어떻게 동작할까? + 자바8에서의 변화
⭐ 좋은 hashCode란?
☑️ 논리적 동치인 객체라면, 같은 hashCode를 반환한다.
위에서 살펴봤듯이 equals를 재정의했는데 hashCode를 재정의하지 않으면 HashMap이나 HashSet 같은 컬렉션의 원소로 사용할 때 문제를 일으킬 것이다.
따라서 논리적 동치다? ➡️ 무조건 같은 hashCode 반환
이기 때문에 equals 재정의 시 hashCode도 재정의 하라는 것이다.
☑️ 논리적 동치가 아닌 객체라면, 다른 hashCode를 반환한다.
논리적으로 다른 객체이지만 같은 hashCode를 반환해도 된다.
PhoneNumber number1 = new PhoneNumber(010, 6546, 7890);
PhoneNumber number2 = new PhoneNumber(010, 1111, 1111);이렇게 논리적 동치가 아닌 객체 2개가 있다고 하자.
만약 이 두 객체가 같은 hash를 가진다면?
HashMap에 같은 버킷에 담기게 된다. (같은 버킷 안에 LinkedList로 연결되어 있는 형태일 것이다.)
map.put(number1, 1);
int num = map.get(number2);이렇게 put()하고 get()을 하면
HashMap의 버킷을 찾고, equals 비교를 해서 true가 나온다.
number1와 number2는 논리적 동치이므로 같은 식별자를 가진다고 판단한다.
이렇게 해도 문제가 없는 것 처럼 보이지만 이렇게 다른 객체에 같은 hash를 반환하면 성능에 좋지 않다.
모든 객체가 같은 hash를 가진다면 하나의 버킷 안에서 노드들이 연결되어 있는 모습일 것이다. 이건 get, put, remove, containsKey에서 시간 복잡도 O(1)을 가지는 HashMap의 장점을 이용하지 못하는 것이다.
따라서 아래 처럼 모든 객체에 같은 hash를 반환하는 hashCode는 최악이다.
@Override
public int hashCode() {
return 42;
}⭐ hashCode 메서드를 어떻게 구현할까?
- 기본타입 필드인 경우 :
기본타입의박싱클래스.hashCode(필드) - 참조타입 필드인 경우 :
필드.hashCode() - 배열의 경우 :
Arrays.hashCode()
☑️ 전형적인 hashCode 메서드
@Override public int hashCode() {
int result = Short.hashCode(areaCode); // 1
result = 800000 * result + Short.hashCode(prefix); // 2
result = 800000 * result + Short.hashCode(lineNum); // 3
return result;
}☑️ Object 클래스의 hash() 이용하기
@Override public int hashCode() {
return Objects.hash(lineNum, prefix, areaCode);
}Object 클래스는 임의의 개수만큼 객체를 받아 해시코드를 계산해주는 정적 메서드 hashCode()를 제공한다. 책에서는 아쉽다고 말하고 있긴 한데 hashCode 때문에 성능에 크게 문제가 생기는 상황이 아니라면 써도 상관 없다고 (개인적으로) 생각한다.
참고로 인텔리제이의 도움을 받아 hashCode를 만들 때에도 이렇게 만들어진다.
☑️ 해시코드 계산 비용이 크다면 지연초기화 전략을 고려할 수 있다.
해시코드 계산 비용이 크다면 지연초기화 전략을 이용할 수도 있다.
private volatile int hashCode; // 캐시메모리가 아니라 메인메모리에 값이 저장됨. 기본 값은 0이다.
@Override public synchronized int hashCode() {
int result = hashCode;
if (result == 0) {
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
this.hashCode = result;
}
return result;
}이렇게 hashCode() 가 처음 사용될 때 hashCode가 만들어지고 그 값을 캐싱해서 사용하는 코드다. 이럴 때는 스레드 안정성을 고려해야 하기 때문에 synchronized 키워드로 임계구역을 감쌌다.
⭐ hashCode를 쉽게 구현하도록 도와주는 것들
이건 이전에 작성한 글 아이템10에서 작성했다. hashCode를 작성하는 툴도 equals를 재정의 하는 툴과 같다.
간단하게 적어보자면
-
@AutoValue:@AutoValue는 구글에서 만든 코드 자동 생성 라이브러리인데 책에서@AutoValue를 너무 찬양하고 있다. 코틀린을 쓴다면 데이터클래스를,record를 지원하는 java 버전을 쓴다면record를 쓰라고 추천하고 있으니@AutoValue를 쓰는 게 무조건 좋다고 말할 수는 없을 것 같다. -
인텔리제이로 직접 만들기 : 인텔리제이 같은 IDE를 이용해 내가 직접
hashCode를 구현하는 것이다. -
Lombok : Lombok의
@EqualsAndHashCode를 쓰면 자동으로 hashCode를 만들어준다. -
record : java16 이상의 버전을 쓰면
record를 사용할 수 있는데getter,setter,equals,hashCode,toString같은 메서드들을 만들어준다.
책을 읽다보면 hashCode를 재정의할 때 고려해야할 점이 많은데
다른 혹은 같은 hash를 반환하는지 생각하거나 그 hashcode를 테스트하지 않고,
그냥 lombok 를 이용하면 되지 않을까 하는 생각이 든다. (lombok을 이용하면 lombok이 잘 동작하는지에 대해서는 테스트하지 않아도 되기 때문에)
그리고 스레드 안정성에 대한 애기도 나오는데 HashMap 대신 Thread-safey한 HashTable을 사용하는 방법도 있다.
