Systems Performance - #2 Methodologies
Systems-Performance #1 Introduction에서 이어지는 내용으로, Brendan gregg의 책 Systems Performance를 정리한 내용이다.
Performance에 대해 공부하기 위해 CLI tool들과 metric들만 들여다보는건 도움이 안된다. page fault, context swiwch 같은것들이 뭔지 man page의 처음부터 끝까지 읽는것과, 주어진 signal/metric을 통해 솔루션을 어떻게 도출해낼지는 별개의 문제다.
경험많은 시스템 관리자는 문제의 원인을 파악하기 위한 자신만의 절차가 있다. 어떤 메트릭이 중요한지, 어떨때 문제가 되는지, 어떻게 그것들을 활용해서 문제를 좁혀나갈지 알고 있다. 이게 바로 man page에 빠져있는 know-how다. 보통 이런것들은 시니어들의 어깨 너머로 배우게 된다.
이 장은 책의 저자 brendan gregg이 그동안 모으고 정리하고 공유하고 발전시킨 performance methodology에 대해 설명한다.
이 장에서 배우고자 하는것들은:
- Key performance metric의 이해: latency, utilization, saturation
- Scale에 대한 감각 키우기
- tuning trade-off, target 그리고 언제 analysis를 그만두어야 할지 알기
- workload vs architecture 문제 식별
- resource vs workload analysis 고려하기
- USE method, workload characterization, latency analysis, static performnace tuning, performance mantra와 같은 performance methodology 실천
- 통계와 queueing 이론에 대한 기본적인 이해
시간이 흐르며 많은 소프트웨어, 하드웨어, 도구들이 다 변해버렸지만 이론과 방법론들은 변하지 않았다. 그만큼 읽으면서 공감이 많이 된 장이기도 하다.
2.1 Terminology
다음은 system performance를 이해하기 위한 핵심 용어들이다.
- IOPS: Input/output Operation Per Second. 데이터 전송 작업의 속도. disk I/O의 경우 초당 몇번 읽고 쓰는지를 의미한다.
- Throughput: 일을 처리하는 속도. 맥락에 따라 communication 같은 곳에선 data rate, database 같은 곳에선 operation rate가 될 수 있겠다.
- Respones time: 일을 처리하는데 걸린 시간. 이 용어는 기다리는 시간과 실제 일을 처리하는 시간 그리고 데이터를 주고받는 시간을 포함한다.
- Latency: 작업이 실제 처리되기 전에 기다린 시간. 어떤 맥락에선 작업이 처리되는 시간까지 포함해 response time과 같은 취급을 하기도 한다. 2.3절의 예시를 참고
- Utilization: 서비스가 요청한 자원에 대해, utilization은 주어진 시간동안 실제로 얼마나 작업에 사용되었는가로, 그 자원이 얼마나 바쁜지를 나타낸다. 저장 공간을 제공하는 자원에선 사용한 시간 대신 사용한 공간으로 utilization을 계산하곤 한다. (e.g., memory utilization)
- Saturation: 처리하지 못하고 큐에서 대기하고 있는 작업이 얼마나 있는지를 나타내는 정도
- Bottleneck: 병목. 전체 시스템의 성능을 제한하는 자원. 이를 식별하고 제거하는 것은 systems performance의 핵심 작업중 하나다.
- Workload: 시스템이 받는 input 또는 처리해야 하는 부하. 데이터베이스의 경우, 클라이언트가 보내는, 쿼리와 명령의 조합이 되겠다.
- Cache: 한정된 양의 데이터를 복사/버퍼링 하여, 느린 저장공간과 직접 데이터를 주고 받는 것을 피해 성능을 개선 시킬 수 있는 빠른 저장공간. 경제적인 이유로, cache는 보통 느린 저장공간보다 작다.
2.2 Models
2.2.1 System Under Test
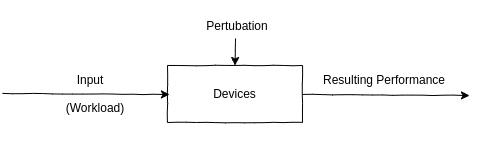
pertubation(interference)가 결과에 영향을 미칠 수 있음에 유의하라. 스케줄링된 시스템 작업이나 시스템의 다른 유저들, 다른 workload들이 여기 포함된다. pertubation의 원인은 명확하지 않을 수 있다. 따라서 이를 파악하기 위해선 세심한 접근이 필요할 수 있다. 특히 guest tenant의 다른 작업은 guest SUT에서 보이지 않기 때문에, 클라우드 환경에서 이를 파악하는것은 어려울 수 있다.
오늘날의 환경에서 더욱 어려운 것은 SUT가 로드밸런서, 프록시서버, 웹서버, 캐싱서버, 어플리케이션 서버, 데이터베이스 서버, 저장공간 등등을 포함해 네트워크로 연결된 컴포넌트들의 조합으로 이루어져 있다는 것이다. 컴포넌트간의 연결관계만 파악해봐도 이전에 간과했던 pertubation의 원인을 밝히는데 도움이 될 수 있다.
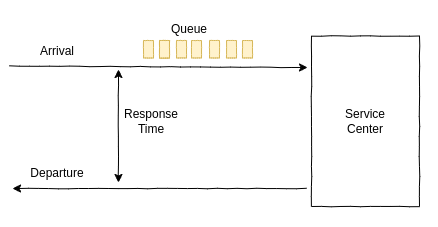
2.2.2 Queueing System
몇몇 컴포넌트와 자원들은 큐잉 시스템으로 모델링되어 각각 다른 환경에서의 성능을 예측해볼 수 있다. 디스크가 보통 큐잉 시스템으로 모델링되어 부하마다 어떻게 response time이 달라질지 예측할 수 있다.
2.3 Concepts
2.3.1 Latency
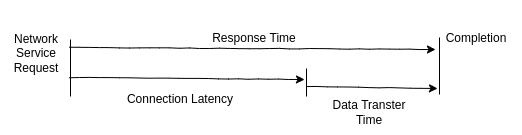
위 그림은 HTTP GET 요청과 같은 네트워크 전송을 latency와 transfer time으로 나눠서 보여준다. latency는 실제 작업이 처리되기 전에 소요된 시간이다. 이 예제에서 실제 작업은 데이터를 전송하기 위한 네트워크 서비스 요청으로, 이 작업이 수행되기 전에 먼저 이 맥락의 latency에 해당하는 네트워크 연결이 수립되어야 한다.
latency는 다양한 맥락에서 계산될 수 있어 종종 관측대상과 같이 나타내지곤 한다. 예를 들어 웹사이트의 load time은 DNS latency, TCP connection latency, TCP data transfer time의 구성으로 나타낼 수 있다.
더 높은 계층에선, 이것들이 그냥 전부 무언가의 latency로 취급될 수 있다. 예를 들어 유저가 웹사이트 링크를 클릭하고나서 결과 페이지가 전부 불러와질때 까지를 latency라 할 수 있다. 따라서 그냥 "latency" 라는 단어는 모호하며, 무엇의 latency인지를 명시해주는게 제일 좋다.
latency는 시간 기반 metric이기에 다양한 계산이 가능하다. 성능 이슈는 latency를 활용해 수량화되고 우선순위를 매길 수 있다. 모두 같은 단위(시간)을 사용하여 표현할 수 있기 때문이다. 예를 들어 IOPS metric같은 것들은 서로 쉽게 비교가 힘들다.
가능하면 다른 metric 타입을 latency나 시간단위로 바꾸는게 서로 비교하기 용이하다. 100 network I/O와 50 disk I/O 중 뭐가 더 나은지 알기 어렵지만(네트워크 홉 갯수, drop&retransmit 비율, I/O 크기, 순차/무작위 I/O 등등을 고려해야 하므로), 100ms network I/O와 50ms disk I/O는 쉽게 비교할 수 있다.
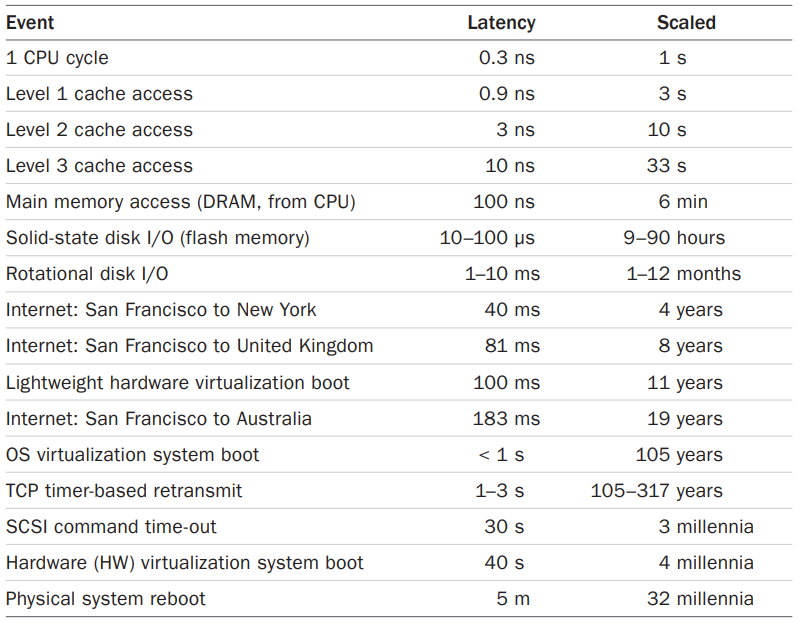
2.3.2 Time Scales
시스템 컴포넌트들은 서로 다른 time scale을 가지고 있다. 아래 표는 각 계층의 latency들을 정리하여 시간 개념에 대한 직관을 갖게 하는데 도움이 된다.
2.3.3 Trade-Offs
- 좋다 / 성능이 좋다
- 빠르다 / 기한내에 완성한다
- 싸다 / 비용이 적게 든다
종종 여기서 둘을 고르면 하나를 포기해야 하는 경우가 있다.
많은 IT 프로젝트들이 적은 비용으로 기한내에 완성하는걸 우선하고 성능에 관한건 뒷전으로 미루곤 한다. 성능 튜닝에서 흔한 trade-off는 CPU와 메모리다. 메모리는 결과를 캐싱해 CPU 사용량을 줄이는데 사용될 수 있기 때문이다. 요즘 CPU가 충분한 시스템에선 반대로 메모리 사용량을 줄이기 위해 CPU를 사용하여 데이터를 압축할때도 있다.
튜닝 가능한 매개변수들도 종종 trade-off가 필요하다:
- 파일 시스템 레코드 크기(또는 블럭 크기): 어플리케이션 I/O 크기에 가까운, 작은 레코드 크기일수록 random I/O workload 성능이 좋고, 다른 어플리케이션들이 실행될때 파일시스템 cache를 더 효율적으로 쓸 수 있다. 레코드 크기가 크면 파일 시스템 백업이나 wokload 스트리밍 같은 작업을 더 효율적으로 할 수 있다.
- 네트워크 버퍼 크기: 작은 버퍼 크기는 connection당 메모리 오버헤드를 줄여줘 시스템을 확장할 때 도움이 된다. 큰 크기는 network throughput을 개선하는데 도움이 된다.
2.3.4 Tuning Efforts
성능 튜닝은 실제 작업이 수행되는 곳에서 가까운 곳에서 할수록 효과적이다. 어플리케이션이 수행하는 workload의 경우, 그 어플리케이션 자체에서 성능 튜닝을 하는게 가장 효과적이다. 아래 표는 튜닝 가능한 소프트웨어 스택들이다.

어플리케이션 계층에서 튜닝함으로써, 데이터베이스 쿼리 같은것들을 아예 없애버릴 수 있고 성능을 크게 개선 시킬수도 있다.(예를 들면 20배 정도). 저장공간 계층으로 내려가 튜닝한다면 storage I/O를 개선 시킬수도 있지만, 이미 상위계층의 OS 스택 코드를 실행하는데 든 비용이 있어 전체 어플리케이션 성능은 몇 퍼센트밖에 개선시키지 못할 수 있다.(예를 들면 20% 정도)
어플리케이션 계층에서 성능을 크게 개선시킬 수 있는 또 다른 이유가 있다. 오늘날 많은 환경이 새로운 기능을 빨리 개발하는데 초점을 두고 있어 프로덕션 릴리즈를 하루, 일주일 주기로 하기도 한다. 따라서 개발팀이나 검수팀은 잘 동작하는지에 집중하고 성능 측정이나 개선에는 시간을 잘 쓰지 않는다. 이런 작업들은 나중에 성능이 문제가 되면 수행된다.
어플리케이션이 튜닝하기 가장 효과적인 계층이지만, 기본적인 observation을 하는데에는 제일 효과적인 계층이 아닐 수 있다. 느린 쿼리는 그게 on-CPU에 쓰인 시간이나 수행한 파일 시스템과 디스크 I/O를 보는게 제일 최선일 수 있다.
클라우드 컴퓨팅을 포함한 많은 환경에서, 어플리케이션 계층은 계속 개발되고 변경사항이 반영된다. regression을 고치는것을 포함한 큰 성능 개선이 코드를 수정하는것으로 이뤄지는 경우가 많다. 이런 환경에선, OS를 튜닝하거나 측정/관측 하는게 쉽게 간과될 수 있다. OS에서의 performance analysis가 어플리케이션의 이슈를 식별하는데에도 도움될 수 있음을 기억하라.
2.3.5 Level Of Appropriateness
조직과 환경마다 성능에 대한 요구사항이 다르다. 어떤곳에선 성능에 대한 기준이 매우 높을수도, 어떤곳에선 낮을수도 있지만 뭐가 맞고 틀린건 없다. 이 기준은 performance expertise에 대한 ROI(Return Of Investment)에 따라 다르다. 아주 큰 데이터 센터나 클라우드 환경을 갖춘 조직은 performance engineer을 고용해 커널 내부, CPU performance counter를 포함한 모든것들을 분석할 수 있고 performance를 모델링하거나 tracing tool을 개발하는 등의 작업도 수행할 수 있다. 1년에 컴퓨터 비용으로 수백만 달러를 쓰는 환경에선 이런 performance 팀을 쉽게 고용하고 ROI를 달성할 수 있겠다. 컴퓨터 비용으로 얼마 쓰지 않는 작은 스타트업이라면 간단한 performance 체크만 수행하거나 third-party 모니터링 솔루션에 의지할 수도 있다.
그러나 systems performance는 비용에 관한것만이 아니라 end-user experience에 관한 것이기도 하다. 스타트업에선 웹사이트나 어플리케이션의 latency를 개선하기 위해 performance engineering에 투자할 필요성이 생길 수 있는데 여기서의 ROI가 꼭 비용 감소일 필요는 없다. 이 경우엔 기존 고객보다 더 행복한 고객이 되겠다.
주식매매와 high-frequency trader와 같은 극한 환경들에선 performance와 latency가 매우 중요해서 막대한 비용과 노력을 투자할 수 있다. 예로, 뉴욕에서 런던까지 3억 달러를 들여 대서양 횡단 케이블을 교체한적이 있는데 transmission delay를 겨우 6ms 줄이기 위해서였다.
2.3.6 When to Stop Analysis
Performance analysis를 수행할 때 항상 중요한것은 언제 멈출지를 아는 것이다. 너무 많은 도구들도 있고 봐야할 것들도 너무 많다.
퍼포먼스에 3가지 문제가 있는 시스템에서 누군가는 1개만 찾고 멈추고, 누군가는 2개, 누군가는 3개 모두를 찾는다. 그러나 누군가는 있지도 않는 문제를 찾기위해 계속 시도한다. 당연히 3개만 찾고 멈추는게 이상적이겠지만, 현실에서 문제가 몇개인지 답을 알수는 없다.
아래 예제들은 analysis를 멈추는걸 고려해볼만한 시나리오들이다:
-
performance 이슈의 대부분을 설명했을 때: 자바 어플리케이션이 이전보다 CPU를 3배나 더 사용하고 있었다. 처음에 찾은 이슈는 CPU를 잡아먹고 있던 예외 스택중 하나였다. 이 스택에서 소모된 시간을 확인하니 전체 CPU footprint의 12%만 설명되었다. 만약 이 수치가 66% 정도만 되었으면 여기서 멈췄을거다. (3배 느려진게 설명되므로) 하지만 그러지 않았으니 계속 봐야겠다.
-
잠재적인 ROI가 analysis 비용보다 작아질 때: 몇몇 performance 이슈들은 1년에 수천만달러의 가치를 가진다. 이런 것들엔 수개월의 시간(engineering cost)를 쏟아부어도 좋다. 개선해봤자 수백달러 정도 밖에 절약되는 이슈라면, 거기에 1시간조차 쓰기 아까울 수 있다.
-
다른 더 큰 ROI가 있을 때: 위 두 시나리오가 아니더라도 다른 더 중요한 일(ROI가 높은 일)이 있다면 그것부터 처리하는게 좋다.
full-time performance engineer들은, 잠재적인 ROI를 기준으로 각 이슈의 analysis에 우선순위를 매기는게 주로 일과가 될것 이다.
2.3.7 Point-in-Time Recommendations
유저들이 늘어나거나, 하드웨어가 교체되거나, 소프트웨어가 업데이트 되는등 시간이 지남에 따라 환경의 performance characteristic도 변한다. 나중에 디스크나 CPU 성능을 100 Gbit/s로 올리면 10 Gbit/s였던 네트워크 인프라가 병목이 될 수 있다.
performance recommendation, 특히 튜닝가능한 parameter의 값들은 오직 특정 시점에서만 유효하다. performance 전문가가 제시한 최적의 값이 다음주에는 소프트웨어나 하드웨어 업그레이드로 더이상 유효하지 않을 수 있다. 인터넷에 검색한 parameter 값들은 쉽고 빠르게 적용해볼 수 있지만 시스템이나 workload가 적절치 않다면 오히려 성능을 저하시킬 수 있다.
2.3.8 Load vs Architecture
어플리케이션은 그것이 돌고 있는 하드웨어나 소프트웨어 설정 같은거에 이슈가 생기면 성능이 나빠질 수 있다. 아니면, 너무 많은 workload가 들어와도 큐잉과 긴 latency의 결과로 성능이 나빠질수도 있다.
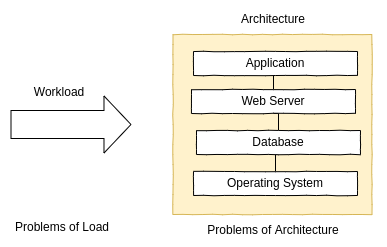
만약 어떤 architecture의 analysis에서 작업을 처리하는데는 문제가 없지만, 작업이 큐에 쌓인다면, 이슈는 어쩌면 너무 많은 부하 때문일지 모른다. 클라우드 컴퓨팅 환경에선 더 많은 인스턴스가 필요한 때이다.
다른 CPU들은 놀고있는데 싱글 쓰레드 어플리케이션 하나가 on-CPU 상태에서 요청이 쌓일 수 있다. 이 경우의 performance는 어플리케이션의 싱글 쓰레드 architecture로 제한된다. 다른 architecture의 이슈로 single lock으로 경쟁하는 멀티 쓰레드 프로그램도 있을 수 있다.
멀티 쓰레드 어플리케이션에서 모든 CPU를 사용할때 요청이 쌓일 수 있다. 이 경우의 performance는 사용 가능한 CPU 성능에 달려있다. 다시 말해 CPU가 처리할 수 있는것보다 더 많은 부하가 걸린것이다.
2.3.9 Scalability
부하가 증가할때의 시스템 성능을 scalability 라 한다.
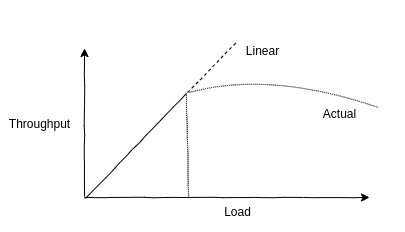
위 그림은 시스템의 부하가 증가할때의 throughput를 보여주고 있다.
일정 부하까지는 linear scalability를 보이지만, 어떤 지점부터는 자원을 두고 경쟁하기 때문에 성능에 지장이 생기기 시작한다. 이 지점을 knee point라 한다. 어떤 컴포넌트가 100% utilization에 도달했을때 발생할 수 있고 이를 saturation point라 한다.
이런 양상을 보이는 시스템의 예로, 아주 많은 연산을 수행하는 어플리케이션이 있다. CPU가 100% utilization에 도달하면, CPU 스케줄러 latency의 증가로 response time이 나빠지기 시작한다. utilization 100%에서 peak performance를 찍고나면, CPU 자원을 소모하는 context-switch 때문에 throughput은 떨어지기 시작한다.
nonlinear scalability에도 급이 있다. 메모리 부하같은 경우엔 성능 저하가 빨리 올수 있고 CPU 부하 같은 경우엔 느리게 올수 있다. 성능저하가 빨리오는 예로는 디스크 I/O가 있다. 부하가 늘어날수록(결과적으로 디스크 utilization도) I/O가 다른 I/O 뒤에 쌓이게 된다. idle 상태일때 1ms reponse time이던게 부하가 늘어나면 10ms가 될 수도 있다.
자원이 사용불가 일때 작업을 쌓아두는 대신 에러를 반환하면 linear scalability를 보장할 수 있다.
2.3.10 Metrics
Performance metric은 시스템, 어플리케이션 또는 관심있는 작업을 측정하는 도구들로 생성된 자료들이다. 이것들은 performance analysis와 모니터링을 위해 사용된다. system performance metric은 흔히 Throughput, IOPS, Utilization, Latency를 포함한다.
throughput의 사용은 맥락에 따라 다르다. 데이터베이스 throughput은 초당 쿼리나 요청으로 측정되며 네트워크 throughput은 초당 bits나 bytes로 측정된다. IOPS도 맥락에 따라 정의가 달라질 수 있다.
Performance metric은 공짜가 아니다. 그것들을 수집하고 어딘가 기록해두는데에는 어느정도의 CPU cycle이 필요하다. 이는 overhead를 야기해 측정 대상의 performance의 악영향을 미친다. 이를 observer effect 라 한다.
어쩌면 소프트웨어 벤더사가 잘 엄선된 metric을 버그 없이 깔끔하게 잘 제공해줄거라 생각할 수 있다. 현실에선, metric은 햇갈리고, 복잡하고, 불안정하고, 부정확하고 심지어는 버그때문에 애초부터 잘못된 경우가 있으니 주의하라.
2.3.11 Utilization
utilization 라는 용어는 종종 OS에서 CPU나 디스크같은 장치의 사용량을 나타낼때 사용한다. utilization은 time-based거나 capacity-based일 수 있다.
time-based utilization은 "해당 서버나 자원이 사용된 평균 시간의 양" 즉
U=Utilization, B=시스템이 사용된 전체 시간, T=관측한 시간
일때
와 같이 정의된다.
os performance tools에서 가장 많이 제공해주는 utilization이기도 하다. 디스크 모니터링 도구인 iostat(1)은 이 metric을 percent busy 라는 뜻의 %b로 나타낸다.
몇몇 컴포넌트들은 병렬로 작업을 처리할 수 있는데, 이런 컴포넌트들에선 utilization이 100%여도 성능이 크게 나빠지지 않을 수 있다. 빌딩의 엘리베이터가 움직이는 동안 utilized되고 움직이지 않을때 utilized가 아니라 할때, 이미 utilization이 100%인 와중에도 계속 사람을 더 태울수 있다. 또는 100% utilization 상태인 디스크도 on-disk cache에 write 작업을 버퍼링하는 식으로 추가적인 작업을 처리할 수 있다. storage array도 어떤 디스크는 항상 바쁠테니 쉽게 100% utilization을 찍지만 다른 idle 디스크들이 추가적인 작업을 받을 수 있다.
Capacity planning에서의 utilization은 다음과 같이 정의될 수 있다.
"A system or component (such as a disk drive) is able to deliver a certain amount of throughput. At any level of performance, the system or component is working at some proportion of its capacity. That proportion is called the utilization."
IT professionals / Wong, B., Configuration and Capacity Planning for Solaris Servers, Prentice Hall, 1997 에서 가져온 말인데 매끄럽게 번역하기 어려워 원문을 그대로 가져왔다. 이름 자체가 직관적이라 사실 이런 정의 없이도 쉽게 이해할 수 있을것이다.
여기선 utilization을 time이 아닌 capacity로 정의했다. 이는 100% utilization인 디스크는 더이상 추가적인 작업을 처리할 수 없음을 의미한다. 예를 들어 이전의 엘리베이터도 capacity가 100% 차면 더이상 사람을 받을 수 없다.
이 책에선 보통 utilization이 time-based로 non-idle time이라 부를수도 있다. capacity-based 버전은 메모리 사용량 같은 몇몇 volume-based metric에 사용된다.
2.3.12 Saturation
어떤 자원에 처리할 수 있는 양보다 얼마나 더 많은 작업이 들어왔는지 정도를 saturation 이라 한다. saturation은 utilization(capacity-based)이 100%일때 발생하기 시작해서 추가적인 작업을 처리하지 못하고 쌓아두게 된다.
2.3.13 Profiling
Computing performance에서 profiling은 일반적으로 일정 주기로 시스템의 상태를 sampling 하고 sample들을 살펴보는것으로 수행된다. IOPS나 throughput과 같은 metric과 달리 sampling은 대상 작업의 대략적인 개요만 제공한다. 얼마나 대략적인지는 sampling 주기에 따라 다르다. profiling의 예로 CPU가 있는데 CPU instruction pointer나 stack trace를 일정 주기로 수집하는 것으로 어떤 code path가 주로 CPU 자원을 소모하는지 알 수 있다.
2.3.14 Caching
Caching은 성능을 개선하기 위해 종종 사용된다. 더 느린 계층의 저장공간의 결과를 더 빠른 계층의 저장공간에 기록해두는 식이다. 메인 메모리에 디스크 블럭을 caching하는 예가 있겠다.
여러 계층의 cache도 있다. CPU는 보통 메인 메모리를 위해, 가장 빠르지만 작은 1계층부터 점점 느려지지만 용량은 커지는 여러 하드웨어 cache(1, 2, 3계층)를 사용한다.
cache performance를 이해하기 위한 metric중 하나는 hit ratio다. 전체 접근한 횟수(hit+miss) 대비 몇번이나 실제 필요한 데이터가 cache에 있었는지(hit), 다음과 같이 정의된다.
값이 높을수록, 더 자주 성공적으로 더 빠른 장치에서 데이터를 가져온다는 뜻이므로, 더 좋다.
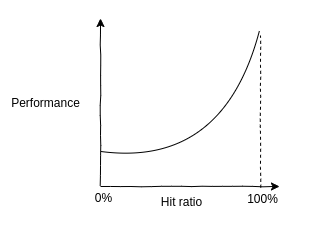
그림과 같이, 98% -> 99%의 hit ratio 차이가 10% -> 11%보다 훨씬 크다. nonlinear profile인 이유는 hit와 miss의 속도차가 있기 때문이다.
cache performance를 이해하기 위한 또 다른 metric은 초당 miss횟수를 나타내는 cache miss rate다. hit ratio와 다르게 linear profile이며 쉽게 해석 가능하다.
Cache management algorithm/policy는 cache의 한정된 사용가능한 공간에 무엇을 기록해둘것인지 결정한다. MRU(Most Recently Used)는 cache retention policy로써, 가장 최근에 사용된 개체를 cache에 남겨둔다. LRU(Least Recently Used)는 cache eviction policy로써, cache 공간이 부족할때 어떤 개체를 cache에서 제거해야 할지 결정한다. 외에도 MFU(Most Frequently Used), LFU(Least Frequently Used), NFU(Not Frequently Used, LRU보다 빠르지만 부정확한 버전) policy들도 있다.
cache의 상태는 크게 3가지가 있다.
-
Cold: cold cache는 비어있거나 필요없는 데이터로 채워져있다. hit ratio는 0에 가깝다.
-
Warm: warm cache는 필요한 데이터가 채워지긴 했지만 아직 hot이라기엔 hit ratio가 충분치 않다.
-
Hot: hot cache는 대부분 필요한 데이터로 채워져 있으며 99%와 같은 높은 hit ratio을 가진다.
2.3.15 Known-Unknowns
서문에서도 나온 내용인데, Performance 분야에서 중요한 개념이기도 하니 한번 보자. 원래는 2002년에 미국 국방부 장관이 뉴스 브리핑에서 언급한 내용이라고 한다.
- Known-known: 우리가 알고 있는것. 그 metric을 어떻게 확인하는지, 현재 값은 어떤지도 알고 있다. 예를 들어 CPU utilization을 어떻게 확인하는지 그리고 보통 그값은 평균적으로 10%라던지와 같은 것들이 있다.
- Known-unknown: 우리가 모르고 있다고 알고 있는 것. 어떤 metric 또는 subsystem의 존재는 알고 있지만 아직 관측은 안해봤다. 예를 들어 뭐가 CPU를 쓰는지 profiling 해볼 수 있지만 안해봤다던가 같은 것들이 있다.
- Unknown-unknown: 우리가 모르고 있다는것도 모르고 있는 것. 예를 들어 device interrupt가 CPU 자원을 잡아먹을 수 있다는 사실을 몰라서 아예 확인할 생각도 못할 수 있다.
Performance 분야에서 "the more you know, the more you don’t know."란 말이 있다. system에 대해 알면 알수록, 더 많은 unknown-unknown이 우리가 확인할 수 있는 known-unknown 바뀌는 것이다.
2.4 Perspective
Performance analysis에 크게 두가지 관점이 있다. workload analysis와 resource analysis다.
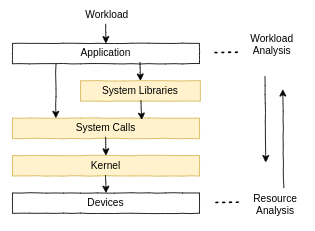
2.4.1 Resource Analysis
Resource analysis는 CPU, 메모리, 디스크, 네트워크 인터페이스, 버스같은 시스템 자원들을 분석하는것으로 시작한다. 이는 대부분 물리적 자원을 책임지는 시스템 관리자가 수행한다. 이들이 하는 업무에는
- Performance issue investigation: 어떤 타입의 자원이 문제인지 알기 위해
- Capacity planning: 새로운 시스템의 견적을 재기 위해, 그리고 언제쯤에 현재 시스템 자원이 모두 소진될지 알기 위해
와 같은 것들이 있다. 이 관점은 uilization에 집중해, 자원들이 언제 limit에 도달할지 알아본다. CPU와 같은 자원은 쉽게 utilization metric을 구할 수 있다. 다른 자원들의 utilization도 사용가능한 metric들로부터 계산할 수 있다. 예를 들어 네트워크 인터페이스의 utilization은 이미 알고 있거나 예상되는 최대 대역폭과 보내고 받는 초당 megabit(throughput)을 비교해 구할 수 있다.
resource analysis에 효과적인 metric들로는 다음과 같은 것들이 있다:
- IOPS
- Throughput
- Utilization
- Saturation
2.4.2 Workload Analysis
Workload analysis는 어플리케이션의 성능을 본다. 수행해야 할 workload와 어플리케이션이 얼마나 잘 작업을 수행하고 있는지. 보통 어플리케이션 개발자나 support staff가 수행한다. workload analysis의 대상이 되는 것들로는 다음과 같은 것들이 있다:
- Requests: 수행해야 할 workload
- Latency: 어플리케이션의 response time
- Completion: 에러 확인
workload requests를 분석하는 작업은 그것들의 속성을 확인하고 정리하는 일을 수반한다. 이는 workload characterization 과정 중 일부로, 데이터베이스를 예를 들면, 이런 속성들에는 클라이언트 호스트, 데이터베이스 이름, 쿼리 문자열 같은 것들이 있을 수 있다. 이런 정보들은 불필요하거나 unbalance한 작업을 식별하는데 도움을 줄 수 있다. 현재 workload에 대해서 시스템이 문제없이 작동하고 있더라도(low latency) 이런 속성을 살펴보는 것은 수행해야 할 작업을 줄이거나 아예 없애는 방법을 알려줄지도 모른다. 가장 빠른 쿼리는 아예 아무것도 하지 않는것임에 유의하라.
Latency(response time)은 어플리케이션 성능을 나타내는데 가장 중요한 metric이다. MySQL 데이터베이스의 경우에, query latency; Apache 경우엔 HTTP request latency 등등.
workload analysis 작업들은 이슈를 식별하고 확인하는 것까지 포함한다. 예를 들면, 임계치를 넘는 latency를 찾는다거나. 그리고 latency의 원인을 찾아내고 fix 적용 후 latency가 개선되었는지 확인한다. 시작점이 어플리케이션임에 주목하라. latency를 살펴보는 일은 보통 어플리케이션, 라이브러리, OS(kernel)로 더 깊게 파고 들어가는 작업을 수반한다.
시스템 이슈는, 에러 상태와 같이 어떤 이벤트의 completion과 관련된 특성을 살펴보는 것으로 식별될 수 있다. request가 빠르게 처리 완료되었을지라도, 사실은 어떤 에러 때문에 여러번 재시도 되서 결국 전체 latency가 늘어난 것일 수 있다.
Workload Analysis에 가장 적합한 metric들로는 Throughput, Latency같은 것들이 있다.
2.5 Methodology
성능이 제대로 나오지 않고 복잡한 시스템 환경을 맞닥뜨렸을 때, 가장 처음 난감한 일은 어디서부터 시작해서 어떻게 진행해야 하는지 아는 것이 될 수 있다. 1장에서도 나왔듯이 performance issue는 소프트웨어, 하드웨어 그리고 data path 사이의 아무 컴포넌트 어디에서나 발생할 수 있다. Methodology는 이런 복잡한 시스템들에 대해 analysis를 어디서부터 시작해야 할지 보여주고, 효과적인 절차는 무엇인지 제안한다.
아래는 타입별로 카테고리를 분류한 methodology들이다:
-
Streetlight anti-method: Observational analysis
-
Random change anti-method: Experimental analysis
-
Blame-someone-else anti-method: Hypothetical analysis
-
Ad hoc checklist method: Observational and experimental analysis
-
Problem statement: Information gathering
-
Scientific method: Observational analysis
-
Diagnosis cycle: Analysis life cycle
-
Tools method: Observational analysis
-
USE method: Observational analysis
-
RED method: Observational analysis
-
Workload characterization: Observational analysis, capacity planning
-
Drill-down analysis: Observational analysis
-
Latency analysis: Observational analysis
-
Method: R Observational analysis
-
Event tracing: Observational analysis
-
Baseline statistics: Observational analysis
-
Static performance tuning: Observational analysis, capacity planning
-
Cache tuning: Observational analysis, tuning
-
Micro-benchmarking: Experimental analysis
-
Performance mantras: Tuning
-
Queueing theory: Statistical analysis, capacity planning
-
Capacity planning: Capacity planning, tuning
-
Quantifying performance gains: Statistical analysis
-
Performance monitoring: Observational analysis, capacity planning
⠀
다른 장에서 살펴볼 추가적인 methodology들에는 다음과 같은 것들이 있다:
-
Linux performance analysis in: 60s Observational analysis
-
CPU profiling: Observational analysis
-
Off-CPU analysis: Observational analysis
-
Cycle analysis: Observational analysis
-
Priority tuning: Tuning
-
Resource controls: Tuning
-
CPU binding: Tuning
-
Leak detection: Observational analysis
-
Memory shrinking: Experimental analysis
-
Disk analysis: Observational analysis
-
Workload separation: Tuning
-
Scaling: Capacity planning, tuning
-
Packet sniffing: Observational analysis
-
TCP analysis: Observational analysis
-
Passive benchmarking: Experimental analysis
-
Active benchmarking: Observational analysis
-
Custom benchmarks: Software development
-
Ramping load: Experimental analysis
-
Sanity check: Observational analysis
2.5.1 Streetlight Anti-Method
이 methodology는 사실 methodology의 부재 그 자체다. 자신에게 익숙하거나, 인터넷에서 찾은 도구들로 아무 곳이나 찔러봐서 무언가가 나올때까지 성능을 분석하는 것이다. 이 접근 방식은 많은 종류의 이슈들을 지나치고 넘어갈 수 있다.
퍼포먼스 튜닝도 비슷하게 시행착오를 거치는 식으로 수행된다. 아무 parameter나 익숙한 값으로 바꿔보고 뭔가 개선된게 있는지 확인하는 식이다.
어느날 밤 경찰이 등불 아래서 무언갈 찾고 있는 술취한 사람을 보고 무엇을 찾는 중인지 물었다. 그 사람이 말하길 자기 열쇠를 잃어버렸단다. 경찰도 찾지 못해 물었다: "여기, 등불 아래서 잃어버린게 확실한가요?" 술취한 사람이 답하길: "아뇨, 그래도 빛이 있는곳에서 찾는게 제일 좋잖아요."
2.5.2 Random Change Anti-Method
문제가 있을 수 있는곳을 아무곳이나 찍어보고 문제가 해결될때까지 이것저것 만져보는 식이다. 각 변경의 결과로, 성능이 개선되었는지 아닌지 보기위해 어플리케이션 런타임, 수행시간, latency, throughput 같은 metric을 살펴본다. 접근 방법은 다음과 같다:
1. 변경할 아무거나 고른다.
2. 한쪽으로 변경해본다.
3. 성능을 재본다.
4. 다른쪽으로 변경해본다.
5. 성능을 재본다.
6. (3)이나 (5)의 결과가 처음보다 더 나아졌는가? 그렇다면 그대로 두고 다시 (1)로 돌아간다.
이런 접근 방법이 언젠가 먹힐수도 있지만, 시간을 매우 많이 잡아먹고 이렇게 구한 현재의 튜닝값이 나중엔 유효하지 않을 수 있다. 예를 들어 어떤 어플리케이션 변경사항이 데이터베이스나 OS의 버그를 우회하는 식으로 동작해서 성능이 개선된 경우, 나중에 그 버그가 고쳐지면 더이상 그 튜닝은 유효하지 않게 되고, 처음보면 아무도 제대로 이해하지 못할 것이다.
어떤 변경사항이 제대로 이해되지 않고 반영되면 production load가 peak일때 더 안좋은 문제를 야기 할 수 있다는 리스크도 있다.
2.5.3 Blame-Someone-Else Anti-Method
이 anti-methodology는 다음 작업을 따른다:
- 나랑 관련없는 시스템이나 컴포넌트를 찾는다.
- 문제 원인이 그 컴포넌트라 가정한다.
- 그 컴포넌트와 관련된 팀에 이슈를 넘긴다.
- 가정이 틀렸다면, (1)로 돌아간다.
"아마 네트워크가 문제일거에요. 네트워크 팀에다가 패킷이나 뭐 그런거 drop 시키는거 없는지 물어보세요."
퍼포먼스 이슈를 살펴보기보다, 이 methodology를 사용하는 사람들은 그것들을 다른 이의 문제로 돌린다. 이로 인해 다른 팀의 공수가 낭비될 수 있다.
2.5.4 Ad Hoc Checklist Method
미리 준비된 체크리스트를 따르는 것은 support professional들이 짧은 시간내 시스템을 체크하고 튜닝해달라는 요청을 받았을때 흔히 사용되는 methodology다. 이런 체크리스트들은 ad hoc이며 그 시스템에 대한 최근 경험과 이슈들로부터 만들어진다.
체크리스트 항목을 예로 하나 들면:
iostat -x 1을 실행하고r_await열을 확인. 만약 지속적으로 10ms을 넘으면 디스크 읽기가 느리거나 디스크가 과부하 상태다.
체크리스트는 이런 항목들 여러개로 구성될 수 있다.
이런 체크리스트들이 짧은 시간내에는 아주 효과적이지만, 이것들은 point-in-time 권장사항이고(2.3절, Concepts 참고) 자주 갱신될 필요가 있다. 만약 support professional 팀을 관리하는 위치라면, ad hoc 체크리스트는 흔한 이슈들을 다들 어떻게 확인해야하는지 알려주는 좋은 방법이 될 수 있다. 체크리스트는 명확하게 지시사항들이 쓰여져야 하며, 각 이슈를 어떻게 식별하고 고쳐야 하는지 보여줄 수 있어야 한다. 이 리스트들은 주기적으로 갱신되어야 함에 유의하라.
2.5.5 Problem Statement
problem statement를 정의하는 것은 이슈를 처음 받았을 때 support staff가 일상적으로 하는 업무다. customer에게 다음과 같은 질문을 하는것으로 수행된다:
1. 무엇 때문에 성능에 문제가 있다고 생각하세요?
2. 이 시스템 성능이 괜찮았을때가 있었나요?
3. 최근에 변경된게 있나요? 소프트웨어, 하드웨어, 부하 아무거나요
4. 문제가 latency나 runtime으로 표현될 수 있나요?
5. 문제가 다른 사람이나 어플리케이션에 영향을 주나요? (아니면 당신에게만?)
6. 환경이 어떻게 되나요? 어떤 소프트웨어와 하드웨어를 사용하나요? 버전은? 설정은?
그냥 이렇게 물어보고 질문에 답을 하는것만으로 바로 문제의 원인과 해결책이 나올때가 자주 있다.
2.5.6 Scientific Method
가정을 만들고 테스트해보는 것으로 모르는 것을 살펴본다. 다음 작업들로 요약될 수 있다:
질문 -> 가정 -> 예상 -> 실험 -> 분석
여기서의 질문은 performance problem statement다. 이로부터 낮은 성능의 원인이 무엇이 될 수 있을지 가정을 세워볼 수 있다. 예를 들어 더 적은 메모리를 가진 시스템으로 마이그레이션한 뒤 어플리케이션 성능이 저하되었음을 확인했고 이 문제의 원인이 더 적은 파일 시스템 cache라고 가정했다 하자. observational test를 통해 두 시스템의 cache miss rate를 측정하고 더 적은 시스템에서 cache miss가 더 높게 나올것이라 예상한다. experimental test는 cache 크기를 늘리고(RAM을 추가해서) 성능이 개선되는지 확인한다. 또는 experimental test를 할때 파라미터같은걸 튜닝해서 일부러 cache 크기를 줄인뒤 성능이 나빠지는지 확인하는 것도 있다.
Observational 예시:
- 질문: 무엇이 데이터베이스 쿼리를 느리게 하나요?
- 가정: Noisy neighbor(다른 클라우드 컴퓨팅 사용자)들이 디스크 I/O를 수행해서 데이터베이스 디스크 I/O에 영향을 주는것 같다.
- 예상: 만약 파일 시스템 I/O latency를 쿼리 중에 측정한다면, 파일 시스템에 문제가 있는지 알 수 있을것이다.
- 실험: 쿼리 latency의 비율로 데이터베이스 파일 시스템 latency를 트레이싱 해보니 5% 미만의 시간이 파일시스템을 기다리는데 쓰인걸 알 수 있었다.
- 분석: 파일 시스템과 디스크는 느린 쿼리와 관련이 없다.
이 이슈는 여전히 풀리진 않았지만, 확인해야할 큰 컴포넌트 몇몇이 없어졌다. 이제 (2)로 돌아가 새로운 가정을 세워볼 수 있다.
Experimental 예시:
- 질문: 왜 호스트A에서 호스트C로 가는 HTTP 요청이 호스트B에서 호스트C로 가는것보다 더 오래 걸리나요?
- 가정: 호스트A와 호스트C는 서로 다른 데이터센터에 있기 때문이다.
- 예상: 호스트A를 호스트B와 같은 데이터센터로 옮기면 문제가 해결될 것이다.
- 실험: 호스트A를 옮기고 성능을 측정한다.
- 분석: 문제가 해결되었다. - (2)의 가정과 일치한다.
만약 문제가 해결되지 않았다면, experimental change를 되돌린다.(다시 호스트A를 원래 위치로 옮기고)
Experimental 또다른 예시:
- 질문: 파일 시스템 cache 크기가 늘어나면서 왜 파일 시스템 성능이 나빠졌나요?
- 가정: 더 큰 cache가 많은 레코드를 기록하고 더 큰 cache를 관리하는데 더 많은 연산이 필요하기 때문이다.
- 예상: 레코드 크기를 점점 줄여나가, 같은 양의 데이터를 기록하는데 더 많은 레코드를 필요하게 만들면, 성능이 점점 안좋아질것이다.
- 실험: 점점 작은 레코드 크기로 동일한 workload를 실험해본다.
- 분석: 결과를 그래프로 나타내니 (2)의 가정과 일치했다. cache management routine에 Drill-down analysis를 수행한다.
이는 negative test의 예시 중 하나로, 의도적으로 성능을 저하시켜 정보를 얻는다.
2.5.7 Diagnosis Cycle
diagnosis cycle은 scientific method와 유사하다:
가정 -> 측정 -> 데이터 -> 가정
이 사이클은 수집한 데이터로부터 새로운 가정이 도출되는 것을 강조한다.
2.5.8 Tools Method
도구 지향적인 접근법은 다음과 같다:
1. 사용 가능한 performance tool들을 나열한다. (필요하다면, 새로 설치하거나 구입해서)
2. 각 tool마다, 제공하는 유용한 metric들을 나열한다.
3. 각 metric마다, 그것을 어떻게 해석할 수 있을지에 대한 방법들을 나열한다.
이러면 어떤 tool을 쓸지, 어떤 metric을 읽을지, 그것들을 어떻게 해석할지 알려주는 체크리스트가 나올 것이다. 이게 꽤나 효과적이긴 해도, 전적으로 사용가능한(알고 있는) tool에 의존하고 있어, 나머지에 대해서는 여전히 모르는 채로, 시스템에 대한 불완전한 시각을 제공할 수 있다. custom tooling(e.g., dynamic tracing)이 필요한 이슈는 식별되지도 해결되지도 않을 수 있다.
실전에서, tools method는 특정 자원의 병목, 에러 그리고 다른 종류의 문제들을 식별하긴 하지만 그렇게 효과적이진 않다.
더 많은 tool들과 metric이 사용 가능할때, 이것들을 모두 써보는 것은 시간이 많이 걸릴 수 있다. 만약 여러 tool들이 동일한 기능을 제공한다면 그것들의 장단을 비교하고 이해하는데 시간을 더 써야 한다. 파일 시스템 마이크로 벤치마크 tool같은 몇몇 경우엔, 필요한 도구는 하나일때, 사용할 수 있는 tool들은 수십개가 있을 수 있다.
2.5.9 The USE Method
Utilization, Saturation, 그리고 Errors (USE) method는 시스템 병목을 찾을 때 조기에 수행되어야 한다. 이는 시스템 자원에 초점을 둔 methodology이며 다음과 같이 요약될 수 있다:
모든 자원들에 대해, utilization, saturation, 그리고 errors를 확인하라
각 용어는 다음과 같이 정의된다:
- Resources: All physical server functional components (CPUs, buses, . . .). 몇몇 소프트웨어 자원도 포함될 수 있다.
- Utilization: 단위 시간 동안, 해당 자원이 사용된 시간의 percentage. 사용되는 동안 더 많은 작업을 받는게 가능할 수 있다; 그렇게 하지 못하는 정도는 saturation으로 식별된다.
- Saturation: 해당 자원이 처리해야 할 작업이 얼마나 밀려있는지. 밀린 작업들은 보통 큐에서 대기한다. 다른 용어로는 pressure라 한다.
- Errors: The count of error events.
메인 메모리와 같은 몇몇 자원 종류에서 utilization은 자원의 capacity를 의미한다. capacity resource가 100% utilization에 도달하면 더이상 작업을 받을 수 없고 이를 큐에 넣거나(saturation) 에러를 반환하게 된다.
Error도 성능을 해칠 수 있기에 확인이 필요하다. 그러나 실패하면 재시도하는것 처럼, failure mode가 recoverable하다면 바로 눈에 띄지 않을 수 있다.
tools method와 달리, USE method는 tool이 아니라 system resource를 순회한다. 이는 완전한 리스트를 만들고 난뒤, 필요한 도구를 찾는데 도움이 된다. tool들이 몇몇 질문에 답을 하지 못할때라도, performance analyst에게는 매우 유용할 수 있다: 이제 그것들은 "known-unknown"이다.
USE method는 또한 제한된 수의 key metric에 대한 분석을 지시해서 모든 시스템 자원들이 가능한 한 빠르게 확인될 수 있도록 한다. 이후에 아무 문제도 찾지 못했다면 다른 methodology를 사용할 수 있다.
USE method는 다음 그림처럼 나타낼 수 있다.
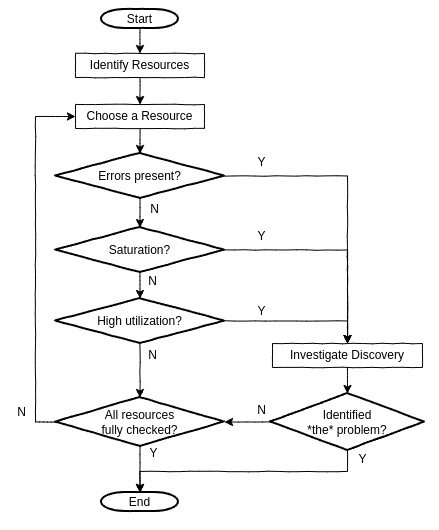
Error는 보통 해석하기 제일 빠르므로 가장 먼저 확인한다. (그것들은 보통 객관적이다) 두번째로 Saturation을 확인한다. Utilization보다 해석하기 빠르기 때문이다. (모든 레벨의 saturaiton은 문제가 될 수 있다) 이 방법은 시스템의 병목이 될만한 문제를 식별한다. 불행히도, 시스템은 하나 이상의 문제를 가질 수 있으므로 처음 찾은 문제가 다가 아닐 수 있다.
직관적이지 않을 수 있지만, 높은 utilization의 short burst가 긴 주기에서 전체적인 utilization이 낮더라도, saturation과 성능 이슈를 야기할 수 있다. 몇몇 모니터링 tool은 5분 평균의 utilization을 보여준다. CPU utilization을 예를 들면 매초마다 매우 급격히 바뀔 수 있어 5분 평균은 짧은 시간의 100% utilization 즉 saturation을 보여주지 못할 수 있다.
USE method의 첫 작업은 자원을 나열하는 것이다. 가능한 완전하게. 다음은 특정 예시들과 함께 일반적인 서버 하드웨어 자원들을 나열한 것이다:
- CPU: 소켓, 코어, 하드웨어 쓰레드(가상 CPU)
- 메인 메모리: DRAM
- 네트워크 인터페이스: 이더넷 포트, Infiniband
- 저장 장치: 디스크, storage adapter
- Accelerator: GPU, TPU, FPGA
- 컨트롤러: 스토리지, 네트워크
- Interconnect: CPU, 메모리, I/O
각 컴포넌트들은 일반적으로 하나의 자원 타입을 수행한다. 예를 들면, 메인 메모리는 capacity resource고 네트워크 인터페이스는 I/O resource다. 몇몇 컴포넌트는 여러 자원 타입을 수행할 수 있다. 예를 들면, 저장 장치는 I/O resource이자 capacity resource다. 성능에 병목이 될 수 있는 모든 타입을 고려하라. 또 I/O resource들은 나중에 queueing system으로써 추가적인 조사가 가능함에 유의하라.
하드웨어 cache와 같은 몇몇 물리적 컴포넌트들은 체크리스트에서 제외될 수 있다. USE method는 높은 utilization 또는 saturation에서 성능 저하를 겪는 자원에 대해 가장 효과적인데, cache는 utilization이 높으면 성능이 좋아진다. 이런것들은 다른 methodology를 사용해 확인할 수 있다.
자원들을 순회하는 또다른 방법으로는 아래 그림처럼 functional block diagram을 그려보는 것이다. 이렇게 컴포넌트간 관계도 그려보면 데이터의 흐름에서 병목을 찾을때 매우 유용할 수 있다.
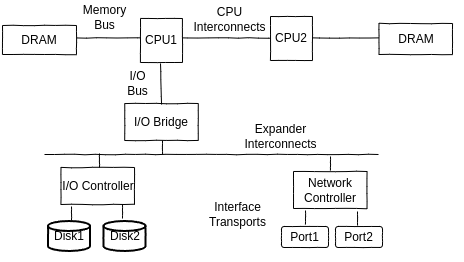
CPU, 메모리 그리고 I/O interconnect와 bus들은 쉽게 간과될 수 있다. 다행히, 그것들은 일반적인 시스템 병목은 아니다. 불행히도 만약 그것들이 병목이라면, 문제가 쉽게 해결되진 않을 것이다.
자원들의 리스트를 만들었다면, 각각의 적절한 metric 타입을 고려하라: Utilization, Saturation 그리고 Errors. 다음은 가능한 metric들과 함께 자원들과 metric 타입의 예시들을 보여준다:
- CPU / Utilization: CPU utilizaiton(per CPU나 시스템 평균)
- CPU / Saturation: Run queue length, scheduler latency, CPU pressure(Linux PSI)
- Memory / Utilization: Available free memory
- Memory / Saturation: Swapping(anonymous paging), page scanning, out-of-memory events, memory pressure
- Network interface / Utilization: Receive throughput/max bandwidth, transmit throughput/max bandwidth
- Storage device / Utilization: Device busy percent
- Storage device IO / Saturation: Wait queue length, I/O pressure (Linux PSI)
- Storage device IO / Errors: Device errors
이 metric들은 단위시간당 평균 또는 count가 될 수 있다.
대부분의 이슈는 위의 metric으로 해결되지만 조금 까다로운 이슈는 다음 metric이 필요할 수 있다:
- CPU / Errors: machine check exception, CPU cache error(e.g., ECC)
- Memory / Errors: failed malloc() (Linux는 overcommit때문에 이런일은 드물다)
- Network / Saturation: Linux overrun
- Storage controller / Utilization: maximum IOPS나 throughput을 확인
- CPU interconnect / Utilization: 포트별 throughput/maximum bandwidth
- Memory interconnect / Saturation: Mermoy stall cycle, high cycles per instruction
- IO interconnect / Utilization: Bus throughput/maximum bandwidth (e.g., Intel uncore events)
몇몇 소프트웨어 자원들도 비슷하게 검사해볼 수 있다. 예를 들면:
- Mutex lock: lock을 소유했던 시간으로 Utilization을 정의하고, lock을 기다리며 큐잉된 쓰레드들로 Saturation을 정의할 수 있다.
- Thread pools: 쓰레드들이 작업을 수행한 시간으로 Utilization을 정의하고, 작업이 처리되기까지 기다리는 요청들로 Saturation을 정의할 수 있다.
그 외 Process/thread capacity나 File descriptor capacity도 고려해볼 수 있다.
각 metric 타입별 해석은 일반적으로 다음과 같다:
- Utilization: 100%면 보통 병목. 60% 이상은 단위시간에 따라 short burst 떄문에, 또는 하드 디스크와 같은 몇몇 자원처럼 작업중에 interrupt가 불가능한 자원들 때문에, 문제가 될 수 있다.
- Saturation: 0 이상이면 문제가 될 수 있다. wait queue의 길이나 queue에서 보낸 시간등으로 구할 수 있다.
- Errors: non-zero면 조사해볼 가치가 있다.
클라우드나 컨테이너 환경에선, 시스템을 공유하는 tenant를 limit 또는 throttle 해주기 위해 resource control이 걸려있을 수 있다. 예를 들면, Linux container가 자원 사용을 제한하기 위해 cgroups를 사용한다. 물리적 자원을 검사할때와 유사하게 이런 각각의 resource limit도 USE method로 검사 해볼 수 있다.
예로, "memory capacity utilization"는 전체 memory cap 대비 tenant의 memory 사용량이 될 수 있다. "memory capacity saturation"은 호스트 시스템이 memory pressure를 겪고 있지 않더라도, limit-imposed allocation error나 해당 tenant에서의 swapping을 통해 구할 수 있다.
마이크로서비스 아키텍처라면 resource metric이 너무 많아 각 서비스마다 그것들을 일일이 확인하기 힘들 수 있다. Netflix에서는 다음과 같이 접근하고 있다:
- Utilization: 전체 인스턴스 클러스터의 평균 CPU utlization
- Saturation: 99th latency percentile과 average latency간 차이(99th가 saturation 때문이라 가정하고)
- Errors: Request errors
2.5.10 The RED Method
이 methodology는 마이크로서비스 아키텍처의 클라우드 서비스에 집중한다. 유저 관점에서 monitoring health를 하기 위해 다음과 같은 세가지 metric을 식별한다:
- Request rate: 초당 서비스 요청 횟수
- Errors: 실패한 요청 횟수
- Duration: 요청이 완료되기까지 걸린 시간 (평균 외에도 distribution statistic도 고려하라. 2.8절 참고)
USE method가 machine health를 다룬다면, RED method는 user health를 다룬다.
request rate는 중요한 단서를 제공한다: 성능 이슈가 부하 때문인지 아닌지. 만약 request rate가 일정한데 duration이 증가한다면 아키텍처 문제일 공산이 크다. 만약 둘다 같이 올라간다면, 처리해야 할 부하가 문제일 수 있다. 이는 나중에 workload characterization으로 더 살펴볼 수 있다.
2.5.11 Workload Characterization
Workload characterization은 처리해야 할 부하로 인한 이슈의 종류를 파악하는데 있어 간단하고 효과적인 방법이다. 이 방법은 성능 대신, 시스템의 input에 집중한다. 현재 시스템은 아키텍처면에서, 구현면에서, 설정면에서 아무 문제도 없지만 너무 많은 부하가 들어와서 문제를 겪을 수 있다.
Workload는 다음 질문들로 characterized될 수 있다:
- 누가 해당 부하를 야기하는가? 프로세스 ID, 유저 ID, 원격 IP 주소?
- 왜 해당 부하가 생기는가? 코드 경로, stack trace?
- 해당 부하의 특성은 무엇인가? IOPS, throughput, direction (read/write), type?
- 시간에 따라 해당 부하는 어떻게 변하는가? 패턴이 있는가?
다음 시나리오를 보자: 웹 서버 여러대에서 접근하는 데이터베이스에서 performance issue가 생겼다. 어떤 IP 주소에서 데이터베이스를 접근하고 있는지 볼까? 어차피 설정한대로 전부 웹서버에서 접근하고 있는걸텐데.. 라 생각했는데? 그래도 검사해 봤더니? DoS 공격이었다.
최고의 성능 개선은 불필요한 작업을 하지 않는 것. 그러나 확인된 작업을 없애지 못하는 경우도 있다. 그럴 땐 system resource control을 사용해 제어하는 방법도 있다. 예로, 백업 압축에 CPU, 데이터 전송에 네트워크 자원을 사용하는 백업 작업이 프로덕션 데이터베이스에서 일어나고 있다 해보자. 이때 resource control로 CPU와 네트워크 사용량을 조절해 백업 작업이 조금 느려지더라도 데이터베이스 성능을 해치지 않게 할 수 있다.
2.5.12 Drill-Down Analysis
Drill-down analysis는 상위 레벨에서 이슈를 살펴보는 것으로 시작해서, 이전에 찾은 정보를 토대로 점점 좁혀나가고, 별로 중요해보이지 않는건 버리면서, 중요해보이는 곳을 더 깊게 파고들어간다. 다음은 "McDougall, R., Mauro, J., and Gregg, B., Solaris Performance and ... OpenSolaris, Prentice Hall, 2006." 에서 나온 세 단계의 drill-down analysis다:
- Monitoring: 상위 레벨의 통계를 계속 기록하고 문제가 있으면 식별하고 알람을 울린다.
- Identification: 문제가 주어지면, 특정 자원 또는 영역으로 좁혀나가며 잠재적인 병목을 식별한다.
- Analysis: 특정 시스템 영역의 추가적인 조사는 이슈의 근본적인 원인을 찾기 위해 수행된다.
Monitoring은 전사적으로 수행될 수 있으며, 모든 서버 또는 클라우드 인스턴스의 결과들을 집계한다. 이를 위해 예전에는 SNMP(Simple Network Management Protocol)을 사용해 network-attached 장비들을 모니터링할 수 있었다. 최근의 monitoring system은 각 시스템 위에서 metric을 수집하고 배포하는 software agent인 exporter를 사용한다. 이런 데이터들은 monitoring system에 의해 기록되고 front-end GUI에 의해 시각화된다. 짧은 시간동안 CLI를 사용해서 볼땐 안보이던 long-term pattern을 찾을 수 있다.
Analysis tool들은 의심가는 부분을 더 깊게 조사하기 위해 tracing이나 profiling에 기반한 것들을 포함할 수 있다. 이러한 작업은 custom tool을 만들거나 소스코드를 까보는 일을 수반할 수 있다. Linux에서 이런 일을 위한 tool들로는 strace(1), perf(1), BCC tools, bpfrace, 그리고 Ftrace 같은게 있다.
drill-down analysis 단계에서 Five Whys라는 methodology를 사용해 볼 수 있다. 다음 예시를 참고하라:
- 쿼리가 많아지면 데이터베이스 성능이 나빠지기 시작한다. 왜?
- Memory paging으로 인한 disk I/O 때문에 지연이 생긴다. 왜?
- 데이터베이스 메모리 사용량이 너무 커졌다. 왜?
- 할당자가 너무 많은 메모리를 잡아먹고 있다. 왜?
- 할당자에 memory fragment 이슈가 있다.
2.5.13 Latency Analysis
Latency analysis는 작업이 완료되기까지의 시간을 살펴보고 그것을 작은 컴포넌트들로 쪼개서 가장 큰 latency를 가진 곳을 재귀적으로 분석해 근본 원인을 식별하고 수량화할 수 있게 한다. drill-down analysis와 유사하게 latency issue의 근원을 찾기 위해 소프트웨어 스택 각 계틍을 drill down한다.
처리해야 할 workload부터 시작해서, 어떻게 그 workload가 어플리케이션에서 처리되는지 살펴보고, os library, system call, kernel, device driver까지 파고 내려가볼 수 있다. 예를 들어 MySQL query latency 분석을 위해 다음 질문들을 던져볼 수 있다:
- query latency 이슈가 있나? 그렇다.
- query time이 주로 on-CPU에서 쓰이나? 아니면 off-CPU에서 기다리나? off-CPU에서 기다린다.
- off-CPU일땐 무엇을 기다리나? file system I/O를 기다린다.
- file system I/O는 disk I/O 때문인가? 아니면 lock contention 때문인가? disk I/O 때문이다.
- disk I/O 시간은 주로 queueing에 쓰이는가? 아니면 I/O를 수행하는데 쓰이는가? 수행하는데 쓰인다.
- 디스크 수행 시간은 주로 I/O 초기화에 쓰이는가? 아니면 데이터 전송에 쓰이는가? 데이터 전송에 쓰인다.
이 예시에서 각 단계는 latency를 두 파트로 쪼개고 큰 파트를 분석해나가고 있다.
2.5.14 Method R
... 이 부분은 Latency Analysis랑 큰 차이를 모르겠어서 생략한다. 굼금하면 직접 읽어보세요
2.5.15 Event Tracing
시스템은 각각의 이벤트들을 처리하며 수행된다. 여기에는 CPU instruction, disk I/O 그리고 다른 disk commands, network packets, system call, library call, application transaction, database query등을 포함한다. Performance analysis는 보통 이런 초당 작업 횟수, 초당 bytes, 평균 latency 같은 이벤트들의 요약을 분석한다. 가끔 중요한 세부정보가 요약에 누락될때가 있는데 그런 이벤트는 개별적으로 살펴보는게 좋다.
Network 트러블슈팅은 종종 tcpdump(8)같은 tool로 packet-by-packet 조사가 필요하다. 아래 예제는 패킷을 1줄 짜리 텍스트로 요약한다.
# tcpdump -ni ens33 -ttt
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), snapshot length 262144 bytes
00:00:00.000000 IP 192.168.79.135.56814 > 1.1.1.1.53: 35345+ A? v2.velog.io. (29)
00:00:00.000052 IP 192.168.79.135.56814 > 1.1.1.1.53: 53266+ AAAA? v2.velog.io. (29)
00:00:00.006207 IP 1.1.1.1.53 > 192.168.79.135.56814: 53266 0/1/0 (110)
00:00:00.000000 IP 1.1.1.1.53 > 192.168.79.135.56814: 35345 2/0/0 A 13.125.162.37, A 13.209.38.88 (61)
00:00:00.000225 IP 192.168.79.135.52790 > 13.125.162.37.443: Flags [S], seq 3181678417, win 64240, options [mss 1460,sackOK,TS val 3313072316 ecr 0,nop,wscale 7], leng
...block device레벨에서 저장 장치의 I/O는 biosnoop(8)로 trace해볼 수 있다:
# biosnoop
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 ThreadPoolFore 3553 sda W 195074560 8192 0.29
0.000356 jbd2/sda1-8 265 sda W 101062224 81920 0.19
0.000562 jbd2/sda1-8 265 sda W 101062384 4096 0.18
0.469930 kworker/u256:0 3431 sda W 195074568 4096 0.39
0.469941 kworker/u256:0 3431 sda W 2048 4096 0.34
0.469944 kworker/u256:0 3431 sda W 2064 4096 0.31
...biosnoop(8)의 출력은 I/O completion time(TIME(s)), 프로세스 정보(COMM, PID), I/O 종류(T), 크기(BYTES), I/O duration(LAT(ms))들을 포함한다.
위 예제들은 현재 이 글을 쓰고 있는 'Linux dongho-arch 5.16.12-arch1-1 #1 SMP PREEMPT Wed, 02 Mar 2022 12:22:51 +0000 x86_64 GNU/Linux' 환경에서 최신 커널로 테스트 되었다.
tracing하기 좋은 다른곳으로 system call 계층이 있다. Linux에선 strace(1)과 perf(1)의 trace subcommand로 가능하다. Event tracing 할땐 다음 정보들을 찾아라:
- Input: 이벤트 요청의 모든 속성들: 타입, 방향(read/write), 크기 등등
- Time: 시작 시간, 완료 시간, latency
- Result: Error 상태, 이벤트 결과(e.g., 성공적으로 전송한 크기)
request든 result든 이벤트의 속성들을 살펴보는것만으로 performance issue들이 해결될때가 종종있다. 이전 이벤트들을 살펴보는것도 많은 정보를 준다. latency outlier로 알려진, 이례적으로 높은 latency 이벤트는 그 이벤트 자체보단 이전 이벤트들에 의해 발생한걸 수도 있다. 예를 들어, 큐의 꼬리 부분에 있는 이벤트는 높은 latency를 가질 수 있지만 그 자체의 문제라기보다 앞서 큐에 쌓인 이벤트들 때문에 그런걸 수 있다.
2.5.16 Baseline Statistics
흔히들 monitoring solution을 사용해 server performance metric을 기록하고 line chart 같은걸로 시각화 한다. 이런 line chart들은 최근 metric에 어떤 변화가 있었는지 쉽게 보여줄 수 있다.
이런 접근법은 이미 모니터링 되고 있는 metric들에겐 잘 먹히지만, 모니터링 되지 않고 있는 metric들도 많이 있기에 익숙치 않은 시스템의 통계를 볼 때 이게 "정상"인지 판단하기란 쉽지 않은 문제다.
이는 완전히 새로운 문제도 아니고 line chart를 사용한 monitoring solution 이전부터 쓰여온 methodology가 있다. baseline statistics 은 시스템이 "정상" 일때의 metric을 수집해 파일 또는 DB에 기록해둔다. 이 baseline software는 셸스크립트로 작성할 수도 있다.
만약 baseline도 없고 monitoring도 되어있지 않았다면, 몇몇 observability tool의 경우 kernel counter를 기반으로 summary-since-boot 평균을 보여줄 수 있다는 점에 유의하라. 다소 부정확하긴해도 아예 없는것보단 나으니까.
2.5.17 Static Performance Tuning
Static performance tuning은 이미 설정된 아키텍처의 이슈를 다룬다. 다른 methodology들이 처리해야 할 부하의 performance — dynamic performance — 를 다룬다면, static performance analysis는 시스템에 아무 부하가 없을때 수행할 수 있다.
static performance analysis와 tuning을 위해, 시스템의 모든 컴포넌트들에 대해 다음 사항들을 체크하라:
- 컴포넌트가 괜찮은가? (오래되거나, 전력이 부족하거나)
- 처리해야 할 부하에 맞게 설정이 되어 있는가?
- 컴포넌트에 에러가 생겨서 성능이 저하된적이 있는가?
다음은 static performance tuning으로 찾을 수 있는 이슈의 예시들이다:
- 10 Gbit/s가 아닌 1 Gbit/s의 네트워크 인터페이스
- RAID pool 내 실패한 디스크
- 오래된 버전의 OS, 어플리케이션, 펌웨어
- 거의 꽉찬 파일 시스템
- workload I/O size에 맞지 않는 파일 시스템 record size
- 실수로 debug mode로 돌고 있던 어플리케이션
2.5.18 Cache Tuning
I/O 성능을 개선하기 위해 어플리케이션부터 디스크까지 여러 cache를 사용할 수 있다. 각 cache 계층을 튜닝하는 일반적인 전략은 다음과 같다:
1. 가능한 한 실제 작업이 수행되는 곳 가까이, 상위 스택을 캐싱해서 cache hit의 operational overhead를 줄이도록 한다. 이 위치는 더 많은 메타데이터를 담고 있어 cache retention policy를 개선하는데 도움이 된다.
2. cache가 활성화 되어있고 작동하고 있는지 확인한다.
3. cache hit/miss ratio와 miss rate을 확인한다.
4. cache size가 동적이라면 현재 size를 확인한다.
5. workload에 맞게 cache를 튜닝한다.
6. workload를 cache에 맞게 튜닝한다.
double caching에도 유의한다 — 같은 데이터를 캐싱하고 있는 서로 다른 두 cache.
각 계층에서 cache tuning으로 얻을 수 있는 전체적인 성능 이득에 대해서도 고려하라. CPU Level 1 cache는 cache miss가 나도 Level 2가 있어 수 나노초의 차이 정도지만 CPU Level 3은 잘하면 훨씬 느린 DRAM 접근을 피할 수 있어 훨씬 더 많은 성능 이득을 얻을 수 있다.
2.5.19 Micro-Benchmarking
Micro-benchmarking은 간단하고 인위적인 workload의 성능을 테스트한다. macro-benchmarking (또는 industry benchmarking)는 real-world의 실제 workload를 다룬다는 차이가 있다. Macro-benchmarking은 수행하고 결과를 해석하기 비교적 까다롭다.
더 적은 요소들 덕에, micro-benchmarking은 좀 더 쉽게 수행하고 결과를 해석할 수 있다. 흔히 사용되는 micro-benchmark는 Linux iperf(1)로 TCP throughput test를 수행해서 외부 네트워크 병목을 식별하는 것이다.
Micro-benchmarking은 micro-benchmark tool을 사용해 workload를 처리하고 성능을 측정해서 수행하거나 load generator tool로 workload만 처리하고 성능 측정은 다른 observability tool로 할 수 있다. 뭘하든 둘 다 상관 없지만, micro-benchmark tool를 사용하고 다른 도구로 한번 더 확인하는게 제일 안전할 것이다.
micro-benchmark 대상의 예시들로는:
- Syscall time: fork(2), execve(2), open(2), read(2), close(2)
- File system reads: cache된 파일로부터 읽는 크기를 1byte 부터 1Mbyte까지 바꿔가며 테스트
- Network throughput: TCP 종단간 데이터 전송을 socket buffer size를 바꿔가며 테스트
2.5.20 Performance Mantras
성능을 개선시키는 가장 좋은 tuning methodology들을 가장 효과적인 순으로 아래 나열했다:
- 하지 마라 -> 불필요한 작업을 없애라
- 해도, 또 하진 마라 -> caching
- 적게 해라 -> refresh, pollig, update를 더 적게 하도록 tuning
- 나중에 해라 -> write-back caching
- 시스템이 한가할때 해라 -> off-peak으로 스케줄링
- 병렬로 해라 -> 싱글쓰레드에서 멀티쓰레드로 변경
- 더 싸게 해라 -> 더 빠른 하드웨어 구입
Modeling
시스템의 analytical modeling은 다양한 목적으로 활용될 수 있는데, 특히 부하 또는 자원이 증가함에 따라 performance scale이 어떻게 변화하는지 알기 위한 scalability analysis가 그렇다. 이때 자원은 CPU core와 같은 하드웨어 또는 프로세스나 스레드 같은 소프트웨어가 될 수 있다.
Analytical modeling은 observability(measurement), experimental testing(simulation)에 이은 performance evaluation activity의 세번째 타입으로 생각할 수 있다.
만약 기존 시스템을 분석하고자 한다면 measurement부터 시작할 수 있다. 부하 특성을 파악하고 성능을 분석한다. 부하가 따로 없거나 현재 부하 이상을 테스트 하기 위해서는 simulation을 사용할 수 있다. 그리고 analytical modeling을 통해 위 measurement와 simulation의 결과를 예측하고 비교해 볼 수 있다.
scalability analysis를 통해, 성능이 자원의 한계로 인하여 특정 지점에서 선형적으로 scailing되지 않는 knee point를 미리 찾아 production에서 맞닥뜨릴 수 있는 문제를 조기에 해결할 수 있다.
2.6.1 Enterprise vs Cloud
modeling이 큰 스케일의 전사 시스템을 실제 소유하는 비용없이 시뮬레이션 할 수 있게 해주지만, 이런 환경에서의 성능은 정확히 modeling 하기에 종종 너무 복잡하고 어렵다.
cloud computing으로 어느 스케일의 환경이든 벤치마크를 하기 위한 짧은 기간만 대여할 수 있게 되었다. 수학적인 모델을 만들어서 성능을 예측하는 대신, 다양한 스케일의 클라우드 환경에서 부하를 정의하고 시뮬레이션하고 테스트해볼 수 있다. 덕분에 modeling에서 놓칠 수 있었던 knee point들 같은 것들을 발견할 수도 있다.
2.6.2 Visual Identification
x축을 scalability 차원, y축을 performance(throughput, transaction per second 같은)라 했을때 다음과 같은 패턴들을 찾을 수 있다:
- Linear scalability: 자원이 확보될수록 성능도 이에 비례하여 증가
- Contention: 일부 자원들은 서로 공유되며 오직 한번에 하나의 컴포넌트만 접근할 수 있는 경우가 있는데, 이렇게 공유되는 자원을 둘러싼 경쟁은 scaling의 효율을 떨어트린다.
- Coherence: scaling을 해서 얻는 이득보다 propagation, data coherency에 드는 비용이 더 커지는 경우
- Knee point: 패턴이 바뀌는 변곡점
- Ceiling: 버스의 최대 throughput 또는 resource throttling 같은 병목으로 인해 도달한 hard limit
2.6.3 Amdahl's Law of Scalability
serial resource 또는 workload component의 contention을 다룬다.
수식으로 정리한 형태는:
- C(N)는 relative capacity. 즉 전혀 병렬처리 되지 않는 작업 대비 전체 수행시간이 몇배 단축되는지
- N은 CPU 갯수나 user load 같은 scaling dimension
- 매개변수()는 직렬성의 정도로, 얼마나 선형적으로 스케일링 되기 어려운지 나타낸다.
구체적인 단계는 다음과 같다.
1. 범위 N의 데이터 수집. scaling dimension에 해당하는 x축과 성능이 몇배 개선되는지에 해당하는 y축을 구하는데 사용
2. 회귀 분석을 통해 Amdahl parameter () 계산
3. 이를 그래프로 그려 modeling한 함수와 실제 수집한 데이터간 차이를 확인하고, 스케일링이 어떻게 될것이지 예측
다음 절로 넘어가기 전에 함수가 어떻게 저렇게 나오는지 짚고 넘어가자.
을 1개의 프로세서로 작업을 수행했을때 걸린 시간이라 하고,
는 직렬로 수행되는 작업의 비율, 는 병렬로 처리되는 작업의 수행시간을 몇배 단축시켰는지 나타낸다 할 때,
이라 할 수 있다.
그럼 병렬 처리를 전혀 하지 않은 대비 얼마나 속도가 빨라질지 나타내는 함수 은 로 식을 정리하면 처음 식이 나온다.
얼마 전에 정리한 Amdahl's Law와 햇갈렸던 부분은
전체 수행시간 중 비율 을 차지하고 있는 컴포넌트의 속도를 배 개선했을때, 전체 수행시간은 배 빨라진다.
Amdahl's Law of Scalability에서는
병렬 처리되지 못하는 컴포넌트의 비율이 이고 병렬 처리되는 작업의 속도를 배 개선했을때, 전체 수행시간은 배 빨라진다.
약간 서로 다루는게 다르므로 햇갈리지 말자.
2.6.4 Universal Scalability
과거 super-serial model이라고도 불렸던 Universal Scalability Law(USL)은 Dr. Neil Gunther가 coherence delay도 고려하기 위해 만들었다. contention의 영향도 같이 고려하면서 coherence scalability pattern도 보여주는 USL은 다음과 같이 정의할 수 있다:
, , 는 Amdahl's Law of Scalability에 나온것과 같고, 는 coherence 매개변수다. 만약 가 0이라면 Amdahl's Law of Scalability와 동일하다.
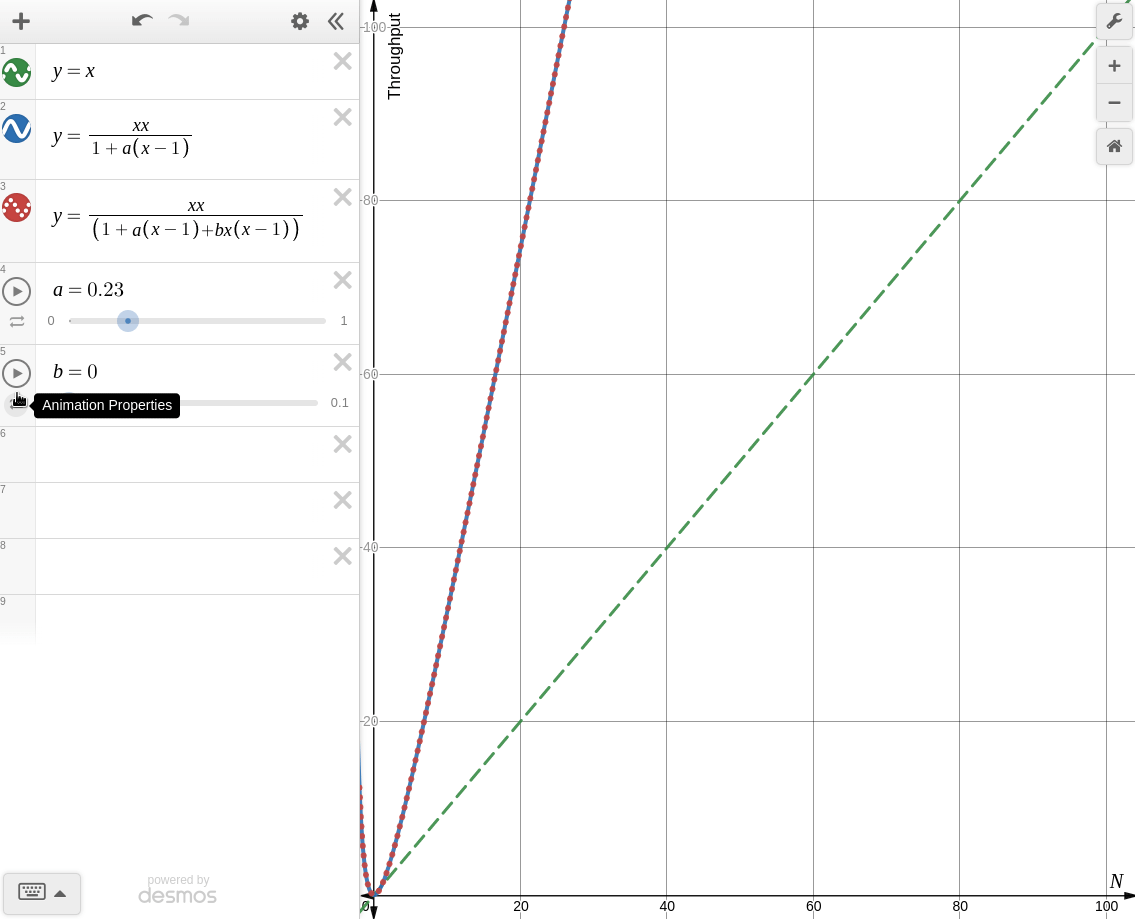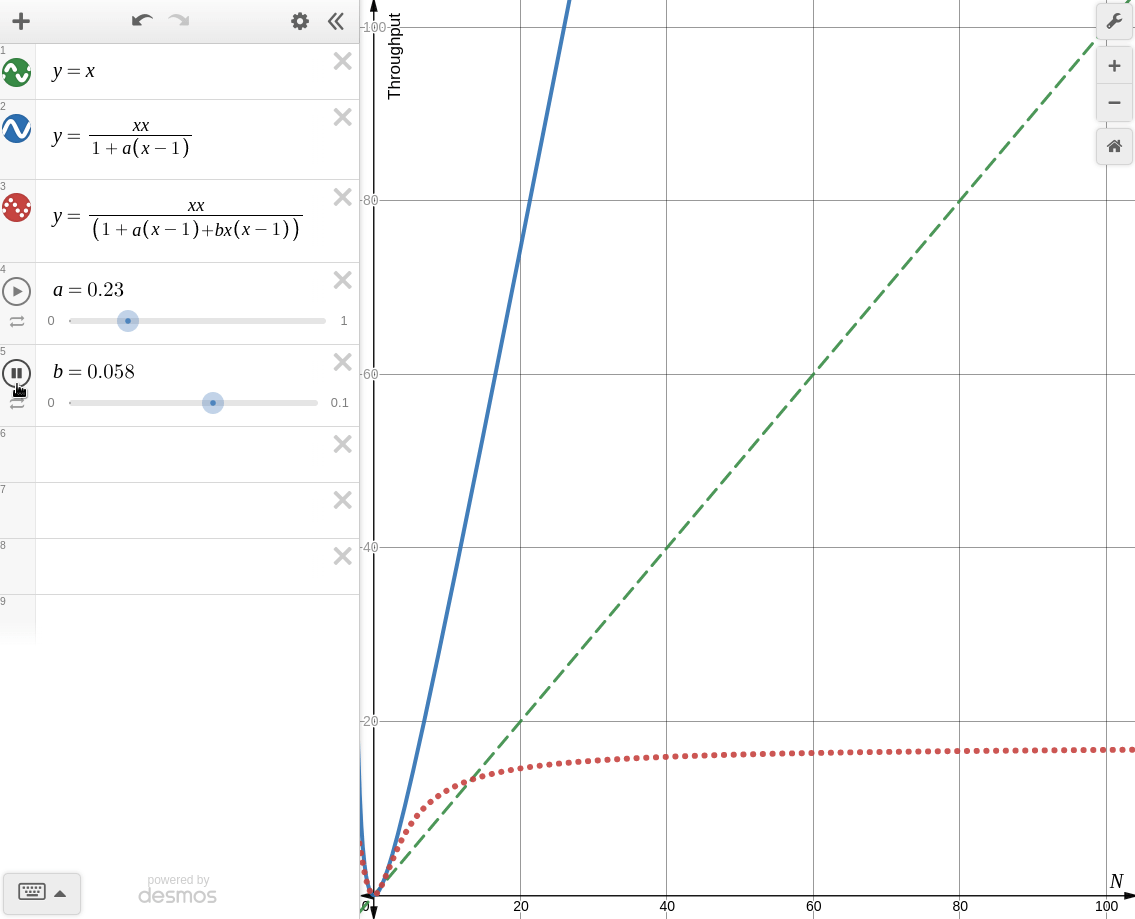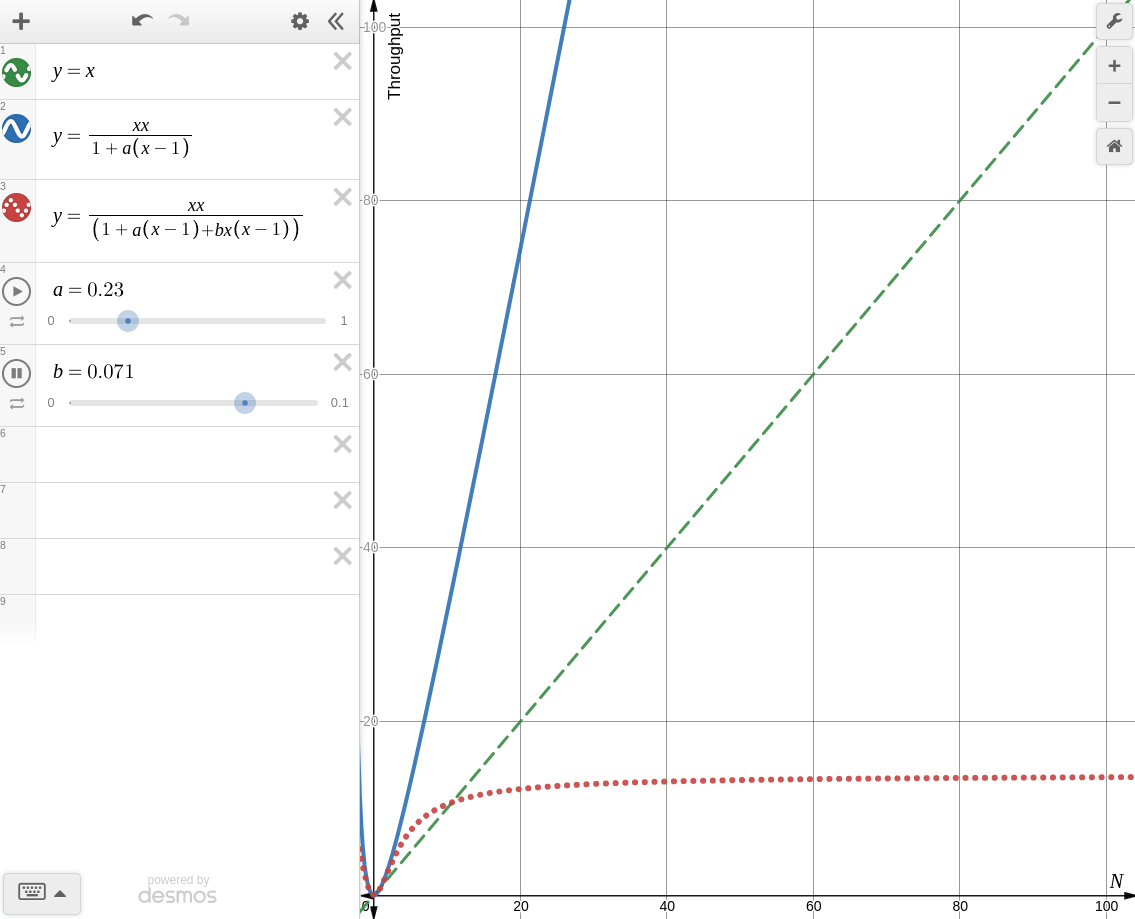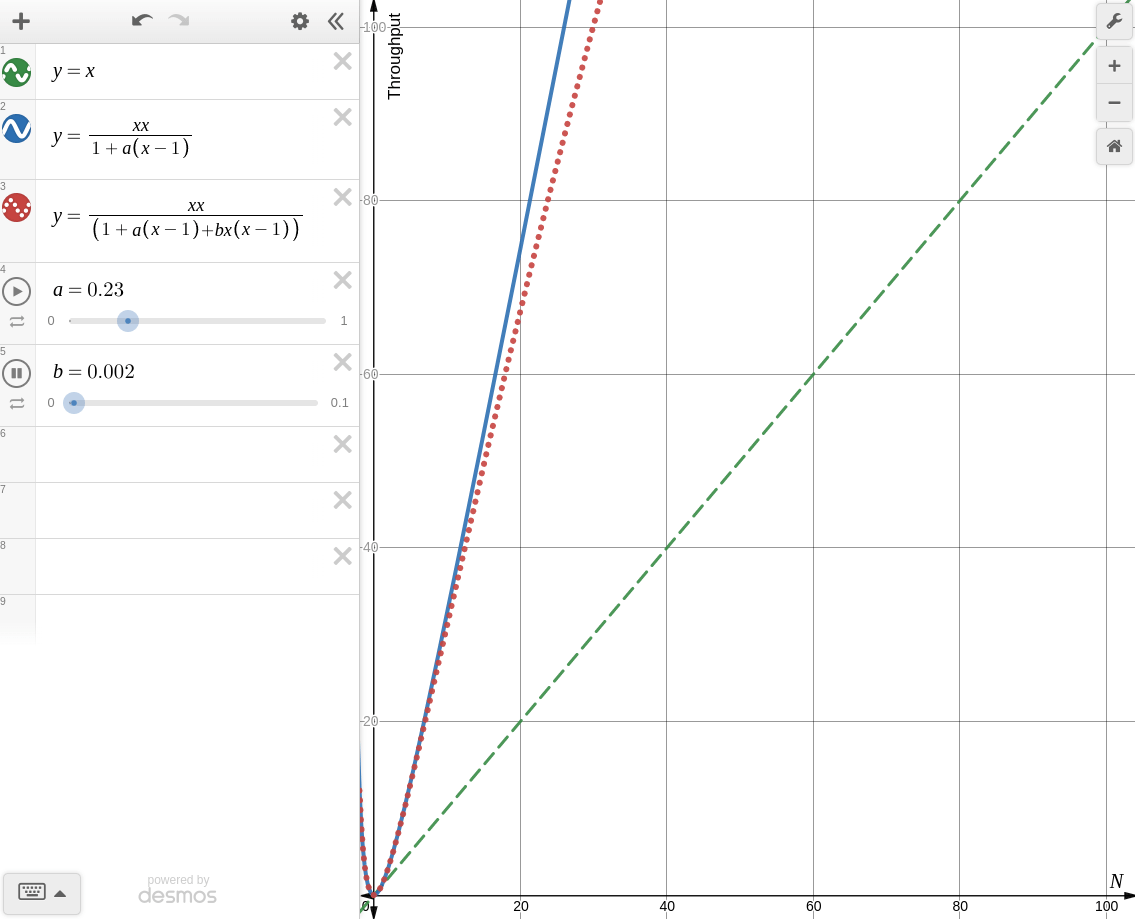
한번 desmos로 각각의 경우를 그려보면 아래와 같다.
-
: coherence를 고려하지 않을 때
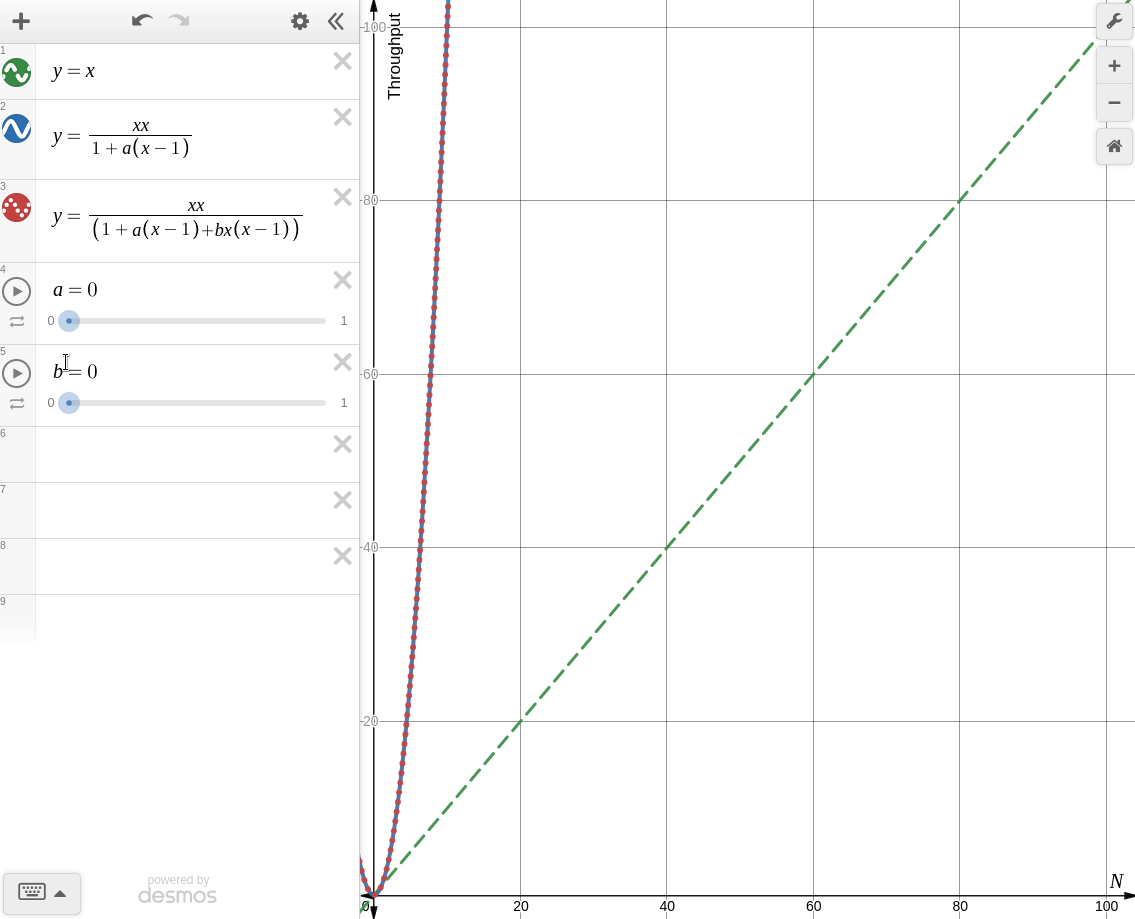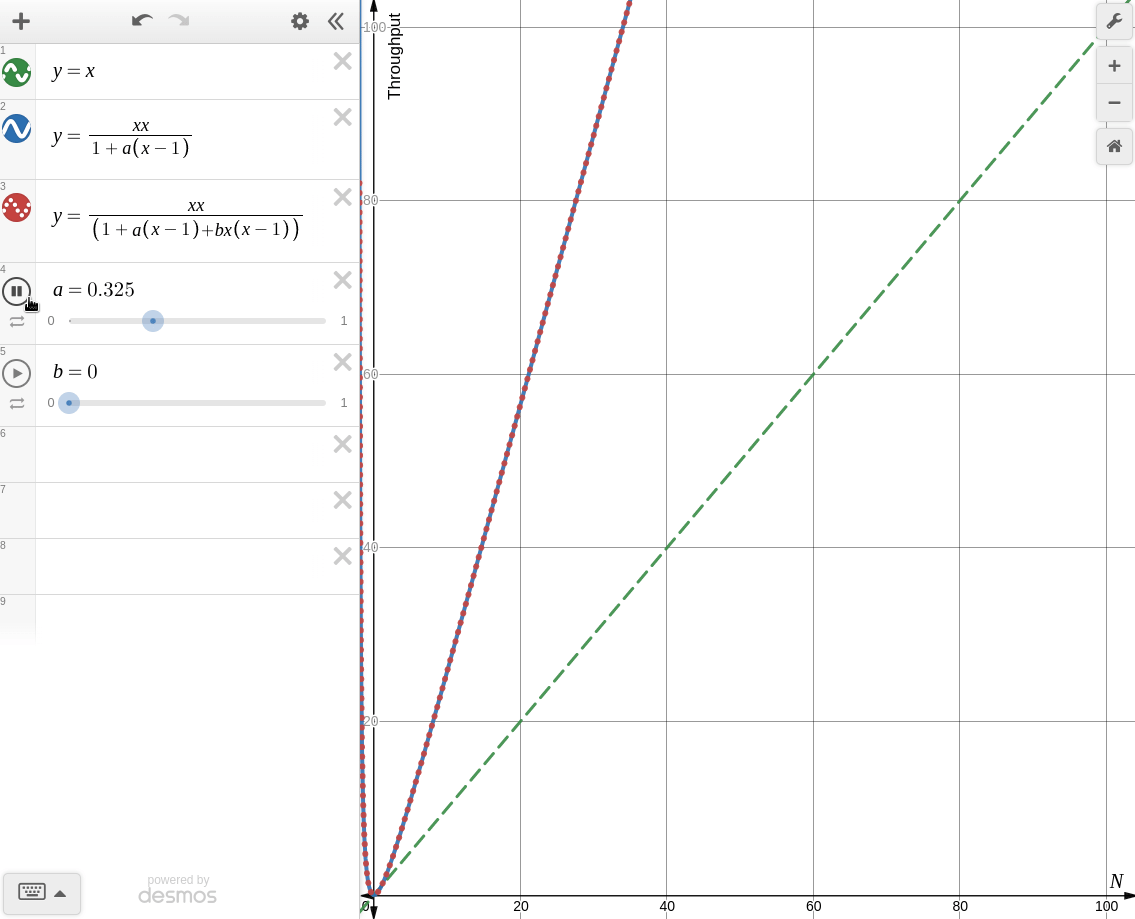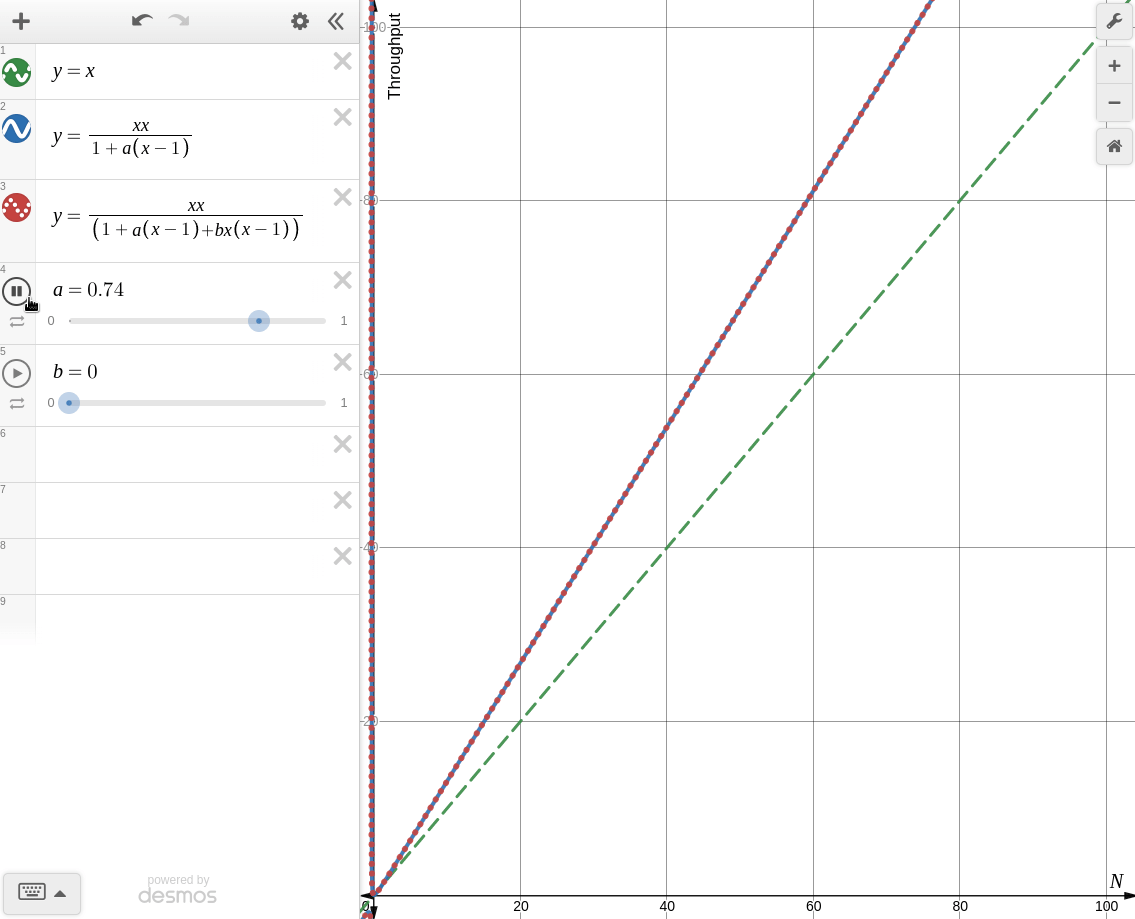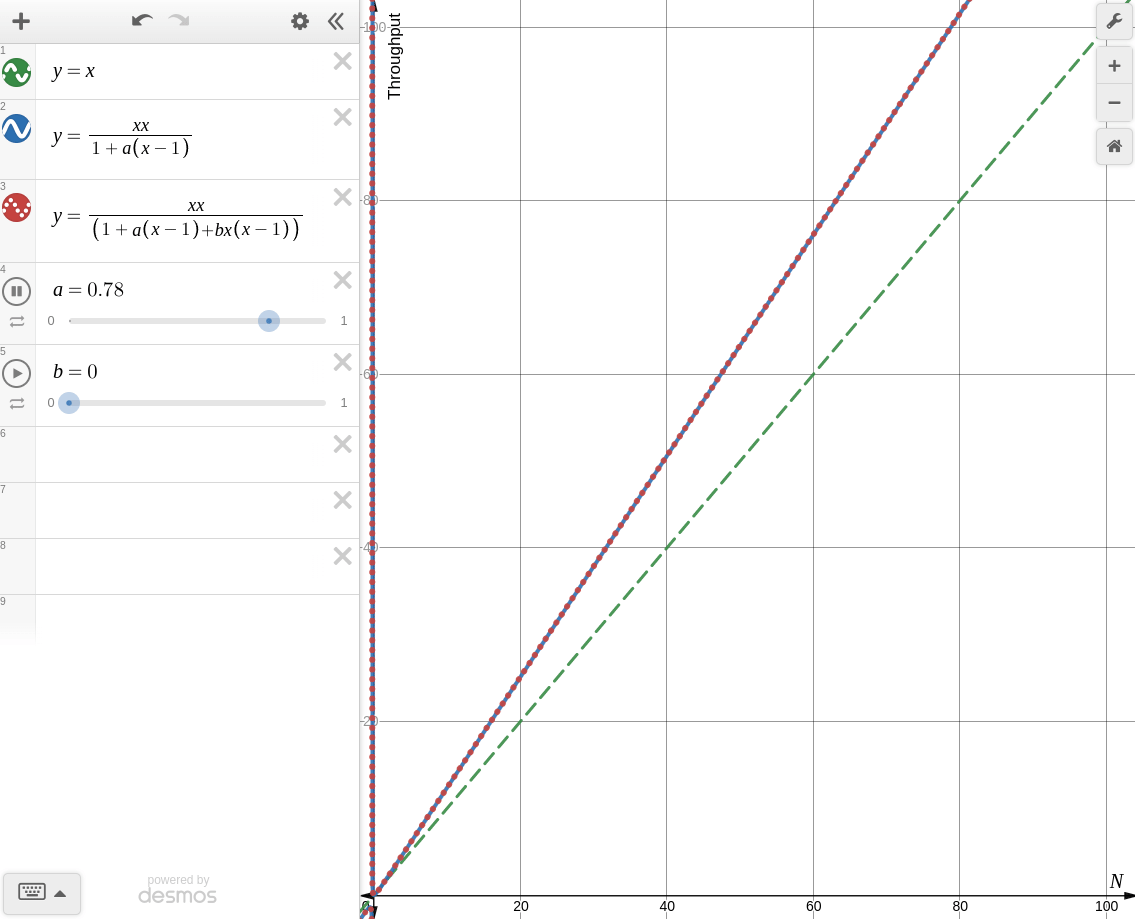
Amdahl's Law of Scalability와 동일한 양상을 보인다. -
: coherence를 고려할 때
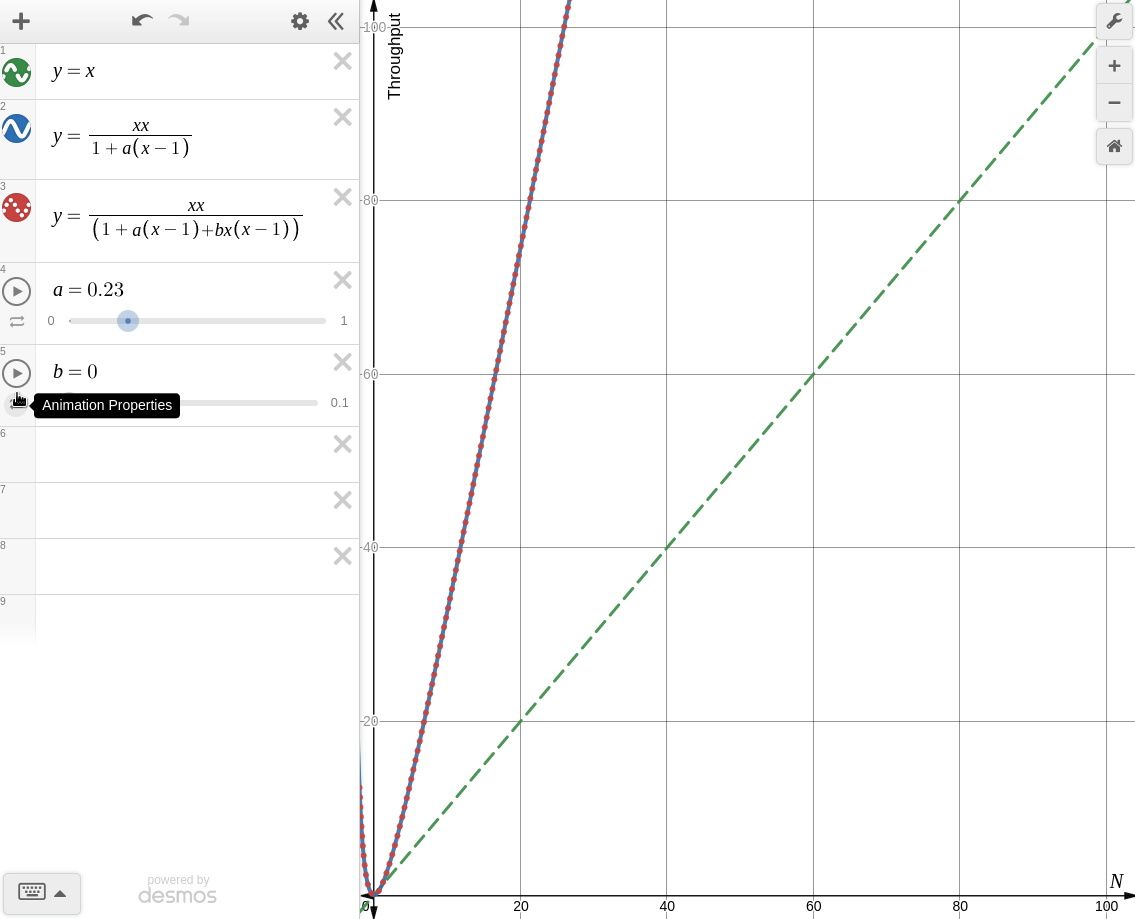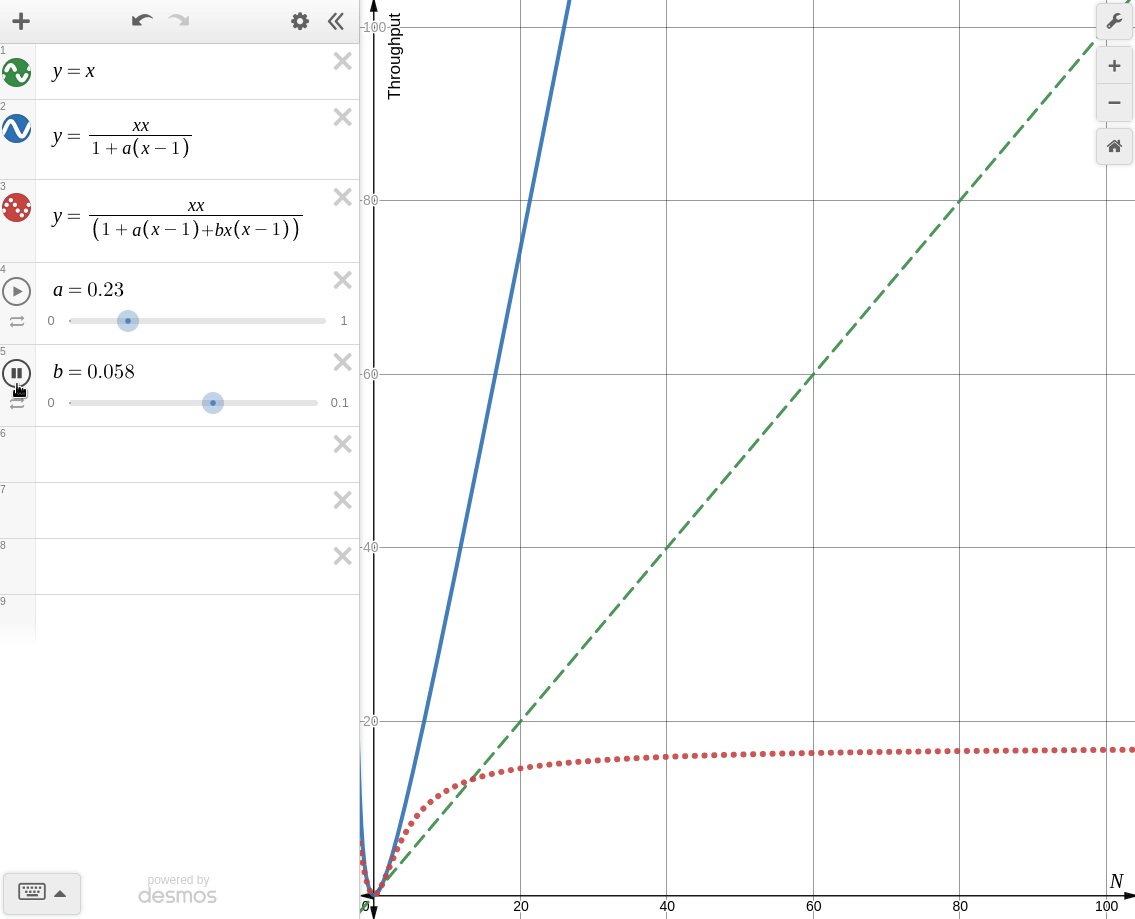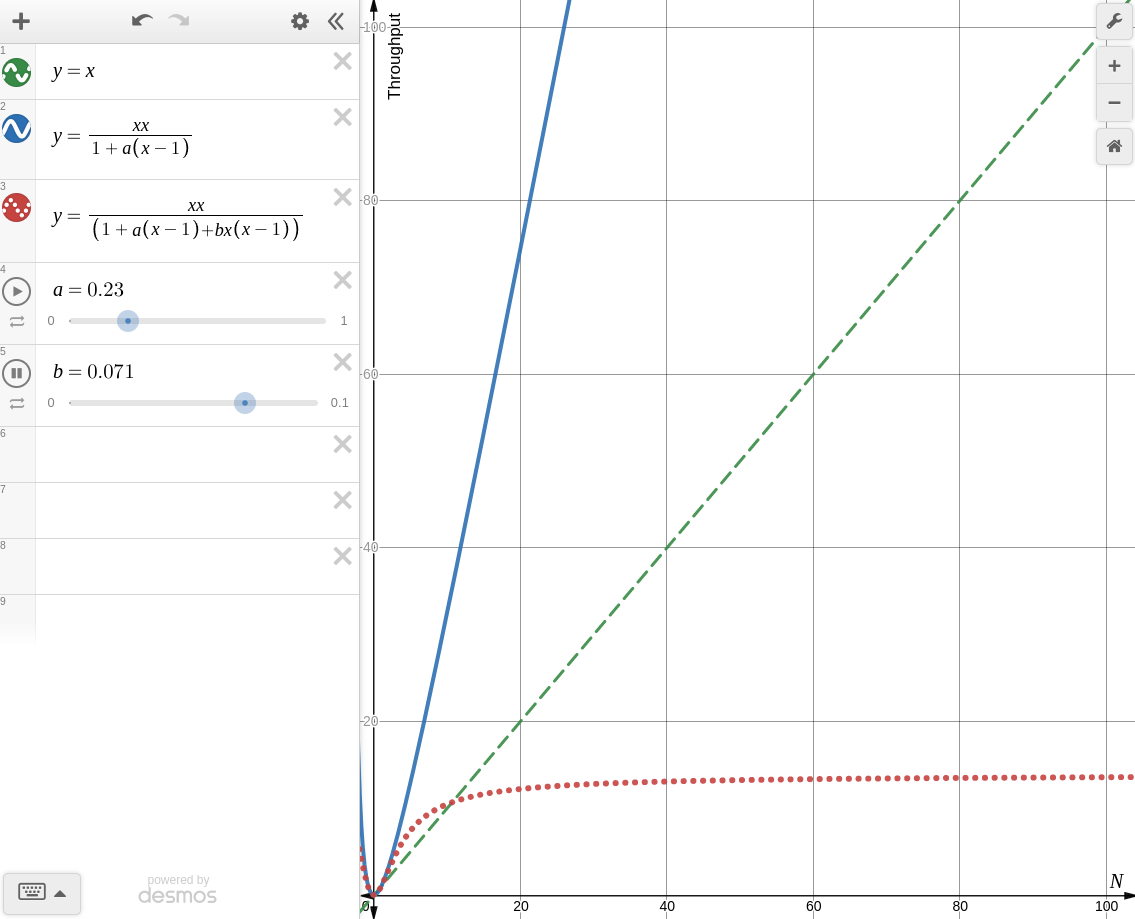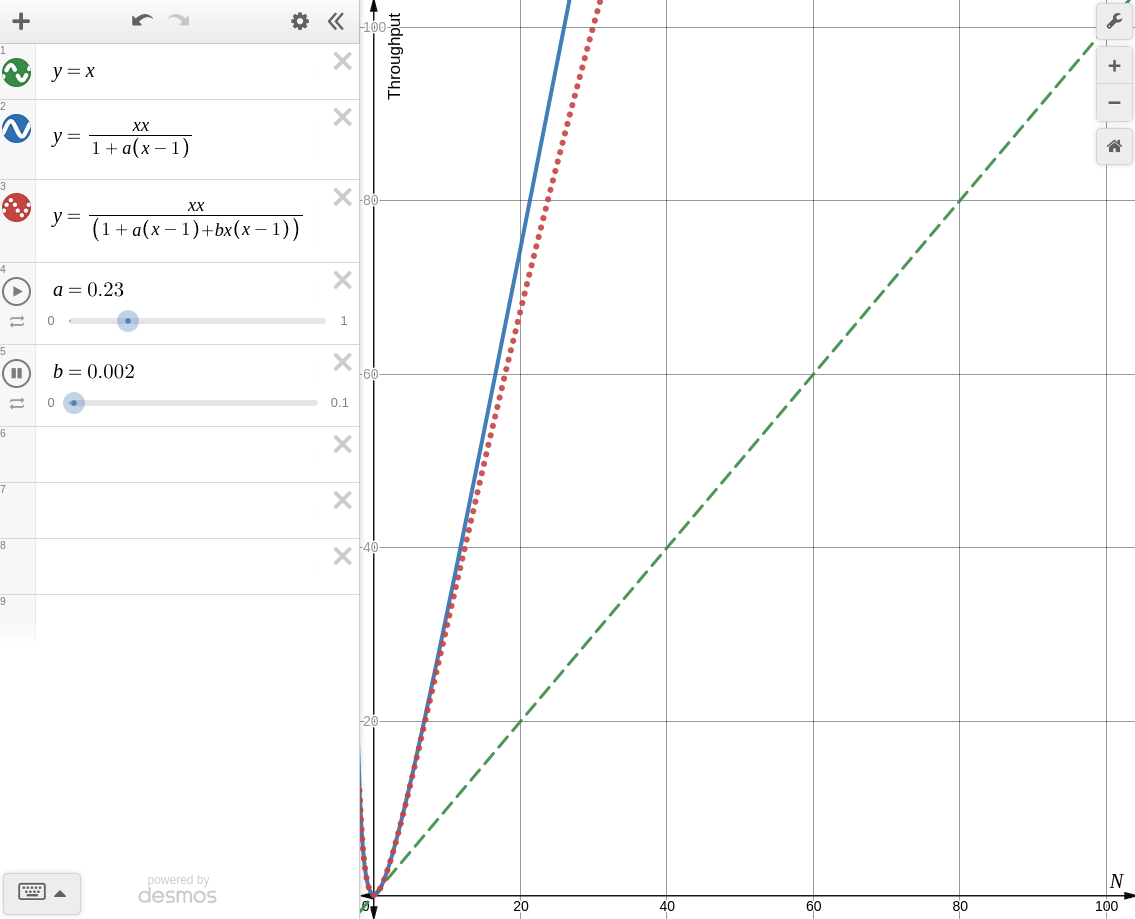
knee point가 생기는 것을 볼 수 있다. 때문에 coherence가 존재하는 시스템에서 무작정 병렬처리를 한다면 컨텍스트 스위칭, 버스 병목, 락 대기등의 이유로 오히려 성능이 더 떨어지는 경우가 생길 수 있다.
2.6.5 Queueing Theory
Queueing theory는 큐를 가진 시스템의 큐 길이, 대기 시간(latency), utilization(time-based)같은 것들을 분석할 수 있게 해준다. 소프트웨어 하드웨어 할것 없이 컴퓨터의 많은 컴포넌트들은 queueing system으로 모델링할 수 있는데, 이 여러 queueing system들의 모델링은 queueing networks라 한다.
이 절은 queueing theory의 개요만 짚고 넘어갈텐데, 워낙 방대한 분야라 자세한 내용들은 Jain 91, Gunther 97를 참고
queueing theory는 probability distribution, stochastic process, Erlang's C formula, Little's Law와 같은 수학과 통계에 기반한다. Little's Law는 다음과 같이 표현될 수 있다:
시스템의 평균 요청 수를 결정하는 은 평균 요청율 에 평균 요청시간 를 곱해 결정된다. 이를 큐에 적용하면, 은 큐 대기열 길이, 는 큐 평균 대기 시간이 되겠다.
queueing system은 다음과 같은 질문들에 답하는데 활용될 수 있다:
- 부하가 2배가 되면 평균 응답 시간은 어떻게 될것인가?
- 프로세서를 추가하면 평균 응답 시간은 어떻게 될것인가?
- 부하가 2배가 되도 p90 응답 시간이 100ms 아래를 유지할 수 있을까?
응답 시간뿐만 아니라 utilization, queue length, number of resident jobs 같은 것들도 분석할 수 있다.
간단한 queueing system model을 그림으로 그려보면 아래와 같다.
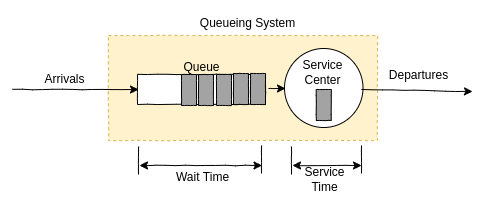
여기선 단일 service center가 작업을 처리하지만 여러개의 service center가 병렬로 작업을 처리할 수도 있다. queueing theory에서 service center는 종종 server라고도 불린다.
Queueing system은 다음 세가지 요소로 분류할 수 있다:
- Arrival process: queueing system에 들어오는 요청 주기를 다룬다. 이 주기는 무작위거나 고정일 수 있고 Poisson같은 분포를 따를 수 있다. 여기서 사용되는 process란 용어는 확률론에서 시간의 진행헤 대해 확률적인 변화를 구조를 의미한다.
- Service time distribution: service center의 service time을 다룬다. 처리하는 데 걸리는 시간은 고정(deterministic)이거나 exponential하거나 다른 분포를 따를 수 있다.
- Number of service centers: 하나 거나 여러개
그리고 이러한 요소들은 Kendall's Notation으로 표현이 가능하다.
각각 Arrival process, Service time distribution, number of service centers를 의미한다. 이를 확장해 시스템의 버퍼 갯수, population size(size of calling source), service discipline(FIFO, PQ, ...) 등을 포함하는 경우도 있다.
일반적으로 연구되는 queueing system들은:
- M/M/1: Markovian arrivals(arrival time 분포가 exponential한), Markovian service times(exponential distribution), one service center
- M/M/c: M/M/1과 같지만 server가 여러개
- M/G/1: Markovian arrivals, general distribution of service times (any), one service center
- M/D/1: Markovian arrivals, deterministic service times (fixed), one service center
이 중 M/G/1은 회전식 하드디스크의 성능을 분석하는데 활용된다.
(다음으로 넘어가기 전에 Markovian arrival process에 대해 좀 더 알아보고 싶었지만 아직 기반 지식이 부족해 나중에 준비가 되면 따로 정리하고 싶다.)
M/D/1에 Utilization 60%
queueing theory의 간단한 예로, workload를 deterministic하게 처리하는 디스크를 고려해보자. 이 모델은 M/D/1이다.
utilization이 증가하면 디스크의 응답 시간은 어떻게 변할까? 라는 질문에 답하기 위해 다음 정리를 이용할 수 있다.
M/D/1의 응답 시간은
각각 response time, service time, =utilization를 의미한다.
이를 그래프로 그린 형태는 아래와 같다.
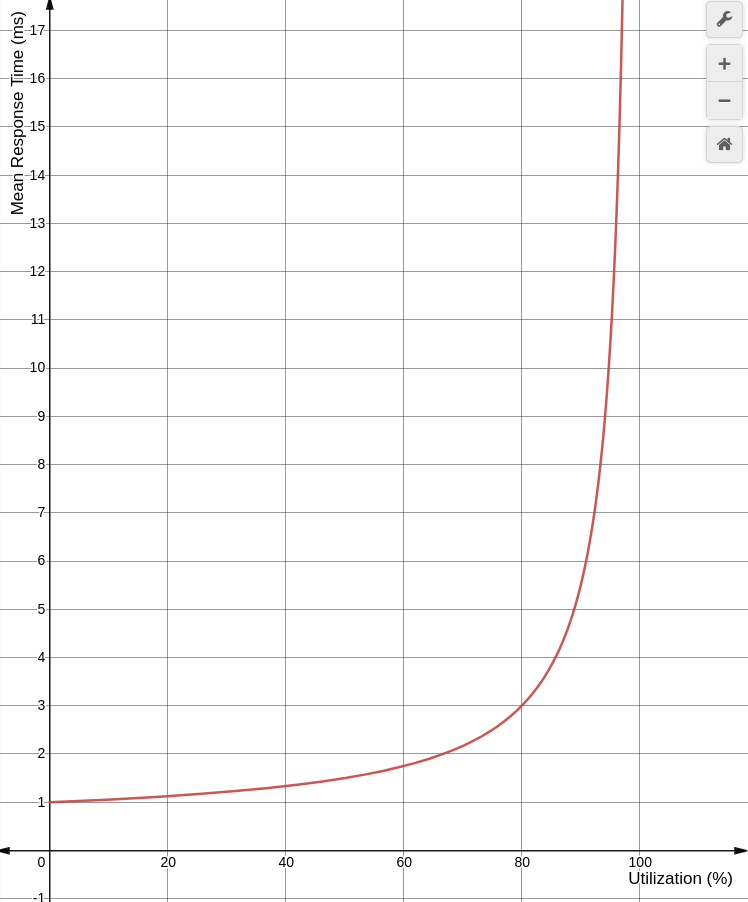
utilization이 60%가 되면 평균 응답 시간은 2배가 되고, 80%가 되면 3배가 된다. disk I/O latency 가 종종 성능의 병목이 된다는걸 감안하면, 이렇게 크게 평균 latency가 증가하는것은 성능에 큰 악영향이 될 수 있다. 때문에 disk의 utilization은 100% 되기 전에 먼저 문제가 터질 수 있는것이다. CPU와 같이 더 높은 우선순위를 가진 작업이 preempt할 수 있는 자원은 이에 해당하지 않는다.
2.7 Capacity Planning
Capacity planning은 시스템이 부하를 얼마나 잘 처리할 것인지, 부하가 늘어날수록 어떻게 scaling 될건지를 다룬다. resource limit을 분석하거나 factor analysis를 수행하는 식의 다양한 방식으로 수행할 수 있다.
2.7.1 Resource Limits
이 방법은 어떤 부하가 들어왔을때 병목이 될만한 자원을 찾는데 사용된다.
먼저 server의 역할과 어떤 유형의 요청을 받는지 식별한다. 예를 들어, web server는 HTTP 요청을 받고, Network File System(NFS)는 NFS 프로토콜 요청을 받고 database server는 query 요청을 받는다.
다음으로 요청마다 시스템의 자원 소모량이 어떤지 파악한다. 그리고 외삽법으로 어떤 자원이 가장먼저 100% utilization에 도달하게 될지, 그 때의 요청 주기는 어떻게 될지 알아낸다.
나중을 위해, micro-benchmarking 또는 load generator를 사용해 테스트 환경에서 시뮬레이션도 가능하다. 부하를 충분히 늘려가며 자원의 utilization을 측정하면 실험적으로 limit을 찾을 수 있다.
모니터링할 자원들에는 다음과 같은 것들이 있다:
- Hardware: CPU utilization, memory usage, disk IOPS, disk throughput, disk capacity(volume used), network throughput
- Software: Virtual memory usage, processes/tasks/threads, file descriptors
현재 1000 requests/s의 속도로 작업을 수행중인 시스템이 있다 하자. 가장 바쁜 자원은 평균 utilization이 40%인 16개의 CPU들이다. 만약 이것들의 utilization이 100%가 되면 곧 병목이 될것이다. 이 때 초당 요청수는 얼마가 될까?
마지막 식의 /s가 어디서 나왔는지 처음에 잘 이해가 되지 않았다. 그런데 우리가 처음 계산한 식에서 를 구할 때 를 사용했는데 여기서 쓰인 는 사실 1000 requests/s 에서 나온 값이다. 즉 처음에 계산한 는 요청이 하나 들어왔을때 CPU 하나가 1초동안 0.64초가 쓰인다고 이해할 수 있을것이다.
다음으로 은 이전에 구한 가 언제 100%가 되는지 그리고 그때의 requests는 얼마인지를 구하는것으로 시작한다.
즉 개의 요청이 들어오면 CPU 하나의 Utilization이 100%가 되는것을 알 수 있다. 그런데 여기서 사용한 CPU%의 단위 시간은 1초였다. 즉 다시말해 "초당" 156.25개의 요청이 들어오면 CPU 하나의 Utilization이 100%가 되니 CPU 16개가 모두 100%가 되는 requests (per second)는 이 되는것이다.
2,500 requests/s가 충분할지는 peak workload가 어떨지에 따라 다르다. 예를 들어 하루에 100,000개의 요청을 처리하는 웹 서버가 있을때 1 request/s 는 별로 많아 보이지 않지만, 100,000개의 요청 대부분이 특정 시간에 몰려있다면 얘기가 달라진다.
2.7.2 Factor Analysis
새로운 시스템을 구매하고 배포할때, 원하고자 하는 성능을 최소 비용으로 달성하기 위해 고려해야 할 factor(요소)들이 많다. 디스크나 CPU 갯수, RAM 크기, flash 장치, RAID 설정 등등을 조절하는것들이다.
모든 조합들을 테스트 해보면 최적의 가성비 조합을 알 수 있겠지만, 당장 8개의 binary factor만 해도 256개의 조합이 나오는것을 보면 어려워 보인다는 것을 알 수 있다.
모든 조합을 다 테스트 해보는 대신, maximum system configuration을 기반으로 다음과 같이 접근해 볼 수 있다:
1. 모든 factor들을 최대치(가장 좋고 비싼?)로 했을때의 성능을 테스트
2. 각각의 factor들을 하나씩 줄여보며 성능을 테스트
3. (2)에서 각각의 factor들을 줄일때마다 성능이 얼마나 떨어졌는지, 절약한 비용은 얼마인지 테스트
4. 최대치의 성능(과 비용)부터 시작해, 요구사항을 만족하면서 어떤 factor들을 줄여야 최대한 비용이 줄어들지 알아낸다.
5. 실제로 해당 factor들의 조합으로 원하는 성능이 잘 나오는지 확인해본다.
예를 들어, 새로운 storage system의 capacity planning을 한다고 하자. 요구사항은 1 GB/s의 read throughput과 200GB의 working set size다. maximum configuration에선, 프로세서 4개, 256GB RAM, dual-port 10 GbE 네트워크 카드 두개, jumbo frame, 암호화와 압축 없이, 2GB/s의 성능을 달성했다고 하자. 프로세서를 2개로 줄였더니 30%, 네트워크 카드를 한개 줄였더니 25%, non-jumbo frame을 썼더니 35%, 암호화 했더니 10%, 압축 했더니 40% 성능이 떨어졌고 DRAM을 90% 줄였더니 더이상 workload가 완전히 캐싱되지 않았다. 각각 성능을 얼마나 떨어뜨리는지, 그리고 얼마나 비용을 절약할 수 있는지 알아냈으므로, 요구사항을 만족하는 최적의 성능/비용 조합을 계산할 수 있다: 프로세서 2개에 네트워크 카드 하나만 쓰면 GB/s의 성능을 만족할거라 예상할 수 있다. 물론 이것들의 조합이 각각 완전히 독립적이라는 보장은 없으므로 직접 테스트 할 필요가 있다.
2.7.3 Scaling Solutions
더 높은 성능을 위해 vertical scaling과 같이 더 큰 시스템을 구축하거나, horizontal scaling과 같이 부하를 여러 시스템에 분산시키되 load balancer를 사용해 하나로 보이게 하는 방법이 있다.
AWS에는 auto scaling group (ASG)라는 기술이 있어 사용량에 따라 자동으로 인스턴스를 늘리고 줄이고 할 수 있다. Container ochestration system도 k8s의 horizontal pod autoscaler (HPA) 같은걸 활용해 CPU utilization이나 다른 metric같은걸 기반으로 Pod 갯수를 조절할 수 있다.
데이터베이스에선 일반적으로 sharding이란 방법이 있다. 데이터를 여러개의 논리적 컴포넌트로 쪼개 각각의 데이터베이스에서 관리하는 것이다. 예를 들어, customer database를 customer name의 알파벳으로 쪼갤수 있다. 부하를 데이터베이스에 균등하게 나누기 위해선 샤딩키를 어떻게 고르느냐가 중요하다.
2.8 Statistics
이 절에서는 통계적 기법을 사용해 performance issue들을 수량화 하는것을 다룬다.
2.8.1 Quantifying Performance Gains
이슈들과 그것을 고침으로써 얻을 수 있는 이득을 수량화 하는것은 업무의 우선순위를 정할 수 있게 해준다. 크게 관측 또는 실험으로 수행할 수 있으며 자세한 설명은 생략한다.
2.8.2 Averages
평균은 데이터셋을 값 하나로 표현한다. 여러 종류가 있는데 그 중 가장 흔히 쓰이는 arithmetic mean(짧게 mean, 산술 평균)은 값을 전부 더해 값의 갯수로 나눈것이다. 외에도 몇가지가 더 있는데..
Geometric Mean
geometric mean(기하 평균)은 값의 갯수가 n이라 할때, 모든 값을 곱한 값에 1/n 승을 취한 값이다. 예를 들면 커널 네트워크 스택 각 계층의 성능이 10%, 50%, 70% 개선되었다고 하자. 패킷은 모든 계층을 거치게 되므로 각 개선의 효과는 곱으로 계산된다. 따라서 각 계층에서 평균적으로 (41.02%) 만큼 개선되었다고 볼 수 있다. 만약 이를 그냥 산술 평균으로 계산하면 (43.33%)로 각 값을 검산해보자.
이런 식으로 성능 개선의 효과가 곱으로 적용되는 경우는 기하 평균이 더 적합하다.
Harmonic Mean
harmonic mean(조화 평균)은 값의 갯수를 각 값의 역수들의 합으로 나눈 값이다. 속도의 평균을 구하는데 적합하다. 예로 800 MB짜리 데이터의 평균 전송 속도를 계산해보자. 첫번째 100 MB는 50MB/s로 전송되고 나머지 700MB는 10 MB/s로 전송된다고 할때 평균 전송 속도는 MB/s
그런데 이게 값의 갯수?와 값의 역수?랑 어떤 연관이 있는지 햇갈린다. 그냥 여기서 속도가 라 생각하고 계산하는게 이해가 더 쉬울것 같다.
Averages over Time
많은 metric들이 시간 기반의 평균이다. CPU가 특정 시점에 딱 50% utilization이었다던가 그런건 없다. 그건 "일정 시간"(초당, 분당, 시간당, ...) 중 "50%"가 utilized 되었다란 뜻이다. 평균을 다룰땐 이 시간을 잘 확인해야 한다.
예를 들면, monitoring tool로 CPU utilization을 보니 80%를 넘은적이 없는데도, CPU saturation(scheduler latency)를 겪고 있다고 해보자. monitoring tool이 5분 평균의 utilization을 보여주고 있는거라면 수초동안 생기는 peak(100% utilization)이 가려져서 보이지 않을 수 있다.
Decayed Average
decayed average의 예로 system "load average"가 있다. uptime(1) 이나 top(1) 같은 tool로 볼 수 있는 값이다. 일정 시간 동안 관측하는건 같으나 최근에 있는 값일 수록 더 가중치를 높게 잡아 계산해 평균에서 short-term fluctuation을 줄여준다.
Limitations
평균은 세부 사항들을 숨긴다. 종종 disk I/O latency가 100ms를 넘길때가 있는데도 평균 latency는 1ms인 경우가 그 예다. 이런 데이터를 제대로 이해하기 위해서는 다음 절의 Standard Deviation, Percentiles, Median등을 활용할 줄 알아야 한다.
2.8.3 Standard Deviation, Percentiles, Median
Standard deviation(표준 편차), percentile(백분위수, e.g. p99, 95th) 들은 데이터 분포를 보여주는데 활용할 수 있는 기법들이다. Standard deviation은 값이 평균에서 얼마나 멀리 떨어져 있는지, percentile은 값을 순서대로 나열했을때 특정 백분위에 해당하는 값을 의미한다.
90th, 95th, 99th, 99.9th와 같은 percentile들은 요청들 중 가장 느린것들을 수량화 할때 쓰인다. 예를 들어 99th request latency가 200ms 라면, 99%의 요청의 latency는 200ms 보다 빠르고 1%의 요청은 200ms 이상이라는 것이다. Service-Level Agreement(SLA)를 명시할때도 사용된다. 이중 50th percentile은 median(중앙값)이라고도 불리며 대부분의 데이터가 어디에 있는지 보여주는데 사용할 수 있다.
2.8.4 Coefficient of Variation
Standard deviation이 50이라는 정보만으론 별로 도움되지 않는다. 여기에 평균이 200이라는 정보가 주어지기 전까진 말이다. 이 둘을 한꺼번에 표현하는 방법으로, 으로 계산되는 coefficient of variation(CoV 또는 CV)이 있다. 다른 방법으론 해당 값이 표준편차의 몇배만큼 평균에서 떨어져 있는지 알려주는 z value가 있다.
2.8.5 Multimodal Distributions
mean, standard deviation, perentile 같은 것들은 normal이거나 unimodal한 분포에서만 효과적이다. System performance는 종종 bimodal한 분포를 보인다. 어떤 code path를 타느냐, 캐시 hit냐 miss냐에 따라 속도가 크게 달라질때가 많기 때문이다. mode가 2개보다 더 많을수도 있다.
평균이 performance metric으로 쓰인걸 볼때마다 되물어라: 분포는 어떠한가?
2.8.6 Outliers
아주 적은 갯수지만 극단적으로 크거나 작은 값들을 outlier라 하는데 어떤 분포에 딱 들어맞지 않는 문제가 있다.
disk I/O latency가 그 예로, 대부분은 10ms 미만이지만, 아주 드문 경우에 1,000ms를 넘을 수 있다. 또다른 예로는 TCP timer-based retransmit으로 인한 netowkr I/O latency outlier가 있다.
정규 분포의 경우, outlier가 조금이더라도 mean에 영향을 미칠 수 있는 반면에, median은 크게 영향을 받지 않아 고려해볼 수 있다. standard deviation이나 99th percentile도 outlier를 식별하는데 도움이 될 수 있지만 그건 outlier의 빈도에 달려있다.
2.9 Monitoring
System performance monitoring은 시간에 따른 performance statistic들을 기록하여 과거와 현재를 비교하고 시간에 따른 usage 패턴들이 식별될 수 있도록 해준다. 이는 capacity planning을 하거나 peak usage를 파악하는데도 유용하다. 이런 기록들은 현재 performance metric 값을 이해하기 위해 필요한 맥락을 제공하기도 한다: "정상"적인 값의 범위는 무엇인지
2.9.1 Time-Based Patterns
시간에 따른 metric 값을 그래프로 그려보면 다양한 cycle들을 볼 수 있다: Hourly, Daily, Weekly, Quarterly, Yearly 등등
다른 작업으로 인해 패턴에 불규칙적인 변화가 생길수 있다: 새로운 컨텐츠를 릴리즈 했다던가, 대규모 정전이라던가, 스포츠 결승전이라던가 하는 것들
2.9.2 Monitoring Products
system performance monitoring을 위한 third-party 제품들도 많다. 보통, 데이터를 적재하고 이를 브라우저로 보여주고 alert을 설정할 수 있는 기능을 제공한다.
이들 중에는 agent(exporter라고도 불리는)를 사용해 각 시스템의 정보를 수집하는 것들도 있다. 이 agent들은 iostat(1) 이나 sar(1) 같은 observability tool을 실행해 출력값을 파싱하거나 os library와 kernel interface로부터 직접 값을 읽어서 동작한다. monitoring 제품중에는 특정 대상들의 정보만을 수집하는 agent들의 집합을 제공하기도 한다: 웹서버, 데이터베이스, 특정 runtime 등
점점 시스템이 분산되고 클라우드 컴퓨팅 사용이 증가하면서, 중앙집중식 monitoring 제품들이 각광을 받고 있다.
2.9.3 Summary-Since-Boot
monitoring이 지금껏 되지 않았더라도, OS가 summary-since-boot 값을 제공 할 수 있으니 확인해서 있다면, 현재 값과 비교해 볼 수 있다.
2.10 Visualizations
시각화를 적절한 방법으로 잘 하면 기계적으로 파악하기 어려운 metric간의 상관관계도 쉽게 효과적으로 파악할 수 있다. 여기선 간단히 나열만 하겠다.
- Line chart
- Scatter plot
- Heat map
- Timeline chart
- Surface plot
- Sankey diagram
- Flamechart
편의상 많은 부분을 생략했음에도 불구하고 한번 더 요약이 필요해 보인다. 특히 2.5절은 중요한 내용들이 많아 다른 글에서 더 자세히 정리할 예정이다. 왠만한 것들은 모르는게 있을때마다 공부하고 정리했는데 확률 분포 쪽에서 아직 모르는게 많아 더 공부가 필요함을 느꼈다. 더 자세한 설명과 예시 그리고 그림 자료들은 Systems Performance를 읽어볼 것을 추천한다.
