[WEPSKAM - Commodity Hardware Today]에서 이어지는 내용으로 Red Hat의 Ulrich Drepper씨가 2007년에 쓴 논문 What Every Programmer Should Know About Memory의 3장 내용이다.
번역하기 어렵거나 원문이 더 이해하기 좋을 것들은 <<...>>로 남겨두었다.
13p ~
옛날에는 CPU 코어의 클럭 속도가 메모리 버스와 비슷했고 메모리 접근은 레지스터 접근보다 조금 느린 정도였다. 하지만 90년대 초반 CPU 개발자들은 CPU의 클럭속도를 메모리보다 훨씬 더 많이 개선 시켜버렸다. 더 빠른 RAM도 가능은 했지만 앞서 보았듯이 경제적이지 않기 때문이다.
만약 아주 빠르지만 아주 작은 RAM과 평범한 RAM이 있으면 평범한 RAM이 더 나을것이다. 작은 RAM 크기를 넘는 working set 크기와 하드 드라이브 같은 보조기억장치에 접근하는 비용을 고려하면 말이다. 문제는 swapped out된 working set을 적재할 보조기억장치의 속도다. 이런 디스크에 접근하는것은 DRAM에 접근하는것보다도 몇 자릿수 만큼이나 느리기 때문이다.
다행히 양자택일은 아니다. 컴퓨터는 작지만 빠른 SRAM에 추가로 많은 양의 DRAM을 가질 수 있다. 이런 경우에 SRAM의 역할은 기본적으로 register의 연장이다. 이렇게 구현할수도 있지만 필수는 아니다. 프로세스의 가상 주소 공간에 SRAM 메모리 같은 물리적 자원을 맵핑하는 문제를 무시하면(그자체로 너무 어렵기 때문에) 이 방법은 각 프로세스가 메모리 리전 할당을 관리해주어야 한다. 메모리 리전의 크기는 프로세서마다 달라질 수 있다. 프로그램의 각 모듈들은 더 빠른 메모리를 두고 경쟁하기 때문에 추가적인 동기화 비용이 생겨난다. 요약하면 더 빠른 메모리는 이를 관리하는 비용 때문에 그 효용성을 잃게 된다는 것이다.
따라서 SRAM을 OS나 유저의 제어 아래 두는 대신, 프로세서가 transparently하게 사용하고 관리할 수 있도록 하게 되었다. 이런 방식에서, SRAM은 곧 프로세서가 사용할것 같은 데이터를 임시로 복제해 두는 용도(캐싱)로 사용된다. 이게 가능한 이유는 프로그램 코드와 데이터가 공간/시간 지역성을 가지기 때문이다. 말인 즉슨 짧은 시간 안에는 같은 코드나 데이터가 재사용될 가능성이 있다는 것이다. 예를 들어 반복문에서 같은 코드가 계속 반복해서 실행 된다거나(공간 지역성) 이전에 접근한 메모리에서 가져온 값을 짧은 시간안에 다시 사용하게 될 가능성이 크다거나(시간 지역성) 하는 경우가 있겠다. 코드에서 이를 보면, 반복문 안에 함수 호출이 있고 그 함수가 다른 주소 공간에 있는 경우 그 함수는 멀리 떨어진 메모리에 있을 수 있지만 짧은 시간에 호출될 것이다. 데이터에서는, 한번에 사용하는 전체 메모리의 양(working set 크기)은 이상적으로는 한계가 있지만, 실제로 사용되는 메모리는 RAM의 random access라는 특성상 서로 떨어져 있는게 일반적이다.
메인 메모리에 접근이 200 cycle, 캐시 메모리에 접근이 15 cycle 걸린다 하자. 그럼 코드가 100개의 데이터에 100번 접근하면, 캐시가 없을땐 2,000,000 cycle, 캐시를 100% 활용하면 168,500 cycle이 걸린다. 91.5% 더 빠른것을 볼 수 있다.
캐시에 사용되는 SRAM은 메인 메모리에 비해 훨씬 작다. working set(현재 사용중인 데이터 집합)의 크기가 캐시보다 작다면 문제되지 않겠지만, 컴퓨터가 아무 이유없이 큰 메모리를 사용하는게 아닐 것이다. working set은 캐시보다 크기 마련이다. 특히 여러 프로세스를 돌리는 시스템에서 더욱 그렇다.
한정된 캐시 크기를 다루기 위해 필요한 것은 언제 어떤것이 캐싱되어야 할지 결정하는 전략이다. 임의의 시점에서 working set에서 실제로 모든 데이터가 모두 쓰이는것은 아니기에, 캐시에 있는 몇몇 데이터는 다른것으로 교체할 수 있고 어떠면 데이터가 실제로 필요하기전에 미리 수행될 수도 있다. 이런 prefetching은 프로그램 실행과 비동기적으로 동작하므로 메인 메모리의 접근 비용을 다소 줄여줄 것이다. 이러한 방법들은 캐시가 실제보다 더 커보이게 해준다.
3.1 CPU Caches in the Big Picture
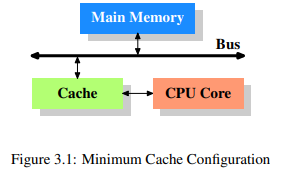
그림 3.1은 최소한의 캐시 설정을 보여준다. CPU 캐시가 처음 도입되었을 당시의 아키텍쳐에서 볼 수 있는 구조다. CPU 코어가 메인 메모리에 직접 붙는 대신, 모든 읽기/쓰기 작업은 캐시를 거치게 된다. CPU 코어와 캐시간의 연결은 다른것들과 비교했을때 훨씬 빠르다. 다시말해 캐시와 메인 메모리간의 연결은 다른 컴포넌트들도 데이터를 주고 받을 수 있는 시스템 버스고 캐시와 CPU 코어간의 연결은 contention이 없다는 것이다. 이 시스템 버스를 요즘에는 FSB라 부른다.
최근 수십년간 대부분의 컴퓨터들이 폰노이만 구조를 따르긴 했지만, 코드와 데이터에 대한 캐시를 따로 두는게 더 좋다고 알려져왔다. 코드와 데이터에 대한 메모리 구역이 구분되어 있기 때문이다. 또 명령어를 해석하는 작업이 대부분의 프로세서에서 느리기에, 이를 캐싱하여 실행속도를 높이고자 하는데도 캐시를 구분하는 것이 더 유용하다. 특히 분기를 잘못 예측해서 파이프라인이 비어있을때 더욱 그렇다.
시간이 지나고 시스템이 복잡해지며 캐시와 메인 메모리간의 속도 차이도 커지게 되어 다른 레벨의 캐시가 필요하게 되었다. 오늘날에는 그림 3.2와 같이 세 단계로 캐시를 나누는것이 일반적이다.
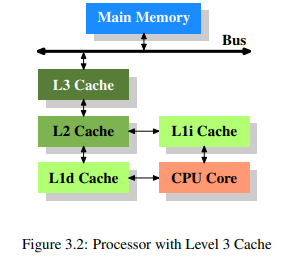
여기서 L1d는 level 1 data cache, L1i는 level 1 instruction cache를 의미한다. 위 그림은 도식화된 구조일 뿐이며 코어와 메모리간 데이터는 꼭 모든 캐시를 다 거칠 필요는 없다.
여러 프로세서가 있고, 그 프로세서에는 여러 코어가, 그리고 그 코어에는 여러 스레드들이 있다. 코어와 스레드의 차이는 각 코어가 하드웨어 자원에 대한 각각의 복사본을 가지고 있다는 점이다. 같은 자원을 사용하려고 하지 않는 이상 코어들은 각각 완전히 독립적으로 실행될 수 있다. 이에 반해 스레드는 프로세서 자원의 대부분을 공유한다. Intel의 스레드 구현은 오직 레지스터만 구분하는 것이었다. 현대 CPU를 다시 도식화하면 그림 3.3과 같다.
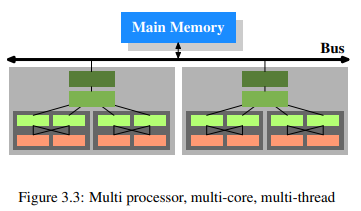
프로세서(밝은 회색) 2개에 각각 코어(어두훈 회색)가 2개, 각 코어마다 스레드가 2개 있다. 스레드들은 level 1 캐시들을 공유하고 각 코어들은 개별적인 level 1 캐시들을 갖는다. CPU의 모든 코어들은 더 상위의 캐시들을 공유한다. 두 프로세서는 당연히 어떠한 캐시도 공유하지 않는다. 이 내용은 나중에 멀티 프로세스, 멀티 스레드 어플리케이션에서의 캐시를 다룰 때 중요하다.
3.2 Cache Operation at High Level
기본적으로 CPU 코어가 읽고 쓰는 데이터들은 모두 캐시에 기록된다. 캐싱되면 안되는 메모리 구역도 있긴 하지만 그건 OS개발하는 사람들이 신경쓸 일이고 프로그래머가 알 필요는 없다. 만약 CPU가 어떤 데이터를 필요로 한다면 먼저 캐시를 찾아본다. 당연히 캐시가 모든 메인 메모리의 내용을 갖고 있는건 아니므로, 메인 메모리에 있는 데이터의 주소를 사용하여 각 캐시의 항목들은 tagged 된다. 이러한 방식으로, 임의의 주소에 대한 읽기/쓰기 요청은 캐시에서 매칭되는 tag를 찾는게 가능하다. 캐시 구현에 따라 이 맥락에서 사용된 주소는 가상 주소 또는 물리적 주소 둘 다 될 수 있다.
실제 메모리에 추가로 tag를 위한 공간이 필요하기 때문에 word를 캐시 단위로 잡는것은 비효율적이다. x86의 32bit word에서는 tag 자체는 32bit 이상이 필요할 것이다. 근접한 메모리는 같이 사용될 가능성이 높기에 캐시에 같이 적재되면 좋을것이다. 2.2.1절에서 배웠듯이 RAM 모듈은 새로운 신호나 신호 없이 연속된 data word들을 전송하는것이 훨씬 더 효율적이다. 그러므로 캐시에 적재되는 항목은 단일 word가 아니라 연속된 word들일것이다. 초창기 캐시는 32bytes 길이였지만 요즘은 64bytes다. 만약 메모리 버스가 64bit 너비라면 이는 캐시 line당 8 transters를 의미한다.
프로세서가 메모리 내용이 필요할때 전체 캐시 line이 L1d에 적재된다. 각 캐시 line의 메모리 주소는 캐시 line 크기에 따라 주소값을 마스킹하여 계산된다. 64byte 캐시 line에서는 하위 6bit들이 0이 되는 것이다. 버려진 bit들은 캐시 line의 offset으로 쓰인다. 실질적으로 주소값은 세 파트로 나뉜다. 32bit 주소에서는 다음과 같다.
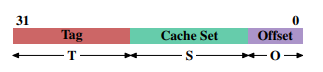
크기의 캐시 line에서는 하위 bit들이 캐시 line의 offset으로 사용된다. 다음 bit들은 캐시 집합을 선택한다. 남은 bit들은 tag를 구성한다. 같은 캐시 집합에 캐시된 모든 alias 들을 구분하기 위해, bit들은 각 캐시 line과 연관된 값이다. 캐시 집합 주소에 사용된 bit들은 저장될 필요가 없다. 같은 집합의 모든 캐시 line에서는 어차피 다 똑같기 때문이다.
명령어가 메모리를 수정하는 경우에도 프로세서는 처음에 캐시 line을 가져와야 한다. 한번에 전체 캐시 line을 바꾸는 명령어가 없기 때문이다. 따라서 쓰기 작업전에 캐시 line에 있는 내용이 먼저 읽혀야 한다. 캐시가 캐시 line의 일부분만을 갖고 있는건 불가능 하다. 뭔가 쓰여졌는데 메인 메모리에는 쓰여지지 않은 캐시 line을 "dirty"라 한다. 한번 메인 메모리에 쓰여지면 dirty flag는 지워진다.
캐시에 새로운 데이터를 적재하려면 먼저 캐시에 공간이 필요하다. L1d에서의 eviction은 캐시 line을 L2로 내린다. 이는 L2에도 똑같이 공간을 요구하며 L3에서 메인 메모리까지 쭉 이어진다. 각 eviction은 점점 비용이 커진다. 이 내용은 AMD와 VIA 프로세서에서 선호되는 exclusive cache 모델이다. Intel은 L1d에 있는 각 캐시 line이 L2에도 있는 inclusive cache 를 사용한다. 따라서 L1d에서의 eviction이 훨씬 빠르다. L2 캐시가 충분하다면 같은 메모리를 두곳에서 관리한다는 단점이 줄어들고 eviction시 더욱 효과적이다. exclusive cache의 장점으로 새로운 캐시 line를 읽을때 L2가 아니라 L1d만 건드리면 되기에 더욱 빠르다는게 있다.
Symmetric Multi-Processor(SMP) 시스템에서 CPU의 캐시들은 각각 독립적으로 동작할 수 없다. 모든 프로세서들은 항상 같은 메모리 내용을 봐야 하는데, 메모리의 이런 일관적인 view를 관리하는 것을 "cache coherency"라 한다. 만약 프로세서가 단순히 자신의 캐시와 메인 메모리만을 본다면, 다른 프로세서의 dirty cache line의 내용은 보지 못할 것이다. 한 프로세서에서 다른 프로세서의 캐시로 직접적인 접근을 제공하는것은 매우 비싸고 심한 병목이 될 것이다. 대신 프로세서들은 언제 다른 프로세서가 특정 캐시 line에 읽고 쓰기를 원하는지 알아낸다. 만약 쓰기 접근이 감지되고 프로세서가 캐시에 clean copy만 가지고 있다면, 해당 캐시 line은 invalid가 된다. 나중에 참조하면 해당 캐시 line은 reloaded된다. 다른 CPU의 읽기 접근은 invalidation이 꼭 필요한건 아님에 유의할 것.
한 프로세서의 캐시 line이 dirty고 다른 프로세서가 그 캐시 line을 읽거나 쓰려한다 가정하자. 이 경우에 메인 메모리는 out-of-date므로 요청하는 프로세서는 처음 프로세서의 캐시 line에 접근해야만 한다. 처음 프로세서는 snooping을 통해 이 상황을 인지하고 자동으로 요청하는 프로세서쪽에 데이터를 보낸다. 이 작업은 메인 메모리를 우회하는데, 몇몇 구현에서는 메모리 컨트롤러가 이를 인지하고 메인 메모리의 갱신된 캐시 line 내용을 적재하기도 한다. 만약 쓰기 작업이라면 처음 프로세서는 로컬 캐시 line의 copy를 invalidate한다.
지금껏 다양한 cache coherency 프로토콜이 개발되었는데, 가장 유명한게 MESI다. 요약하면:
-
dirty cache line은 어느 프로세서의 캐시에도 존재하지 않는다.
-
같은 캐시 line의 clean copy들은 임의의 여러 캐시에 존재할 수 있다.
위와 같은 룰이 잘 지켜만 진다면 멀티 프로세서 시스템이더라도 프로세서들이 자신들 각각의 캐시를 효과적으로 사용할 수 있게 된다. 모든 프로세서가 해야할 일은 다른 프로세서들의 쓰기 접근을 모니터링하고 자신들 로컬 캐시의 주소들과 비교하는 것이다.
마지막으로 캐시 hit와 miss와 관련된 비용을 보자.

여기서 흥미로운건, on-die L2 캐시의 접근 시간 상당 부분이 wire delay에 의해서라는 점이다. 캐시 크기를 늘리면서 생기는 물리적 한계다. 60nm 공정을 45nm으로 줄이는 식의 process shrinking으로만 wire delay를 줄일 수 있다.
표의 숫자들이 다소 커보이긴 해도 매번 캐시 load/miss 마다 저 사이클이 모두 필요하진 않다. 오늘날의 프로세서들은 명령들이 디코딩 되고 실행 가능한 경우에, 각각 다른 길이의 내부 파이프라인을 사용한다. <<Part of the preparation is loading values from memory (or cache) if they are transferred to a register. (if 뒤 내용의 맥락을 모르겠음)>> 만약 파이프라인에서 메모리 load 명령이 충분히 일찍 시작될 수 있다면, 다른 명령들이랑 병렬로 처리되어 전체 load 비용이 줄어들 수 있다. 이는 L1d에서 종종 가능하며 긴 파이프라인을 가지는 몇몇 프로세서에서는 L2에서도 가능하다. 그러나 메모리를 일찍 읽기 시작하는데에는 많은 어려움이 있다. 메모리 접근에 대한 충분한 자원이 없거나 load할 주소가 다른 명령의 결과에 의존하는 경우들이다. 이런 경우에는 load 비용이 줄어들지 않는다.
쓰기 명령은 값이 메모리에 안전하게 적재되기까지 CPU가 기다려야 할 필요가 없다. 이후 명령들의 실행 결과가 값이 메모리에 적재되었다 가정했을때와 동일하다면 CPU가 shortcut을 취하지 않을 이유가 없으므로 다음 명령을 일찍 실행할 수 있다. 일반적인 레지스터에서 더 이상 유효하지 않는 값을 갖고있는 shadow 레지스터의 도움으로, 쓰기 작업이 다 되기도 전에 해당 값을 변경하는것도 가능하다.
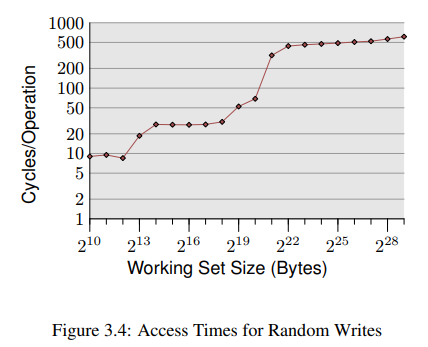
위는 무작위 방식으로 반복해서 메모리에 접근하는 프로그램의 간단한 시뮬레이션이다. 각각의 데이터는 고정된 크기를 갖고 있고 elements의 갯수는 각각의 working set size로 결정된다. Y축은 element 하나를 처리하는데 소요된 평균 CPU 사이클(로그 스케일임의 유의)을 나타낸다.
그래프는 3개의 plateau들을 보여주는데 이는 몇몇 프로세서들이 L1d, L2 캐시만 있고 L3 캐시가 없기 떄문이다. 이 실험을 바탕으로, L1d가 bytes, L2가 bytes 임을 유추해볼 수 있다. 만약 전체 working set이 L1d에 적재될 수 있다면, 각 element에 대한 은 10 미만이 될것이다. L1d 크기를 넘어버리면 프로세서는 L2에서 데이터를 가져와야만 하고 평균 시간은 28 언저리로 뛰어버린다. L2까지 충분치 않게되면 480 cycle 이상이 되는데, 대부분의 명령들이 메인 메모리에서 값을 가져와야만 할때가 그렇다. 더 안좋은 사실은, 데이터가 수정되었기 떄문에, dirty cache line도 다시 쓰여져야만 한다는 것이다.
이 그래프는 캐시 사용을 개선하는데 도움이 되는 코딩 방식을 고민해볼만한 충분한 동기를 제공한다. 우리는 쥐꼬리만한 퍼센트를 개선하고자 하는게 아니라 수 자릿수의 개선을 말하고 있다.
3.3 CPU Cache Implementation Details
이 섹션은 읽으면 좋지만 논문의 나머지를 이해하는데 필요하진 않아 생략한다.
3.4 Instruction Cache
프로세서가 사용하는 데이터만 캐싱되는게 아니다. 프로세서가 실행한 명령어들 또한 캐싱 된다. 이 캐시는 데이터 캐시보단 덜 까다로운데 왜냐하면:
- 실행되는 코드의 양은 필요한 코드의 크기에 의존한다. 코드의 크기는 일반적으로 문제의 복잡도(complexity of problem?)에 의존하며 문제의 복잡도는 고정되어 있다.
- 프로그램의 데이터 처리방식이 프로그래머에 의해 설계되는 반면, 프로그램의 명령어들은 일반적으로 컴파일러에 의해 생성된다. 컴파일러 개발자들은 좋은 코드 생성 규칙에 대해 알고 있다.
- 프로그램의 흐름은 데이터 접근 패턴 보다 훨씬 더 예측하기 쉽다. 오늘날의 CPU는 패턴을 인식하는데 아주 뛰어나다. 이는 prefetching에 도움이 된다.
- 코드는 항상 좋은 공간적/시간적 지역성을 가진다.
CPU core clock이 극적으로 증가해 캐시(심지어 L1도)와 코어의 속도차가 커진 이래로, CPU는 파이프라인과 함께 설계되었다. 즉, 명령어들이 단계적으로 실행됨을 의미한다. 먼저 명령어가 디코딩되고 파라미터들이 준비된 뒤 마지막으로 실행된다. 그런 파이프라인은 꽤 길수 있다.(Intel의 Netburst 아키텍처는 20 단계 이상) 긴 파이프라인은 stall시 다시 속도를 내려면 시간이 좀 걸린다. 다음 명령의 위치가 제대로 예측되지 못했거나 다음 명령을 가져오는데 너무 오래걸렸을때(메모리에서 불러와야만 하는 경우) stall이 발생한다. 그래서 CPU 설계자들은 최대한 파이프라인 stall이 덜 일어나도록 분기 예측에 많은 시간과 노력을 들이고 있다.
CISC 프로세서들에선 디코딩 단계에도 다소 시간이 소요된다. 특히 x86, x86-64 프로세서가 그러한데 때문에 요즘 프로세서들은 raw byte sequence대신 디코딩된 명령어들을 L1i에 캐싱한다. 이 경우의 L1i는 "trace cache"라 불린다. << Trace caching allows the processor to skip over the first steps of the pipeline in case of a cache hit which is especially good if the pipeline stalled. >>
앞서 언급됐지만, L2 캐시들은 코드와 데이터를 모두 포함하는 unified cache다. 여기서의 코드는 디코딩된 형태가 아닌 byte sequence다.
최적의 성능을 달성하기 위해서 명령어 캐시와 관련된 몇가지 규칙이 있다:
- 가능한한 코드를 짧게 생성하라. << There are exceptions when software pipelining for the sake of using pipelines requires creating more code or where the overhead of using small code is too high. >>
- 프로세서가 좋은 prefetching 결정을 내릴 수 있도록 도와라. code layout 또는 명시적인 prefetching으로 가능하다.
이러한 규칙들은 보통 컴파일러가 코드를 생성할때 적용된다. 프로그래머가 할 수 있는것들은 6절에서 알아볼것이다.
3.4.1 Self Modifying Code
컴퓨터 초창기엔 메모리가 아주 비쌌다. 사람들은 프로그램 크기를 줄이기 위해 무엇이든 했다. 자주 사용됐던 트릭중 하나는 시간에 따라 프로그램 자기 자신을 변경하는 것이었다. 그러한 Self Modifying Code(SMC)는 오늘날 종종 발견되는 것들 대부분은 성능이나 보안관련된 이유 때문이다.
SMC는 일반적으로 피하는게 좋다. 보통 제대로 실행되긴 하지만 그렇지 않은 예외 케이스도 있으며 이는 성능 문제를 야기한다. 당연하게도 변경되는 코드는 디코딩된 명령어들을 담고 있는 trace cache에 적재될 수 없고, 만약 코드가 한번도 실행되지 않아서 trace cache가 사용되지 않았더라도 여전히 문제가 있다. 만약 이후 명령어가 이미 파이프라인에 들어왔는데 변경된다면 프로세서는 많은 비용을 들여 처음부터 다시 작업을 수행해야만 한다.
마지막으로 프로세서가 코드 페이지는 불변이라고 가정하기에, L1i 구현은 MESI 프로토콜을 사용하지 않고 대신 간소화된 SI 프로토콜을 사용한다. << This means if modifications are detected a lot of pessimistic assumptions have to be made. >>
언제나 가능하면 SMC를 피하는게 좋다. 메모리는 더이상 그렇게 귀한 자원도 아니고 코드를 수정하는 것보다 다른 기능을 하는 코드를 더 새로 짜는게 권장된다. << Maybe one day SMC support can be made optional and we can detect exploit code trying to modify code this way. >> 만약 SMC가 반드시 필요하다면, write 작업은 캐시를 우회하여 L1i에서 필요로 하는 L1d의 데이터와 문제가 되지 않도록 해야한다.
리눅스에서는 프로그램이 SMC를 포함하는지 알기 쉽다. 보통 toolchain에선 모든 프로그램의 코드는 write-protected 되지만 코드 페이지가 writable인 실행파일을 만들기 위해선 프로그래머가 링크 타임에 반드시 뭔가 작업을 해야 한다. 이때 Intel x86, x86-64 프로세서들은 SMC를 사용하는 횟수를 카운트하는 전용 카운터를 갖고있다. << With the help of these counters it is quite easily possible to recognize programs with SMC even if the program will succeed due to relaxed permissions. >>
3.5 Cache Miss Factors
메모리 접근이 cache miss가 되면 비용이 급등하는걸 알아봤다. 가끔 이런 cache miss는 피할수 없으며 실제 비용이 얼마인지 그리고 어떻게 이를 완화할 수 있는지 이해하는 것은 중요하다.
3.5.1 Cache and Memory Bandwidth
프로세서의 성능을 더 자세히 알기 위해 우리는 최적의 환경에서 사용 가능한 대역폭을 측정한다. 이 측정은 프로세서 버전마다 크게 다르다는 점에서 특히 흥미롭다고 할 수 있다. 이 절이 서로 다른 장비에서 측정된 데이터들이 많은 이유기도 하다. 성능을 측정하려는 프로그램은 16 bytes를 한번에 load/store 하기 위해서 x86, x86-64의 SSE 명령어를 사용한다. working set은 1kB 부터 512MB까지 증가하며 얼마나 많은 bytes가 한 사이클에 load/store 될 수 있는지를 측정했다.
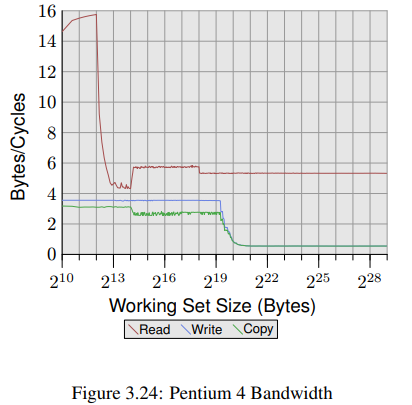
그림 3.24는 Intel Netburst 프로세서의 성능을 보여준다. working set size가 L1d보다 작을 때, 프로세서는 16 bytes 전체를 한 사이클에 모두 읽을 수 있다. 이 실험은 읽은 데이터로 아무것도 하지 않으며 단순히 읽기 명령 그 자체만을 테스트했다. L1d가 충분치 않자마자 한 사이클당 6 bytes로 급격히 성능이 떨어진다. bytes의 step은 DTLB(Data Translation Lookaside Buffer) 캐시를 다 써버려서 각 새로운 페이지마다 추가적인 작업이 필요하기 때문이다. 읽는 작업이 순차적이기 때문에 prefetching은 접근을 완벽하게 예측할 수 있고 FSB(Front Side Buffer)는 모든 working set size에 대해 사이클당 5.8 bytes로 메모리 내용을 stream할 수 있다. prefetch된 데이터는 L1d로 전파되진 않는다. 물론 이 값들은 실제 프로그램에선 얻을 수 없는 수치니까 그냥 실질적인 한계 정도로 이해하길 바란다.
읽기 성능보다 더 놀라운건 쓰기/복사 성능이다. 쓰기 성능은 심지어 더 작은 working set size에서도 사이클당 4 bytes를 넘지 못한다. 이떄 Netburst 프로세서에서 L2 속도에 제약받는 L1d 를 위해 Intel이 Write-Through 모드를 사용하기로 했음을 알 수 있다. << This also means that the performance of the copy test, which copies from one memory region into a second, non-overlapping memory region, is not significantly worse. >> 필요한 read 작업들은 훨씬 빠르고 write 작업과 일부 겹치는것도 가능하다. write/copy 측정에서 가장 눈여겨볼만한 점은 L2 캐시가 더이상 충분치 않을때의 낮은 성능이다. 사이클당 0.5 bytes까지 성능이 떨어지는것을 볼 수 있다. 이는 쓰기 성능이 읽기 성능보다 10배만큼 느리다는 것을 의미한다. 프로그램의 성능을 위해서 write/copy 작업을 최적화 하는것이 훨씬 더 중요하다.
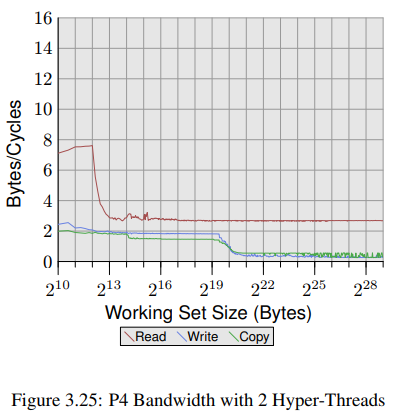
그림 3.25에선 동일한 프로세서지만 쓰레드 두개를 사용한 결과를 볼 수 있다.<<, one pinned to each of the two hyper-threads of the processor.>> 하이퍼 쓰레드는 레지스터를 제외한 모든 자원을 공유하므로 각 쓰레드는 오직 절반의 캐시와 대역폭만을 사용할 수 있다. 즉 각 쓰레드는 많이 대기할 수 밖에 없고 다른 쓰레드가 실행 시간을 양보하더라도 결과는 크게 달라지지 않는다. 왜냐하면 다른 쓰레드가 어차피 메모리 자원을 기다려야 하기 때문이다. 확실히 하이퍼 쓰레드 최악의 활용법이긴 하다.

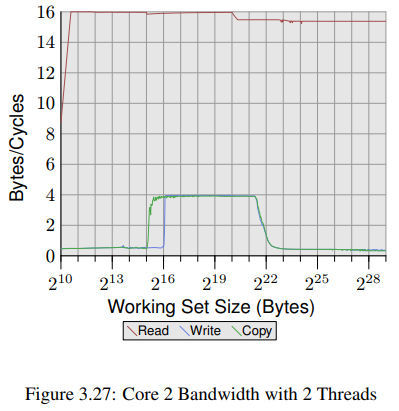
그림 3.24, 3.25와 비교했을 때 그림 3.26, 3.27은 Intel Core 2 프로세서를 사용해, 확연히 다른 결과를 보여주고 있다. 이는 P4보다 4배큰 L2를 공유하는 듀얼 코어 프로세서로, write/copy 성능의 delayed drop-off를 설명한다.
다른 차이점들도 있다. working set 범위 전체에서 읽기 성능이 사이클당 16 bytes 근처를 왔다 갔다 하는데 bytes 에서 발생한 읽기 성능의 drop-off는 working set size가 DTLB보다 너무 커서 그렇다. 이렇게 높은 수치를 달성했다는 것은 프로세서가 단순히 데이터를 prefetch하고 그 데이터를 적시에 전송할 수 있을 뿐 아니라 데이터가 L1d에도 prefetch됨을 의미한다.
write/copy 성능도 확연히 다르다. 이 프로세서는 Write-Through 정책이 없어서 쓰여진 데이터는 L1d에 적재되고 필요할 때만 evict된다. 덕분에 write 속도가 거의 사이클당 16 bytes에 가깝게 나올 수 있다. L1d가 더이상 충분치 않으면 성능은 급격히 떨어진다. Netburst 프로세서와 마찬가지로, write 성능이 훨씬 낮다. 심지어 L2가 더이상 충분치 않을땐 속도가 20배나 느려진다. 그래도 Core 2 프로세서 성능이 Netburst보단 항상 뛰어나다.
그림 3.27의 실험은 Core 2 프로세서 각각의 코어에서 두개의 쓰레드를 돌렸다. 두 쓰레드 모두 같은 메모리에 접근했다.(꼭 완벽하게 동기화될 필요 없이) read 성능은 싱글 쓰레드일때와 크게 다르지 않다. 멀티쓰레딩에서 종종 보이는 몇몇 jitter들이 보이는 저옫다.
흥미로운 점은 working set size가 L1d보다 작을때의 write/copy 성능이다. 그림에서 보이듯이, 데이터를 메인 메모리에서 가져와야 하는것처럼 성능이 나온다. 두 쓰레드는 같은 메모리 위치와 cache line에 보내야 하는 RFO 메시지를 두고 경쟁한다. 문제가 되는 부분은 두 코어가 캐시를 공유함에도 불구하고, 이러한 요청들이 L2와 같은 속도로 처리되지 않는다는 것이다. L1d 캐시가 더이상 충분치 않으면 변경된 항목들은 각 코어의 L1d는 코어가 공유하는 L2로 flush된다. 이 때 성능이 급격히 좋아지는데 왜냐하면 이제 L1d miss가 L2 캐시로 해결됐고, RFO 메시지는 데이터가 flush 되지 않았을떄만 필요해졌기 때문이다. 이정도 크기의 working set에서 50%의 속도 감소는 이 때문이다. 두 코어가 같은 FSB를 공유하기에 각 코어는 FSB 대역폭의 절반만 사용 가능하고, 이는 큰 working set에 대해 각 쓰레드의 성능이 싱글 쓰레드에 비해 절반 정도 되는것을 의미하므로 asymptotic behavior를 보이는 것은 당연하다.
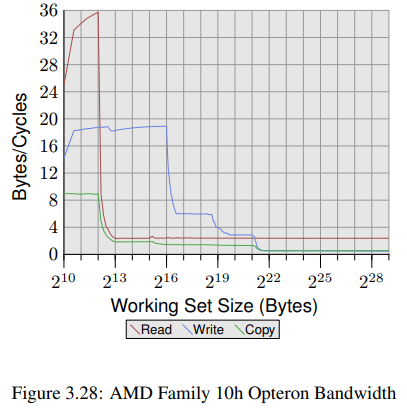
같은 벤더사의 프로세서에 대해서도 버전 마다 결과가 크게 다르므로, 다른 벤더사의 프로세서들을 보는것도 충분히 가치 있을것이다. 그림 3.28은 AMD family 10h Opteron 프로세서의 성능을 보여준다. 이 프로세서는 64kB L1d, 512kB L2, 그리고 2MB L3을 갖고 있다. L3 캐시는 프로세서의 모든 코어가 공유한다.
신기한 점은, 프로세서가 L1d 캐시가 충분하다면 사이클당 두개의 명령어도 처리할 수 있다는 것이다. read 성능이 사이클당 32 bytes를 넘으며 write 성능도 사이클당 18.7 bytes나 된다. read 곡선은 사이클당 2.3 bytes로 빠르게 flatten 되긴 하지만.. <<The processor for this test does not prefetch any data, at least not efficiently.>>
반면에 write 곡선은 다양한 캐시 크기에 따라 성능이 달라진다. L1d가 충분할때 성능이 peak를 찍고, L2에선 6 bytes, L3에선 2.8 bytes, 마지막으로 L3까지 부족하면 .5 bytes 까지 떨어진다. L1d 캐시의 성능은 이전의 Core 2 프로세서보다 좋고, Core 2 프로세서의 캐시 크기가 더 큼에도 불구하고 L2 접근 속도는 비슷하다. 그리고 L3와 메인 메모리 접근은 더 느리다. copy 성능은 read/write 성능보다 못하다.
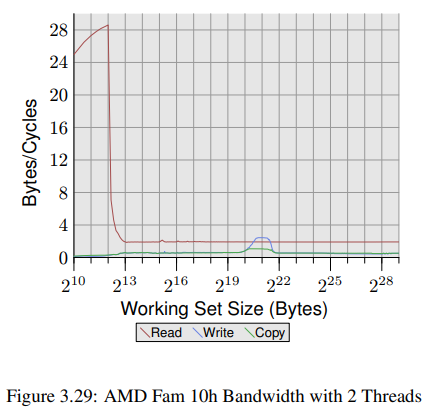
Opteron 프로세서의 멀티쓰레딩 성능은 그림 3.29에서 볼 수 있다. read 성능은 크게 영향받지 않았다. 각 쓰레드의 L1d와 L2는 이전처럼 동작했고 L3 캐시는 그렇게 잘 prefetch하지 못했다. <> 가장 큰 문제는 write 성능이다. 쓰레드들이 공유하는 모든 데이터는 L3 캐시를 거쳐야 한다. 이렇게 공유하는건 꽤 비효율적으로 보이는데 왜냐하면 L3 캐시 크기가 모든 working set을 감당할 수 있을정도로 충분하더라도 L3 접근보다 비용이 훨씬 비싸기 때문이다. 이 그래프를 그림 3.27 와 비교해보면 Core 2 프로세서의 두 쓰레드가 적당한 working set size 범위에선 shared L2 캐시의 속도로 동작하는 것을 볼 수 있다. 이 정도 레벨의 성능은 Opteron 프로세서에선 아주 일부 범위의 working set size에서만 얻을 수 있다. 심지어 그마젇 Core 2의 L2보다 훨씬 느린 L3의 속도에만 근접할 수 있을 뿐이다.
3.5.2 Critical Word Load
메모리는 메인 메모리에서 캐시로, 블럭 단위로 전송되며 이 블럭 단위는 cache line 크기보다 작다. 오늘날 64 bit는 한번에 전송되고 cache line 크기는 64 또는 128 bytes다. 즉 캐시당 8 또는 16번의 전송이 필요하다.
DRAM 칩은 burst mode에서 이 64 byte 블럭들을 전송할 수 있다. 덕분에 메모리 컨트롤러에서 별도의 추가적인 명령과 그에 따른 딜레이 없이 cache line을 채울 수 있다. 만약 프로세서가 cahce line을 prefetch한다면 이게 최적의 성능일 것이다.
만약 프로그램이 데이터나 명령어에 대한 캐시 접근이 miss면 상황이 달라진다. cache line에 있는, 프로그램이 계속 필요로 하는, word가 cache line의 첫 word가 아닐 수 있다. burst mode에 double data rate를 쓴다 하더라도, 각각의 64-bit 블럭들은 완전 다른 시간에 전송될 수 있다. 각 블럭들은 이전것보다 4 CPU 사이클 또는 그 이상 정도 느리게 전송된다. 만약 프로그램이 필요로 하는 word가 cache line의 8번째에 있다면 그 프로그램은 30 사이클 이상을 더 기다려야 한다.
꼭 이럴 필요는 없다. 메모리 컨트롤러는 자유롭게 cache line의 word들을 다른 순서로 요청할 수 있다. 프로세서는 어떤 word가 프로그램이 기다리는 word 즉 critical word 인지 알려줄 수 있고 메모리 컨트롤러는 이 word를 첫번째로 요청할 수 있다. word가 전송되면, 프로그램은 나머지 cache line의 word들이 도착하고 아직 캐시가 consistent state가 아닌 동안 계속 실행될 수 있다. 이러한 기법을 Critical Word First & Early Restart라 한다.
오늘날의 프로세서들은 이 기법을 구현하지만 그렇게 못하는 상황들도 있다. 프로세서가 데이터를 prefetch 할 땐 critical word를 모른다. 만약 프로세서가 prefetch 도중에 cache line에 요청한다면 순서를 바꾸지도 못하고 critical word가 도착할때까지 기다려야만 할 것이다.
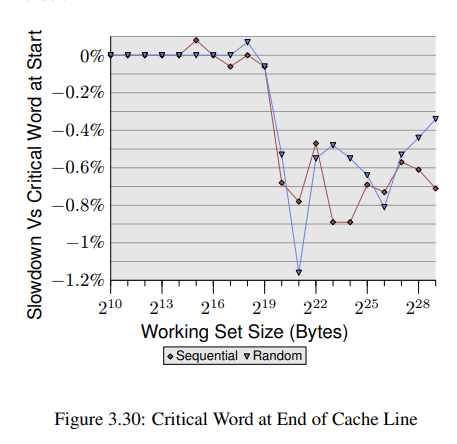
이러한 최적화들에도 불구하고 cache line에서 critical word의 위치는 중요하다. 그림 3.30은 sequential/random 접근에 대한 실험이다. << Shown is the slowdown of running the test with the pointer used in the chase in the first word versus the case when the pointer is in the last word. >> element의 크기는 cache line 크기에 따라 64 bytes다. 값이 좀 뒤죽박죽이긴 하지만 L2가 working set size에 대해 충분치 않자마자 critical word가 끝에 있을 때의 성능이 거의 0.7% 더 느린것을 알 수 있다. sequential 접근은 영향을 좀 더 많이 받은걸로 보인다. 이는 앞서 보았던 다음 cache line을 prefetching 할때의 문제와 동일하다.
3.5.3 Cache Placement
캐시가 하이퍼 쓰레드, 코어 그리고 프로세서와 어떤식으로 배치될지는 프로그래머가 제어할 수 있는게 아니다. 하지만 프로그래머는 쓰레드가 어디서 실행될지 결정할 수 있으므로 사용중인 CPU와 캐시가 어떻게 관련되는지 아는건 중요하다.
쓰레드를 돌릴때 언제 어떤 코어를 써야하는지에 대한 세부사항은 넘어가겠다. 여기서는 프로그래머가 쓰레드의 affinity를 언제 신경써야 하는지에 대한 아키텍처 세부사항만 설명한다. 정의상으론, 하이퍼 쓰레드는 레지스터 셋을 제외한 모든것을 공유한다. 여기에는 L1 캐시도 포함된다. 각 코어는 최소한 자신만의 L1 캐시를 가진다. << Aside from this there are today not many details in common: >>
- 초기 멀티코어 프로세서들은 캐시를 전혀 공유하지 않았다.
- Intel의 이후 모델들은 듀얼 코어 프로세서에서 L2 캐시를 공유했다. 쿼드 코어 프로세서에서는 두 코어의 각 쌍을 위해 분리된 L2 캐시를 처리해줘야 한다.
- AMD의 family 10h 프로세서들은 분리된 L2 캐시와 통합된 L3 캐시를 가진다.
프로세서 벤더사별로 자신들의 각 모델들의 장점들을 많이 광고해왔다. 겹치지 않는 코어들이 working set을 처리할때, 캐시를 공유하지 않는건 장점을 가진다. 싱글쓰레드 프로그램에서 특히 그렇다. << Since this is still often the reality today this approach does not perform too badly. >> 하지만 항상 어느정도는 겹친다. 캐시는 모두 공통 런타임 라이브러리에서 가장 자주쓰는 부분을 포함하므로, 이렇게 겹치는 캐시 공간은 낭비로 이어진다.
Intel의 듀얼 코어 프로세서처럼 L1말고 다른 캐시들도 모두 완전히 공유하면 큰 장점이 있다. 만약 두 코어에서 돌고 있는 쓰레드들의 working set이 많이 겹친다면, 전체 사용가능한 캐시 메모리는 늘어나고 working set은 성능 저하 없이 더 커질 수 있을것이다. 만약 working set이 겹치지 않는다면 Intel의 Advanced Smart Cache에서 어떤 한 코어가 전체 캐시를 독점하지 않도록 관리할 것이다.
만약 두 코어가 각각의 working set을 위해 캐시를 거의 절반씩 쓴다면, 약간의 마찰이 있긴할거다. 그 캐시는 계속 두 코어의 캐시 사용량을 저울질하고 rebalancing이 제대로 되지 않는 경우엔 eviction해야 한다. 이 문제들을 이해하기 위해 다른 테스트 프로그램의 결과를 보겠다.
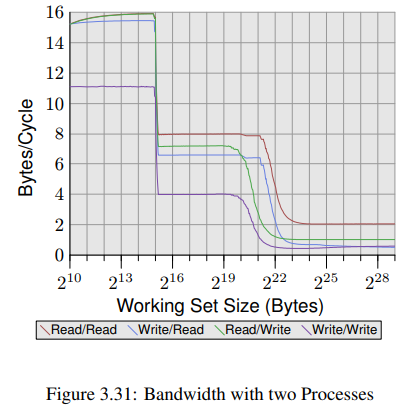
이 테스트 프로그램은, SSE 명령어를 사용해 지속적으로 2MB 블럭의 메모리를 읽고 쓰는 프로세스를 가진다. 2MB는 Core 2 프로세서의 L2 캐시 크기 절반이라 그렇다. 두번째 프로세스가 다른 코어에 물려있는 동안 이 프로세스도 한 코어에 물려있다. 두번째 프로세스는 임의의 크기로 메모리를 읽고 쓴다. 그래프는 사이클당 몇바이트가 읽고 쓰이는지 보여준다. read/write 프로세스들 각각의 조합을 4가지 그래프로 나타냈다. read/write 그래프는, 항상 2MB working set을 write에 쓰는 background 프로세스, 그리고 임의의 working set을 read에 쓰는 measured 프로세스에 관한 그래프다.
그래프에서 흥미로운점은 와 bytes 부분이다. 만약 두 코어의 L2 캐시가 완전히 분리되어 있다면, 우리는 4개 테스트의 성능이 와 bytes 부분에서 L2 캐시가 완전히 소진돼 성능이 떨어질 것이라 예측해볼 수 있다. 하지만 그림 3.31을 보면 그렇지 않다는걸 볼 수 있다. background 프로세스가 write하는 경우엔 더욱 명확하다. working set size가 1MB에 도달하기도 전에 성능이 떨어지고 있다. 두 프로세스는 메모리를 공유하지 않기에 RFO 메시지도 생성하지 않는다. 이게 pure cache eviction 문제다. << The smart cache handling has its problems with the effect that the experienced cache size per core is closer to 1MB than the 2MB per core which are available. >> 우린 그저 코어들이 공유하는 캐시가 이후 나올 프로세서들의 기능으로 계속 남는다면, smart cache handling에 쓰이는 알고리즘이 고쳐지길 바랄 뿐이다.
두개의 L2 캐시를 가지는 쿼드 코어는 상위레벨의 캐시가 나오기전의 임시방편일 뿐이다. 이러한 설계는 듀얼코어 프로세서에서 소켓을 분리하는것에 비해 성능면에서 크게 이점이 없다. 두 코어는 서로 같은 버스를 사용해 데이터를 주고 받으며, 이 버스는 외부 FSB에 노출되어 있다. 데이터를 교환하는데 따로 특별한 경로는 없다.
AMD의 10h 프로세서 계열을 시작으로, 멀티 코어 프로세서를 위한 미래의 캐시 설계에는 더 많은 레이어를 사용하게 될 것이다. 프로세서의 일부 코어들이 계속 하위계층의 캐시를 공유할지는 지켜볼 일이다. (2008세대 프로세서들에선 L2캐시를 공유하지 않았다.) 빠르고 자주 쓰는 캐시는 많은 코어들에서 공유할 수 없어서, 추가계층(extra level)의 캐시는 필요하다. 성능도 영향을 받을거고 높은 associativity와 매우 큰 캐시도 필요할 것이다. 캐시 크기와 associativity 모두 캐시를 공유하는 코어의 수에 비례해야 한다. 큰 L3 캐시와 적당한 크기의 L2 캐시를 사용하는것은 합리적인 trade-off다. L3 캐시는 느리긴 해도 L2 캐시만큼 자주 쓰이진 않는다.
<< For programmers all these different designs mean complexity when making scheduling decisions. >> 누군가는 최적의 성능을 위해서 machine architecture의 workload와 세부사항을 이해해야 한다.
3.5.4 FSB Influence
FSB는 성능에서 중요한 역할을 한다. 캐시의 내용를 얼마나 빠르게 읽고 쓸수 있는지는 메모리와의 연결에 달려있다. 같은 프로그램을 두 장비에서 오직 메모리 모듈 속도만 달리 하여 테스트 해보았다. 그림 3.32는 NPAD=7, 64bit에서 Addnext() 테스트(pad[0] 다음 값을 pad[0]에 추가)의 결과를 보여준다. 두 장비는 모두 Intel Core 2 프로세서를 가지고 첫번째는 667MHz DDR2 모듈을, 두번째는 800MHz 모듈(20% 증가한)을 사용한다.
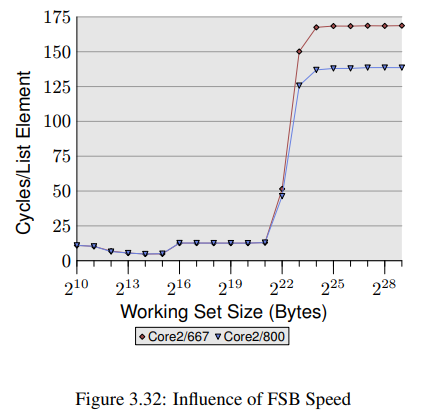
working set size가 커져서 FSB에 심한 부하가 걸리면 차이는 더욱 커진다. 이 실험에서 나온 maximum performance increase는 18.2%로 이론상 얻을 수 있는 차이에 근접한다. 이는 더 빠른 FSB가 확실히 많은 시간을 절약해줄 수 있음을 의미한다. 만약 working set이 캐시보다 작다면 크게 중요한건 아니다.(여기선 4MB L2를 사용했다.) 지금 여기선 프로그램 하나를 테스트중임에 유의하자. 시스템의 working set은 돌고 있는 모든 프로세스들이 필요한 메모리들의 합이다. 따라서 훨씬 작은 프로그램들이더라도 4MB 메모리를 초과하기 쉽다.
요즘 몇몇 Intel의 프로세서들은 FSB 속도를 최대 1,333MHz 까지 지원한다. 나중에는 더 높아질 것이다. (지금 내가 2022년에 쓰고 있는 i7-8700는 8 GT/s) 만약 속도가 중요하고 working set size가 크다면 빠른 RAM과 FSB가 충분히 돈 쓸 가치가 있을 것이다. 그러나 프로세스가 더 빠른 FSB를 지원하더라도 Motherboard/Northbridge에서 지원을 안할 수 있으니 주의하라.
