k8s dns issue and optimization in fedora
dns issue
이것 때문에 삽질한 시간에 비해 글 내용은 길지 않다.
이슈 내용을 요약하면 다음과 같다:
fedora32부터 firewalld의 backend로 iptables가 아닌 nftables가 기본으로 사용되는데, 아직 minikube나 kind같은 local k8s cluster에서 이를 지원하지 않아 dns resolution이 제대로 되지 않는 이슈
솔루션이 복잡하진 않다.
- /etc/firewalld/firewalld.conf의 FirewallBackend를 nftables에서 iptables로 변경
systemctl restart firewalld.service&&systemctl restart docker로 서비스 재시작- 다른곳에선 언급되지 않았지만 내 경우엔 호스트도 재부팅하기전까진 아무리 클러스터를 새로 만들고 시도해도 dns resolution이 되지 않았다.
처음에 트러블슈팅 방향을 k8s, kind, dns, timeout, coredns 로만 생각하니 불필요한 삽질을 많이 했던것 같다.
dns optimization
끝나고 coredns로 한번 더 확인했을때 유의하면 좋을것 같은게 있어 간단히 기록해둔다.
kubectl -n kube-system edit cm coredns로 아래처럼 log directive를 추가한 뒤
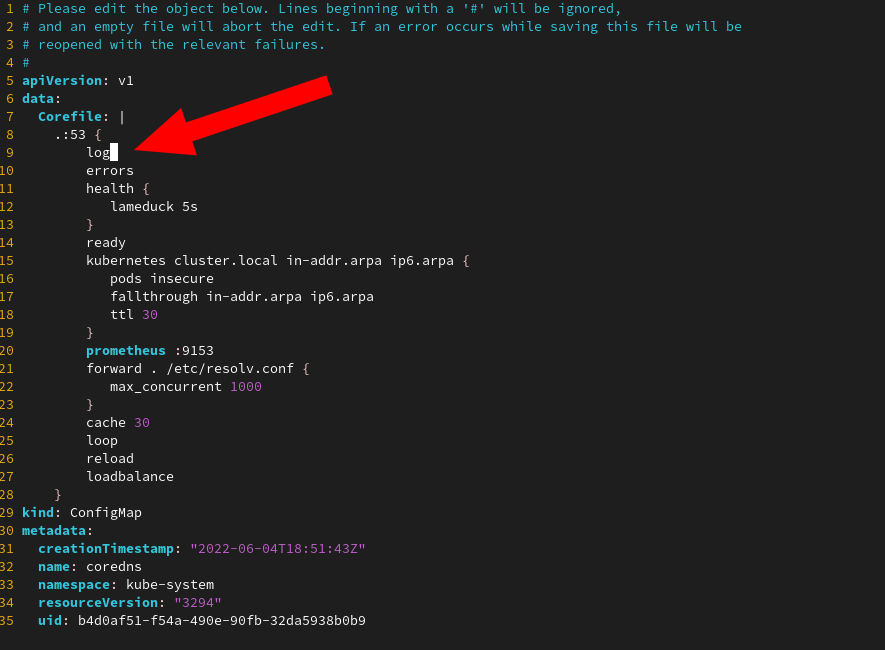
kubectl -n kube-system logs -l k8s-app=kube-dns -f로 로그를 확인했다.
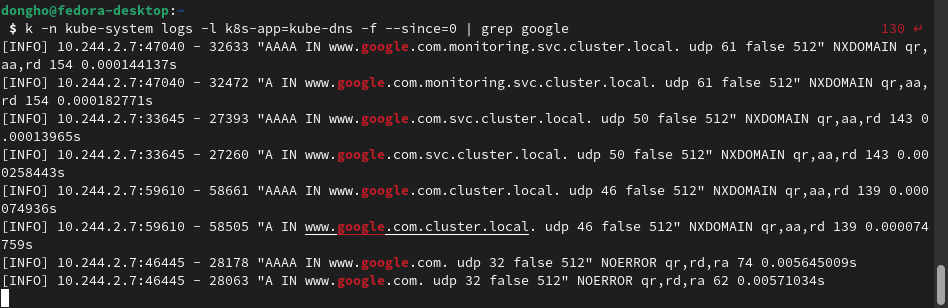
보면 www.google.com의 주소를 질의하는데 /etc/resolve.conf의 search list인 monitoring.svc.cluster.local svc.cluster.local cluster.local를 하나씩 다 조회해보는것을 볼 수 있다. /etc/resolve.conf의 ndots값보다 .이 적어서 FQDN 취급이 되지 않았기 때문이다.
위 로그 내용으로 간단히 보면 DNS 조회에 실패에 걸린 시간이 전체의 4%에 해당하지만, dns조회량이 많거나 search list가 길어지면 문제가 될수도 있다. DNS latency가 부하에 따라 어떤 경향을 보일지는 직접 벤치마킹을 해봐야 알겠지만 이를 완화하는 방법또한 무척 간단하니 일단 공유하자면 다음과 같다.
외부 도메인 주소를 정확하게 알고 있는 경우 마지막에
.을 붙이면 ndots와 관계없이 이를 FQDN으로 취급하기에 coredns에 불필요한 요청을 줄일 수 있게된다.
reference
