후기 2탄..
지난 후기는 모델선정하는 과정(?) 을 적었는데 이번엔 대회에서 원하는 출력이 무엇인지 알아보고 튜닝에 필요하는 학습데이터셋을 알아보도록 하겠습니다.
대회에서 starter kit을 제공하여서 열어보니 예시 문제가 있었습니다.
evaluation을 하기 위한 local_evaluation.py 가 존재하고
이 파일을 열어보니 data 폴더 안의 development.json을 불러오고 있었습니다.
development.json

이 파일을 열어보니 5개 track에 관한 문제가 있었습니다.
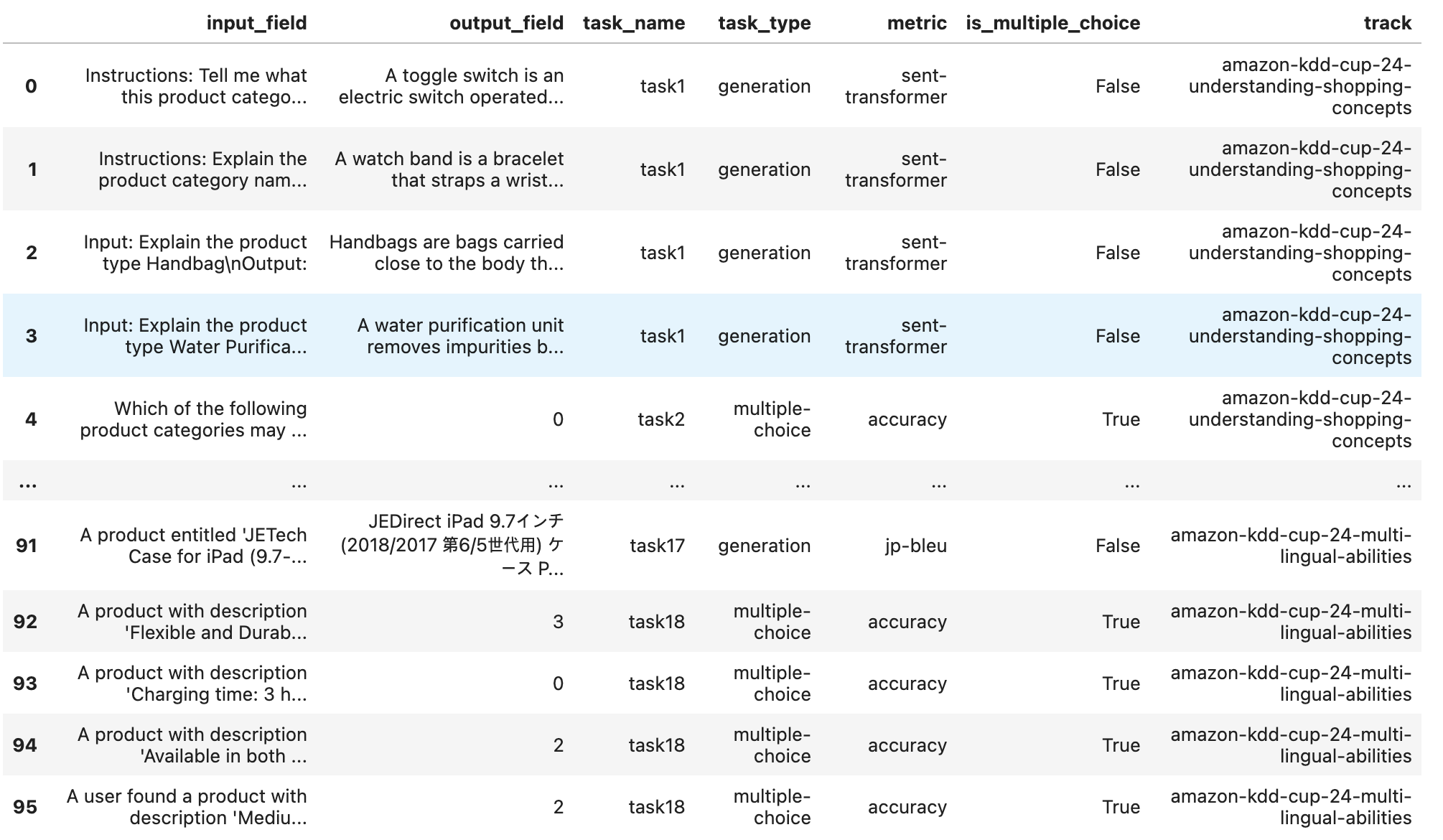
마지막 열에 해당하는 것이 track 이고
제가 참가한 건 shopping knowledge reasoning 이기에
필터링 하면
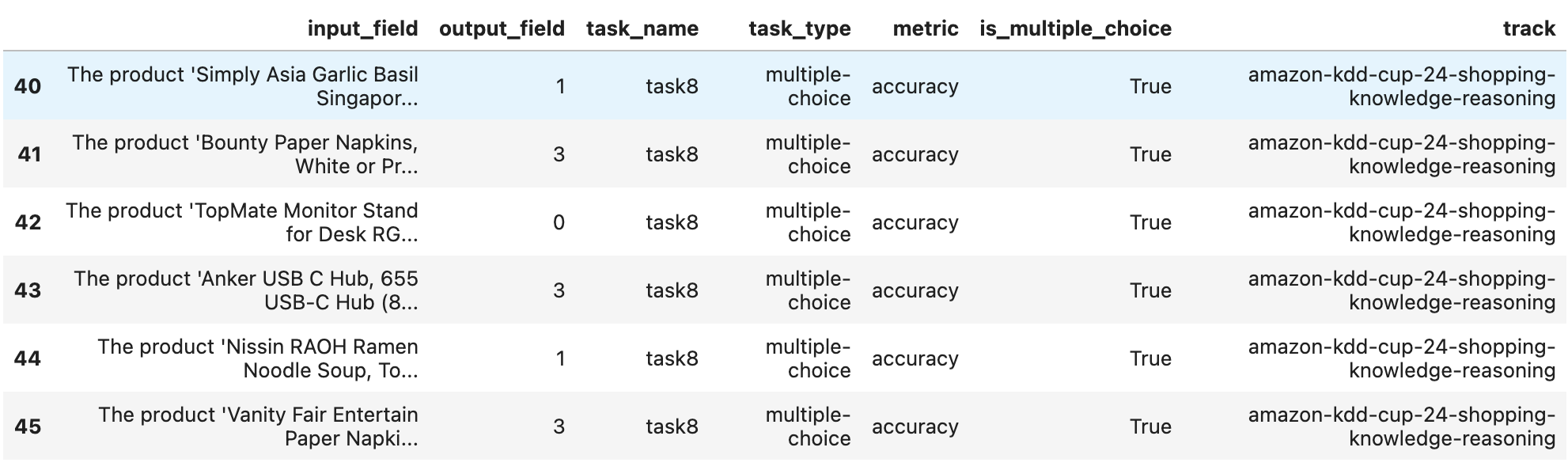
이런 문제가 총 16개 있었습니다.
input_filed가 제대로 보이지 않아서 출력해보면

이러한 문제가 있었습니다.
여기서 중요하게 본 부분은 input_filed에 문제, 보기, answer: 이 3가지가 존재한 것을 발견하였습니다.
또한 위에서 output_field가 숫자 하나만 뱉어내기에 이것도 중요한 부분인 것 같습니다.
학습방법
학습의 자세한 방법은 구글링 하면 잘 나오니.. 그건 패스하고
파인튜닝을 하기위해 query와 response만으로 학습을 하려고 합니다.
query는 앞에서 예시 문제처럼
문제, 보기, 마지막에 answer:를 붙여서 query로 넣고 response는
문자(숫자지만 str로 되어있었음) 1개를 넣어 파인튜닝하였습니다.
학습을 위한 프롬프트 세팅은 학습하는 단계에서 설명하겠습니다..!
학습데이터 구하기
모든 데이터는 huggingface에서 구했습니다.
multiple choice 문제가있고 그것에 대한 대답으로 이루어진 데이터를 찾아보았으나 당연히 없었습니다.. (날로먹기 실패)
그래도 비슷한 건 있었습니다.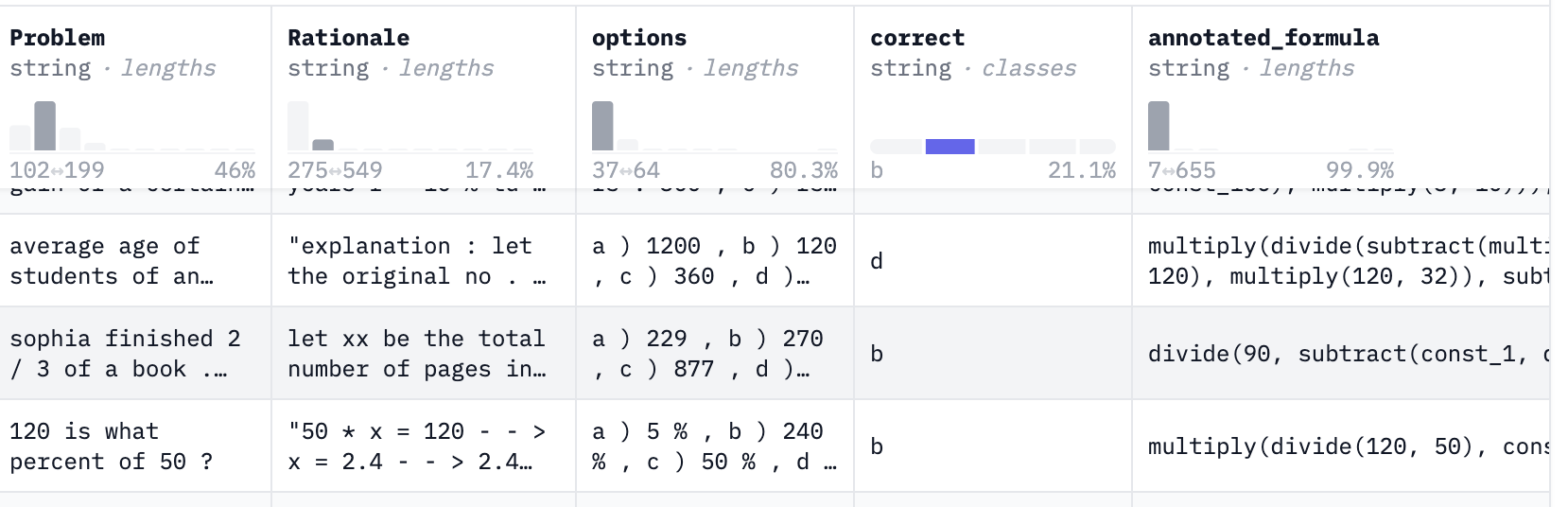
Problem, option, correct 등등 이루어진 데이터셋이었는데
이걸 원하는 형태로 변형하면 됩니다. 이러한 데이터셋을 모아서 10만 행을 가진 데이터셋을 만들었습니다.
원래 분할해서 학습을 하려했으나...실패하였습니다. 이건 학습하는 과정 보일 때 설명하겠습니다...ㅠ..
최종적으로 수학데이터셋, 감성데이터셋, 쇼핑데이터셋으로 학습을 진행하였습니다. 시간이 없어서 많이는 못했습니다...
여튼 이런 방법으로 query 와 response로 학습을 하면 됩니다. 참 쉽죠.......
말은 진짜 쉬운데 막상 코드와 데이터를 다루는 순간 수백가지의 에러를 보게 될 것입니다. LLM 파인튜닝은 참... 번거롭고 힘드네요...
학습이 끝나면 그냥 model.pt 나오면 얼마나 좋습니까...
이상한 .json , .safetensors등.. 당황했지만 이제는 친숙해졌습니다..ㅎ
이렇게 학습이 된걸 model 폴더에 넣고 파이썬 파일들을 수정하여 불러옵니다.
출력을 생성하는 predict함수만 제대로 작성해서 제출하면 됩니다. predict함수는 ground_truth와 비교하기 위한 최종출력단 이라고 생각하면 됩니다.
이제 학습 방향까지 정했으니 학습을 하고 검증해서 제출하면 되겠죠?
이떄까지는 몰랐습니다. 제출이 가장 어렵다는걸........
(3)에서 계속... 투비 칸티뉴ㄷ..
