DB 정리 1.
Database: 일정한 규칙, 규악 등을 통해 구조화되어 저장되는 데이터의 모음
DBMS(Database Management System): DB를 제어, 관리하는 소프트웨어
Query: DBMS에 따라 조금씩 다를 수 있으며, 삽입, 조회, 수정, 삭제 등의 명령을 수행하는 언어
Entity: OOP의 객체와 비슷한 개념으로, 각 사물이 가진 속성을 추상화, 구조화한 것
또한 Entity는 Strong Entity, Weak Entity로도 나뉘는데, Weak Entity는 Strong Entity에 종속적이다.
예를 들어 2 개의 Entity, Post와 Comment가 있으면 Comment는 항상 Post가 있어야 존재할 수 있기 때문에 Weak Entity, Post는 Comment가 없어도 존재할 수 있기 때문에 Strong Entity라고 볼 수 있다.
Relation: DB에서 정보를 구분하여 저장하는 기본 단위이며, 관계형 DB에서는 이를 Table이라 부르고 NoSQL DB에서는 Collection이라 한다.
DB의 종류는 RDB(Relational DB), NoSQL(Not only SQL) DB로 나뉘는데, 가장 보편적으로 사용되는 것은 RDB에서는 MySQL, NoSQL은 MongoDB가 있다.
구조와 명칭이 조금씩 다른데, MySQL은 DB-Table-Record, MongoDB는 DB-Collection-Document로 구성되어 있다.
좀 더 자세히 살펴보면, MySQL에서 DB는 여러 개의 Table로 이루어지고, Table은 또 여러 개의 Record로 구성된다.
MongoDB도 비슷하게 DB는 여러 개의 Collection로 이루어지고, Collcetion은 여러 개의 Document로 구성된다.
Attribute(속성): Relation에서 관리하는 구체적이고 고유한 이름을 갖는 정보.
예를 들어, Person이라는 Entity는 이름, 나이, 직업, 학력, 주소 등 수많은 정보를 가지고 있을 것이며, 그것은 모두 Attribute가 될 수 있을 것이다.
그러나 서비스에서 필요로 하는 정보만 뽑아서 Entity의 Attribute로 만드는 것이 보다 효율적일 것이다.
type Person struct {
Name string // 서비스에서 꼭 필요한 정보만 Attribute로 지정
Age int
}
Domain: Relation에 포함된 각 속성들이 가질 수 있는 값의 집합.
예를 들어, 성별이라는 속성의 값은 남, 여가 될 수 있으며, {남, 여}는 성별이 될 수 있는 값의 집합이자 도메인이라고 볼 수 있다.
Field, Record: 앞서 살펴본 Person이라는 Entity는 Name, Age라는 Attribute를 갖는다.
이 때, 각 Attribute의 이름인 Name, Age를 Field라고 부르고, 실제로 저장되는 행 단위의 값을 Record라고 부른다.
Name: "a", Age: 10 // Record(=Tuple)
또한 Record는 Tuple이라고도 한다.
Field Type: 각 Field는 타입을 갖는다.
예를 들어 이름은 문자열, 나이는 정수형 타입이 될 것이다.
MySQL의 정수형 타입은 아래와 같다.
// MySQL INT Types
TINYINT
SMALLINT
MEDIUMINT
INT
BIGINT
날짜 타입은 아래와 같다.
// MySQL Date Types
DATE // 1000-01-01 ~ 9999-12-31(3byte)
DATETIME // 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 (8byte)
TIMESTAMP // 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 (4byte)
문자 타입은 아래와 같다.
// MySQL String Types
CHAR // 항상 고정된 길이(0 ~ 255)
VARCHAR // 가변 길이(0 ~ 65535) 데이터 byte + 길이 기록용 1byte
TEXT // 게시판 본문 등의 큰 문자열 저장 용도
BLOB // 이미지, 동영상 등의 큰 데이터 저장 용도(보통은 S3 등에 저장하기 때문에 사용 빈도 낮음)
ENUM // 최대 65535개의 요소를 가질 수 있으며 0, 1 등의 숫자로 맵핑되어 적은 메모리 소모
SET // 최대 64개의 요소를 가질 수 있으며, 여러 개의 데이터를 선택할 수 있고, 비트 단위 연산 가능
ENUM, SET은 메모리 공간을 절약할 수 있지만 데이터가 변경되었을 때, 정의된 목록을 수정해야 하는 단점이 있음
Relation:
DB에는 여러 개의 테이블이 존재하고, 각 테이블은 서로 관계를 맺고 있는 경우가 있음
1:1
2개의 테이블 User, Email가 있고, 각 사용자는 로그인 이메일을 반드시 하나만 가져야 하는 서비스의 경우, User - Email 테이블은 각 1:1 관계가 됨
1:NPost, Comment가 있으면, 하나의 포스트는 여러 개의 댓글을 가질 수 있지만, 하나의 댓글은 여러 개의 포스트에 존재할 수 없기 때문에 1:N 관계가 됨
이 때, Comment는 Post 없이는 존재할 수 없기 때문에 Weak Entity, Post는 Comment 없이 존재할 수도 있기 때문에 Strong Entity가 되며, Comment가 0인 Post도 있을 수 있음.
즉, 1:N에서 N은 0이 될 수도 있음
N:MStudent, Lecture가 있음.
학생은 여러 개의 강의를 들을 수 있으며, 강의를 듣는 학생도 여러 명이 될 수 있음.
그래서 여러 학생과 여러 강의가 연결될 수 있으므로, N:M 관계가 됨.
두 테이블의 N:M의 관계를 나타낼 때는 하나의 테이블이 더 필요.
Student, Lecture 테이블이 있을 때, Student_Lecture 등의 새로운 테이블을 만들 필요가 있음
Key
: 테이블 간의 관계를 보다 명확하게 하고, 테이블 자체의 index를 위해 설정된 장치
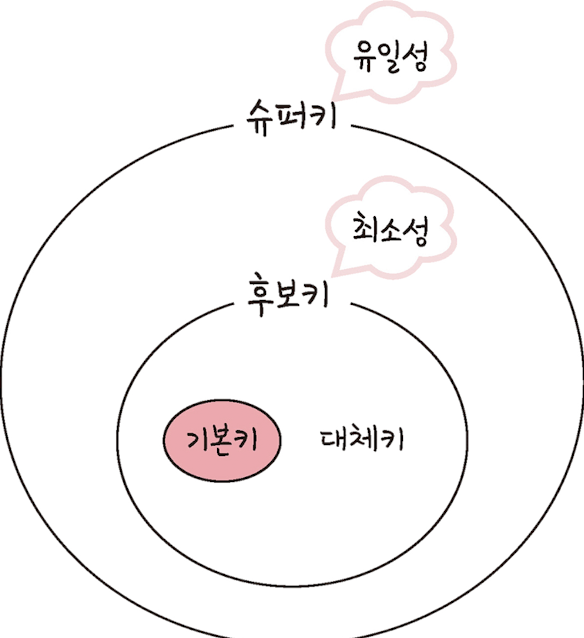
Primary Key: PK라 줄여 말할 때가 많으며, 유일성, 최소성을 만족하는 키.
테이블에 존재하는 각 Record는 반드시 PK가 중복되는 일이 없어야 함.(유일성 위배)
(Name, Age) 등 복합키가 아닌 단일 Attribute가 되어야 함.(최소성 위배)
- 자연키
Person테이블은 이름, 성별, 주민등록번호 등을 속성으로 가지게 될 것이다.
그 중 이름, 성별은 중복될 수 있는 값이지만, 주민등록번호는 각 사람마다 중복되지 않는 고유의 값이다.
ID처럼 각 Record 별로 중복되지 않는 고유의 값을 인위로 만드는 것이 아니라, 자연적으로 존재하는 고유의 값을 자연키라고 부른다. - 인조키
자연키와 반대로 중복되지 않는 고유의 값으로 각 Record를 구별하기 위한 키를 인위적으로 생성하는 것이다. - Foreign Key(FK)
다른 테이블의 PK를 사용하여 테이블 간의 관계를 식별하는 데 사용하는 키다.(중복 가능)
예를 들어,Post,Comment2개의 테이블이 있으면,Comment는 어떤Post에 포함될 수 있는 1:N 관계이기 때문에,Post::id를post_id로 저장하여 FK로 사용할 수 있다.
예를 들어id가 10인Comment의post_id가 1이라면, 해당Comment는id가 1인Post에 달린 댓글이라는 뜻이 될 것이다. - Candidate Key(후보키)
PK가 될 수 있는 후보들이며, 유일성과 최소성을 동시에 만족하는 키 - Alternate Key(대체키)
후보키가 2개 이상일 경우, 그 중 하나를 PK로 지정하고 남은 후보키들을 일컫는다. - Super Key
각 Record를 유일하게 식별할 수 있는 유일성을 갖춘 키
