2024년 1학기 운영체제 수업을 듣고 정리한 내용입니다. 수업 교재는 운영체제 - 내부구조 및 설계원리 8 판입니다.
기본 요소
컴퓨터를 이루는 기본적인 요소들은 다음과 같다.
- CPU
- Main memory (휘발성)
- I/O Module
- HDD
- 네트워크 모듈
- 모니터, 마우스
- ...
- 시스템 버스
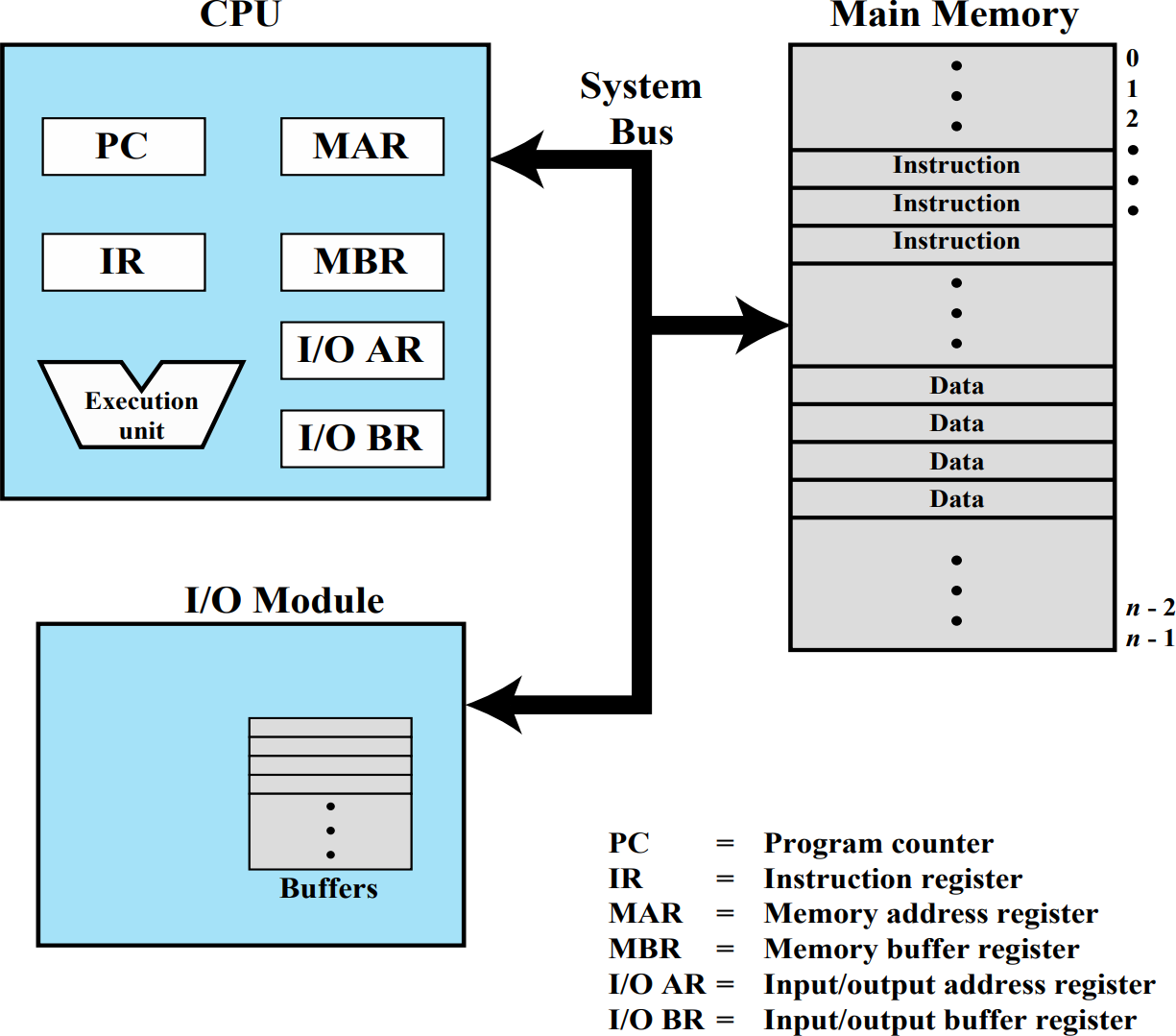
각 요소들은 시스템 버스로 연결된 통로를 통해 데이터를 전달한다.
명령어
명령어는 CPU가 어떤 데이터를 갖고 어떤 행동을 해야 하는가를 담고 있다.
명령어는 두 단계로 나뉘어 처리되는데 명령어를 읽는 단계와 명령어를 실행하는 단계가 있다.
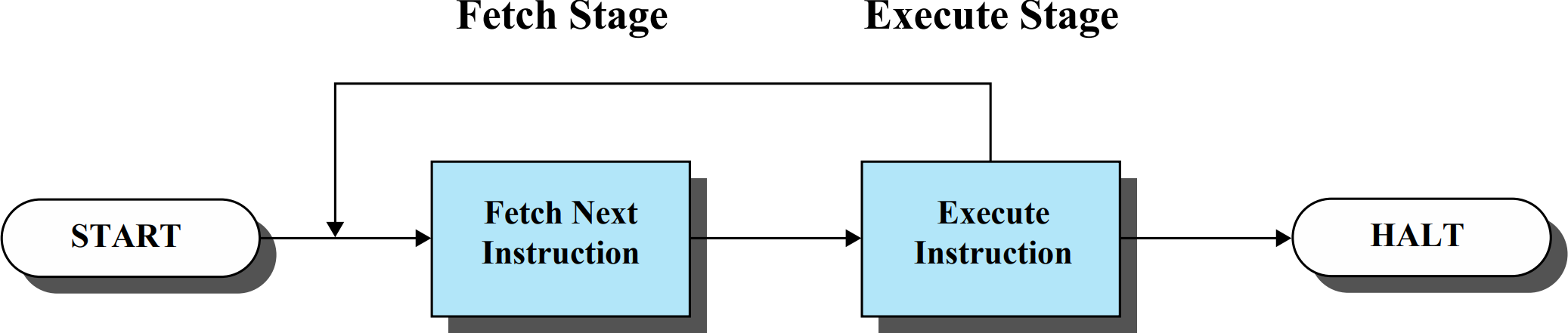
모든 명령어는 이 Fetch-Execution Cycle안에서 처리된다.
Fetch stage
Program Counter를 통해 명령어를 가져오는 단계다.
MAR <- PC, PC++ # PC값을 MAR에 저장
read, MBR <- (MAR) # MAR번지에 위치한 명령어를 읽어 MBR에 저장
IR <- MBR # MBR에 저장된 명령어값을 Instruction Register에 저장Execution stage
가져온 명령어를 분석하여 실제로 수행하는 단계다. 명령어의 종류에 따라 수행하는 작업이 달라진다.
ex) load
Opcode 분석
MAR <- (IR의 주소 부분) # 명령어에 명시된 메모리 주소를 MAR에 저장
read, MBR <- (MAR) # MAR번지에 위치한 값을 읽어 MBR에 저장
AC <- MBR # MBR에 저장된 값을 AC에 저장 (임시 공간에 저장한다는 뜻)Interrupt
Interrupt의 뜻은 중단으로, 유저 프로그램이 실행될 때 정상적인 작업을 중단한 후 OS 작업을 실행하는 것을 말한다.
Interrupt의 종류에는 4가지가 있다.
-
Program
프로그램 실행중 하드웨어에 의해 발생한다. Division by zero, PC를 Data 메모리 영역으로 Jump하거나 하드웨어적인 코드 오염 또는 누락 등이 여기에 해당한다.
-
Timer
프로그램을 바꾸어야할 시간이 되면 발생한다. 실행되고 있던 유저 프로그램을 중단한 후 다른 프로그램으로 교체하여 실행한다.
-
I/O
요청했던 I/O 작업이 끝난 경우 발생한다.
-
Hardware failure
물리적? 오류이다. 파워 문제 또는 RAM 오류 등이 해당한다.
대부분의 Interrupt는 I/O에서 발생한다. 왜냐하면 대부분의 I/O 디바이스는 CPU보다 훨씬 느리기 때문이다. CPU는 I/O 디바이스에게 요청을 한 다음에 기다리지 않고 다른 작업을 하게 된다. 언젠가는 I/O 요청이 처리가 될 것이고 CPU는 거기서부터 다시 작업을 이어나가야 하는데, I/O와 상관없는 작업을 처리중이었으므로 Interrupt가 발생하게 된다.
Instruction cycle with Interrupt
그렇다면 Interrupt는 명령어가 처리되는 과정인 Fetch-Execution Cycle에서 어느 위치에 발생하는 걸까?
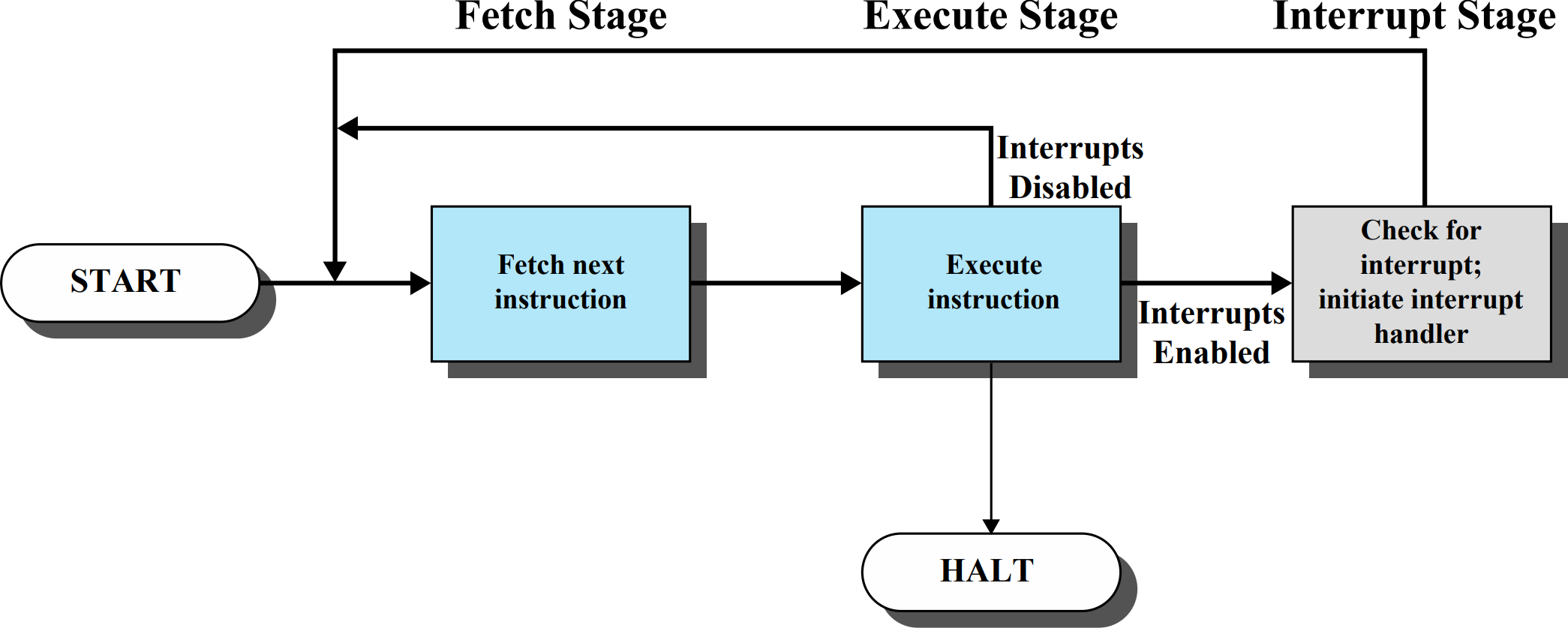
Fetch stage와 Execution stage를 건드리지 않는 대신 두 단계를 거친 후에 Interrupt stage를 거치게 된다. 사실 생각해볼때, 명령어를 읽어오고 수행하는 중간에 중단을 걸어야 한다면 그것을 구현할 하드웨어가 또 필요하다. 비용이 늘어난다! 따라서 하드웨어적으로 해결할 수 있는 방법은 최소화하고 소프트웨어적으로 해결하도록 발전하게 되었다.
Program Status Word
Interrupt stage를 거칠지 말지에 대한 여부는 CPU내에 있는 레지스터중 하나인 PSW(Program Status Word)에 담겨있다. PSW에는 Interrupt stage에 진입할 수 있는지에 대한 정보와 현재 실행중인 프로그램의 실행 주체에 대한 정보 등이 담겨 있다.
PSW를 확인했을 때 Interrupt Enable이 1이라면 Interrupt stage에 진입한다. 여기서는 하드웨어적으로 Interrupt가 발생했는지 확인하고, 만약 발생했다면 현재 실행중인 프로그램을 잠시 중단하고 Interrupt를 처리할 수 있는 Handler program을 불러오도록 한다. (Cycle이 멈추는 것이 아니라 PC값을 Handler program으로 설정하여 다시 Fetch-Execution을 하도록 만든다.)
Interrupt processing
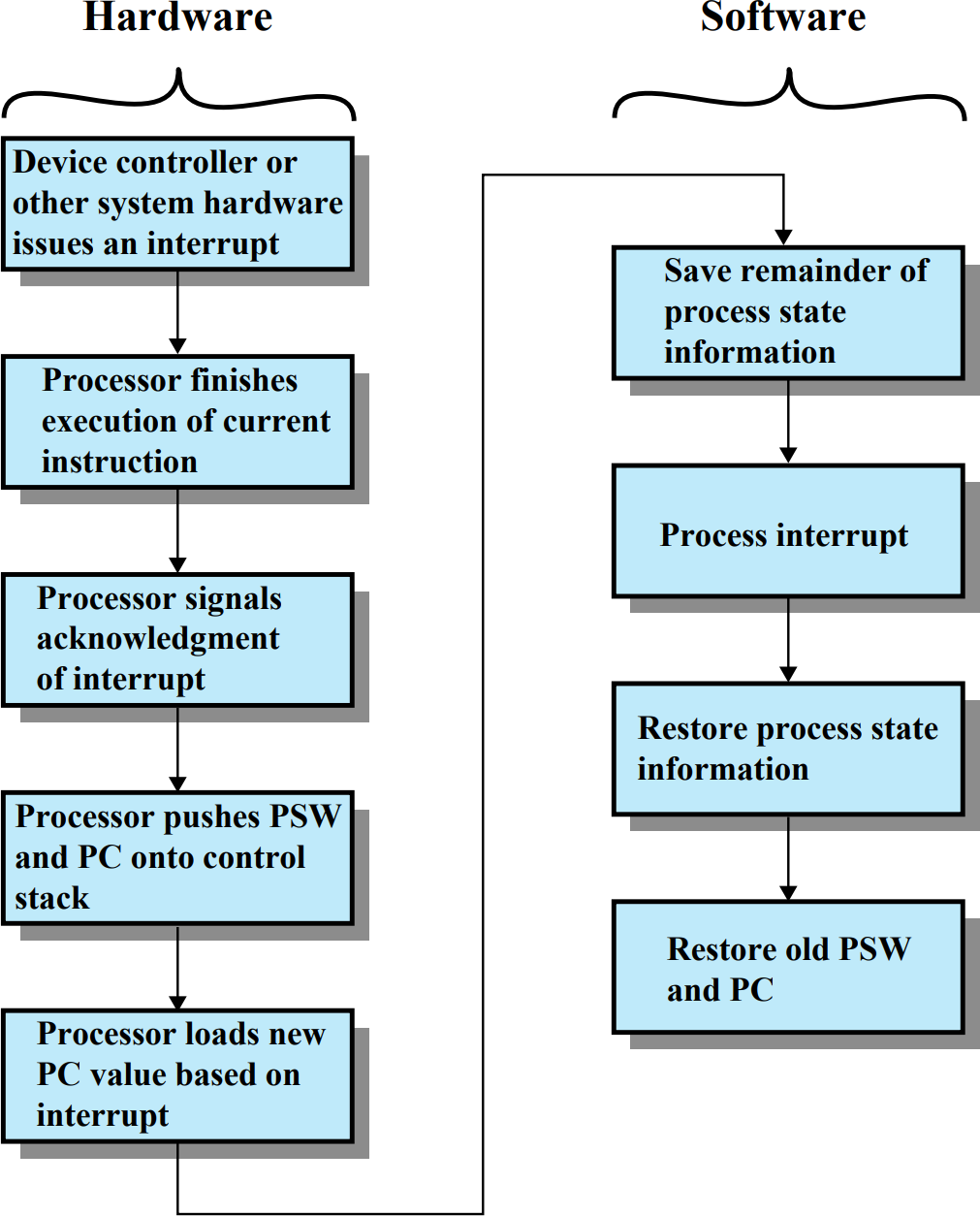
Interrupt는 하드웨어적 처리가 선행되고 그 다음에 소프트웨어적 처리가 진행된다.
-
하드웨어적 처리
- Interrupt 발생에 대한 정보가 어떤 경로를 통해 제기된다.
- CPU가 execution을 끝낸다.
- CPU가 Interrupt stage에서 Interrupt가 발생했음을 하드웨어적으로? 알린다.
- 프로그램의 PSW와 PC값을 Control Stack에 저장한다.
- Interrupt Handler 프로그램의 시작 주소를 PC에 저장한다.
-
소프트웨어적 처리
- Process State Information을 저장한다.
- Handler 프로그램을 실행하여 Interrupt를 처리한다.
- 완료되었다면 저장했었던 Process State Information을 다시 불러온다.
- Control stack에 저장했었던 PSW와 PC값을 불러온다.
Q. 왜 PSW와 PC값을 먼저 저장한다음에 Handler를 불러오는가?
Interrupt를 처리하기 위해서는 Handler program을 불러와야 한다. Handler program을 불러오는 것 또한 Fetch-Execution Cycle에서 진행되므로 PC값을 통해 프로그램을 읽어오게 된다. 이 과정에서 이전에 유저 프로그램을 읽어오던 PC값이 사라지게 된다. 그러므로 먼저 PC값을 저장한 다음 Handler program의 시작 주소를 PC값에 저장해야 한다.
Handler program이 실행되면서 프로세서 즉 CPU에 저장되어 있던 여러 정보들(레지스터)이 변하기 때문에, 하드웨어적으로 미리 백업을 해놓아야 나중에 다시 유저 프로그램을 되돌려 놓았을 때 문제없이 진행할 수 있다.
Cache memory
CPU의 속도가 무진장 빠르기 때문에 메모리에게 요청을 하더라도 기다려야 한다. 굉장히 성능에 좋지 않기 때문에, 덩치가 크지만 느린 메모리에게 요청을 하기보다 크기가 작더라도 나름 빠른 메모리를 중간에 두어 속도를 올리려고 캐시 메모리가 등장했다.
Q. OS는 Cache memory의 존재를 모른다. 왜?
캐시는 하드웨어 레벨에서 동작한다. 하드웨어 단계에서 동작하는 캐시 메모리를 소프트웨어 단계에서 처리하려고 하면 오버헤드가 발생하기 때문이다.
사실 이 문제에 대한 정확한 해답은 얻기 힘들었다.
Direct Memory Access
메모리에 저장된 데이터가 I/O 디바이스에게 전달되어야 한다면 CPU가 중간에서 전달자 역할을 해야한다. CPU를 거쳐야 하는 점 때문에 오버헤드가 발생하게 되는데(버스를 두 번 거쳐서 전달해야하므로), Direct Memory Access 모듈을 사용하면 그런 문제를 개선할 수 있다.
CPU는 DMA 모듈에게 데이터를 전송하라는 신호를 보낼 때에만 관여할 뿐 데이터가 전송되는 과정에는 간섭을 하지 않는다. DMA가 버스를 사용하여 데이터를 전송할 때에는 CPU의 실행이 방해를 받게 되지만, CPU가 전달자 역할을 하는 방식보다는 낫다고 한다.
