2024년 1학기 운영체제 수업을 듣고 정리한 내용입니다. 수업 교재는 운영체제 - 내부구조 및 설계원리 8 판입니다.
멀티프로세서라는 단어는 한 메모리를 공유하는 여러 CPU들의 집합이다.
Scheduling Design Issues
멀티프로세서를 사용한 스케줄링은 3가지 디자인 이슈를 갖는다.
Assignment of Processes to Processors
CPU에게 어떻게 프로세스를 할당해줄 것인지를 말한다. 각 CPU마다 큐를 가질 경우 CPU가 큐에 있는 프로세스를 바로 꺼내와 실행시킬 수 있지만, 각각 실행시간이 다른 프로세스들을 골고루 분배할 수 없는 단점이 있다.
그러므로 이 문제를 해결할 수 없어서 Ready 큐를 글로벌 큐로 1개만 두고 각 CPU가 critical section에 접근하여 한 번에 한 CPU만 꺼내가도록 결정되었다.
Use of multiprogramming on individual processors
프로세스마다 동기화 빈도가 다르다. 어느 프로세스는 다른 프로세스와 동기화를 거의 하지 않고 I/O 작업만 하는 경우가 있고, 또다른 프로세스는 동기화 빈도가 높아서 Blocked되었다가 금방 해제되는 경우가 있다.
동기화 빈도가 낮다면 대개 I/O 작업이나 Page fault 등의 이유로 Blocked되는데, 다시 Ready 상태로 바뀌려면 많은 시간이 걸리므로 그동안 다른 프로세스를 작업하여야 이득이다.
동기화 빈도가 높다면 Blocked되었다한들 곧바로 다른 CPU가 동기화 신호를 보내 금방 Blocked상태가 해제되기 때문에 굳이 다른 프로세스로 스위칭하지 않아도 된다.
즉, 프로세스의 타입에 따라 멀티프로그래밍을 하거나 하지 않는다.
Actual dispatching of a process
멀티프로세서에서 프로세스를 어떤 순서로 실행할지는 큰 상관이 없다.
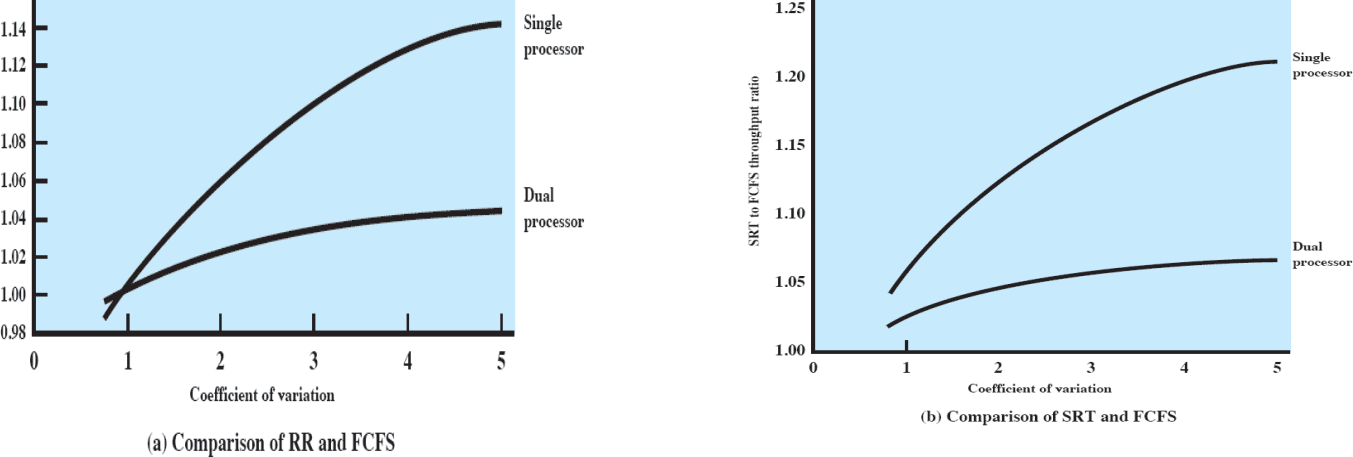
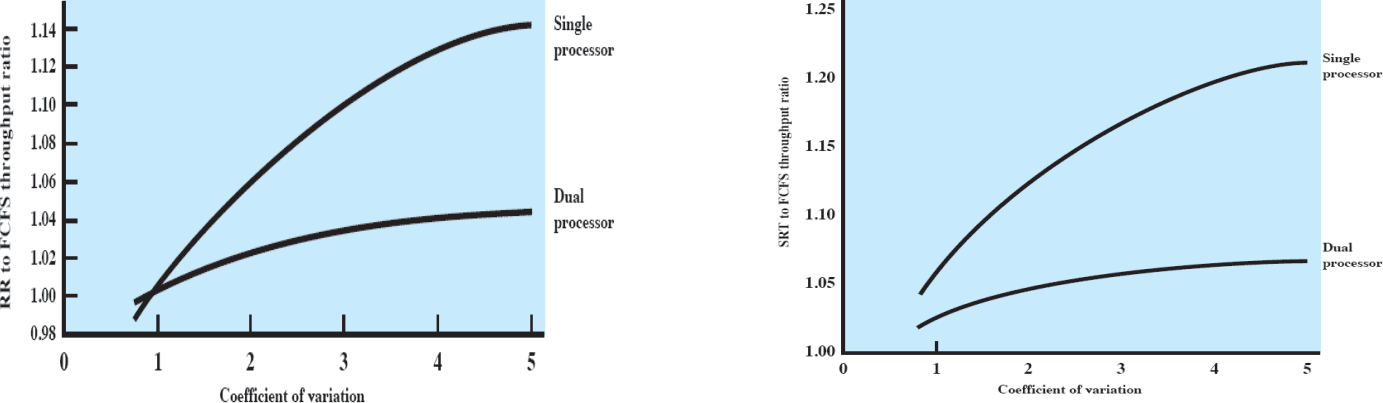
왼쪽은 Round-Robin과 FCFS를, 오른쪽은 SRT와 FCFS를 비교한 그래프다. 세로축은 두 스케줄링 방법의 throughput를 비율로 나타낸 것인데, 간단히 보아도 듀얼 프로세서가 더 낮은 값을 보여주고 있다. 즉, 값이 1에 가깝기 때문에 어느 스케줄링방법을 쓰든 별 차이가 없다는 것이다.
결론적으로 멀티프로세서 환경에서는 스케줄링 순서가 큰 의미를 갖지 못한다. 왜냐하면 싱글프로세서 환경에서는 한 CPU가 작업을 하고 있다면 다른 프로세스들은 실행중인 프로세스가 끝날때까지 기다려야 하지만, 멀티프로세서 환경에서는 그냥 놀고있는 다른 CPU에게 실행을 해달라고 하면 그만이기 때문이다(기다리는 시간이 더 짧아짐!).
Thread Scheduling
스레드의 실행 순서를 결정하는 것이 아니라 실행하는 방식을 결정하는 스케줄링방법이다. 어플리케이션은 여러 프로세스 또는 스레드로 구성되어 있는데 동시에 실행하면 throughput이 좋아진다. 아래의 4가지 방법은 어플리케이션 속 스레드를 실행하는 방법이다.
Load Sharing
CPU 수가 프로세스 수보다 적을 경우 선택할 수 있는 방법이다.
모든 프로세스의 스레드를 글로벌 큐에 올리고, 모든 CPU가 똑같이 일을 한다. 즉, idle-while-busy가 없이 동작한다. 각각의 CPU가 실행할 스레드나 프로세스를 선택한다.
글로벌 큐를 사용하기 때문에 한 번에 한 CPU만 큐에 접근할 수 있으므로 critical section을 구현해야 한다. 만약 누가 스레드를 꺼내가고 있다면 기다려야 하므로 성능이 저하될 수 있다. 그리고 여러 CPU를 오가면서 스레드가 실행되기 때문에 캐시를 제대로 활용하지 못한다. 또한 어플리케이션 단위로 실행되는 것이 아니라 스레드 단위로 실행되기 때문에 한 어플리케이션 속 스레드가 모두 동시에 실행되는 것이 아니다. 그러므로 동기화를 이유로 Blocked 되었다면 그 상태가 언제 해제될지 모른다.
보통은 CPU개수가 프로세스 개수보다 훨씬 적기 때문에 보편적으로 사용하는 방법이다.
Gang Scheduling
CPU의 수가 충분히 많을 경우 사용하는 방법이다. 어플리케이션 단위로 줄을 선다. 어플리케이션 속 스레드가 Blocked 되더라도 스레드 스위칭을 하지 않는다. 여러 어플리케이션을 실행할 경우 Round-Robin으로 정해진 시간마다 번갈아가면서 실행한다.
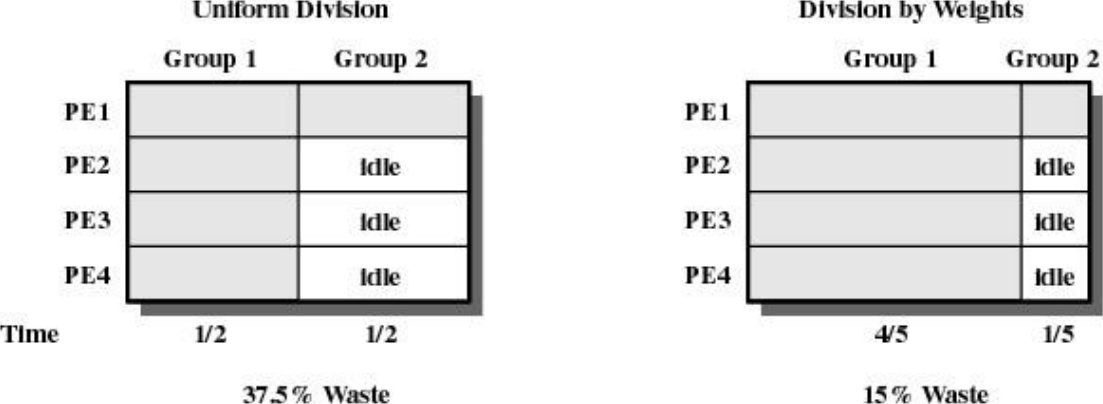
왼쪽 그림을 보면 어플리케이션(그룹) 2개를 실행할 때 1번 그룹은 스레드가 4개, 2번 그룹은 스레드가 1개이다. 만약 두 어플리케이션이 단순 Round-Robin으로 실행된다면 37.5%만큼 CPU가 쉬게 된다. 따라서 가중치를 부여해 스레드가 많은 어플리케이션에 더 긴 시간을 주면 idle 상태를 줄일 수 있다.
Dedicated Processor Assignment
Gang Scheduling과 같이 어플리케이션 단위로 줄을 선다. 그러나 CPU가 매우 많은 시스템에서 사용하는 방법이기 때문에 각 어플리케이션마다 CPU를 할당하여 어플리케이션이 종료될 때까지 그 CPU 집합에서 작업을 수행한다. 즉, Timeout없이 작업을 끝까지 한다(Batch 프로그래밍)
Dynamic Scheduling
어플리케이션 속 스레드 개수가 몇 개인지 정확하게 알 수 없기 때문에 실행 중에 동적으로 변경하는 방법이다.
OS는 CPU를 할당해주는 역할만 한다. 그러므로 스레드 스케줄링은 각 어플리케이션이 담당하게 된다.
OS는 어플리케이션에게 CPU를 할당해주되, 남는 CPU가 없으면 CPU를 2개 이상 갖고 있는 어플리케이션의 CPU를 뺏어서 준다. 모든 어플리케이션이 CPU를 한 개씩만 갖게 되는 상황이 발생하면 그 때 어플리케이션이 Ready 큐에서 기다리게 된다.
Real-Time Scheduling
Real-Time Task는 데드라인이 존재하는 작업이다. 즉, 정해진 시간까지 무조건 끝내야하는 작업이다. Real-Time Task에는 두 가지 종류가 있다.
-
Hard real-time task
데드라인을 못 맞출 경우 시스템이 터져버리는 작업이다.
-
Soft real-time task
데드라인을 못 맞추어도 시스템이 터지지 않는다. 그러나 그 시간동안 아무것도 하지 않은 것으로 처리되므로 throughput이 낮아지게 된다.
또한 이런 작업들은 주기적인 작업과 비주기적인 작업으로 나뉘는데, 주기적인 작업은 시스템에서 주기적으로 호출하기 때문에 주기, 데드라인, 실행 시간을 모두 알고 있다. 반대로 비주기적인 작업은 갑자기 등장한 작업으로, 사전에 주기, 데드라인, 실행 시간을 알지 못한다. 비주기적인 작업은 스케줄링하기 어려우므로 주기적인 작업을 스케줄링한다.
Earliest-deadline Scheduling
- 데드라인이 빠른 작업부터 처리한다.
- Preemptive 방식이다.
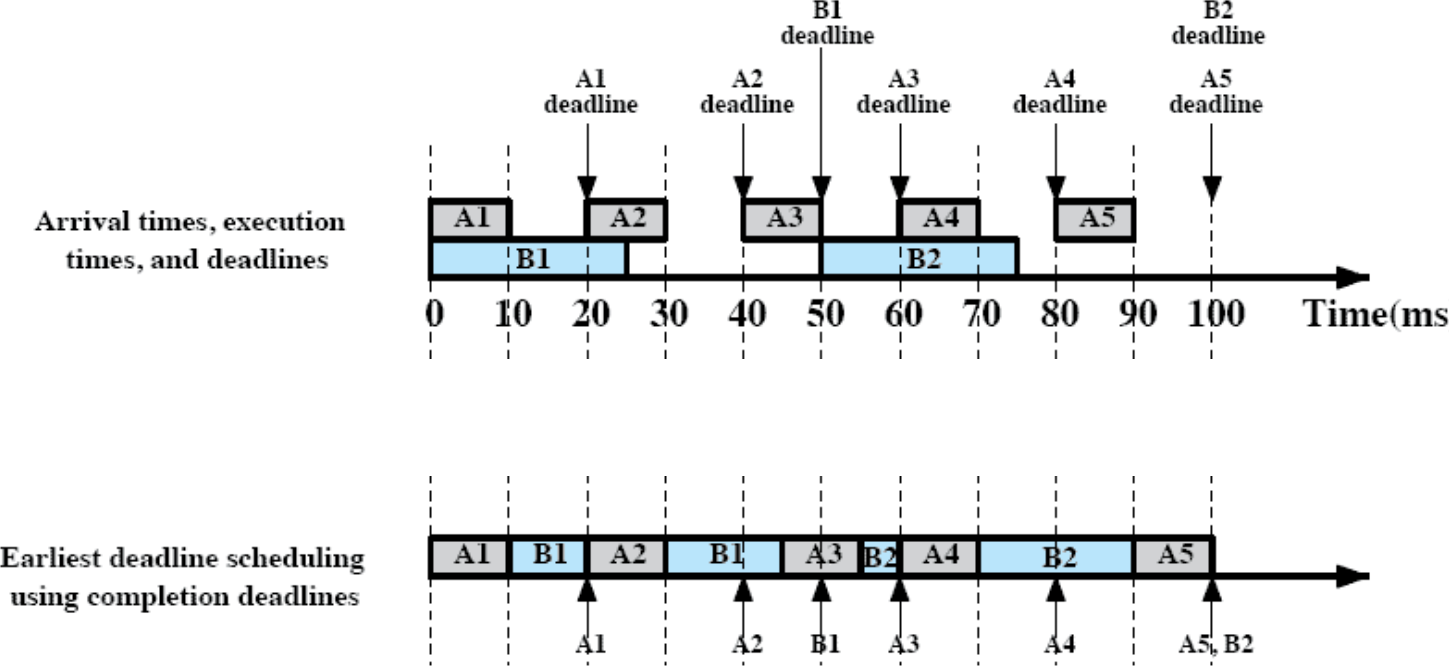
위에 있는 그림은 도착한 시간과 실행 시간, 그리고 데드라인을 보여주는 타임라인이다. Earliest-deadline을 적용하면 아래에 있는 그림으로 나타난다.
0초에 A1과 B1이 도착했지만 데드라인이 더 짧은 작업은 A1이다. 따라서 A1이 실행되고 10초까지 실행을 한 끝에 작업을 완료하게 되었다. 그 다음 데드라인이 제일 짧은 B1이 실행된다.
B1이 실행되다가 20초에 다시 다음 주기가 돌아서 A2가 도착했다. A2의 데드라인은 30초, B1은 50초이므로 A2가 실행되고, 종료된 이후에는 다시 B1이 실행된다.
40초에는 A3가 도착하는데, A3의 데드라인은 60초, B1의 데드라인은 50초이다. 그러므로 B1이 실행되고 45초에 A3가 실행된다.
이런식으로 데드라인이 더 짧은 작업부터 실행되는데, 80초에는 B2가 실행되는 중에 A5가 도착한다. 두 작업의 데드라인이 같은 상황에서는 먼저 들어온 순서대로 작업하기로 결정되어 있다. B2가 먼저 도착했기 때문에 B2가 실행되고 그 다음에 A5가 실행된다.
Rate monotinic Scheduling
- 작업마다 부여한 우선순위에 따라 실행한다. 우선순위는 주기가 더 짧은 작업이 높다.
- Preemptive 방식이다.
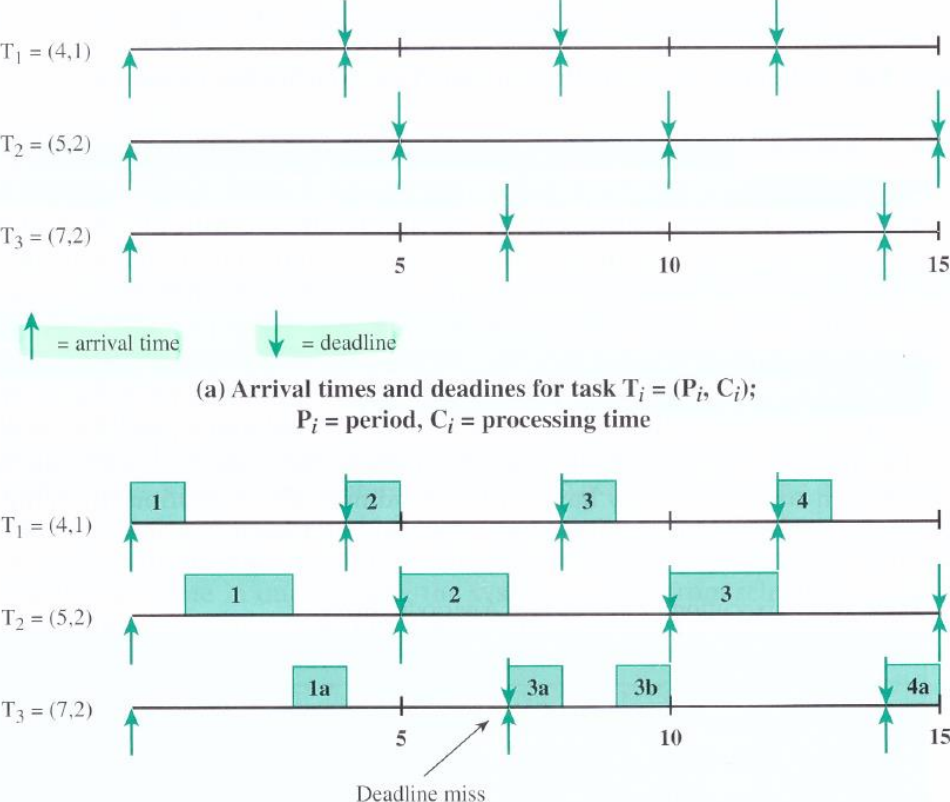
위에 있는 그림은 부터 까지 주기 및 실행 시간과 데드라인을 보여준다. 은 주기가 고 실행 시간이 라는 뜻이다. 이 주기가 4이므로 우선순위가 제일 높고 이 주기가 7로 우선순위가 제일 낮다.
까지 실행을 마치고 가 실행되는데, 4초에 다시 이 등장한다. 당연히 이 우선순위가 높기 때문에 은 에게 순서를 뺏긴다. 이 실행을 마친 순간 가 다시 등장한다. 역시 가 더 높은 우선순위이므로 순서를 뺏기게 된다.
7초가 되어서 는 종료되지만, 의 데드라인에 도달하게 된다. 따라서 은 작업을 miss하게 된다. 작업한 것 버리고 새로 작업을 시작하게 된다.
12초에 의 4번째 작업이 시작하고 13초에 종료되지만, 와 모두 데드라인에 맞춰 작업을 종료하고 다음 주기를 기다리고 있으므로 실행할 작업이 없다. 이런 상황에는 CPU가 idle상태가 된다.
결론적으로 Earliest-deadline보다 throughput은 낮다. 그러나 대부분의 OS들은 이 방법을 사용한다.
Priority Inversion
우선순위가 더 높은 작업을 처리할 때 우선순위가 낮은 작업이 우선순위가 높은 작업보다 먼저 처리되는 현상이 일어나는데 이걸 Priority Inversion이라고 부른다.
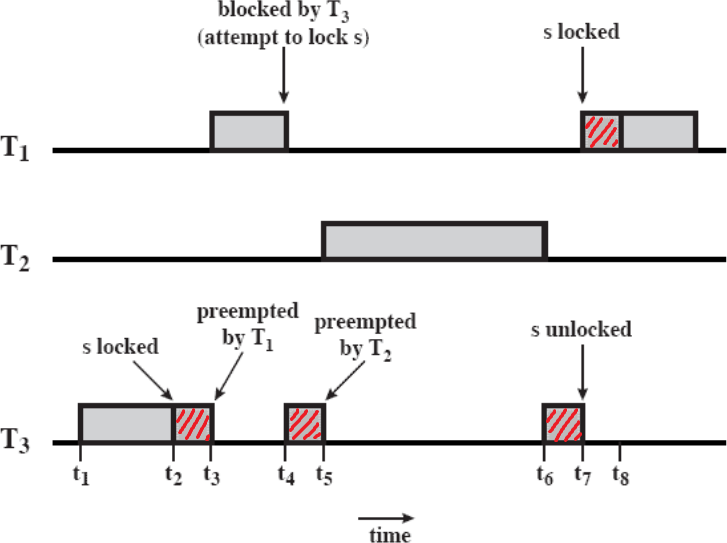
이 critical section으로 진입한다. 빨간색 빗금친 영역이 critical section에 진입한 상태를 의미한다. 이 등장하게 되어서 은 순서를 뺏기게 된다. 또한 critical section으로 진입하는데, 이미 이 있기 때문에 Blocked된다.
이 멈췄으므로 이 다시 실행되는데 가 등장해서 순서를 뺏긴다. 가 실행을 마치면 다시 이 실행된다.(은 Blocked 되었으므로 실행 가능한게 뿐이다)
이 critical section을 탈출하는 순간 이 Blocked 상태에서 해제되어 순서를 뺏긴다.
은 critical section에 진입하는 순간 이 실행을 마쳐야 실행되는 모습이 보인다. 즉, 우선순위값으로는 인데 실제 실행은 순으로 실행된다. 이게 Priority Inversion이다.
이 문제는 우선순위값을 상속시킴으로 해결가능하다. 자신보다 우선순위가 낮은 Task가 lock을 건 데이터에 접근할 때 그 Task에게 자신의 우선순위를 상속하는 것이다.
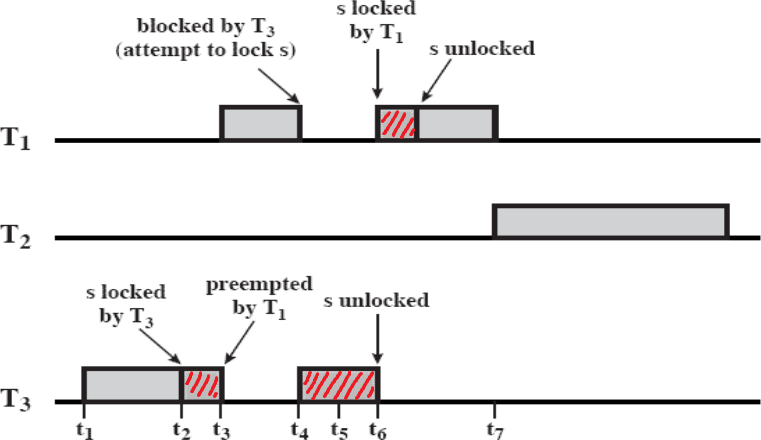
이 critical section에 진입하고 이 등장해서 순서를 뺏긴다. 이 critical section에 진입할 때 이미 이 진입해 있으므로 Blocked 된다. 이 때 의 우선순위를 에게 상속해준다.
이 Blocked 된 후 가 등장해도 의 우선순위가 과 같기 때문에 에게 순서를 뺏기지 않고 실행하게 된다. 이 critical section을 탈출하면 에게 제어가 넘어가고, 이 적절히 실행을 마치면 다시 에게 순서가 넘어간다.
우선순위를 상속한 시점에 우선순위값은 이렇게 변한다.
Windows Scheduling
윈도우는 Real-time 작업과 그렇지 않은 작업을 나누었다. Real-time 작업은 16부터 31까지의 우선순위 값을 갖는 16개의 큐를, Non Real-time 작업은 0부터 15까지 우선순위값을 갖는 16개의 큐를 사용한다. 우선순위 값이 높을수록 우선순위가 높다(0번이 제일 낮음).
Real-time 작업은 우선순위값이 고정이며 실행중에 달라지지 않는다. 우선순위가 높은 것부터 처리하되 같은 큐에 있는 작업들은 Round-Robin으로 처리한다.
Non Real-time 작없은 Feedback 방식을 사용한다.
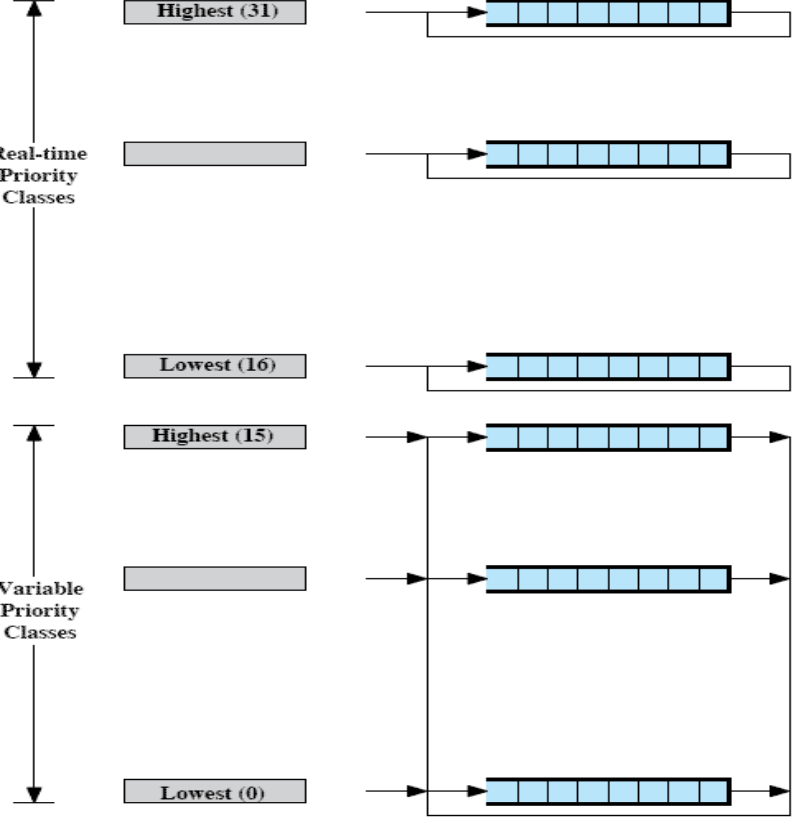
Real-time 작업들은 우선순위가 고정이므로, Timeout되면 다시 같은 큐로 들어간다. 큐에 작업이 1개라면 Timeout이 없는 셈이고, 큐에 작업이 여러 개면 Round-Robin으로 작업한다. 만약 실행 중에 자신보다 우선순위값이 높은 작업이 등장하면 CPU를 뺏기고 다시 같은 큐로 진입한다.
Non Real-time(Variable Priority) 작업들은 Feedback 방식을 사용하기 때문에 Timeout되면 한 단계 아래의 큐로 이동한다. 자기가 있었던 큐에서 한 단계 아래로 가게 되는데, 만약 0번에 위치한다면 더 아래로 갈 수 없기 때문에 0번 큐로 다시 진입한다. 반대로 I/O작업 때문에 Blocked 되었다면 그 상태가 해제될 때 우선순위를 한 단계 높여 이동한다. 만약 15번 큐까지 올라갔을 때 Blocked 상태가 해제된다면 다시 15번 큐로 이동하게 된다.
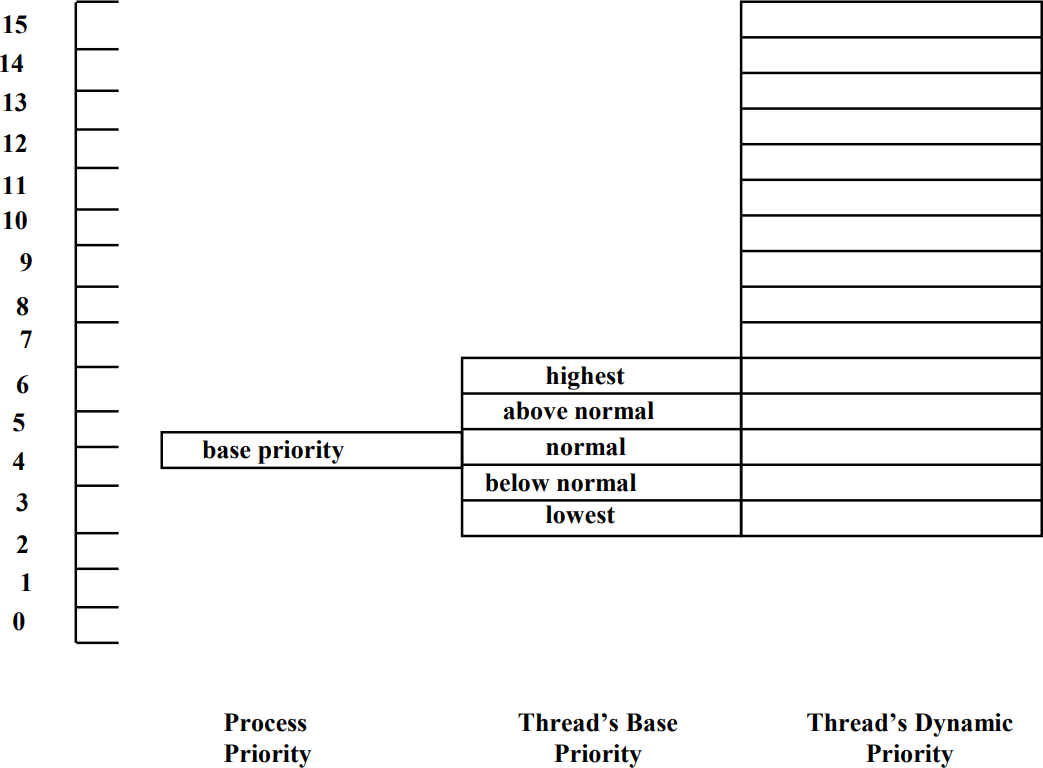
작업의 우선순위는 프로세스의 Base Priority와 스레드의 Base Priority에 의해 결정되고 실행중에 변경된 값은 Dynamic Priority이다. 프로세스의 Base Priority는 프로세스의 타입에 의해 정해지는 우선순위이고 이 값을 기준으로 하여 ±2만큼 변경 가능한 것이 스레드의 Base Priority이다. 이 우선순위값은 실행중에 변경되는데 이것이 Dynamic Priority이다. Dynamic Priority는 스레드의 Base Priority보다 낮아지지 않으며, Variable Priority의 범위인 15보다 커지지 않는다.
CPU가 다음에 실행하는 것은 우선순위가 높은 스레드이므로 Load Sharing과 같이 Idle-and-Busy문제가 일어나지 않는다. Load sharing처럼 여러 CPU를 오가며 작업을 하기 때문에 캐싱이 제대로 안되는 문제가 발생한다. 윈도우에서는 이 문제를 해결하기 위해 Affinity를 설정하여 특정 CPU 집합에서 실행하도록 설정한다.
UNIX SVR4 Scheduling

UNIX는 Real-time 프로세스들은 159~100번 큐에서, 커널모드 프로세스들은 99~60번 큐에서, 유저모드 프로세스는 59~0번 큐에서 작업한다. (0번이 제일 낮은 우선순위다.)

UNIX에서 큐를 탐색할 때에는 비트마스킹을 통해 빠르게 탐색한다. 큐에 원소가 있는지 없는지 빠르게 알기 위해 큐에 원소가 있으면 1, 그렇지 않으면 0인 비트만 모아놓은 자료구조로 탐색한다. 비트 수가 160비트=32비트 5이므로 간단히 확인가능하다.
윈도우와 같이 우선순위 기반의 Preemptive 스케줄링을 사용하고, Real-time 작업들 또한 우선순위가 고정되어 있으며 같은 큐에서는 Round-Robin을 사용한다. Non Real-time 작업들은 Feedback 방식을 사용한다.
윈도우와 다른 점은, 우선순위가 낮은 큐에 긴 실행 시간을 부여하여 낮은 우선순위를 가진 프로세스가 실행될 때 최대한 긴 실행시간을 주어 작업을 끝낼 수 있도록 유도한다(Starvation 해결).
Linux Scheduling
리눅스 역시 Real-time 작업들은 0~99번 큐에서, Non Real-time 작업들은 100~139번 큐에서 작업한다.
리눅스는 스케줄링 방법을 선택할 수 있다. Real-time 작업들은 FIFO 또는 Round-Robin방법중 하나를 선택할 수 있다. 이 작업들은 실행 시간이 짧기 때문에 스위칭 중에 끝날 수 있는 작업들이 대부분이다. 사전에 이미 모든 정보를 알고 있는 작업들이므로 실행 시간이 짧은 작업들이 많다면 FIFO를, 실행 시간이 긴 작업이 많다면 Round-Robin을 고를 수 있도록 한 것이다.
리눅스 역시 각각의 큐들은 우선순위 기반의 Preemptive 방식이다.
FIFO를 사용할 때 Real-time 작업들은 다음 상황이 아니라면 멈추지 않고 실행한다.
- 더 우선순위가 높은 작업이 등장할 때
- 실행중인 작업이 Blocked 될 때
- 시스템 콜을 사용하여 Blocked 될 때
- 같은 우선순위를 가진 Task가 여러 개여서 FIFO에 의해 순서를 기다릴 때
Round-Robin을 사용한다면 위 4가지 상황에서 멈추게 될 뿐만 아니라 Timeout될 때 Preemptive된다.
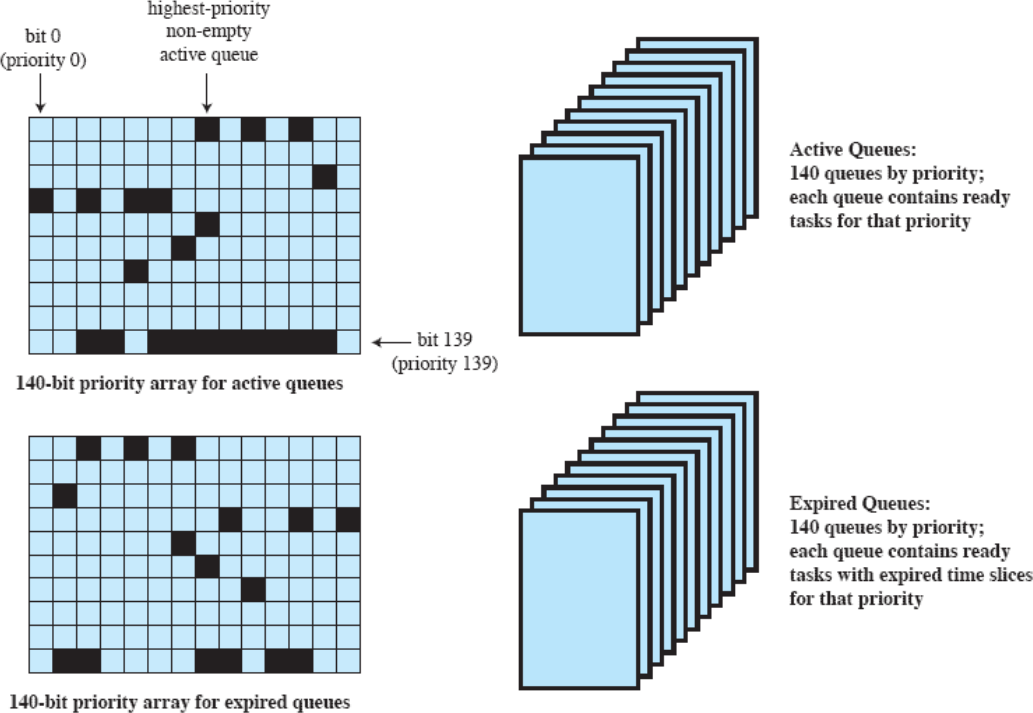
리눅스는 비트맵을 사용하여 큐를 탐색한다. 그리고 큐를 두 개로 사용하는데, active와 expired 두 개를 사용한다.
새로 들어온 작업은 active 큐로 진입한다. 여기서 가장 우선순위가 높은 작업을 선택해 실행한다.
Real-time 작업들은 Timeout되면 다시 같은 active큐로 간다.
Non Real-time 작업들은,
- Timeout되면 우선순위를 한 단계 낮춘 expired 큐로 이동한다.
- I/O 작업으로 Blocked 되면, Blocked 상태가 해제될 때 한 단계 높은 우선순위의 active 큐로 이동한다.
- 더 높은 우선순위를 가진 작업이 등ㅈ아한다면 같은 우선순위의 active 큐로 이동한다.
active큐가 비어있게 되는 상황이 발생하면 active 큐와 expired 큐를 교체한다.
Q. 왜 교체하나?
139번 큐와 100번 큐에 작업이 있다고 가정하자. 큐가 하나만 있다고 생각하면 100번 큐가 작업을 다 마칠 때까지 우선순위가 점점 낮아지면서(100->101->...->138->139) 실행되기 때문에 139번 큐에 있는 작업은 실행 기회를 거의 못잡는다.
따라서 우선순위가 높은 작업들이 더 많이 실행되기 때문에 우선순위가 낮은 작업들이 CPU를 잡을 기회를 주기 위해서 한 번 실행을 마친 작업들은 expired 큐로 이동함으로 Starvation을 해결하려고 한 것이다.
