2024년 2학기 멀티코어프로그래밍 수업을 듣고 정리한 내용입니다. 수업 교재는 Computer Architecture: A Quantitative Approach입니다.
VGG16모델을 구현하면서 느낀 최적화 방법을 몇 가지 소개하는 글입니다.
Im2Col
영역에 대한 컨볼루션 연산은 상당히 까다롭다. 동적할당을 해보면 알 수 있듯 메모리는 사실 1차원 배열로 되어 있다. y인덱스를 증가시켜 접근한다는 것은 시각적으로는 바로 아래에 있는 데이터에 접근하는 것으로 보이지만 실제로는 가로 길이만큼 이동한 다음에 x인덱스만큼 더 이동하여 접근하는 것이다. 당연히 왔다갔다 하므로 복잡한 참조가 일어난다. (정확히는 Memory Coalescing을 지키지 않는 것이다.)
Bank Conflict
또한 컨볼루션을 진행하다보면 메모리 참조를 중복하게 된다. stride가 1이기 때문에 내가 계산하기위해 참조해야할 데이터는 바로 옆이나 아래에서 진행할 때 또 참조하게 된다. 동시에 여러 커널이 실행되어 컨볼루션을 한다면 아까 말했던 메모리 참조가 동시에 일어난다. CUDA에서는 메모리를 bank로 부르는데, 이 bank는 한 번에 한 사람만 접근할 수 있다. 따라서 동시에 컨볼루션을 한다면 다른 사람이 bank에 접근하여 데이터를 참조하고 있을 때 나는 접근할 수 없게 된다. 이걸 Bank Conflict라고 부른다. im2col을 한다면 각자 크기의 데이터를 접근하게 될 때 서로 다른 메모리에 접근하는 것이 보장되므로 bank conflict를 없앨 수 있고, 최적화가 성공한다.
하지만 당연히 GPU의 메모리를 더 쓰게 되므로 메모리가 부족한 환경이라면 사용하지 못하는 방법이다. 이번 프로젝트는 RTX 3060 12GB을 사용하기 때문에 제약을 받지 않아 적용할 수 있었다.
'임시 - 쿠다 공유메모리 뱅크 충돌이란.' - Yes! Programmer
'multithreading - What is a bank conflict? (Doing Cuda/OpenCL programming)' - Stack Overflow
im2col에 대해서는 여러 블로그에 잘 정리되어 있으므로 찾아보면 금방 알 수 있다.
그래서 컨볼루션 레이어 직전에 미리 다른 글로벌 메모리에 크기의 입력 채널을 im2col 커널 코드로 처리하여 크기의 입력 채널로 확장한 다음 컨볼루션을 진행하면 기존 컨볼루션을 로 바꿀 수 있다. 1차원으로 접근할 수 있으므로 인덱스관리가 간단해진다.
Memory Coalescing
한 그룹 속 여러 스레드들이 동시에 GPU상에서 실행된다면 동시에 메모리 참조를 하게 된다. 이 때 각 스레드들이 따로따로 다른 위치에 있는 메모리를 참조한다면 글로벌 메모리 참조가 복잡해진다. CUDA에서는 스레드들이 한 단위(Warp)로 묶여서 메모리 접근을 한다. 쉽게 말해서 단체로 메모리 블록에 들어오게 된다. 단체로 메모리에 들어왔으니 단체 행동을 하면 관리가 단순하지만 각자 다른 메모리 영역을 참조하게 된다면 복잡해지게 된다.
GPT에게 Memory Coalescing을 물어보면 이렇게 답을 해준다.
메모리 대역폭 효율 극대화
GPU의 전역 메모리(global memory)는 메모리 대역폭이 한정되어 있습니다. 메모리 코얼레싱을 따르면 여러 쓰레드가 메모리에 접근할 때, 개별 메모리 요청을 하나의 병합된(coalesced) 요청으로 처리할 수 있습니다. 이로 인해 메모리 대역폭이 효율적으로 사용되며 데이터 전송 비용이 감소합니다.
예시)
잘 코얼레싱된 접근 → 128바이트 요청 한 번 (하나의 warp 내에서)
비코얼레싱 접근 → 32개의 개별 요청 발생전역 메모리 접근 레이턴시 감소
GPU의 전역 메모리는 레이턴시(latency)가 높습니다. 코얼레싱된 접근은 더 적은 메모리 트랜잭션(memory transaction)으로 필요한 데이터를 가져오기 때문에 레이턴시를 줄이고, 계산과 메모리 접근 간 병렬성을 증가시킵니다.워프 실행 효율성 향상
메모리 코얼레싱을 지키지 않으면, 여러 쓰레드가 다른 메모리 주소를 참조하게 되어 비효율적인 메모리 트랜잭션이 발생합니다. 이 경우 워프(warp) 내에서 일부 쓰레드만 활성화(active)되고 나머지 쓰레드는 대기 상태가 되기 때문에 실행 효율이 떨어집니다.
따라서 커널 코드를 설계할 때 그룹 내의 스레드가 각각 떨어진 위치에 있는 데이터를 읽도록 하면 성능이 저하된다는 것이다.
'[기본] Memory Coalescing에 이해' - HOTSTONE
'definition - In CUDA, what is memory coalescing, and how is it achieved?' - Stack Overflow
'Memory Coalescing Techniques — mcs572 0.7.8 documentation' - University of Illinois Chicago
Row-major, Column-major
행렬곱을 할 때 앞에서 말했던 Memory Coalescing 문제가 발생하는 곳이다.
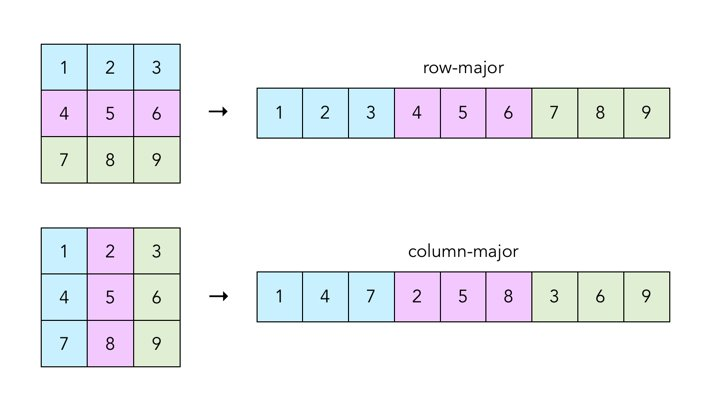
위의 예시는 2차원 배열에서 메모리에 접근할 때 어떤 순서대로 접근하게 되는지 보여준다. Row-major order로 접근하여야만 연속적인 메모리 블록에 접근할 수 있다. 처음에 행렬곱을 구현할 때 Column-major order로 접근했다가 굉장히 오래 걸렸던 이유가 여기에 있었다.
'[Nvidia] OpenCL 기초 문법 및 병렬처리 관련 정리' - The space of T-Kay
'gpu - Optimising Memory Access OpenCL' - Stack Overflow
'graphics - Why OpenGL uses column-major matrix order?' - Stack Overflow
Workgroup Size


여러 발표 자료를 살펴보면 한 그룹 내에 256개의 스레드를 갖는 것을 권장한다고 한다.
Local work size는 Global work size의 약수여야 하고 그 크기는 하드웨어적으로 제한된다. OpenCL 코드를 통해 설정값들을 조회하면 아래와 같은 정보를 얻을 수 있다.
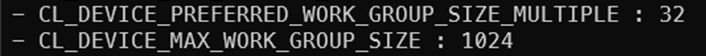
하드웨어적으로 선호하는 배수는 슬라이드에도 나와있듯이 32배수가 적당하다고 한다.
프로젝트에 관련된 최적화
- 한 번에 한 이미지를 처리하지 않고 3천장을 처리하는 프로젝트이기 때문에 3천 장의 이미지를 적당한 크기로 잘라 작업 큐에 넣어 처리한다. 우리 팀은 250장 정도가 적당했다. 이렇게 하면 큐에서 작업을 꺼내 처리하는 오버헤드가 줄어든다.
- 로컬 메모리 사용(타일링)을 통해 최적화 하는 것보다 글로벌 메모리 접근을 최적화하는 것이 더 빠를 수도 있다.
- private 메모리는 레지스터이기 때문에 제일 빠르게 접근할 수 있다. 적은 수의 private 메모리를 적극적으로 사용하는 것이 좋다.
- 한 그룹 안에서 처리하는 작업량이 적다면 그룹 스위칭(?)이 빈번하게 발생하므로 오버헤드가 커진다. 한 그룹 내 스레드들에게 많은 작업량을 할당하는 것이 좋다.
cl_float으로 접근하면 메모리 접근을 할 때 4바이트만 가져오게 된다. 크기의 필터를 가져오려고 한다면 9번 요청하게 된다. 버스 길이가 192비트이므로 한 번에 6바이트를 획득가능하기 때문에cl_float3이나cl_float4를 사용하여 벡터 타입으로 접근한다면 요청 횟수를 줄일 수 있다.
network.bin안에 필터와 바이어스가 붙어있으므로cl_float만 써서 접근할 수 밖에 없다. CNN 코드를 실행하기 전에, 전체 데이터를 복사한 글로벌 메모리에서 필터와 바이어스를 분리하는 커널 코드를 실행하고 각 컨볼루션 레이어마다 분리한 글로벌 메모리를 사용하면cl_float3으로 접근할 수 있다.
im2col을 적용할 때에도 처리 결과를cl_float로 저장하지 않고cl_float3으로 저장한다면 컨볼루션 레이어에서 벡터 타입으로 읽어올 수 있다.
여기까지는 우리 팀에서 생각한 방법들이고, 아래부터는 다른 팀 발표에서 얻은 인사이트다.
- 이미지를 처리하기 위해 데이터를 쓰는 작업과, 이미지를 처리하는 작업은 별도의 버스를 사용한다. (호스트-GPU 간, GPU-GPU 간) 따라서 두 개의 커맨드 큐를 써서 데이터 전송과 데이터 처리를 분리한다. 두 커맨드 큐간 동기화는 이벤트를 사용하여 처리한다.
- 각 이미지를 처리할 때 사용하는 필터가 중복되기 때문에 미리 필터를 private 메모리에 올려둔 후 여러 이미지에 대해서 처리할 때 사용하면 글로벌 메모리 접근을 매우 줄일 수 있다. 우리 팀에서 생각한 방법은 아니라서 조금 아쉬웠다.
이렇게 한다면 커널 코드를 한 이미지에 대해서 처리하지않고 적당한 크기의 이미지 묶음에 대해서 처리하도록 변경해야한다. - 대부분의 데이터들이 0이기 때문에, 만약 현재 가져온 값이 0이라면 연산을 하지 않고 건너뛰도록 만들어 연산 횟수를 줄인다.
실패한 시도들
- FFT를 통해 주파수 영역에서 컨볼루션을 처리하는 방법을 고민해봤지만 필터 크기가 으로 작아서 적용하지 못했다. FFT를 하는 연산이 오버헤드가 굉장히 심해서 적용하지 못했다.
- 다른 조에서 시도한 방법이다. 위노그라드 알고리즘은 행렬곱셈의 연산 수를 줄이는 알고리즘이지만 실제 커널 코드로 구현하면 복잡한 커널이 되기 때문에 오히려 성능이 좋지 않았다고 한다.
참고 자료
OpenCL Optimization, San Jose | 10/2/2009 | PengWang, NVIDIA
