[논문 정리] Learning Transferable Visual Models From Natural Language Supervision (CLIP)
ABSTRACT
SOTA(State-of-the-art, 현 시점 최고 수준의 결과) 컴퓨터 비전 시스템은 미리 결정된 객체 카테고리에서 고정된 집합을 예측
-> 따라서 다른 시각적 주제를 위해선 추가적인 레이블 필요
-> 이를 원시 데이터 학습으로 해결.
어떤 캡션이 어떤 이미지와 일치하는지 예측하는 pre-training이
4억 이미지-텍스트 데이터 쌍의 데이터셋에서 SOTA 이미지 표현을 처음부터 학습하는 데에 효과적.
pre-training 이후, 자연어는 학습한 시각적 주제를 참고 또는 새로운 것을 묘사하는 데에 사용되며 다운스트림 태스크에서 zero-shot 전이학습을 가능하게 한다.
데이터셋별 훈련 없이도 완전 지도 학습과 성능이 비슷.
Zero-shot Learning: 모델이 학습 과정에서 본 적이 없는 새로운 클래스를 인식할 수 있도록 하는 기술. 예시를 주지 않고 지시문만으로 결과를 얻음.
CONCLUSION
주제: NLP에서의 태스크 비종속적 웹 규모 pre-training 결과를 다른 도메인으로 전이 가능한지
훈련 목표를 최적화하기 위해 CLIP 모델은 사전 훈련 중에 광범위한 태스크를 수행하도록 학습.
이러한 태스크 학습은 자연어 프롬프팅을 통해 기존 데이터셋으로의 zero-shot 전이 가능하게 함.
태스크 별 지도 학습 모델과 경쟁이 가능하지만 충분히 더 발전할 수 있음.
INTRODUCTION (Last Part)
약한 지도 모델과 자연어로부터 직접 이미지 표현을 학습하는 최근 연구 사이의 중요한 차이점은 규모.
본 연구에서는 규모에 대한 격차를 해소하기 위해
대규모로 진행된 자연어 지도를 통해 훈련된 이미지 분류기의 동작을 연구.
인터넷 공개 및 대규모 데이터를 통해 4억 개의 이미지-텍스트 쌍으로 구성된 새로운 데이터셋을 생성 후, 처음부터 학습된 ConVIRT의 단순화된 버전인 CLIP(Contrastive Language-Image Pre-training)이 자연어 지도 학습의 효율적인 방법임을 입증.
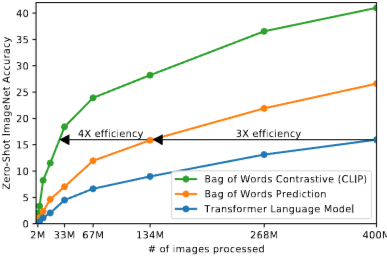
CLIP의 zero-shot 전이 성능을 30개 이상의 기존 데이터셋에서 벤치마킹하여 이전의 작업별 지도 학습 모델과 성능이 비슷함을 확인.
또한 linear-probe 표현 학습 분석을 통해 결과를 확인했으며
CLIP이 공개적으로 사용 가능한 최고의 ImageNet 모델보다 뛰어나면서 계산 효율성이 더 높음.
더불어 zero-shot CLIP 모델이 동등한 정확도의 지도 학습 ImageNet 모델보다 훨씬 더 강건하다는 것을 발견, 이는 태스크 비종속적 모델의 zero-shot 평가가 모델의 실제 능력을 훨씬 더 잘 나타냄.
INTRODUCTION (Prior)
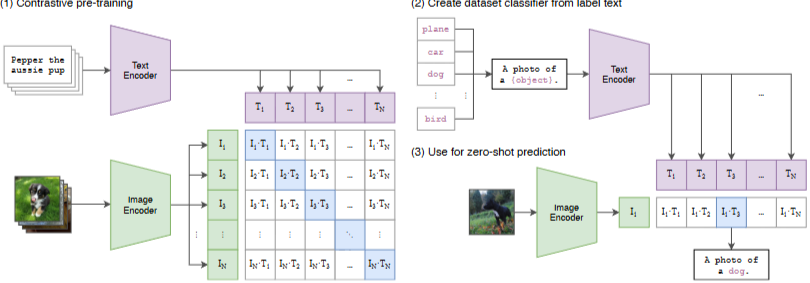
raw text로부터 학습하는 pre-training의 혁신.
웹의 텍스트 데이터에서 사전 학습 방법들이 얻을 수 있는 종합적인 지도 정보가
사람이 직접 라벨링한 고품질의 NLP 데이터셋이 제공하는 지도 정보보다 좋음.
-> 하지만 컴퓨터 비전엔 적용되지 않음.
-> 선행 연구를 봤을 때 적용 가능.
- 이미지-텍스트 쌍 문서의 명사와 형용사를 예측하도록 모델을 훈련하여 콘텐츠 기반 이미지 검색을 개선
- 이미지와 관련된 캡션의 단어를 예측하도록 훈련된 분류기를 매니폴드 학습을 통해 더 효율적인 이미지 표현을 학습
- 저수준 이미지 및 텍스트 태그 특징 위에 다중 모드 Deep Boltzmann Machine을 훈련하여 심층 표현 학습
- 연구 흐름을 현대화하고 이미지 캡션의 단어를 예측하도록 훈련된 CNN이 유용한 이미지 표현을 학습
-> 이미지에 대한 제목, 설명 및 해시태그 메타데이터를 bag-of-words 다중 레이블 분류 작업으로 변환, AlexNet을 사전 훈련하는 것이 전이 학습에서 ImageNet 기반 사전 학습과 유사한 성능 - n-그램을 예측하도록 확장하고, 학습된 시각적 n-그램 사전 기반으로 대상 클래스를 점수화하고 가장 높은 점수를 가진 것을 예측함으로써 다른 이미지 분류 데이터셋으로 zero-shot 전이하는 능력을 입증
- 트랜스포머 기반 언어 모델링, 마스크드 언어 모델링, 대조적 목표(contrastive objectives)가 텍스트로부터 이미지 표현을 학습
반면,
1. Li et al. (2017)은 zero-shot 설정에서 ImageNet에 대해 11.5%의 정확도
대신,
7. 좁은 범위에 목표 설정이 잘 된 약지도의 사용이 성능을 향상
8. ImageNet으로 미세 조정되었을 때 사전 학습된 모델들은 정확도를 5% 이상 증가
9. 노이즈가 많은 JFT-300M 데이터셋의 클래스를 예측하도록 모델을 사전 학습, 대규모 전이학습에서 좋은 성과
** 크라우드 라벨링: 사람이 직접 분류
APPROACH
2.1. Natural Language Supervision
비지도 학습, 자기 지도 학습, 약지도 학습(weakly supervised), 지도 학습으로 나뉜다.
모두 자연어가 훈련의 기초.
초기 연구의 토픽 모델 및 n-gram 표현에서 자연어 활용 어려웠지만 현재 심층 문맥 표현 학습을 통해 활용 가능.
자연어 학습 강점:
표준 크라우드소싱 레이블링이랑 비교했을 때 one-hot 인코딩처럼 정답 레이블이 필요하지 않아 자연어 지도학습 확장에 뛰어남.
대신, 자연어를 활용하는 방식은 인터넷에 널려 있는 방대한 양의 텍스트에 포함된 정보를 통해 수동적으로 학습 가능.
자연어로부터 학습하는 것은 대부분의 비지도 또는 자기 지도 학습 방식에 비해 이미지의 표현만을 학습하는 데 그치지 않고, 그 표현을 언어와 연결한다는 점에서 zero-shot 전이를 가능하게 한다는 이점을 가짐.
2.2. Creating a Sufficiently Large Datase
MS-COCO: 크라우드소싱 레이블 데이터셋, 고품질, 훈련용 사진이 약 10만 개로 사진으로 규모가 작음. (타 데이터셋은 35억)
YFCC100M: 1억 개, 하지만 품질의 범위가 다양, 메타데이터가 부족. 활용 가능한 건 1500만 -> 이미지넷과 같음.
=> 4억 개의 이미지-텍스트 쌍으로 구성된 새로운 데이터셋을 구축.
1 쿼리당 최대 2만 개 이미지-텍스트 쌍, 도합 50만 쿼리.
=> GPT-2를 훈련하는 데 사용된 WebText 데이터셋과 유사한 총 단어 수 가짐.
2.3. Selecting an Efficient Pre-Training Method
이미지 CNN과 텍스트 트랜스포머를 처음부터 공동 훈련하여 이미지의 캡션을 예측했지만 느렸음.
-> 텍스트의 정확한 단어를 맞추는 대신, 어떤 텍스트가 어떤 이미지와 짝을 이루는지만 예측하자"는 더 쉬운 가상 작업(Proxy task)을 연구.
N개의 이미지-텍스트 쌍 배치가 주어졌을 때, CLIP은 배치 내에서 N × N개의 가능한 이미지-텍스트 쌍 중 실제로 발생한 쌍을 예측하도록 훈련.
배치 내에 존재하는 N개의 정답 쌍에 대해서는 이미지와 텍스트 임베딩 간의 코사인 유사도 최대화, 나머지 N^2 - N개의 잘못된 쌍은 유사도를 최소화하도록 이미지 인코더와 텍스트 인코더를 공동 학습.
2.4. Choosing and Scaling a Model
Modified ResNet-50: ResNet-D 구조와 Blur Pooling 기법을 적용. Global Average Pooling을 Attention Pooling으로 바꿈. 단순 평균 대신 트랜스포머 스타일의 QKV 어텐션을 사용, 이미지의 중요한 부분을 더 잘 포착하도록.
Vision Transformer (ViT): 임베딩 층 뒤에 Layer Normalization을 하나 더 추가 / 초기화 방식 수정.
텍스트 인코더 (Text Encoder): GPT-2 스타일의 Transformer를 사용(63M 파라미터, 12 레이어), 텍스트를 BPE(Byte Pair Encoding)로 토큰화, 문장 앞뒤에 [SOS]와 [EOS] 토큰을 붙임.
2.5. Training
5개의 ResNet, 3개의 Vision Transformer 32 에포크 훈련.
(ResNet-50, ResNet-101, RN50x4, RN50x16, RN50x64.
ViT-B/32, ViT-B/16, ViT-L/14)
- Adam에 가중치 감소를 분리하여 적용, 학습률은 코사인 스케줄에 따라 서서히 감소하도록.
- 하이퍼파라미터는 휴리스틱 조정 방식, 온도 파라미터 (τ): 0.07
- 로짓 스케일링이 100을 넘지 않도록 클리핑 처리로 학습 불안정성 최소화
- 32,768 크기의 초대형 미니배치를 사용
- Mixed Precision: 훈련 가속 및 메모리 확보
- 그래디언트 체크포인팅으로 메모리 확보.
- 샤딩: 임베딩 유사도 계산 시 각 GPU가 필요한 부분만 계산하도록 분산 처리
결과: RN50x64: V100 GPU 592대, 18일.
ViT-L/14: V100 GPU 256대, 12일.
EXPERIMENTS
3.1.2. USING CLIP FOR ZERO-SHOT TRANSFER
각 데이터셋의 모든 클래스 이름을 잠재적인 텍스트 쌍의 집합으로 사용하고
CLIP에 따라 가장 확률적인 이미지-텍스트 쌍을 예측.
[ 이미지의 특징 임베딩과 가능한 텍스트 집합의 특징 임베딩을 각 인코더로 계산
-> 임베딩의 코사인 유사도를 계산
-> 온도 매개변수 τ로 스케일링
-> 소프트맥스를 통해 확률 분포로 정규화 ]
CLIP 사전 학습의 모든 단계는
- 자연어 설명으로 정의된
- 32,768개의 클래스를 가지며
- 클래스당 1개의 예제를 포함하는
- 무작위로 생성된 가상(proxy) 컴퓨터 비전 데이터셋의 성능을 최적화
3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS
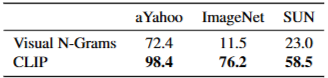
비교대조 시 정확도 향상.
3.1.4. PROMPT ENGINEERING AND ENSEMBLING
다의성 문제: 맥락 부족으로 인해 어떤 단어 의미가 의도되었는지 구별할 수 없는 상황 발생.
사전 학습 데이터셋에서 이미지와 쌍을 이루는 텍스트가 단일 단어인 경우가 상대적으로 드묾
-> A photo of a {label}."라는 프롬프트 템플릿을 대신 사용해 성능 향상
-> 각 작업에 맞게 프롬프트 텍스트를 맞춤 설정함으로써 zero-shot 성능 향상: 카테고리, 따옴표, 이미지 형태 제시.
prompt engineering과 앙상블은 ImageNet 정확도를 거의 5% 향상
3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
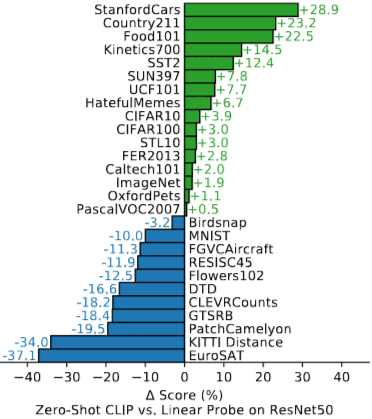
Zero-shot CLIP은 27개 데이터셋 중 16개에서 우위.
-> ImageNet의 명사 중심적 객체 지도 학습에 비해 CLIP은 동사에 대해서도 학습하기 때문.
<-> 전문적이고 복잡하거나 추상적인 작업에서는 약세.
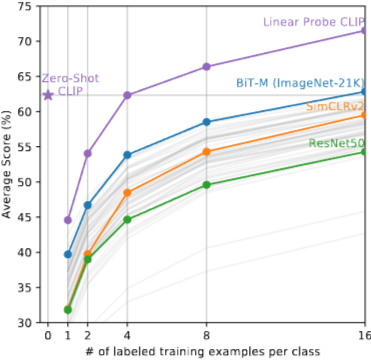
Zero-shot CLIP과 퓨샷(few-shot) 로지스틱 회귀 모델의 성능을 비교.
Zero-shot CLIP이 4샷 로지스틱 회귀의 성능과 일치.
- CLIP의 제로샷 분류기는 자연어를 통해 생성되는데, 이는 시각적 개념을 직접적으로 명시(소통 가능).
하지만 일반적인 지도 학습은 개념을 간접적으로 추론.
맥락 없는 예시 기반 학습은 서로 다른 가설들이 데이터와 일치하는 단점. 특히 원샷.
zero-shot과 퓨샷 성능 간의 차이를 해결하는 방법:
CLIP의 zero-shot 분류기를 퓨샷 분류기의 가중치에 대한 사전 분류기로 사용.
(L2 대신 하이퍼파라미터 최적화)
Zero-shot CLIP은 가장 뛰어난 성능을 보인 16샷 분류기와 거의 대등.
16샷 분류기는 ImageNet-21K 데이터셋으로 학습된 BiT-M ResNet-152x2의 특징을 사용한 모델.
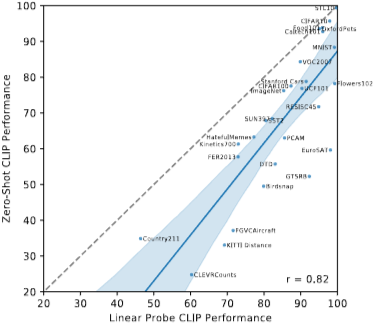
Zero-shot CLIP은 5개의 데이터셋(STL10, CIFAR10, Food101, OxfordPets, Caltech101)에서만 완전 지도 학습 성능에 근접, 제로샷 정확도와 완전 지도 학습 정확도는 90% 초과.
CLIP이 근본적인 표현의 품질이 높은 작업에 대해 제로샷 전이에 더 효과적.
3.2. Representation Learning
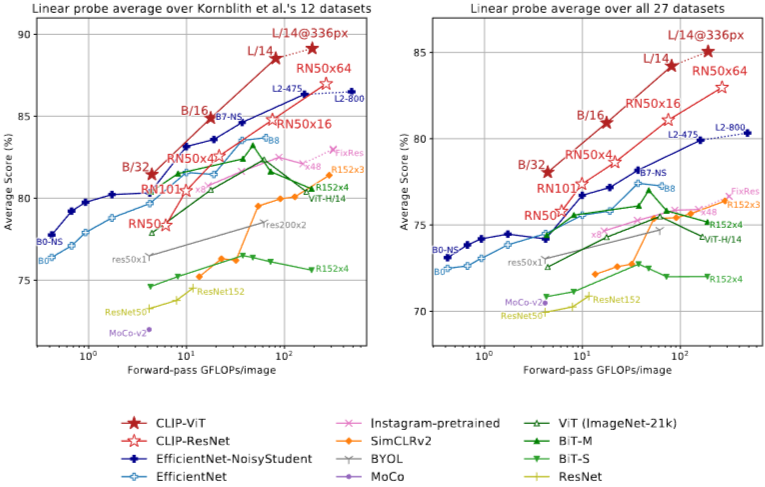
- ResNet-50 및 ResNet-101과 같은 작은 CLIP 모델은 ImageNet-1K에서 훈련된 다른 ResNet보다 우수하지만 ImageNet-21K에서 훈련된 ResNet보다 성능이 떨어짐.
- 하지만 CLIP으로 훈련된 모델은 확장성이 좋으며,
훈련한 가장 큰 모델(ResNet-50x64)은 전체 점수 및 연산 효율성에서 가장 성능이 좋은 기존 모델(Noisy Student EfficientNet-L2)을 약간 능가. - CLIP 비전 트랜스포머는 CLIP ResNet보다 약 3배 더 연산량 효율적.
CLIP 모델은 무작위 초기화부터 종단간 훈련된 단일 컴퓨터 비전 모델에서 이전에 시연된 것보다 더 넓은 범위의 작업을 학습.
모든 CLIP 모델은 규모에 관계없이 계산 효율성에서 모든 모델을 능가.
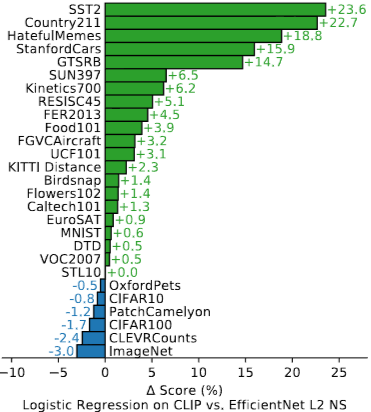
CLIP은 문맥과 세부 정보를 읽어야 하는 작업에서 강함.
ImageNet 모델의 한계는 좁은 지도 학습(하나의 라벨로 전부 묶어버림).
CLIP 상위 분야 (21/27): OCR, 지리 및 장면 인식, 비디오 행동 인식(동작 파악), 미세 분류 (Fine-grained)
CLIP 하위 분야: 저해상도 데이터셋(CLIP은 크기 기반 데이터 증강 부족 추정), 특수 도메인
3.3. Robustness to Natural Distribution Shift
딥러닝 모델이 훈련 데이터셋 전반에 걸쳐 유지되는 상관관계와 패턴을 찾는 데 매우 능숙하여 내부 분포(in-distribution, 인공지능 모델이 학습 과정에서 학습한 데이터와 동일한 확률 분포를 따르는 데이터) 성능을 향상
<-> 하지만 이런 상관관계와 패턴 중 대부분은 실제로 잘못되었고
다른 분포에서는 유지되지 않아
다른 데이터셋에서 성능이 크게 저하
ResNet-101은 ImageNet 검증 세트와 비교했을 때 이러한 자연 분포 변화에 대해 평가될 때 5배 더 많은 실수.
분포 변화(distribution shift) 상황에서의 정확도가 ImageNet 정확도에 따라 예측 가능하게 증가하며, 이는 로짓 변환된 정확도의 선형 함수로 잘 모델링됨.
**분포 변화: 훈련 데이터와 실제 예측에 사용할 데이터가 다른 분포에서 생성될 때 발생하는 상황.
강건성의 두 종류: 유효 강건성, 상대적 강건성.
유효 강건성은 '내부 분포(in-distribution)'와 '외부 분포(out-of-distribution)' 정확도 사이의 입증된 관계를 통해 예측된 것보다 더 높게 나타나는 정확도 향상을 측정.
<-> 반면 상대적 강건성은 외부 분포 정확도에서 나타나는 모든 종류의 성능 향상을 포착.
모든 Zero-shot CLIP 모델은 효과적인 강건성을 큰 폭으로 향상시키고, ImageNet 정확도와 분포 변화 하에서의 정확도 간의 격차 크기를 최대 75% 줄임.
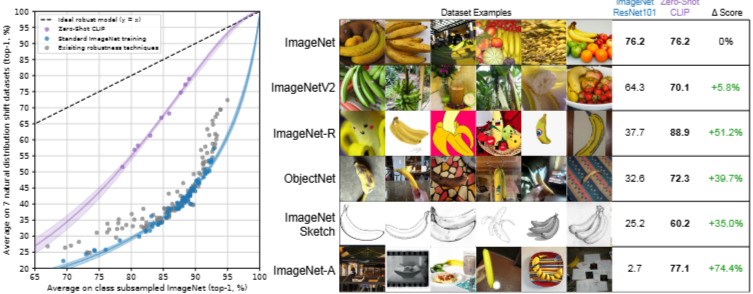
zero-shot 모델은 특정 분포에만 해당하는 허위 상관관계나 패턴을 이용할 수 없어야 함. 해당 분포에 대해 학습되지 않았기 때문.
따라서 zero-shot 모델이 훨씬 더 높은 효과적인 강건성을 가질 것으로 기대하는 것이 합리적.
Zero-shot CLIP이 유효 강건성을 향상시키는 반면 완전 지도 학습 설정에서는 이러한 이점이 거의 사라짐. 퓨샷 모델 또한 비슷.
높은 유효 강건성은 모델이 접근할 수 있는 분포별 학습 데이터의 양을 최소화함으로써 나타나지만 이는 데이터셋별 성능을 감소시킴.
결론적으로 제로샷 및 퓨샷 벤치마킹은 더 강건한 시스템의 개발을 촉진, 모델 성능에 대해 더욱 정확한 평가를 제공
Comparison to Human Performance
5명에게 3669개의 이미지를 보게 한 뒤 37가지 고양이 또는 개 품종 중 어떤 것이 이미지와 가장 잘 일치하는지 요구.
Zero-shot: 예시와 인터넷 검색 없이 레이블을 지정
One-shot: 각 품종의 샘플 이미지 1개를 제공
Two-shot: 각 품종의 샘플 이미지 2개를 제공
인간은 one-shot만으로 평균 성능 54%에서 76%로 향상, 추가 예제로부터의 부가적인 이득(margin gain)은 미미.
-> 인간은 자신이 무엇을 모르는지 알고 있으며 하나의 예시만으로도 불확실한 이미지들에 대한 사전 지식을 갱신 가능.
=> CLIP의 zero-shot 성능은 좋지만, 인간이 소수의 예시로부터 배우는 방식과 논문에서 다룬 퓨샷 방식은 서로 다름
-> 알고리즘 개선 필요
CLIP이 어려운 문제들은 인간에게도 어려움.
데이터셋 내 노이즈(잘못 레이블된 이미지 포함), 인간 및 모델 모두에게 어려운 분포 외 이미지 때문이라고 가정할 수 있음.
LIMITATION
-
Zero-shot CLIP이 SOTA에 도달하기 위해서는 약 1000배의 연산량 증가가 필요. -> 현재 하드웨어로는 불가
-
세밀한 분류와 객체 수 세기처럼 체계적인 태스크, 거리 분류처럼 새로운 태스크의 경우 성능이 낮음
-
타 딥러닝 모델처럼 분포 외 데이터에는 여전히 잘 일반화되지 않음
-
주어진 zero-shot 분류기 내의 개념들 중에서만 선택 가능
-> 대조 학습과 생성 학습 목적 함수를 공동 훈련하거나
-> 추론 시점에 주어진 이미지에 대한 수많은 자연어 설명을 검색하는 등 시도 가능 -
전체 검증 세트에 대한 성능을 반복적으로 조회 -> 수천 개의 예제로 인해 재현 가능성 ↓
-
사회적 편견 학습 가능성
-
언급했듯 zero-shot -> one-shot 설정으로 성능 증가를 보이는 인간과는 방식이 다름
REFERENCES
Zero-shot:
https://wikidocs.net/225335
https://feccle.tistory.com/492#google_vignette
Distribution shift:
https://aliencoder.tistory.com/155
