인턴과정 때 회사 위키에 깔꼼하니 작성했는데, 잘못하면 정직원 전환 안될 것 같아서 마구잡이로 블로그에 복사해둔 글이라 형식이 예쁘진 않습니다. (아 전환은 됐습니다. 다행이죠)
근데 지나가다 도움이 되는 내용이 포함되어 있다면 충분한 것이겠죵
Node
- Chrome V8 JS 엔진으로 빌드된 JS 런타임 (런타임 : 특정 언어로 만든 프로그램들을 실행할 수 있는 환경)
- 원래 js는 웹 브라우저 위에서만 실행 가능 (브라우저에 js 런타임이 내장되어있음)
- 이벤트 기반
- 싱글 스레드
- 논 블로킹 모델 사용
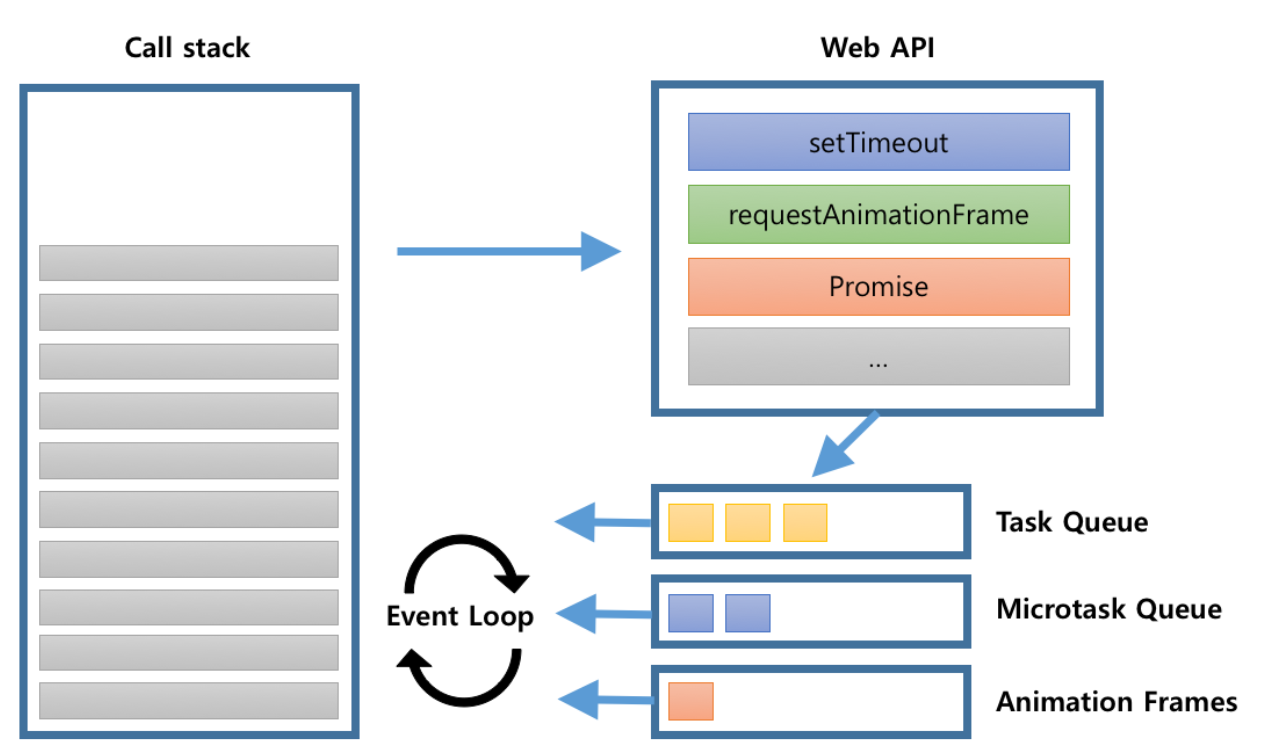
이벤트 기반
- 이벤트 루프 : 어떤 순서로 콜백 함수를 호출할지 결정
- Event Loop는 Call Stack 내에 현재 실행중인 task가 있는지 그리고 각각의 Queue들에 task가 있는지 반복적으로 확인한다.
- 만약 Call Stack이 비어있다면 Queue 내의 task를 Call Stack으로 이동시키고 실행한다.
- Chrome기준으로 Microtask Queue => Animation Frame => Event Queue 순서로 queue안에 들어있는 task들을 확인하고 만약 큐에 task가 있다면 dequeue 한 뒤 Call Stack에 추가한다.
Task Queue(Event Queue)
- Timer 함수(setTimeout, setInterval), DOM 이벤트 리스너(addEventListener) 등등의 콜백 함수가 보관되는 영역
Microtask Queue
- Promise 객체의 .then/.catch/.finally 콜백 함수가 보관되는 영역
Animation Frame
- requestAnimationFrame의 콜백 함수가 보관되는 영역
싱글 스레드
- 스레드가 하나 (동시에 실행될 수 없는 이유)
- 프로세스 - 작업 단위 ( 프로세스간 메모리 같은 자원 공유 X)
- 스레드 - 프로세스 내 실행의 흐름 단위 (프로세스가 스레드 여러 생성하여 작업 동시 처리 가능) (스레드들은 부모 프로세스의 자원을 공유한다)
- 노드는 싱글스레드 논 블로킹 => I/O 작업을 논 블로킹 방식으로 처리, 끝나는 순서대로 처리 => node를 서버로 사용해도 좋은 이유! but CPU 부하가 큰 작업에는 적합하지 않다.
- 멀티 스레드가 좋아보이지만 I/O 작업의 크기에 따라 스레드 늘렸다, 줄였다 하는 비용도 발생
- 멀티 스레드, 논 블로킹 방식이 제일 좋아보인다 => 어려우니까 멀티 프로세싱 방식을 사용하고, I/O 요청은 멀티 프로세싱이 더 효율적이다.
- I/O => 파일 시스템 접근(파일 읽기,쓰기,폴더 만들기)나 네트워크를 통한 요청
논 블로킹
이전 작업완료될 때까지 대기하지 않고 다음 작업 수행한다.
- 동기와 비동기 : 백그라운드 작업 완료 확인
- 블로킹과 논 블로킹 : 함수가 바로 return 되는지 여부
- 동기 : 블로킹 방식에서 호출한 함수가 바로 return 되지 않고, 백그라운드 작업이 끝나야 return된다. 즉 끝날때까지 기다리고 있음 (sync메서드)
- 비동기 : 논블로킹 방식에서는 호출한 함수가 바로 return 되어 다음 작업으로 넘어가면, 백그라운드 작업 신경 쓰지 않고, 나중에 백그라운드가 알림 줄 때 처리함 => 특정 로직의 실행이 끝날 때까지 기다려주지 않고 나머지 코드를 먼저 실행하는 것
노드만의 장점이 뭘까?
- 개수는 많지만 크기는 작은 데이터 실시간 주고받기 (CPU의 부하가 작은 여러 작업들?)
- 네트워크나 데이터베이스, 디스크 작업 같은 I/O에 특화
ex) 실시간 채팅 애플리케이션, 주식 차트, JSON 데이터 제공하는 API 서버- 멀티 스레드 작업도 가능하다 (하지만 어렵고, C, C++, Rust ,Go와 같은언어에 비해 속도가 느리다)
- 대규모 데이터 처리(빅데이터?) CPU 많이 사용하는 작업을 위한 서버로는 권장되지 않는다. => 스레드 하나에서 처리되는 경우가 대부분이라서 cpu 연산이 많이 요구되면 스레드 하나가 감당하기 어렵다.
- 노드에는 웹 서버가 내장되어 있어 입문자가 쉽게 접근 가능
- 노드 외 서버 개발시에는 아파치, nginx처럼 별도의 웹 서버 설치 필요
모듈
import / export 모듈 개념
ES2015(es6) 이용해서 import, export default 이용
require => import
module.exports => export default
정현님이 말씀해주신 모듈
- os : 브라우저상의 js는 운영체제의 정보를 가져올 수 없지만 노드는 가능하다!
- fs : 파일 시스템에 접근, 파일 생성 삭제, 폴더 생성 삭제, 읽고 쓰기
=> 동기 메서드(readFileSync) : 단점 == 요청이 수백개 이상일 때 성능에 문제, 이전 작업 완료되어야 다음 작업 진행
=> 비동기 메서드 (readFile) : 단점? == 코드 순서대로 작업 처리되는 것이 아님, 주로 비동기 메서드가 더 효율적- crypto : 암호화(네트워크보안 때 배운것?)
=> 단방향 암호화 : 복호화 필요 없는 정보 (고객 비밀번호), 해시 기법 이용 => createHash.update.digest
=> 양방향 암호화 : 복호화 가능
http 모듈
- createServer 메소드 안에 requires 매개변수가 있다.
- req 객체 : 요청에 관한 정보
- res 객체 : 응답에 관한 정보
- res.writeHead : 응답에 대한 정보 기록 (첫 번째 인수 : 상태 코드, 두번째 인수 : 콘텐츠 형식) => 헤더
- res.write : 첫번째 인수 : 클라이언트로 보낼 데이터 ( 데이터가 기록 되는 부분 === 본문)
- res.end : 응답 종료 (인수 있으면 그 데이터까지 클라이언트로 보내고 응답 종료)
- listen 메서드로 서버 열고 대기
HTTP 상태 코드
2XX 성공 : 200(성공), 201(작성됨)
3XX 리다이렉션 : 301(영구 이동), 302(임시 이동), 304(수정 되지 않음)
4XX 요청 오류 : 400(잘못된 요청), 401(권한 없음), 403(금지됨), 404(찾을 수 없음,없는 라우트 일때)
5XX 서버 오류 : 500(내부 서버 오류 ), 502(불량 게이트웨이), 503(서비스 사용 불가)
cluster 모듈
싱글 프로세스로 동작하는 노드를 CPU 코어 모두 사용하게 해줌
분산 서비스를 가능하게 함
각 코어마다 노드 프로세스 하나씩 돌릴 수 있어 성능 개선의 장점
하지만 메모리 공유를 못하므로 세션을 메모리에 저장하면 문제가됨
레디스 서버를 도입하여 해결 가능
cluster 모듈을 직접 구현 보다는 pm2처럼 잘 만들어진 라이브러리 사용하는 것이 편리함
pm2 설명으로 이동 (분산 서비스)
REST 와 라우팅
REST : REpresentational State Transfer => 서버의 자원을 정의하고 자원에 대한 주소를 지정하는 방법 (일종의 약속이다!)
REST 구성
- 자원(RESOURCE) - URI
- 행위(Verb) - HTTP METHOD
- 표현(Representations)
REST API 디자인 가이드
- URI는 정보의 자원 표현, 리소스명은 동사보다는 명사를 사용. ex) DELETE /members/1
- 자원에 대한 행위는 HTTP 메서드
- 주소만으로 무엇을 의미하는지 알 수 있다.
HTTP 메서드
GET
- 서버 자원을 가져올 때 사용
- 요청의 본문에 데이터를 넣지 않는다.
- 데이터를 서버로 보내야 한다면 쿼리스트링 사용
POST
- 서버에 자원을 새로 등록
- 요청의 본문(body)에 새로 등록할 데이터를 넣는다.
PUT
- 서버의 자원을 요청에 들어 있는 자원으로 치환할 때
- 요청의 본문(body)에 치환할 데이터를 넣는다.
PATCH
- 서버 자원의 일부만 수정할 때
- 요청의 본문(body)에 일부 수정할 데이터를 넣는다.
DELETE
- 서버의 자원을 삭제 할 때
- 요청의 본문에 데이터를 넣지 않는다.
OPTIONS
- 요청하기 전 통신 옵션을 설명하기 위해
쿠키와 세션
쿠키
서버가 요청자가 누구인지 기억하기 위해 요청의 응답에 쿠키를 함께 보낸다.
쿠키는 유효기간이 있고, '키-값'의 쌍으로 구성
브라우저는 쿠키를 자동으로 동봉해서 서버로 보내므로 따로 처리 필요 없다.
서버에서 브라우저로 쿠키를 보낼때만 코드 작성
쿠키 === 요청자가 누구인지 추적하는 장치
쿠키는 요청의 헤더에 담겨 전송
브라우저는 응답의 헤더에 따라 쿠키 저장
세션
쿠키에 이름 넣지 않고, uniqueInt 숫자 값 보냄
사용자의 이름과 만료시간을 uniqueInt 속성명 아래의 session 객체에 대신 저장
서버에 사용자 정보를 저장하고 (session 객체로) , 클라이언트와는 세션아이디로만 소통
세션 아이디를 쿠키사용으로 주고받는다. => 세션 쿠키 : 세션을 위해 사용하는 쿠키
실제 배포용 서버에서는 세션을 변수에 저장안함 (서버 멈추거나 재시작시 변수 초기화 되니까 => user 정보 싹다 날아감, 서버의 메모리 부족하면 세션을 저장하지도 못함)
변수에 저장하는 대신 레디스나 맴캐시드라는 데이터베이스에 저장한다.
Express 란? : 웹 서버 프레임워크
http 모듈의 요청과 응답 객체에 추가 기능을 부여한 것 ( if문으로 요청 메서드와 주소 구별필요 x)
익스프레스 내부에 http 모듈이 내장되어 있어 서버의 역할 가능
