❓B-Tree와 B+Tree란?
💡B-Tree
🔸 B-Tree (Balanced Tree)
B-Tree는 다수의 자식을 가질 수 있는 균형 잡힌 다진 트리입니다
루트 노드와 단말 노드를 제외한 모든 노드는 ⌈M/2⌉이상 M이하의 자식을 갖는다.
루트 노드는 적어도 2개의 자식을 갖는다.
각 노드의 원소수는 최소 ⌈M/2⌉ - 1개 ~ 최대 M - 1개를 가진다 (최소개수이하 : underflow, 최대 개수 이상 : overflow)
검색, 삽입, 삭제 연산의 시간복잡도는 O(log n)입니다.
삽입
- 데이터는 항상 단말 노드에 추가된다.
- 추가될 단말 노드에 여유 공간이 있다면 그냥 삽입, 없다면 분할한다.
ex) M이 3인 B-Tree 데이터 삽입(1, 8, 4, 6, 13, 5, 27, 9)
-
1, 8삽입
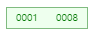
-
4 삽입 후 분할
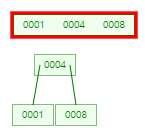
-
6 삽입
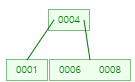
-
13 삽입 후 분할
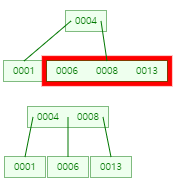
-
5 삽입
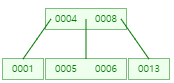
-
27 삽입
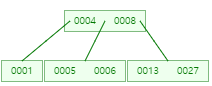
-
9 삽입 후 분할
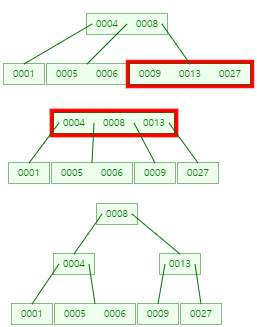
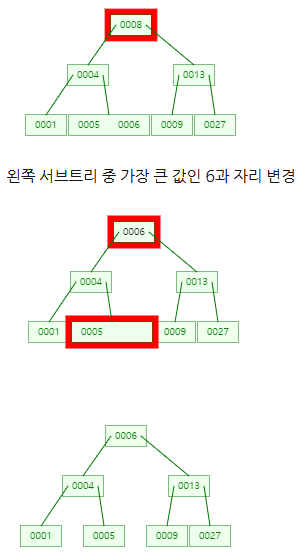
삭제
만약 삭제해도 B트리 조건을 만족한다면 아무런 과정이 필요없다.
하지만 B트리 구조가 깨진다면 다시 맞춰줘야 한다.
💡B+Tree
🔸 B+Tree
B+Tree는 B-Tree를 확장한 구조입니다.
내부 노드는 검색용 키만 저장하고, 실제 데이터는 리프 노드에만 저장합니다.
리프 노드끼리 연결 리스트로 연결되어 있어 범위 검색에 매우 유리합니다.
삽입
단말 노드가 가득 찼을 경우 -> 중간값을 부모노드로 올리고 분할한다.
- 4 삽입
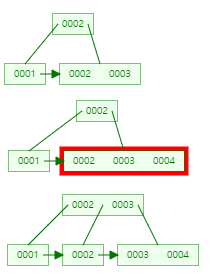
- 5삽입
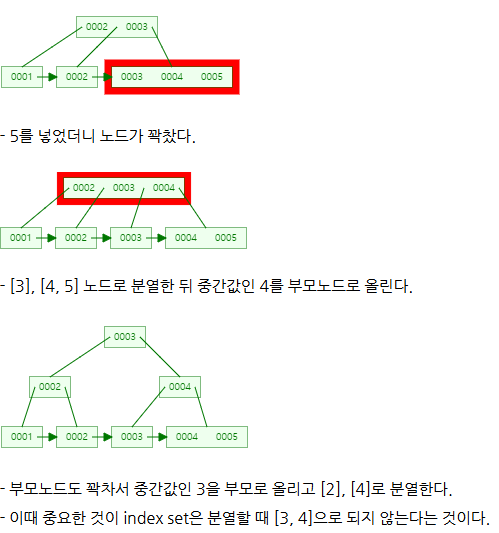
삭제
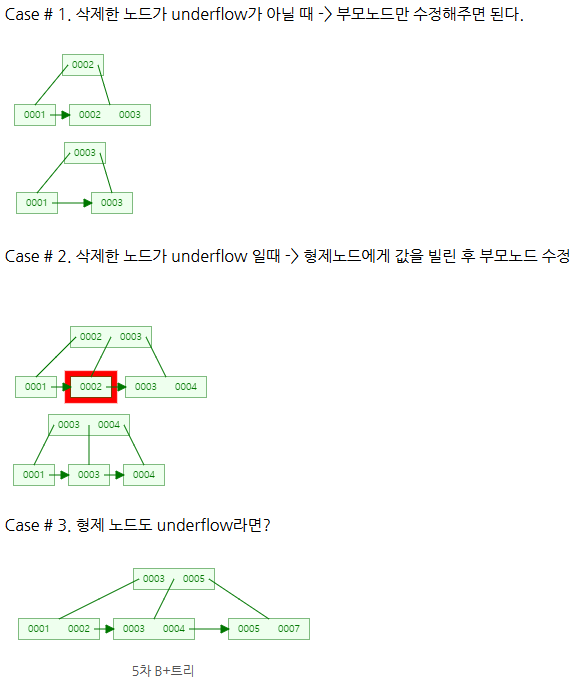
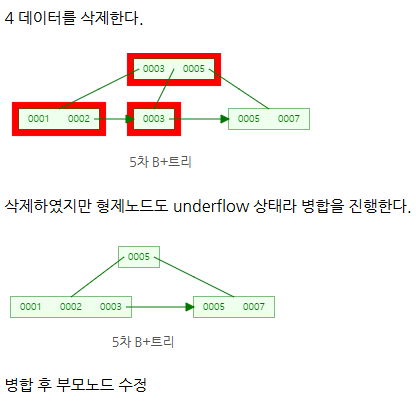
❓B+Tree가 B-Tree보다 반드시 좋을까요?
✅ B+Tree의 장점
1. 리프 노드 간 연결로 빠른 범위 검색
- B+Tree는 모든 실제 데이터를 리프 노드에만 저장하며, 리프 노드들이 연결 리스트처럼 연결되어 있습니다.
- 따라서 특정 범위의 데이터를 조회할 때, 리프 노드에서 시작하여 옆으로만 이동하면 되므로 범위 검색(range query)에 매우 효율적입니다.
2. 더 많은 키를 한 노드에 저장 가능
- B+Tree는 내부 노드에는 오직 키만 저장하므로, 같은 크기의 블록 안에 더 많은 분기가 가능합니다.
- 이는 트리의 높이를 낮추고 디스크 I/O를 줄여 전체적인 성능을 향상시킵니다.
3. 정렬된 순서 보장
- 리프 노드에 모든 키가 정렬된 상태로 저장되어 있어 순차 접근에 특히 적합합니다.
⚠️ 단점
1. 단일 레코드 조회 시, B-Tree보다 느릴 수 있음
- B-Tree는 실제 데이터가 내부 노드에도 존재하므로, 경우에 따라 루트 → 중간 노드만 거치고도 데이터를 바로 찾을 수 있습니다.
- 반면 B+Tree는 무조건 리프 노드까지 내려가야 하므로, 조회 깊이가 더 깊어질 수 있습니다.
2. 구조가 더 복잡하고 메모리 사용량이 더 많을 수 있음
- 리프 노드 연결을 유지하고, 모든 데이터를 리프에 따로 저장해야 하므로 B+Tree는 구현이 더 복잡하고, 경우에 따라 메모리 오버헤드가 더 클 수 있습니다.
✅ 결론
- 범위 검색이 많은 상황 (ex. WHERE age BETWEEN 30 AND 40) → B+Tree 유리
- 단일 키 접근이 빈번한 상황에서는 B-Tree가 이점을 가질 수 있음
❓왜 DB는 RBT 대신 B-Tree/B+Tree를 사용할까?
RBT(RedBlack-Tree)
균형 이진 트리로, 각 노드에 'red' 또는 'black' 속성을 부여해 삽입/삭제 시 트리의 균형을 유지합니다.
일반적으로 메모리 기반 자료구조로 많이 사용되며, std::map, std::set (C++ STL), Java의 TreeMap 등에 쓰입니다.
참고
메모리 접근 방식에서의 차이점
📌 B-Tree는 배열 기반 구조
- B-Tree의 각 노드는 배열 형태로 구현되어 있어, 메모리 상에서 데이터가 연속적으로 저장됩니다.
- 같은 노드 안의 데이터를 탐색할 때는, 포인터 접근 없이 배열 인덱스만으로 직접 접근이 가능합니다.
- 이는 곧, CPU가 별도의 주소 계산 연산 없이 빠르게 메모리 주소를 결정할 수 있다는 뜻입니다.
👉 장점: 내부 노드에서 여러 키를 빠르게 탐색할 수 있어 디스크 I/O 비용이 줄고, 성능이 향상됩니다.
📌 Red-Black Tree는 참조 포인터 기반 접근
- RBT는 각 노드에 하나의 키만 저장하고, 좌우 자식 노드를 포인터로 연결합니다.
- 트리 내의 모든 데이터는 포인터를 따라 이동하며 탐색해야 하며, 메모리 상에 연속적으로 저장되지 않을 수 있습니다.
- 포인터 접근은 CPU가 실제 데이터를 찾기 위해 추가 연산 (주소 계산, 캐시 미스 등) 을 수행해야 하기 때문에, 성능에 영향을 줄 수 있습니다.
👉 단점: 탐색 중 포인터를 따라가야 하므로, 메모리 접근 효율이 떨어지고 캐시 적중률도 낮아질 수 있음.
출처
https://m.blog.naver.com/shekwl24/222245938621
https://steady-coding.tistory.com/558
